DataFrame的基本用法
目录
一、定义/读取 DataFrame
1.定义DataFrame
2.定义一个空的DataFrame
3.从csv中读取DataFrame
二、读取行列
1.直接读取行列
2.使用 .loc() 读取行列
3.使用 .iloc() 读取行列
4.读取前 n 行
5.读取并修改列名
6.读取并修改行名
7.df的转置
三、删除和增加 行、列
1.删除列,增加列
2.删除行,增加行
四、保存为 csv
一、定义/读取 DataFrame
1.定义DataFrame
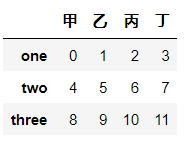
# 定义DataFrame
df = pd.DataFrame(np.arange(12).reshape(3,4),columns = list('甲乙丙丁'),index = ["one","two","three"])
df
2.定义一个空的DataFrame
# 定义一个空的DataFrame
df = pd.DataFrame(data=None,columns=range(1,5),index=[0,1]) # 从列表定义,定义列名和行名
df
df = pd.DataFrame(columns={"a":"","b":""},index=[0,1,2]) #从字典定义
df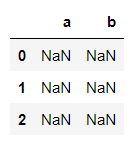
3.从csv中读取DataFrame
# 从csv中读取DataFrame
filename = "path"
data = pd.read_csv(filename, sep=’,’) # ecoding = utf-8 ; header = None 表示读取第一行,不写则表示第一行默认为列名;index_col 表示行索引的列标号二、读取行列
1.直接读取行列
# 读取数据
# 读取一列
df["甲"] # 根据列名选取数据,不能用切片取列,如df['甲':'丙']是错误的
df
# 读取行
df[:2] # 读取前两行, 使用切片读取行, 切片为左闭右开
df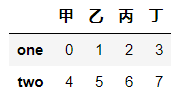
2.使用 .loc() 读取行列
# 使用 .loc() 读取数据(loc(location)) , 这里括号中写的是列名和行名,如果没有行名,即index_col=None,就写行号; 前面是行,后面是列
# 读取某一列
# df.loc[:,"甲"]
df.loc[:,"甲":"丙"]
df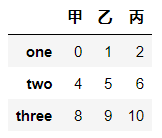
# 读取某一行
# df.loc['one',:]
df.loc["one":"three",:]
df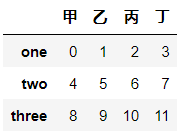
# 同时读取行和列,可以写在一个括号中,也可以写在两个括号中
df.loc["one":"three","甲":"丙"]
# df.loc["one":"three"]["乙"]
df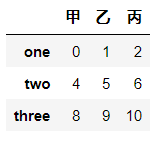
3.使用 .iloc() 读取行列
# 使用 .iloc() 读取数据的位置(iloc(indx location))
# iloc是用第几行第几列这样的数字来筛选行列
# 读取某一行
df.iloc[:2] # 读取前两行
df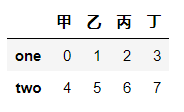
# 读取行和列
df.iloc[:2,:2] # 可以写在一个括号中
# df.iloc[:2][:2] # 也可以写在两个括号中
df
4.读取前 n 行
# 读取前 n 行
df.head(1)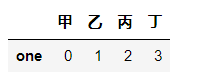
5.读取并修改列名
# 读取列名
df.columns
df.columns = ["A", "C", "D", "E"] # 修改列名
df.columns
df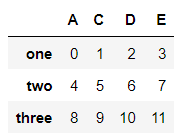
6.读取并修改行名
# 读取行名
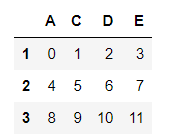
df.index
df.index = [1,2,3]
df.index
df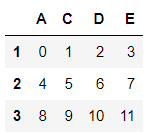
7.df的转置
# df转置
df.T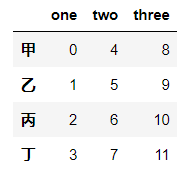
三、删除和增加 行、列
1.删除列,增加列
# 删除某一列,括号中为列名
del df["甲"]
# 删除某一列
# df.drop("乙", axis=1) # axis=0为行,axis=1为列
# df.drop(["甲","乙"], axis=1)
df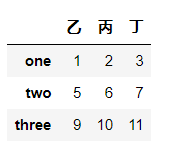
# 增加列
df["戊"] = np.arange(3)
df
2.删除行,增加行
# 增加four行
df.loc["four"] = [1,2,3,4]
df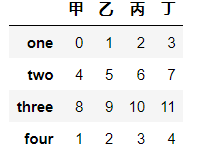
# 删除第一行
df.drop("one")
# 删除某一行
# df.drop(1,axis=0) #删除第二行
# df.drop([1,5,6,8],axis = 0) #去掉第2 6 7 9行
# df.drop([:5]) # 去掉前五行(切片为左闭右开)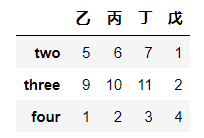
四、保存为 csv
# 保存为csv
filename = 'demo.csv'
df.to_csv(filename, index=False)