Elasticsearch学习笔记
Elasticsearch学习笔记
- 一 下载安装
-
- 1.1 Elasticsearch
- 1.2 elasticsearch-head
- 1.3 Kibana
- 1.4 ik分词器
- 二 es基础知识
-
- 2.1 定义
- 2.2 数据类型
-
- 2.2.1 字符串
- 2.2.2 数字
- 2.2.3 日期
- 2.2.4 boolean
- 2.2.5 binary(二进制)
- 2.2.6 ip
- 2.2.7 range(范围)
- 2.2.8 地理数据
- 2.2.9 Aggregate metric(聚合指标)
- 2.2.10 Alias(别名)
- 2.2.11 array
- 2.2.12 向量
- 2.2.13 token_count(令牌计数)
- 2.2.14 histogram(直方图)
- 2.2.15 join
- 2.2.16 对象
- 2.2.17 percolator
- 2.2.18 形状
- 2.2.19 rank_feature / rank_features
- 2.2.20 search_as_you_type
- 2.3 元数据
- 三 kibana操作CRUD
-
- 3.1 index(索引)
- 3.2 mapping(映射)
- 3.3 aliases(别名)
- 3.4 操作数据
-
- 3.4.1 插入
- 3.4.2 搜索
- 四 集成springboot
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,流行的企业级搜索引擎,也是最受欢迎的企业搜索引擎*。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
一 下载安装
因为elasticsearch是用Java开发的,所以要有Java环境。
1.1 Elasticsearch
-
从官网下载压缩包
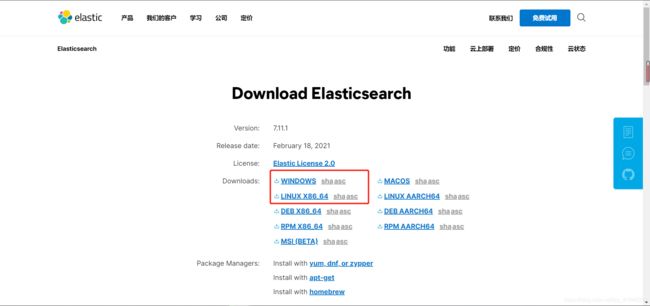
-
上传到自定义目录下,解压
-
服务器设置
① 设置 vm.max_map_count,不小于262144
修改/etc/sysctl.conf文件,添加vm.max_map_count=262144vim /etc/sysctl.conf /sbin/sysctl -p② 开放端口
es默认端口9200,9300
9200为外部通信端口
9300为节点通信端口firewall-cmd --zone=public --add-port=9200/tcp --permanent firewall-cmd --reload③ 新建用户用于启动elasticsearch
在Linux下,elasticsearch不支持使用root用户启动。groupadd elk useradd elk -g elk passwd elk chown -R elk:elk elasticsearch-7.11.1 vim /etc/security/limits.conf #调整elk用户的软硬大小限制(用户的最大打开文件数) su elk# 打开文件/etc/security/limits.conf添加下面的内容,不能小于65535 elk - nofile 65535 -
es配置
① es的jvm内存设置
因为es是用Java写的,所以es运行在jvm上。
最大值与最小值必须相同,不超过服务器总内存的50%。
打开config/jvm.options文件

② 设置当前节点的节点名和所属集群名

③ 设置集群模式-单节点discovery.type: "single-node"④ 如果有设置集群为单节点集群,则不用进行这一步。否则设置集群的主节点名和主节点地址(地址默认 为本地)

⑤ 网络设置network.host: 0.0.0.0 # 绑定运行访问的IP,0.0.0.0运行所有IP访问 http.port: 9200 # 配置运行端口 # 配置跨域访问,运行elasticsearch-head连接es # 开启跨域访问 http.cors.enabled: true # 允许跨域访问的IP http.cors.allow-origin: "*" # 如果es开启了安全模式,则配置 http.cors.allow-headers: Authorization,X-Requested-With,Content-Type,Content-Length
-
执行bin目录下的启动脚本
① Windows下,执行脚本elasticsearch.bat
 ② Linux下,执行命令
② Linux下,执行命令./bin/elasticsearch ./bin/elasticsearch -d [-p pid] # 后台运行
-
访问,验证是否启动成功
curl http://127.0.0.1:9200
-
停止
jps # 查看Java进程 jps | grep Elasticsearch kill -SIGTERM 进程ID pkill -F pid # 读取进程文件pid中的进程ID,关闭进程 -
设置为开机自启动
sudo /bin/systemctl daemon-reload sudo /bin/systemctl enable elasticsearch.service # 之后可以通过systemctl命令操作 sudo systemctl start elasticsearch.service sudo systemctl stop elasticsearch.service -
启动安全模式,设置内置用户的密码
①修改配置文件config/elasticsearch.yml,添加 :xpack.security.enabled: true
②重启es
③输入交互命令:./bin/elasticsearch-setup-passwords interactive
④设置密码

