java数据结构(红黑树)set集合 HashSet HashSet三个问题 LinkedHashSetTreeSet TreeSet集合默认规则排序规则
目录
- 数据结构(红黑树)
-
- 红黑规则
- 红黑树添加结点规则
- set集合
- 小结
-
- HashSet
- HashSet三个问题
- LinkedHashSet
-
- 小结
- TreeSet
-
- TreeSet集合默认规则
- 排序规则(第一种排序方法)
- 方式二
-
- 练习
- 小练
- 总结
- 总结 集合的使用应该怎么选择
数据结构(红黑树)
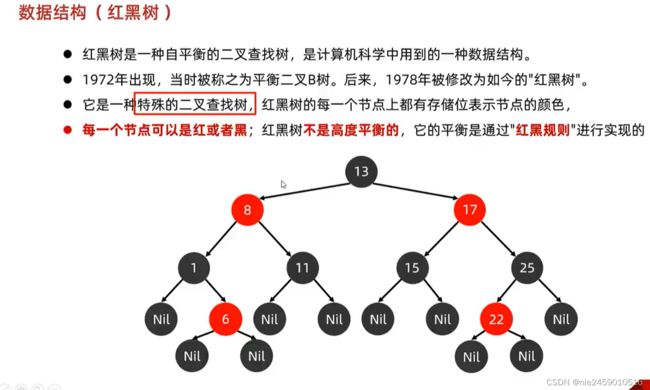

红黑规则
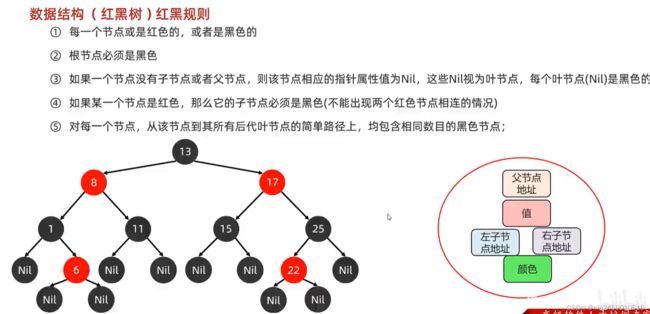
后代节点就是比如13根结点 13下面的8和17上的都是后代叶节点
简单路径就是比如随便一个13到8到11到nil就是一个简单路径.但是如果出现13到8然后再8回13再13到8这就不是简单路径了
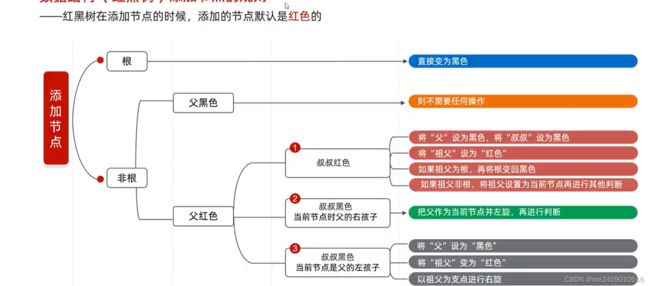
红黑树添加结点规则
set集合

public static void main(String[] args) {
Set<String>s=new HashSet<>();
s.add("张三");
s.add("李思");
s.add("王五");
s.add("老刘");
//添加元素不能重复 如果重复了打印无结果
//细节:add有返回值 会先判断这个元素添加过没有
//打印
Iterator<String> iterator = s.iterator();
while (iterator.hasNext()){
iterator.next();
}
System.out.println(s);//[张三, 李思, 王五, 老刘]
//增强for遍历
for (String s1 : s) {
System.out.print(s1);//张三李思王五老刘
}
System.out.print("________________");
//lambda表达式
s.forEach(new Consumer<String>() {
@Override
public void accept(String s2) {
System.out.print(s2);
}
});
//lambda简化
s.forEach(s3-> System.out.print(s3));
}
小结

