PolarDB 卷来卷去 云原生低延迟强一致性读 1 (SCC READ 译 )
开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1620人左右 1 + 2 + 3 + 4) 3群突破 490已关闭自由申请如需加入请提前说明,新人会进4群(200),另欢迎 OpenGauss 的技术人员加如入。

每人感悟,感悟每日,明白道理的人很多,但还是过不好这一辈子的根本的,你明白的道理可能仅仅是看了一眼道理,就告诉自己你明白了,或者你明白了但是那个道理不是道理。事情是这样的,在我们的MySQL 被 POLARDB 打败了后,我们遇到一个问题,就是强一致读的问题,在一个特殊的应用中,在大批量写后,需要立即进行数据的读,之前在MySQL都是打到主库,但基于想利用PolarDB的double 节点,总不能还强制将读都指定到写节点,所以我们采用了原有的方案,但是发现在大量的写后去马上读的中应用给出的延迟在20ms,也就是在大量UPDATE 几百万的数据后,从库的数据延迟应该在20ms内。虽然我们也解决了这个问题,但是实际上POLARDB 还有一个新的功能我们没有用到,POLARDB-SCC 。
本着卷不死,就往死里卷的态度,今天的继续学习POLARDB-SCC,虽然此时脑子已经给我提示你累了需要休息,下面为白皮书PolarDB-SCC: A Cloud-Native Database Ensuring Low latency for Strongly Consistent Reads
————————————————————————————
常见的云原生数据库设计中大多采用了一个由读写节点为基本单元的组成架构,在这样的设计中,RW- RO节点的数据通过预写日志(REDO)来进行数据的复制,所以应用的设计人员必须接受一个事实,读写节点之间的数据有延迟,或者将应用程序对于数据库的要求降低,因为数据的传播需要传输和应用,如Aurora 选择了性能而不是强一致,所以对于读写一致性要求的应用,从库都是多余的,哪怕你能进行无限的横向扩展。
本文提出了PolarDB-SCC,(polardb 强一致集群),这是一种云原生的数据库架构,具有非常低的延迟和强一致的数据读取性,核心思想是消除不必要的等待,减少在RO读节点需要等待数据应用在RO节点上的时间,简单的说在三个部分进行了优化, 1 时间戳线性减少时间戳获取的操作的消耗,2 最小化网络开销和CPU 的额外使用 3 使用高速RDMA网络进行数据传输。在实现POLARDB-SCC中我们尽量保证不会产生额外的硬件消耗,做到忽略强一致性带来的硬件消耗的数据库产品。
我们对比其他产品如Aurora, Hyperscale, Socrates , Polardb等,其中这些数据库采用了分散共享存储架构,通常来说就是一个主节点,以及多个从节点,为保持RO节点缓冲数据的最新,RW节点为每个更新生成了相关的日志,并将日志传输给RO,RO节点应用日志来更新其缓冲数据,由于日志应用过程是异步的,RO节点应用日志来更新其缓冲数据,而虽然大多数数据库都提出从节点可以提供读服务,但由于从节点无法提供最新的写节点上的数据,而导致从节点没有被有效的利用。
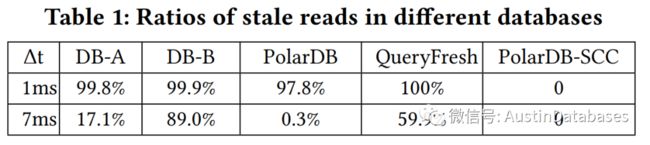
上图中在开启和关闭SCC功能的基础上,在RW节点写入数据,并在从节点立即读取,从上面的显示可以看出只有SCC 功能开启的PolarDB 可以支持RW,RO读写一致性。基于许多应用程序,强一致读中的严格一致性的要求,如果不能保证一致性已经下单的用户会发现订单不存在或支付未显示而产生业务错误的问题,对于强一致的要求在一些应用程序是有体现的。出现这样情况的场景还有可能是微服务,多个微服务共享数据的场景,这样的场景多见于保险公司和金融,支付类的公司。