⑤验证

1.2 elasticsearch-head
elasticsearch-head是es的web前端工具,方便可视化的操作es
使用前提:有Node.js环境
-
从github下载压缩包

-
解压
-
安装依赖
进入项目根目录下,安装依赖,运行安装命令cnpm install -
启动
进入项目根目录下,执行命令npm run start
-
访问
http://127.0.0.1:9100 // 如果es开启了安全模式,则需要带上账号密码 http://127.0.0.1:9100/?auth_user=elastic&auth_password=elastic
-
连接Elasticsearch

1.3 Kibana
Kibana是一个与es协作的web端可视化工具,用于管理与操作es。又node.js开发,所以需要Node.js环境
-
从官网下载压缩包
注:与Elasticsearch的版本相同
-
解压
-
Linux下开放端口,默认端口5601
firewall-cmd --zone=public --add-port=5601/tcp --permanent firewall-cmd --reload -
允许远程访问:修改绑定地址 server.host ,默认为localhost
修改配置文件config/kibana.yml

-
绑定elasticsearch

-
汉化
修改配置文件config/kibana.yml

-
启动
① Windows:执行bin目录下的启动脚本

② Linux:cd /usr/local/ELK/kibana-7.11.1-linux-x86_64/ ./bin/kibana # 后台启动 nohup ./bin/kibana & # nohup ./bin/kibana > logs/kibana.out 2>&1 & exit tail -f nohup.out -
访问:http://localhost:5601

如果开启了安全模式,则进入登录页面(使用账号elastic)

-
点击“”自己浏览“”

-
操作es


-
操作用户



-
其他设置

-
关闭
netstat -nlp | grep 5601 kill -9 进程ID
1.4 ik分词器
官方文档
用于分词,支持自定义字典。
-
根据Elasticsearch版本从github下载对应版本的压缩包

-
在Elasticsearch下面的plugins目录下新建ik文件夹
-
解压到ik目录下

-
自定义字典
新建xxx.dic文件 -
加入自定义字典
打开elasticsearch-7.11.1/plugins/ik/config/IKAnalyzer.cfg.xml文件,把自己的字典加进去

-
重启Elasticsearch

-
分词查询
// 最小分词 GET _analyze { "analyzer": "ik_smart", "text": "中华人民共和国万岁" } // 最大分词 GET _analyze { "analyzer": "ik_max_word", "text": "中华人民共和国万岁" } -
es内置分词器
es内置分词器官方文档
二 es基础知识
2.1 定义
- index:索引,相当于表,存放文档
- doc:文档,相当于表的一行,json格式
- field:字段,相当于表的列,doc中json数据的key值。多层嵌套json的field用点.连接
- id:doc的唯一值
- mappings:映射,相当于关系型数据库中的表结构,用于定义索引的数据结构,字段的数据类型
- hits:命中,表示根据搜索条件,命中的结果
2.2 数据类型
2.2.1 字符串
keyword官方文档
text官方文档
| 类型 | 注释 |
|---|---|
| text | 用于全文搜索,不用于排序,如产品描述等,会被分词,匹配单个分词, |
| match_only_text | 一种空间优化的text,用于禁用计分,它最适合索引日志消息。 |
| keyword | 不会分词,用于过滤与排序。如邮件地址、主机名、状态码等 |
| constant_keyword | 特殊的keyword,类似Java中的常量 |
| wildcard | 通配符,也是一个keyword字段,用于非结构化机器生成的内容,针对具有大值或高基数的字段进行了优化。 |
| version | 版本,特殊的keyword, |
2.2.2 数字
number官方文档
unsigned_long官方文档
-
整数
在满足需求的情况下尽量选择小的。
类型 描述 范围大小 long 一个有符号的 64 位整数 -263 到 263 - 1 integer 一个有符号的 32 位整数 -231 到 231-1 short 一个有符号的 16 位整数 -32,768 到 32,767 byte 一个有符号的 8 位整数 -128 到 127 unsigned_long 一个无符号的 64 位整数 0 到 264-1(包括0和264-1) -
浮点型
类型 描述 double 双精度 64 位 IEEE 754 浮点数,仅限于有限值。 float 单精度 32 位 IEEE 754 浮点数,仅限于有限值。 half_float 半精度 16 位 IEEE 754 浮点数,仅限于有限值。 scaled_float 由long支持的浮点数,按固定double比例因子缩放。 对于float、half_float和scaled_float,-0.0和+0.0是不同的值,使用term查询查找-0.0不会匹配+0.0,反之亦然,同样range查询中上边界是-0.0不会匹配+0.0,下边界是+0.0不会匹配-0.0。
其中scaled_float,比如价格只需要精确到分,price为57.34的字段缩放因子为100,存起来就是5734。
优先考虑使用带缩放因子的scaled_float浮点类型。因为对于浮点类型,使用缩放因子将浮点数据存储为整数通常更有效,这对节省磁盘空间很有帮助,因为整数比浮点更容易压缩。
如果scaled_float不合适,则选择满足需求的最小的。

