NLP实战:Pytorch实现6大经典深度学习中文短文本分类-bert+ERNIE+bert_CNN+bert_RNN+bert_RCNN+bert_DPCNN
目录
- Introduction 导言
- 数据集
- Python环境及安装相应依赖包
-
- Anaconda环境配置
- 源代码地址
-
- 预训练语言模型下载
- 新建saved_dict文件夹
- Bert
-
- 模型说明
- ERNIE
-
- ERNIE 1.0
- ERNIE2.0
- ERNIE 3.0
- bert_CNN、bert_RNN、bert_RCNN、bert_DPCNN
-
- 模型说明
- 各模型效果对比
- 参考资料
- 其它资料下载
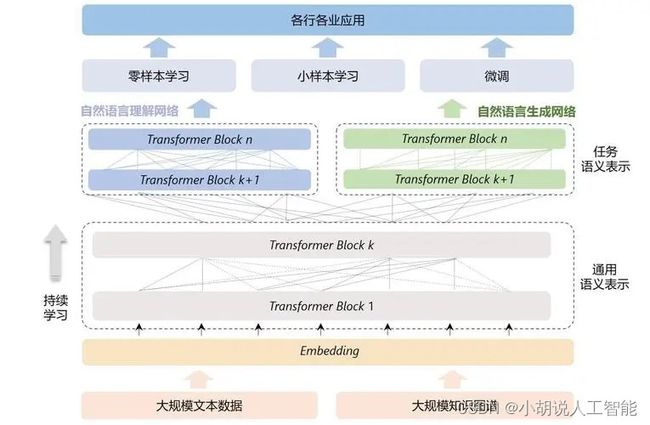
Introduction 导言
本文基于PyTorch框架,实现了6种经典的深度学习中文文本分类模型,这些模型包括基于Transformer模型的Bert和ERNIE,以及结合卷积神经网络、循环神经网络和深度金字塔卷积神经网络的bert_CNN、bert_RNN、bert_RCNN和bert_DPCNN,并对各模型进行了训练与结果比较。
首先,本文提供了详细的数据集说明,包括数据集来源、预处理方法和数据集划分方式。这样,读者可以了解数据集的特点,并按照说明准备和处理数据。
在环境搭建方面,我们提供了必要的依赖库和环境配置说明,以帮助读者顺利设置环境并运行项目。同时考虑到运行时间,也为大家提供了安装GPU版本的Pytorch的详细步骤。
对于每个模型,我们提供了详细的说明,包括模型结构、输入数据格式以及训练和推理过程。这些说明有助于读者理解每个模型的工作原理和实现细节。
最后,我们附上了训练和测试结果的详细报告。这些结果可帮助读者评估各模型在中文文本分类任务中的性能,并进行比较和分析。
通过本文,读者可以了解到各种深度学习中文文本分类模型的实现细节和性能表现。该项目不仅为学术研究者提供了参考,还为开发人员和实践者提供了可复用的代码和实验指南,助力他们在中文文本分类任务中取得更好的结果。
数据集
从THUCNews中抽取了20万条新闻标题,文本长度在20到30之间。一共10个类别,每类2万条。
以字为单位输入模型,使用了预训练词向量:搜狗新闻 Word+Character 300d。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集、词表及对应的预训练词向量,已经打包好,详见下面Github地址中THUCNews文件夹。


Python环境及安装相应依赖包
- python 3.7以上
- pytorch 1.1 以上
- tqdm
- sklearn
- tensorboardX
- boto3
- regex
Anaconda环境配置
-
登录Anaconda官网,下载并安装Anaconda
-
接着打开终端,依次输入下面终端命令:
新建环境:chinese_text_classification
conda create --name chinese_text_classification python==3.8.10
激活环境:
conda activate chinese_text_classification
依次输入下面命令安装相关python包
conda install pytorch
conda install scikit-learn
conda install tqdm
conda install tensorboardX
conda install boto3
conda install regex
注意上述安装的pytorch默认是CPU版本的。由于本文中的bert与ERNIE模型都使用了Transform相关模块,建议大家都安装GPU版本的pytorch。
如果要安装GPU版本的pytorch,可以参考下面步骤:
首先,确保你已经正确安装了NVIDIA显卡驱动程序,并且你的显卡支持CUDA。可以在NVIDIA官方网站上查找相应的驱动程序和CUDA兼容性信息。
在Python环境中安装PyTorch之前,你需要安装适用于你的CUDA版本的CUDAToolkit。可以通过NVIDIA的开发者网站下载并安装适合你的CUDA版本的CUDAToolkit。
完成上面步骤后,你可以使用下面命令,来查看你的GPU相关版本。
nvcc --version

如果没有上述版本的话,需要检查下是否安装好了CUDA 与 CUDAToolkit。
接着,可以在pytorch的下载网站上下载相应版本的whl进行安装,因为一般gpu版本的pytorch文件都很大,不太建议直接使用pip安装。比如下面就是直接使用pip安装gpu版本的pytorch命令,需要花费大概13个小时:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117

