pytorch_神经网络构建5
文章目录
-
- 生成对抗网络
- 自动编码器
- 变分自动编码器
- 重参数
- GANS
- 自动编码器
- 变分自动编码器
- gans网络
- Least Squares GAN
- Deep Convolutional GANs
生成对抗网络
这起源于一种思想,假如有一个生成器,从原始图片那里学习东西,一个判别器来判别图片是真实的还是生成的,
假如生成的东西能以假乱真,那么生成器就出师了,我们就可以用生成器生成各种各样的东西了
自动编码器
最开始的构想比较简单,原始图像->编码器->编码数据->解码器->解码的图像,人们企图使用这个思想模型得到预想的解码器
后来发现如果要生成任意图像还是需要预先知道一张图像的隐藏向量信息,解码器才能画出有用的图像,这太扯了
变分自动编码器
思想是,强制编码器输出粗略符合正态分布的数据,给解码器解码
这样我们随机给出标准正态分布的隐含向量,解码器都可以生成图像
然而实际上,原始的图片经过encoder编码后得到的并不是标准正态分布,它和标准正态分布之间的差异loss可以表示为:
KL divergence
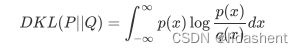
重参数
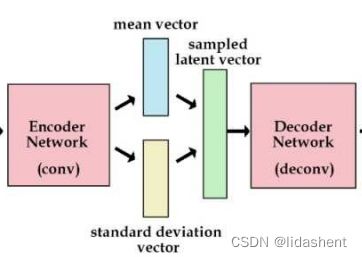
对于变分自动编码器为了避免计算如此复杂的积分,往往采用重参数技巧
含义是:
让编码器不是生成一个隐含向量,而是生成两个向量,分别为均值,标准差
虽然编码器生成的正态分布不一定符合标准正态分布,但是我们可以利用其生成的均值和标准差合成一个标准正态分布
标准正态分布*标准差+均值,得到新的标准正态分布,希望均值为0,方差为1
这样我们随机输入一个标准正态分布,就可以经过解码器得到一张图像
后来人们发现这样也存在问题
无论是自动编码器还是变分自动编码器,训练时计算的loss都是输入和输出像素点之间的误差,实际上即使是相似的像素点视觉效果也不同,需要一种新的方式来计算输入和输出图像是否相同,那么能够不单独比较像素差,而是使用神经网络判断两个图片是否相同呢?
后来有人提出了gans
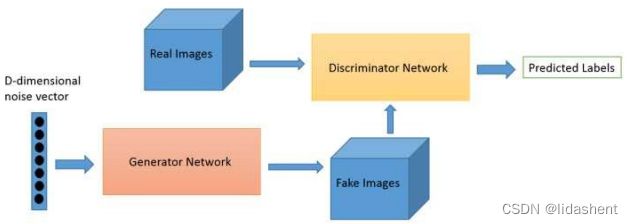
GANS
真实图像和生成器生成的噪声图像被送入判别网络,随着判别网络的判别结果,对生成器生成参数进行优化,直至生成器生成的图像以假乱真
判别器网络只负责判别真假,0,1
生成器网络相对复杂,它先生成一个高维正态分布噪声向量,然后经过xw+b映射到更高纬度排列成一个矩阵,使其符合图片格式,然后进行卷积,转置卷积,池化,激活函数等等,生成一张假图片送去鉴别,鉴别失败后继续更新生成参数
这个过程中判别器参数不会更新,因为这可能导致生成器无论生成什么图片都无法骗过鉴别器,直到生成器参数优化完毕,以假乱真
接下来依次实践这些编码器查看其实际效果如何
自动编码器
它的构成虽然简单,却是所有编码器的起始部分
接下来我们需要将一些图片的数据预先标准化,然后将其送入多层神经网络中训练,然后查看生成效果
图片数据集数据标准化
# 使用内置函数下载 mnist 数据集
train_set = mnist.MNIST('./data', train=True, download=False)
test_set = mnist.MNIST('./data', train=False, download=False)
im_tfs = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.5], [0.5]) # 标准化
])
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = mnist.MNIST('./data', train=True,transform=data_tf)
train_data = DataLoader(train_set, batch_size=128, shuffle=True)
a, a_label=next(iter(train_data))
print(a)
定义多层网络,设置参数优化器和loss优化器
# 定义网络
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 3) # 输出的 code 是 3 维,便于可视化
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Tanh()
)
def forward(self, x):
encode = self.encoder(x)
decode = self.decoder(encode)
return encode, decode
net = autoencoder()
x = Variable(torch.randn(1, 28*28)) # batch size 是 1
code, _ = net(x)
print(code.shape)
criterion = nn.MSELoss(size_average=False).cuda()
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
def to_img(x):
'''
定义一个函数将最后的结果转换回图片
'''
x = 0.5 * (x + 1.)