2.2.3 日期
-
date
官方文档
日期类型,可以接受日期格式的字符串,或者自计算机纪元以来的秒数或毫秒数的数字(但数字必须为正数,所以1970以前,只能用字符串格式表示)。
默认格式:“format”: “strict_date_optional_time||epoch_second”
自定义日期格式PUT my-index-000001 { "mappings": { "properties": { "date": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } } }多种格式用||分隔,其中第一个是搜索结果展示的日期格式。而在排序中,日期都是展示毫秒数。
-
date_nanos
官方文档
保存时间自1970以来的纳秒的数字。
2.2.4 boolean
官方文档
布尔类型,可以接收true或false,或者它们两个的字符串"true"/“false”,也可以接受空字符串,表示false
2.2.5 binary(二进制)
官方文档
二进制类型是指用base64编码的二进制字符串,可用来存储二进制形式的数据,例如图像。默认情况下,该字段不存储且不可搜索。
2.2.6 ip
官方文档
用于索引或存储IPv4或者IPv6的地址
2.2.7 range(范围)
官方文档
范围字段类型表示介于上限和下限之间的连续值范围。它们是使用运算符 gt或gte为下界和lt或lte为上界定义的。
①integer_range,带符号的32位整数区间,最小值-231,最大值231-1
②long_range,带符号的64位整数区间,最小值-263,最大值263-1
③float_range,单精度32位IEEE 754浮点数区间
④double_range,双精度64位IEEE 754浮点数区间
⑤date_range,日期值范围,表示为系统纪元以来经过的无符号64位整数毫秒
⑥ip_range,支持IPv4或IPv6(或混合)地址ip值范围
2.2.8 地理数据
-
geo-point:地址位置数据类型,可以用来存放经纬度。可以接受5种类型的经纬度
官方文档PUT my-index-000001 { "mappings": { "properties": { "location": { "type": "geo_point" } } } } PUT my-index-000001/_doc/1 { "text": "Geopoint as an object", "location": { "lat": 41.12, "lon": -71.34 } } PUT my-index-000001/_doc/2 { "text": "Geopoint as a string", "location": "41.12,-71.34" // 字符串,格式:"lat,lon" } PUT my-index-000001/_doc/3 { "text": "Geopoint as a geohash", "location": "drm3btev3e86" // geohash,Geohashes 是经纬度交错的位的base32编码字符串。geohash 中的每个字符都会为精度增加额外的 5 位。所以哈希越长,它就越精确。出于索引目的,geohash 被转换为纬度-经度对。在此过程中仅使用前 12 个字符,因此在 geohash 中指定超过 12 个字符不会提高精度。12 个字符提供 60 位,这应该将可能的错误减少到小于 2cm。 } PUT my-index-000001/_doc/4 { "text": "Geopoint as an array", "location": [ -71.34, 41.12 ] // 数组,格式: [ lon, lat] } PUT my-index-000001/_doc/5 { "text": "Geopoint as a WKT POINT primitive", "location" : "POINT (-71.34 41.12)" // 字符串,格式:"POINT(lon lat)" } GET my-index-000001/_search { "query": { "geo_bounding_box": { "location": { "top_left": { "lat": 42, "lon": -72 }, "bottom_right": { "lat": 40, "lon": -74 } } } } } -
geo-shape:地理形状数据类型,当被索引的数据包含除地理点之外的形状(如长方形、圆形…)时,使用此数据类型。geo-shape映射将GeoJSON(一种对各种地理数据结构进行编码的格式)映射到geo-shape类型。可以表示点、线(两个点)、多边形(多个点,第一与最后一个点相同,闭合才是形状)、带孔多边形(多个多边形,第一个多边形是外边界,后面的是里面的孔)
官方文档
2.2.9 Aggregate metric(聚合指标)
官方文档
聚合字段用来保存一组最大值,最小值,和,总数等其中几个指标的字段类型
-
定义
PUT stats-index { "mappings": { "properties": { "agg_metric": { "type": "aggregate_metric_double", "metrics": [ "min", "max", "sum", "value_count" ], // 字段中的指标 "default_metric": "max" // 默认指标,搜索时用来匹配 } } } } -
插入数据
PUT stats-index/_doc/1 { "agg_metric": { "min": -302.50, "max": 702.30, "sum": 200.0, "value_count": 25 } } -
查询
POST stats-index/_search?size=0 { "aggs": { "metric_min": { "min": { "field": "agg_metric" } }, "metric_max": { "max": { "field": "agg_metric" } }, "metric_value_count": { "value_count": { "field": "agg_metric" } }, "metric_sum": { "sum": { "field": "agg_metric" } }, "metric_avg": { "avg": { "field": "agg_metric" } } } } // 查询字段agg_metric中max(由default_metric指定)为702.30的 GET stats-index/_search { "query": { "term": { "agg_metric": { "value": 702.30 } } } }
2.2.10 Alias(别名)
官方文档
别名类型,即将一个字段作为另一个字段的别名来使用
PUT trips
{
"mappings": {
"properties": {
"distance": {
"type": "long"
},
"route_length_miles": {
"type": "alias", // 设置类型为别名
"path": "distance" // 指定为那个字段的别名,要是完整的路径
},
"transit_mode": {
"type": "keyword"
}
}
}
}
2.2.11 array
官方文档
在es中,没有专用的数组类型,但是默认情况下,任何类型都是数组类型。
比如字段name定义类型为keyword,但是它不仅支持字符串,也支持字符串数组。