简单记忆:hash:杂乱->无序;linked:链锁->有序;tree:树->可排序
HashSet


哈希值:对象的整数表现形式
哈希碰撞发生的概率特别小可以不计.
public static void main(String[] args) {
//创建对象
Student s1=new Student("张三",18);
Student s2=new Student("张三",18);
//System.out.println(s1.hashCode());//488970385
//System.out.println(s2.hashCode());//1209271652
//这是没有重写hash方法 不同对象计算出的哈希值不同
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
//24022538
//24022538
//重写了hash方法 不同对象只要属性值相同计算出的哈希值也相同
}
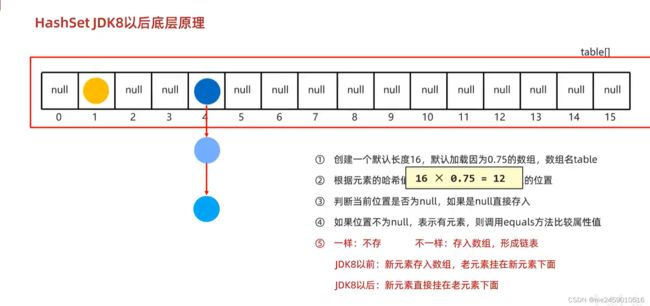
hash表保证元素统一的方法.当要添加一个新元素的时候,发现要添加的位置有元素而且是链表挂了两个,挨个进行equals进行比较,如果都不一样才会添加新的元素.如果比较第三个发现第三个一样,要添加的元素会舍弃不存
加载因子0.75就是扩容时机,以这个题为例,当数组存入16×0.75=12个元素的时候这个数组就会扩容至原先的两倍

当链表的长度过长大于8而且数组长度大于等于64当前链表会自动转化为红黑树
HashSet三个问题
HashSet为什么没有索引
因为底层的结构不唯一(就是有时候用链表存数据有时候用的红黑树),结构太多导致于确定索引比较困难,所以舍弃了索引机制
HashSet利用什么机制保证去重重写equals方法和Hash方法
HashSet为什么存和取的顺序不一样因为存入数据的时候可能会用到链表和红黑树的方式所以取的时候也是按照他们的规则存取的
HashSet添加元素的过程2、新元素排在老元素后面
LinkedHashSet
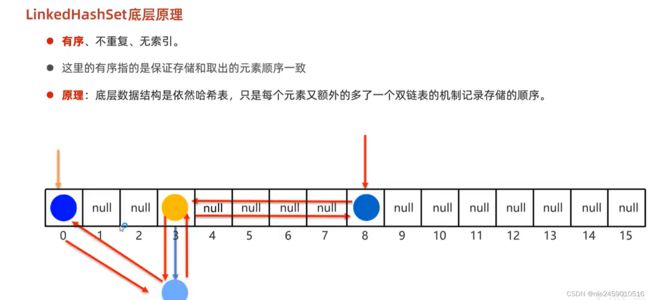
每一个元素都记录当前元素地址值和后一个元素的地址值所以说他是有序的
public static void main(String[] args) {
Student s1=new Student("张三",18);
Student s2=new Student("王五",13);
Student s3=new Student("李四",14);
Student s4=new Student("张三",18);
java.util.LinkedHashSet<Student>lhs=new java.util.LinkedHashSet<>();
System.out.println(lhs.add(s1));
System.out.println(lhs.add(s2));
System.out.println(lhs.add(s3));
System.out.println(lhs.add(s4));
System.out.println(lhs);
//true
//true
//true
//false
//[Student{name = 张三, age = 18}, Student{name = 王五, age = 13}, Student{name = 李四, age = 14}]
}
它可以保证数据的存取顺序
小结

TreeSet

public static void main(String[] args) {
//利用TreeSet存储整数并进行排序
java.util.TreeSet<Integer>ts=new java.util.TreeSet<>();
ts.add(2);
ts.add(1);
ts.add(3);
ts.add(4);
//打印集合
System.out.println(ts);//[1, 2, 3, 4]
//遍历集合
//迭代器
Iterator<Integer> it = ts.iterator();
while(it.hasNext()){
Integer i = it.next();
System.out.println(i);
}
System.out.println("_____________");
//增强for
for (Integer t : ts) {
System.out.println(t);
}
System.out.println("_____________");
//lambda
ts.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
});
}
TreeSet集合默认规则