x = x.clamp(0, 1)
x = x.view(x.shape[0], 1, 28, 28)
return x
开始训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 开始训练自动编码器
print("开始训练")
for e in range(100):
print("第{}次".format(e))
for im, _ in train_data:
im = im.view(im.shape[0], -1)
im = Variable(im)
# 前向传播
_, output = net(im)
loss = criterion(output, im) / im.shape[0] # 平均
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e+1)%20 == 0: # 每 20 次,将生成的图片保存一下
print('epoch: {}, Loss: {:.4f}'.format(e + 1, loss.item()))
pic = to_img(output.cpu().data)
if not os.path.exists('./simple_autoencoder'):
os.mkdir('./simple_autoencoder')
save_image(pic, './simple_autoencoder/image_{}.png'.format(e + 1))
从原始数据集中读取一些数据,查看模型学习到的特征和效果如何,并将学习到的特征打上该特征的标签
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
# 可视化结果
view_data = Variable((train_set.train_data[:200].type(torch.FloatTensor).view(-1, 28*28) / 255. - 0.5) / 0.5)
encode, _ = net(view_data) # 提取压缩的特征值
fig = plt.figure(2)
ax = Axes3D(fig) # 3D 图
# x, y, z 的数据值
X = encode.data[:, 0].numpy()
Y = encode.data[:, 1].numpy()
Z = encode.data[:, 2].numpy()
values = train_set.train_labels[:200].numpy() # 标签值
for x, y, z, s in zip(X, Y, Z, values):
c = cm.rainbow(int(255*s/9)) # 上色
ax.text(x, y, z, s, backgroundcolor=c) # 标位子
ax.set_xlim(X.min(), X.max())
ax.set_ylim(Y.min(), Y.max())
ax.set_zlim(Z.min(), Z.max())
plt.show()
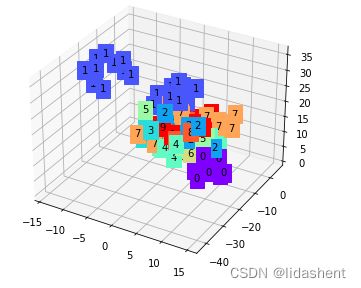
可以看到对于训练集中的数据,编码器学习到了一些特征,并完成了聚类
测试效果,随机生成一些图片
真的是随机,因为我们不知道隐含向量是什么,不过可以借此测试图像生成的如何
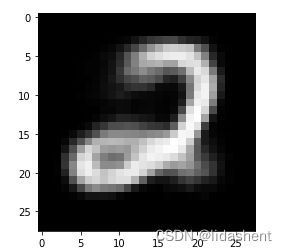
code = Variable(torch.FloatTensor([[1.79, 3.36, 2.06]])) # 给一个 code 是 (1.19, -3.36, 2.06)
decode = net.decoder(code)
decode_img = to_img(decode).squeeze()
decode_img = decode_img.data.numpy() * 255
plt.imshow(decode_img.astype('uint8'), cmap='gray') # 生成图片 3
当然,卷积神经网络对于图片识别效果更好,我们可以将多层神经网络替换为卷积网络
class conv_autoencoder(nn.Module):
def __init__(self):
super(conv_autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # (b, 16, 10, 10)
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # (b, 16, 5, 5)
nn.Conv2d(16, 8, 3, stride=2, padding=1), # (b, 8, 3, 3)
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # (b, 8, 2, 2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # (b, 16, 5, 5)
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # (b, 8, 15, 15)
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # (b, 1, 28, 28)
nn.Tanh()
)
def forward(self, x):
encode = self.encoder(x)
decode = self.decoder(encode)
return encode, decode
conv_net = conv_autoencoder()
if torch.cuda.is_available():
conv_net = conv_net.cuda()
optimizer = torch.optim.Adam(conv_net.parameters(), lr=1e-3, weight_decay=1e-5)
# 开始训练自动编码器
for e in range(40):
for im, _ in train_data:
if torch.cuda.is_available():
im = im.cuda()
im = Variable(im)
# 前向传播
_, output = conv_net(im)
loss = criterion(output, im) / im.shape[0] # 平均
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e+1) % 20 == 0: # 每 20 次,将生成的图片保存一下
print('epoch: {}, Loss: {:.4f}'.format(e+1, loss.item()))
pic = to_img(output.cpu().data)
if not os.path.exists('./conv_autoencoder'):