通过中括号表示数组,但中括号中的数据类型必须相同。
PUT my_test_index
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"birthday": {
"type": "date"
}
}
}
}
POST my_test_index/_doc
{
"name": ["张三", "阿三"],
"age": 18,
"birthday": "2000-05-24"
}
2.2.12 向量
-
dense_vector(密集向量)
官方文档
存放多维向量数据,实际是存放数字类型的数组,其中的数字类型不一定要相同。
dense_vector字段不支持查询、排序或聚合。它们只能通过专用的向量函数在脚本中访问。PUT my-index-000001 { "mappings": { "properties": { "my_vector": { "type": "dense_vector", "dims": 3 // 向量维度,必须 }, "my_text" : { "type" : "keyword" } } } } PUT my-index-000001/_doc/1 { "my_text" : "text1", "my_vector" : [0.5, 10, 6] } -
sparse_vector(稀疏向量)
官方文档稀疏向量字段存储浮点值的稀疏向量。向量中可以包含的最大维数不应超过1024。不同文档的维度数量可能不同。稀疏_向量场是单值场。
这些向量可用于文档评分。例如,文档分数可以表示给定查询向量和索引文档向量之间的距离。
将稀疏向量表示为对象,其中对象字段是维度,字段值是这些维度的值。维度是0到65535之间的整数值,编码为字符串。尺寸不需要按顺序排列。PUT my-index-000001 { "mappings": { "properties": { "my_vector": { "type": "sparse_vector" }, "my_text" : { "type" : "keyword" } } } } PUT my-index-000001/_doc/1 { "my_text" : "text1", "my_vector" : {"1": 0.5, "5": -0.5, "100": 1} } PUT my-index-000001/_doc/2 { "my_text" : "text2", "my_vector" : {"103": 0.5, "4": -0.5, "5": 1, "11" : 1.2} }
2.2.13 token_count(令牌计数)
官方文档
实际上是一个integer字段。
PUT my-index-000001
{
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
// 计算name中单词的数量
"length": {
"type": "token_count",
"analyzer": "standard"
}
}
}
}
}
}
PUT my-index-000001/_doc/1
{ "name": "John Smith" }
PUT my-index-000001/_doc/2
{ "name": "Rachel Alice Williams" }
// 搜索名字是三个单词的
GET my-index-000001/_search
{
"query": {
"term": {
"name.length": 3
}
}
}
2.2.14 histogram(直方图)
官方文档
2.2.15 join
官方文档
在doc级别建立一对多的关系,即将某一些doc作为某一个doc的子级。
2.2.16 对象
-
object:接收一个json对象。官方文档
-
flattened(扁平)
官方文档
flattened类型接受json格式数据,即把一个json对象作为一个字段。它只允许基本查询,不支持数字范围查询或高亮显示。PUT bug_reports { "mappings": { "properties": { "title": { "type": "text" }, "labels": { "type": "flattened" } } } } POST bug_reports/_doc/1 { "title": "Results are not sorted correctly.", "labels": { "priority": "urgent", "release": ["v1.2.5", "v1.3.0"], "timestamp": { "created": 1541458026, "closed": 1541457010 } } } -
nested:嵌套类型,特殊的object类型。可以保持对象的独立性,不使对象被扁平化为多值字段
官方文档// 下面示例中,如果没有第二步,类型为object,那么最后一步搜索是有结果的,但两个 // 搜索条件并不在同一个对象里面,所以这是错误的。有第二步指定类型,就不会有搜索结果 DELETE my-index-000001 PUT my-index-000001 { "mappings": { "properties": { "group": { "type": "text" }, "user": { "type": "nested" } } } } PUT my-index-000001/_doc/1 { "group" : "fans", "user" : [ { "first" : "John", "last" : "Smith" }, { "first" : "Alice", "last" : "White" } ] } GET /my-index-000001/_mapping GET my-index-000001/_search { "query": { "bool": { "must": [ { "match": { "user.first": "Alice" }}, { "match": { "user.last": "Smith" }} ] } } }
2.2.17 percolator
官方文档
2.2.18 形状
-
point(点)
官方文档
存放二维平面的点数据。PUT my-index-000001 { "mappings": { "properties": { "location": { "type": "point" } } } } // 四种插入数据的方式 PUT my-index-000001/_doc/1 { "text": "Point as an object", "location": { "x": 41.12, "y": -71.34 } } PUT my-index-000001/_doc/2 { "text": "Point as a string", "location": "41.12,-71.34" } PUT my-index-000001/_doc/4 { "text": "Point as an array", "location": [41.12, -71.34] } PUT my-index-000001/_doc/5 { "text": "Point as a WKT POINT primitive", "location" : "POINT (41.12 -71.34)" } -
shape(形状)
官方文档
用于二维平面的几何图形。
支持点、直线,多边形、一组未连接但可能相关的点、一组直线、一组单独的多边形(有孔多边形)、或点线等混合形状。
2.2.19 rank_feature / rank_features
rank_feature官方文档
rank_features官方文档