排序规则挨个比较各个字母,如果出现一个比另外下面的大的后面就不用看了
排序规则(第一种排序方法)
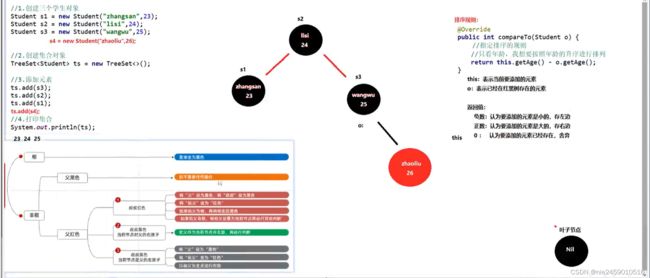

自定义对象如果未实现接口那么排序报错
实现接口需要自定义对象实现Comparable接口 接口下重写抽象方法compareTo方法 底层就是采用一个红黑树比较
方式二

练习
帮助理解什么时候使用第一种什么时候使用第二种
需求存入四个字符串 按照长度排序,如果一样长则按照首字母排序
String默认是按顺序排序但是不符合要求这时候就用到了第二种排序比较器排序
public static void main(String[] args) {
// 按照长度排序,如果一样长则按照首字母排序
TreeSet<String>ts=new TreeSet<>(new Comparator<String>() {
@Override
//o1表示当前要添加的元素
//o2表示已经在红黑树存在的元素
public int compare(String o1, String o2) {
//按照长度排序
int i=o1.length()-o2.length();
//如果长度相同则按照字母
i=i==0?o1.compareTo(o2):i;
//解读: i等于0吗如果等于o就是用默认的compare方法.如果不等于0那就是i
return i;
}
});
ts.add("c");
ts.add("ab");
ts.add("df");
ts.add("qwer");
System.out.println(ts);
//[ab, c, df, qwer]这是默认的排序方式使用的是compareTo
System.out.println(ts);//[c, ab, df, qwer]
//这是使用第二个排序方法后的到的
}
小练

@Override
public int compareTo(Student o) {
int sumO=o.getChineseGrade()+o.getMathGrade()+o.getEnglishGrade();
int totalScore=this.getChineseGrade()+this.getMathGrade()+getEnglishGrade();
//totalScore表示当前总分
//sumO表示o的总分
int i=totalScore-sumO;
i=i==0?this.chineseGrade-this.getChineseGrade():i;
//这句意思是如果总分一样 比较语文成绩
i=i==0?this.getMathGrade()-this.getMathGrade():i;
//如果语文成绩一样比较数学成绩
i=i==0?this.getEnglishGrade()-this.getEnglishGrade():i;
//如果数学成绩一样比较英语成绩
i=i==0?this.getAge()-this.getAge():i;
//如果英语成绩一样比较年龄
i=i==0?this.getName().compareTo(o.getName()):i;
//如果年龄一样按照名字字母排序
return i;
}
public static void main(String[] args) {
//首先创建五个学生对象
Student s1=new Student("zhangsan",13,60,70,80);
Student s2=new Student("lsii",15,63,79,68);
Student s3=new Student("wangwu",11,90,75,57);
Student s4=new Student("neifan",12,46,34,34);
Student s5=new Student("hebing",16,45,56,62);
//创建需要使用哪个集合这边采用TreeSet
TreeSet<Student>ts=new TreeSet<Student>();
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
//System.out.println(ts);
//选一个排序方式 这边采用第一种默认的
for (Student t : ts) {
System.out.println(t);
}
//Student{name = neifan, age = 12, chineseGrade = 46, mathGrade = 34, englishGrade = 34}
//Student{name = hebing, age = 16, chineseGrade = 45, mathGrade = 56, englishGrade = 62}
//Student{name = lsii, age = 15, chineseGrade = 63, mathGrade = 79, englishGrade = 68}
//Student{name = zhangsan, age = 13, chineseGrade = 60, mathGrade = 70, englishGrade = 80}
//Student{name = wangwu, age = 11, chineseGrade = 90, mathGrade = 75, englishGrade = 57}
}
总结

总结 集合的使用应该怎么选择