os.mkdir('./conv_autoencoder')
save_image(pic, './conv_autoencoder/image_{}.png'.format(e+1))
但是对于自动编码器来说,encode之后的编码如何分布如何画出指定的图像是无法解决的,图像由输入的向量决定,然而对于向量的特性依旧一无所知,因此接下来是变分自动编码器,它会将自动编码器输出的数据标准化,这样在生成指定图像时便具备了参考意义
变分自动编码器
其不同之处在于encoder输出的不再是随机的编码,而是均值和方差,我们可以利用这些均值和方差得到需要的数据图像
构建一个网络,然后查看初始的均值和方差参数
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20) # mean
self.fc22 = nn.Linear(400, 20) # var
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparametrize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
eps = torch.FloatTensor(std.size()).normal_()
if torch.cuda.is_available():
eps = Variable(eps.cuda())
else:
eps = Variable(eps)
return eps.mul(std).add_(mu)
def decode(self, z):
h3 = F.relu(self.fc3(z))
return F.tanh(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x) # 编码
z = self.reparametrize(mu, logvar) # 重新参数化成正态分布
return self.decode(z), mu, logvar # 解码,同时输出均值方差
net = VAE() # 实例化网络
if torch.cuda.is_available():
net = net.cuda()
x, _ = train_set[0]
x = x.view(x.shape[0], -1)
if torch.cuda.is_available():
x = x.cuda()
x = Variable(x)
_, mu, var = net(x)
print(mu)
计算loss函数,对目标图像和原始图像的像素点计算误差
reconstruction_function = nn.MSELoss(size_average=False)
def loss_function(recon_x, x, mu, logvar):
"""
recon_x: generating images
x: origin images
mu: latent mean
logvar: latent log variance
"""
MSE = reconstruction_function(recon_x, x)
# loss = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
KLD = torch.sum(KLD_element).mul_(-0.5)
# KL divergence
return MSE + KLD
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
def to_img(x):
'''
定义一个函数将最后的结果转换回图片
'''
x = 0.5 * (x + 1.)
x = x.clamp(0, 1)
x = x.view(x.shape[0], 1, 28, 28)
return x
训练
for e in range(100):
for im, _ in train_data:
im = im.view(im.shape[0], -1)
im = Variable(im)
if torch.cuda.is_available():
im = im.cuda()
optimizer.zero_grad()
recon_im, mu, logvar = net(im)
loss = loss_function(recon_im, im, mu, logvar) / im.shape[0] # 将 loss 平均
loss.backward()
optimizer.step()
if (e + 1) % 20 == 0:
print('epoch: {}, Loss: {:.4f}'.format(e + 1, loss.data[0]))
save = to_img(recon_im.cpu().data)
if not os.path.exists('./vae_img'):
os.mkdir('./vae_img')
save_image(save, './vae_img/image_{}.png'.format(e + 1))
其评判效果依旧是生成图片和目标图片的均方误差loss,这种评判方式并不能完全表示图片之间的相似度,因为像素点之间的差异和整体图片之间的差异是似是而非的
gans网络
gan是一种思想,目的在于让两个神经网络进行对抗,生成器和鉴别器,因此她有很多变体
变体改变的地方其实就是网络结构和loss函数
首先准备好数据,定义画图函数和数据取样函数,用于展示神经网络学习的结果和训练时数据取样
画图函数
def show_images(images): # 定义画图工具
images = np.reshape(images, [images.shape[0], -1])
sqrtn = int(np.ceil(np.sqrt(images.shape[0])))
sqrtimg = int(np.ceil(np.sqrt(images.shape[1])))
fig = plt.figure(figsize=(sqrtn, sqrtn))
gs = gridspec.GridSpec(sqrtn, sqrtn)
gs.update(wspace=0.05, hspace=0.05)
for i, img in enumerate(images):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(img.reshape([sqrtimg,sqrtimg]))
return
def preprocess_img(x):
x = tfs.ToTensor()(x)
return (x - 0.5) / 0.5
def deprocess_img(x):
return (x + 1.0) / 2.0
取样函数
class ChunkSampler(sampler.Sampler): # 定义一个取样的函数
"""Samples elements sequentially from some offset.