2.2.20 search_as_you_type
官方文档
2.3 元数据
官方文档
每个文档都有与其关联的元数据,例如_index/ _type、_id等。创建映射类型时,可以自定义其中一些元数据字段的行为。
- _index:文档所属的索引
- _type:文档的映射类型
- _id:文档的唯一标识
- _source:文档主体的原始JSON
- _size:_source的大小(字节)
- _doc_count:当文档表示预聚合数据时,用于存储文档计数的自定义字段
- _field_names:文档中包含非空值的所有字段。
- _ignored:存储和索引被忽略的字段
- _routing:将文档路由到特定分片的自定义路由值。
- _meta:自定义元数据,用于存储特定于应用程序的元数据,例如文档所属的在应用程序中对应的类
- _tier:在跨多个索引执行查询时,有时需要将保存在给定数据层(data_hot、data_warm、data_cold或data_frozen)节点上的索引作为目标。该_tier字段允许匹配tier_preference文档被索引到的索引设置。在某些查询中可以访问首选值
三 kibana操作CRUD
3.1 index(索引)
-
创建
// 创建索引my_test_index PUT my_test_index -
查询
// 查看所有索引状态 GET _cat/indices // 查看索引my_test_index GET my_test_index -
删除
// 删除索引my_test_index DELETE my_test_index
3.2 mapping(映射)
无法删除映射,也无法修改已有的字段映射,只能重建索引。
-
创建
① 动态映射
即自动创建映射。可以直接插入数据,es会帮忙创建映射。POST my_test_index/_doc { "name": "张三", "age": 18, "birthday": "2000-05-24" }② 显示映射
手动创建映射PUT my_test_index { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "birthday": { "type": "date" } } } } -
查看
// 查看全部 GET my_test_index/_mapping // 查看指定字段的映射,多个字段用英文逗号分割 GET my_test_index/_mapping/field/birthday,name // 还可以用通配符 GET my_test_index/_mapping/field/b* // 从多个索引中查询,多个索引用英文逗号分割 GET /my_test_index,my_test_index2/_mapping/field/b* // 从所有索引中查询 GET /_all/_mapping/field/b* -
添加
PUT my_test_index/_mapping { "properties": { "tel": { "type": "keyword" } } }
3.3 aliases(别名)
官方文档
别名有数据流别名和索引别名。别名与数据流或索引是一对多的关系。可以用别名代替索引名等进行操作
-
添加
POST _aliases { "actions": [ { "add": { "index": "logs-nginx.access-prod", "alias": "logs" } } ] } POST _aliases { "actions": [ { "add": { "index": "logs-*", "alias": "logs" } } ] } -
查看
// 查看集群所有的别名 GET _alias // 查看指定索引或数据流的别名 GET my-data-stream/_alias // 查看别名logs对应的索引和数据流 GET _alias/logs -
移除
POST _aliases { "actions": [ { "remove": { "index": "logs-nginx.access-prod", "alias": "logs" } } ] } -
批量操作
POST _aliases { "actions": [ { "remove": { "index": "logs-nginx.access-prod", "alias": "logs" } }, { "add": { "index": "logs-my_app-default", "alias": "logs" } } ] }
3.4 操作数据
3.4.1 插入
-
插入一条数据
// 向索引my-test-index插入一行数据,指定ID为1 PUT /my-test-index/_doc/1 { "name": "zs", "age": 18, "teacher": [{ "name": "赵老师", "age": 30 }, { "name": "钱老师", "age": 40 }] } // 向索引my-test-index插入一行数据,不指定ID,生成随机ID POST /my-test-index/_doc { "name": "zs", "age": 18, "teacher": [{ "name": "赵老师", "age": 30 }, { "name": "钱老师", "age": 40 }] } -
插入多条数据
PUT /my-test-index/_bulk {"create": {}} {"name":"zs","age":18,"teacher":[{"name":"赵老师","age":30},{"name":"钱老师","age":40}]} {"create": {}} {"name":"zs","age":18,"teacher":[{"name":"赵老师","age":30},{"name":"钱老师","age":40}]}
3.4.2 搜索
-
match、match_phrase和term
match:会对查询条件进行分词。搜索结果只要匹配其中一个分词就可以
match_phrase:会对查询条件进行分词。但搜索结果需要包含所有分词,且连续
term:不对查询条件进行分词 -
_source:元JSON,即插入数据时提供的JSON,查询会默认返回,且是全量返回。设置为false则不会返回。也可以指定返回字段
GET /recipes/_search { "query": { "match": { "name": "鱼" } }, "_source": false } GET /recipes/_search { "query": { "match": { "name": "鱼" } }, "_source": ["name"] } -
fields:字段,指定返回t特定字段的结果,不返回只存储未映射的字段
GET /recipes/_search { "query": { "match": { "name": "鱼" } }, "_source": false, "fields": ["name"] } // 如果字段是时间或地理空间坐标,还可以指定格式 POST my-index-000001/_search { "query": { "match": { "user.id": "kimchy" } }, "fields": [ "user.id", "http.response.*", { "field": "@timestamp", "format": "epoch_millis" } ], "_source": false } // 如果是嵌套字段,需要写全路径,用点分隔 POST my-index-000001/_search { "fields": ["user.first"], "_source": false } // 要返回只存储未映射的字段,使用"include_unmapped" : true POST my-index-000001/_search { "fields": [ "user_id", { "field": "session_data.object.*", "include_unmapped" : true } ], "_source": false } -