当今很多云原生的数据库中,为了支持强一致,应用程序必须将所有的读请求都发到RW节点,无法通过添加RO节点来分散读请求的压力,RW节点就成为整个系统的瓶颈,严重的限制了系统读处理操作中工作负载均衡的能力,实际上很多应用程序都已读作为主要的压力所在,所以在云原生的数据库集群中确保强一致的读取,提高系统的性能是系统真正可扩展是我们要做的。
这里有两种直接设计方案,可以支持RO节点上一致性读取,1 commitwait ,2 readwait,这里两种方案,方案1 需要进行实物COMMIT时等待数据传输到从节点 而方案2 需要读请求等待读节点接受到主节点的时间戳并确认数据事务执行后,在反馈。这两种方案都是以性能作为牺牲而达到的最终一致性。这里我们进行了比较,在开启SCC后RO节点延迟在3.8%,而其他的情况延迟在126% 到128% ,其他的方案中通过使用高速网络RDMA 加速日志传输,或在RO节点更快应用日志,如query fresh,但这样为只能保证最终一致性无法保证强一致。

许多现有的系统以来与流式日志传输,并在RO节点上线性应用日志,并使用了特定的时间戳来标志事务的时间,RO节点在日志应用到特定的时间戳之前无法进行强一致的读,因为RO节点无法获知数据页面是否更改,在不知道前需要进行等待。
针对这些问题,本篇POLARDB-SCC (POLARDB 强一致集群),可以保证RO节点上进行强一致的读取和低延迟,POLARDB-SCC 基于等待策略设计但消除了读等待中的开销,最小化在从库中读的的等待时间,或者说最小化日志应用的等待时间,我们提出了层次化修改的跟踪思路,在多个层次上如全局,表,页面等各个级别上跟踪RW节点的修改,通过这样的方案当全局时间戳不满足要求的情况下,在RO节点可以做细粒度级别的等待日志应用的做法,减少了应用日志等待的时间。避免等待内存数据完全更新的做法中的缺陷,在RO节点上线性的lamport时间戳,避免频繁的从RW 节点获取时间戳,显著降低了网络和通信的开销,利用快速时间戳,进行日志的传输和时间戳的获取,从而消除了RW节点处理时间戳获取请求和传输日志的CPU开销。
基于这些设计,POLARDB-SCC 在RO节点上实现了低延迟和强一致性读取,为应用程序提供了具有强一致性的保证的代理端点,并以负载均衡的方式将读请求发送给RO节点,通过动态的增加RO节点来实现读写分离的弹性需求,因为他允许系统根据应用程序负载透明地动态增加或减少RO节点的数量,同时PolarDB-SCC在不修改数据库内部数据结构也不依赖特定数据库内部数据结构的基础上很容易在不同的数据库上进行实现。
(跳出翻译,这里简单解释一下什么是 lamport 时间戳)
Lamport时间戳是一种用于逻辑时钟的算法,由Leslie Lamport在1978年提出。它主要用于在分布式系统中对事件顺序进行全局排序。
Lamport时间戳由整数值组成,每个进程都维护一个本地计数器。当一个进程执行一个事件时,它会将本地计数器的值赋给该事件的时间戳,并将本地计数器递增。由于时间戳是由本地计数器确定的,因此每个进程的时间戳会随着事件的执行而递增。
Lamport时间戳遵循以下两个规则:
如果事件A在事件B之前发生,那么A的时间戳应该小于B的时间戳。
如果事件A和事件B在同一个进程中发生,并且A在B之前,那么A的时间戳应该小于B的时间戳。
这里跳过一部分英文的内容,对于POLARDB的介绍(SCC是一个独立的文章,这里因为怕读SCC的同学不知道POLARDB的一些内容所以对POLARDB 重复介绍,就这里一并略过,有要获知POALRDB的部分可以参见以前的多篇翻译文章)。
Polardb-SCC 概述
设计原理,PolarDB-SCC 提供低延迟强一致的云原生数据库,只读RO节点始终能返回数据,对于在RW节点上应用的事务在RO上读取应用最小化的等待时间。在RO节点上使用能返回比访问数据时更早的RW上应用的数据,下图是具体的POLARDB-SCC的简易架构图,它包括一个主(RW)节点,一个或多个辅助(RO)节点,以及一个位于RW和RO节点之上的代理节点。RW节点可以同时处理读和写请求,而RO节点只响应读请求。代理节点通过将读请求分发到RO节点并将写请求转发到RW节点,实现透明的负载均衡和高可用性。如果当前的RW节点发生故障,代理节点将升级其中一个RO节点为新的RW节点。代理节点通常有多个成员(通常为2个)以提供高可用性和高性能。RW和RO节点共享分离的云存储,类似于许多云原生数据库。RW和RO节点通过基于RDMA的网络连接,实现快速日志传输和时间戳获取。