Arguments:
num_samples: # of desired datapoints
start: offset where we should start selecting from
"""
def __init__(self, num_samples, start=0):
self.num_samples = num_samples
self.start = start
def __iter__(self):
return iter(range(self.start, self.start + self.num_samples))
def __len__(self):
return self.num_samples
NUM_TRAIN = 50000
NUM_VAL = 5000
NOISE_DIM = 96
batch_size = 128
path=r"D:\PGMCode\Mycode\pythonCode\jupyterNoteBook\data"
train_set = MNIST(path, train=True, download=False, transform=preprocess_img)
train_data = DataLoader(train_set, batch_size=batch_size, sampler=ChunkSampler(NUM_TRAIN, 0))
val_set = MNIST(path, train=True, download=False, transform=preprocess_img)
val_data = DataLoader(val_set, batch_size=batch_size, sampler=ChunkSampler(NUM_VAL, NUM_TRAIN))
imgs = deprocess_img(next(train_data.__iter__())[0].view(batch_size, 784)).numpy().squeeze() # 可视化图片效果
show_images(imgs)
定义生成和判别神经网络,这里使用多层神经网络看看效果
def discriminator():
net = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1)
)
return net
def generator(noise_dim=NOISE_DIM):
net = nn.Sequential(
nn.Linear(noise_dim, 1024),
nn.ReLU(True),
nn.Linear(1024, 1024),
nn.ReLU(True),
nn.Linear(1024, 784),
nn.Tanh()
)
return net
然后定义loss函数,确定参数优化器优化方向
bce_loss = nn.BCEWithLogitsLoss()
def discriminator_loss(logits_real, logits_fake): # 判别器的 loss
size = logits_real.shape[0]
true_labels = Variable(torch.ones(size, 1)).float().cuda()
false_labels = Variable(torch.zeros(size, 1)).float().cuda()
loss = bce_loss(logits_real, true_labels) + bce_loss(logits_fake, false_labels)
return loss
def generator_loss(logits_fake): # 生成器的 loss
size = logits_fake.shape[0]
true_labels = Variable(torch.ones(size, 1)).float().cuda()
loss = bce_loss(logits_fake, true_labels)
return loss
# 使用 adam 来进行训练,学习率是 3e-4, beta1 是 0.5, beta2 是 0.999
def get_optimizer(net):
optimizer = torch.optim.Adam(net.parameters(), lr=3e-4, betas=(0.5, 0.999))
return optimizer
loss函数遵循如下数学公式
首先明白,对于判别器,需要完成真的数据DX判断为1,假的数据DGZ判断为0
![]()
对于生成器,需要让判别器认为所有的生成的假数据都为真1
![]()
它们都是二分类loss函数的变体
![]()
定义这个网络,然后训练一下看看实力
def train_a_gan(D_net, G_net, D_optimizer, G_optimizer, discriminator_loss, generator_loss, show_every=250,
noise_size=96, num_epochs=10):
iter_count = 0
for epoch in range(num_epochs):
for x, _ in train_data:
bs = x.shape[0]
# 判别网络
real_data = Variable(x).view(bs, -1).cuda() # 真实数据
logits_real = D_net(real_data) # 判别网络得分
sample_noise = (torch.rand(bs, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布
g_fake_seed = Variable(sample_noise).cuda()
fake_images = G_net(g_fake_seed) # 生成的假的数据
logits_fake = D_net(fake_images) # 判别网络得分
d_total_error = discriminator_loss(logits_real, logits_fake) # 判别器的 loss
D_optimizer.zero_grad()
d_total_error.backward()
D_optimizer.step() # 优化判别网络
# 生成网络
g_fake_seed = Variable(sample_noise).cuda()
fake_images = G_net(g_fake_seed) # 生成的假的数据
gen_logits_fake = D_net(fake_images)
g_error = generator_loss(gen_logits_fake) # 生成网络的 loss
G_optimizer.zero_grad()
g_error.backward()
G_optimizer.step() # 优化生成网络
if (iter_count % show_every == 0):
print('Iter: {}, D: {:.4}, G:{:.4}'.format(iter_count, d_total_error.item(), g_error.item()))
imgs_numpy = deprocess_img(fake_images.data.cpu().numpy())
show_images(imgs_numpy[0:16])
plt.show()
print()
iter_count += 1
D = discriminator().cuda()
G = generator().cuda()