size:指定返回结果的条数。
// 返回3条数据 GET recipes/_search { "query": { "match": { "name": "鱼" } }, "size": 3 } -
from:对返回结果进行截取,指定从哪一条开始,
// 对根据“鱼”查询到的结果,从第二条开始截取 GET recipes/_search { "query": { "match": { "name": "鱼" } }, "from": 2 } -
分页:size + from
// 查询第二页数据,每页3条 GET recipes/_search { "query": { "match": { "name": "鱼" } }, "size": 3, "from": 3 } -
sort(排序):根据某些(可多个)字段对查询结果进行排序。
// 根据字段rating对返回结果进行排序 GET recipes/_search { "query": { "match": { "name": "鱼" } }, "sort": [ { "rating": { "order": "desc" } } ] } -
collapse(折叠):根据某个字段对返回结果去重。
// 对查询结果根据字段type去重 GET recipes/_search { "query": { "match": { "name": "鱼" } }, "collapse": { "field": "type" } }根据某个字段对返回结果分组,可以对每组数据进行组内排序,还可以指定每组有几条数据。
GET /recipes/_search { "query": { "match": { "name": "鱼" } }, "collapse": { "field": "type", "inner_hits": [{ // 分组可以一次支持多种组内实现方式 "name": "most_recent", // 分组名称,自定义 "size": 2, // 每个分组的数据量 "sort": [{ "rating": "desc" // 分组根据字段rating进行倒序排序 }] },{ "name": "max", "size": 3, "sort": [{ "rating": "asc" }] }], "max_concurrent_group_searches": 4 // 每组允许检索的并发请求数 }, "size": 4, "sort": [ { "rating": { "order": "asc" } } ], "from": 0 }组内(inner_hits内部)还可以支持继续使用collapse。
-
filter:过滤,没有打分,但效率高,会对命中和聚合都进行过滤
GET /recipes/_search { "query": { "bool": { "filter": [{ "term": { "name": "鱼" }} ] } } } -
post_filter:后过滤,有打分,只对命中结果进行过滤
-
highlight:高亮显示。原理是对返回结果中添加标签样式
```java
GET /recipes/_search
{
"query": {
"match": {
"name": "鱼"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
// 使用内置styled标签架构
GET /recipes/_search
{
"query": {
"match": {
"name": "鱼"
}
},
"highlight": {
"tags_schema": "styled",
"fields": {
"name": {}
}
}
}
// 自定义标签
GET /recipes/_search
{
"query": {
"match": {
"name": "鱼"
}
},
"highlight": {
"fields": {
"name": {}
},
"pre_tags": ["", ""],
"post_tags": [" ", ""]
}
}
// 即使字段是单独存储的,也强制突出显示基于源的字段。默认为false.
GET /recipes/_search
{
"query": {
"match": {
"name": "鱼"
}
},
"highlight": {
"fields": {
"name": {"force_source" : true}
}
}
}
```
四 集成springboot
官方文档
-
新建项目
-
引入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.4.2version> <relativePath/> parent> <version>0.0.1-SNAPSHOTversion> <name>apiname> <description>Demo project for Spring Bootdescription> <properties> <java.version>1.8java.version> <elasticsearch.version>7.11.1elasticsearch.version> properties> <dependencies> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-elasticsearchartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>com.alibabagroupId> <artifactId>fastjsonartifactId> <version>1.2.75version> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-devtoolsartifactId> <scope>runtimescope> <optional>trueoptional> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-configuration-processorartifactId> <optional>trueoptional> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <optional>trueoptional> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-testartifactId> <scope>testscope> dependency> dependencies> <build> <plugins> <plugin> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-maven-pluginartifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> exclude> excludes> configuration> plugin> plugins> build> project> -
同步Elasticsearch版本