PolarDB-SCC的核心组件是分层修改跟踪器、线性Lamport时间戳和基于RDMA的日志传输协议。分层修改跟踪器维护了RW节点的三个级别的修改发,在工作中,RO节点先检查RW节点的全局级别的时间戳,然后检查表和页面级别的时间戳,一旦满足某个级别的要求,直接处理请求,无序检查下一个级别,如果也级别也无法满足的情况下,会需要等待请求也的日志应用来进行读操作。
这里最新的修改时间戳在RW节点上维护,RO节点必须为每个请求从RW 节点获取时间戳,虽然RDMA网络的速度很快,但如果RO节点负载过重,仍然会有很大的开销,为客服时间戳获取的开销,则使用Lamport时间戳,RO节点从RW 节点获取时间戳后,将其存储在本地,人和早于时间戳的请求到达RO节点直接使用本地的时间戳,不需要在从RW节点获取新的时间戳,RO 节点负载重时,这样节省了获取的时间和消耗,减少网络开销,我们采用了一边式的RDMA来进行日志的传输和时间戳的获取,将RW节点的日志写入RO节点,节省了RDMA远程写入的CPU周期。
线性Lamport时间戳:为提供强一致读操作,读请求需要能看到在主库已经提交的所有事务的数据,在 PolarDB-SCC 中只有RW节点能够更新数据,因此RW节点充当时间戳产生的角色,RO 节点在必须获取RW节点最新的时间戳并等待日志应用后在处理请求,如果RO节点负载很重,会有许多并发的时间戳的获取请求在RW节点上,这会对性能产生负面的影响,同时RO获取时间戳给RO本身也带来额外的开销,为避免并发获取时间戳的行为,POLARDB-SCC设计了一次从RW节点获取时间戳,批量为RO节点提供时间戳服务。
这解决了读等待的问题,传统的解决方案中每个RO读都要获取RW的时间戳,一个请求是否可以读取到数据的决定在于时间戳,这里新的方式为如果一个请求发现在到达时间之后已经有了其他的请求获取了时间戳的情况下,可以直接重新利用该时间戳,无需在获取新的时间戳,同时这样的方案仍然可以满足强一致性。见下图 RO 节点有一个请求
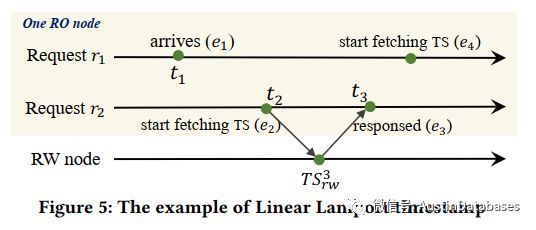
这里我们有两个读库的访问 R1 R2, 当R2 访问数据时请求了时间戳,并在T3 获得结果 TS3RW,这里R1 和 R2 在同一个RO 节点,这里有另一个访问的需求 R1 ,如果R1 对数据进行访问,根据本地时间戳原理,我们可以推测出 E1 E2 都可以采用 TS3RW作为时间戳,根据这个原理可以推出只要,在E3后如果在获取时间戳就需要在次进行获取,而在T3前的都可以使用TS3RW来进行,当在之后的数据访问,会明确之前的获取的时间戳是无效的,需要重新等待新的时间戳到来后,才能继续对读库进行访问,这样的设计就是为了在高并发的数据访问中,可以尽量少的对写库获取时间戳,而尽量复用时间戳的方式来访问读库。
基于这样的理论,我们将RW的时间戳CACHE到RO节点,来进行复用增加POLARDB-SCC在符合条件下的时间戳复用它,为了在Polardb-scc 中实现这一点,每当一个RO节点获取RW节点的时间戳,他会将该时间戳与获取操作的起始时间的时间戳用组合的方式来进行保存,通过这样的设计满足当一个RO节点上请求需要RW节点的时间戳,他将检测RO节点上的元组,如果请求达到时间早于时间戳则可以利用本地的缓存,否则就需要刷新缓存确保读的一致性。这样的方法就减少部分读在获取时间戳比对的时间。
对于可重复的读以及更高隔离级别的事务,事务开始时仅仅一次获取RW节点的时间戳,事务中的所有请求都将使用此时间戳进行强一致读,随后到达RO节点的事务与时间戳比较,检查对于事务强一致读取来说缓存的数据是否是有效的。
待.......