D_optim = get_optimizer(D)
G_optim = get_optimizer(G)
train_a_gan(D, G, D_optim, G_optim, discriminator_loss, generator_loss)

模糊不清,初具效果,看来网络结构和loss函数设计的并不好,那么可以有两个优化方向,改善loss函数和改善网络结构
试试改善loss函数
Least Squares GAN
使用最小平方误差来分别计算生成器和判别器的loss
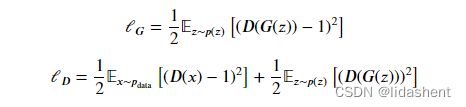
改变一下loss训练一下看看效果
def ls_discriminator_loss(scores_real, scores_fake):
loss = 0.5 * ((scores_real - 1) ** 2).mean() + 0.5 * (scores_fake ** 2).mean()
return loss
def ls_generator_loss(scores_fake):
loss = 0.5 * ((scores_fake - 1) ** 2).mean()
return loss
D = discriminator().cuda()
G = generator().cuda()
D_optim = get_optimizer(D)
G_optim = get_optimizer(G)
train_a_gan(D, G, D_optim, G_optim, ls_discriminator_loss, ls_generator_loss)

既然改善loss函数得到效果有改进但是差别不大,可以改变网络结构试试看,比如卷积网络对于图片就具备很强的识别能力
Deep Convolutional GANs
设计两个判别和生成卷积网络
class build_dc_classifier(nn.Module):
def __init__(self):
super(build_dc_classifier, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5, 1),
nn.LeakyReLU(0.01),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 5, 1),
nn.LeakyReLU(0.01),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(1024, 1024),
nn.LeakyReLU(0.01),
nn.Linear(1024, 1)
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
class build_dc_generator(nn.Module):
def __init__(self, noise_dim=NOISE_DIM):
super(build_dc_generator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(noise_dim, 1024),
nn.ReLU(True),
nn.BatchNorm1d(1024),
nn.Linear(1024, 7 * 7 * 128),
nn.ReLU(True),
nn.BatchNorm1d(7 * 7 * 128)
)
self.conv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, padding=1),
nn.ReLU(True),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 1, 4, 2, padding=1),
nn.Tanh()
)
def forward(self, x):
x = self.fc(x)
x = x.view(x.shape[0], 128, 7, 7) # reshape 通道是 128,大小是 7x7
x = self.conv(x)
return x
训练一下看看实力
def train_dc_gan(D_net, G_net, D_optimizer, G_optimizer, discriminator_loss, generator_loss, show_every=250,
noise_size=96, num_epochs=10):
iter_count = 0
for epoch in range(num_epochs):
for x, _ in train_data:
bs = x.shape[0]
# 判别网络
real_data = Variable(x).cuda() # 真实数据
logits_real = D_net(real_data) # 判别网络得分
sample_noise = (torch.rand(bs, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布
g_fake_seed = Variable(sample_noise).cuda()
fake_images = G_net(g_fake_seed) # 生成的假的数据
logits_fake = D_net(fake_images) # 判别网络得分
d_total_error = discriminator_loss(logits_real, logits_fake) # 判别器的 loss
D_optimizer.zero_grad()
d_total_error.backward()
D_optimizer.step() # 优化判别网络
# 生成网络
g_fake_seed = Variable(sample_noise).cuda()
fake_images = G_net(g_fake_seed) # 生成的假的数据
gen_logits_fake = D_net(fake_images)
g_error = generator_loss(gen_logits_fake) # 生成网络的 loss
G_optimizer.zero_grad()
g_error.backward()
G_optimizer.step() # 优化生成网络
if (iter_count % show_every == 0):
print('Iter: {}, D: {:.4}, G:{:.4}'.format(iter_count, d_total_error.data[0], g_error.data[0]))
imgs_numpy = deprocess_img(fake_images.data.cpu().numpy())
show_images(imgs_numpy[0:16])
plt.show()
print()
iter_count += 1
D_DC = build_dc_classifier().cuda()
G_DC = build_dc_generator().cuda()
D_DC_optim = get_optimizer(D_DC)
G_DC_optim = get_optimizer(G_DC)
train_dc_gan(D_DC, G_DC, D_DC_optim, G_DC_optim, discriminator_loss, generator_loss, num_epochs=5)

效果比之前好多了,这意味着gan思想是有效的,未来我们可以继续优化网络结构和loss函数来生成多种多样的数据,比如文本,图像,声音等等,这就是生成式人工智能