-
配置
spring: elasticsearch: rest: uris: 127.0.0.1:9200 -
使用
批量插入public String parseDataToEs(String keyword) { try { // 获取数据 List<Content> contents = htmlParseUtil.parseJd(keyword); // 判断索引是否存在 GetIndexRequest existsRequest = new GetIndexRequest("jd_commodity"); boolean existsResponse = restHighLevelClient.indices().exists(existsRequest, RequestOptions.DEFAULT); if (!existsResponse) { // 创建索引 CreateIndexRequest createRequest = new CreateIndexRequest("jd_commodity"); restHighLevelClient.indices().create(createRequest, RequestOptions.DEFAULT); } // 批量请求 BulkRequest bulkRequest = new BulkRequest(); for (Content content: contents) { bulkRequest.add(new IndexRequest("jd_commodity").source(JSON.toJSONString(content), XContentType.JSON)); } // 发送请求 BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); if (bulkResponse.hasFailures()) { return "failed"; } } catch (IOException e) { return "failed"; } return "successful"; }搜索
public List<Map<String, Object>> searchPage(String keyword, int from, int size) { // 创建搜索请求 SearchRequest searchRequest = new SearchRequest("jd_commodity"); // 构建搜索条件 MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", keyword); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(matchQueryBuilder); // 分页 searchSourceBuilder.from(from); searchSourceBuilder.size(size); // 高亮 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.field("name"); highlightBuilder.preTags(""); highlightBuilder.postTags(""); searchSourceBuilder.highlighter(highlightBuilder); searchRequest.source(searchSourceBuilder); try { // 发送请求 SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); List<Map<String, Object>> mapList = new ArrayList<>(); for (SearchHit hit: searchResponse.getHits()) { // 高亮替换 HighlightField name = hit.getHighlightFields().get("name"); Map<String, Object> sourceAsMap = hit.getSourceAsMap(); if (name != null) { Text[] fragments = name.fragments(); String temp = ""; for (Text text: fragments) { temp += text; } sourceAsMap.put("name", temp); } mapList.add(sourceAsMap); } return mapList; } catch (IOException e) { e.printStackTrace(); } return null; }其他
@Test void createIndex() throws IOException { CreateIndexRequest request = new CreateIndexRequest("springboot"); CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT); System.out.println(response.index()); restHighLevelClient.close(); } @Test void existIndex() throws IOException { GetIndexRequest request = new GetIndexRequest("springboot"); boolean response = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT); System.out.println(response); restHighLevelClient.close(); } @Test void deleteIndex() throws IOException { DeleteIndexRequest request = new DeleteIndexRequest("springboot"); AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); restHighLevelClient.close(); } @Test void createId() throws IOException { GetIndexRequest existsRequest = new GetIndexRequest("springboot"); boolean existsResponse = restHighLevelClient.indices().exists(existsRequest, RequestOptions.DEFAULT); if (!existsResponse) { CreateIndexRequest createRequest = new CreateIndexRequest("springboot"); restHighLevelClient.indices().create(createRequest, RequestOptions.DEFAULT); } User user = new User("张三", 3); user.setAge("aaa".equals(user.getName()) ? 0 : 1); IndexRequest indexRequest = new IndexRequest("springboot"); indexRequest.id("1"); indexRequest.timeout(TimeValue.timeValueSeconds(1)); indexRequest.source(JSON.toJSONString(user), XContentType.JSON); IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); System.out.println(indexResponse.status()); restHighLevelClient.close(); } @Test void existsId() throws IOException { GetRequest getRequest = new GetRequest("springboot", "1"); // 不获取返回的_source的上下文,效率更快 getRequest.fetchSourceContext(new FetchSourceContext(false)); boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT); System.out.println(exists); restHighLevelClient.close(); } @Test void getId() throws IOException { GetRequest getRequest = new GetRequest("springboot", "1"); GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); System.out.println(getResponse.toString()); System.out.println(getResponse.getIndex()); System.out.println(getResponse.getId()); System.out.println(getResponse.getFields()); System.out.println(getResponse.getSeqNo()); System.out.println(getResponse.getPrimaryTerm()); System.out.println(getResponse.getSourceAsString()); restHighLevelClient.close(); } @Test void updateId() throws IOException { UpdateRequest updateRequest = new UpdateRequest("springboot", "1"); User user = new User("李四", 4); updateRequest.doc(JSON.toJSONString(user), XContentType.JSON); updateRequest.timeout("1s"); UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT); System.out.println(updateResponse.toString()); System.out.println(updateResponse.status()); restHighLevelClient.close(); } @Test void deleteId() throws IOException { DeleteRequest deleteRequest = new DeleteRequest("springboot", "1"); DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT); System.out.println(deleteResponse.status()); System.out.println(deleteResponse.toString()); restHighLevelClient.close(); } /** * 批处理 * * @throws IOException io异常 */ @Test void bulkCreate() throws IOException { GetIndexRequest existsRequest = new GetIndexRequest("springboot"); boolean existsResponse = restHighLevelClient.indices().exists(existsRequest, RequestOptions.DEFAULT); if (!existsResponse) { CreateIndexRequest createRequest = new CreateIndexRequest("springboot"); restHighLevelClient.indices().create(createRequest, RequestOptions.DEFAULT); } BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("10s"); for (int i = 0; i < 10; i++) { User user = new User(String.valueOf(i), i); bulkRequest.add(new IndexRequest("springboot").id(String.valueOf(i)).source(JSON.toJSONString(user), XContentType.JSON)); } BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); System.out.println(bulkResponse.status()); System.out.println(bulkResponse.hasFailures()); // 是否失败 restHighLevelClient.close(); } @Test void search() throws IOException { SearchRequest searchRequest = new SearchRequest("springboot"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); MatchQueryBuilder query = QueryBuilders.matchQuery("name", "1"); sourceBuilder.query(query); sourceBuilder.timeout(TimeValue.timeValueSeconds(10)); // 分页 sourceBuilder.from(0); sourceBuilder.size(2); // 高亮必须要有sourceBuilder.query(query);查询条件,且高亮字段必须与查询字段相同 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.field("name"); highlightBuilder.preTags(); highlightBuilder.postTags(); sourceBuilder.highlighter(highlightBuilder); searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); System.out.println(searchResponse.status()); System.out.println(JSON.toJSONString(searchResponse)); for (SearchHit searchHit: searchResponse.getHits().getHits()) { System.out.println(searchHit.toString()); } restHighLevelClient.close(); }