可以直接用浏览器打开上图中出现的下载网站:https://download.pytorch.org/whl/cu117 然后选择torch 接着搜索上图中的关键词cu117-cp38-cp38-win_amd64.whl。点击即可下载。一般网速快的话,大概10余分钟就可以下载成功。
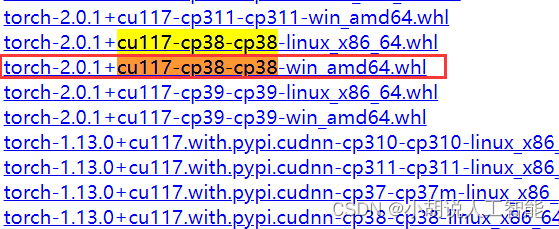
下载成功后,就可以直接使用下面命令进行安装:
pip install <path/to/your/whl/file.whl>
请将pip install /path/to/your/file.whl)
源代码地址
Github地址:https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch
预训练语言模型下载
由于bert和ERNIE都使用了预训练模型。在运行项目前,需下载相关预训练模型文件。
bert模型放在 bert_pretain目录下,ERNIE模型放在ERNIE_pretrain目录下,每个目录下都是三个文件:
- pytorch_model.bin
- bert_config.json
- vocab.txt
预训练模型下载地址:
bert_Chinese: 模型 https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz
词表 https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt
注意词表文件下载后,改名为vocab.txt
ERNIE_Chinese: 网盘地址:https://pan.baidu.com/s/1lEPdDN1-YQJmKEd_g9rLgw
解压后,按照上面说的放在对应目录下,文件名称确认无误即可。
新建saved_dict文件夹
需在THUCNews中新建一个名为saved_dict的文件夹,用于保存每次训练完的ckpt模型文件。
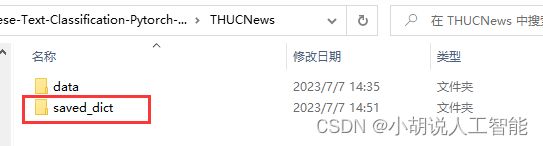
如果没新建,会出现下面错误:

Bert
BERT是2018年10月由Google AI研究院提出的一种预训练模型。BERT的全称是Bidirectional Encoder Representation from Transformers。BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
模型说明
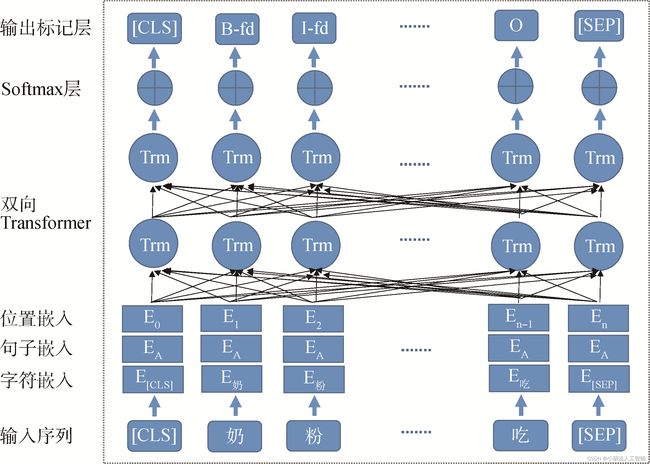
BERT 模型是基于 Transformer 的 Encoder(编码器),主要模型结构就是 Transformer 的堆叠。同时,Bert直接引用了Transformer架构中的Encoder模块,并舍弃了Decoder模块, 这样便自动拥有了双向编码能力和强大的特征提取能力,它是个双向的Transformer网络。某种意义上来说,BERT更加侧重语言的理解,而不仅仅是生成(Language Generation)。
在 BERT 中,输入的向量是由三种不同的 embedding 求和而成,分别是:
1)token embedding:单词本身的向量表示。token 是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。
2)position embedding:将单词的位置信息编码成特征向量。因为我们的网络结构没有RNN 或者LSTM,因此我们无法得到序列的位置信息,所以需要构建一个position embedding。构建position embedding有两种方法:BERT是初始化一个position embedding,然后通过训练将其学出来;而Transformer是通过制定规则来构建一个position embedding。
3)segment embedding:用于区分两个句子的向量表示。这个在问答等非对称句子中是用区别的。
在 BERT 中,输出是由四部分组成:
(1)last_hidden_state:shape 是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态(通常用于命名实体识别)。
(2)pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和 Tanh 激活函数进一步处理的(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)。
(3)hidden_states:这是输出的一个可选项,如果输出,需要指定 config.output_hidden_states=True,它也是一个元组,它的第一个元素是 embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)。
(4)attentions:这也是输出的一个可选项,如果输出,需要指定 config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算 self-attention heads 的加权平均值。
原理图如下:
优点:
Bert的基础建立在transformer之上,拥有强大的语言表征能力和特征提取能力。在11项 NLP基准测试任务中达到state of the art。同时再次证明了双向语言模型的能力更加强大。
缺点:
1)可复现性差,基本没法做,只能拿来主义直接用!
2)训练过程中因为每个batch_size中的数据只有15%参与预测,模型收敛较慢,需要强大的算力支撑!
# coding: UTF-8
import torch
import torch.nn as nn
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
终端运行下面命令,进行训练和测试:
python run.py --model Bert
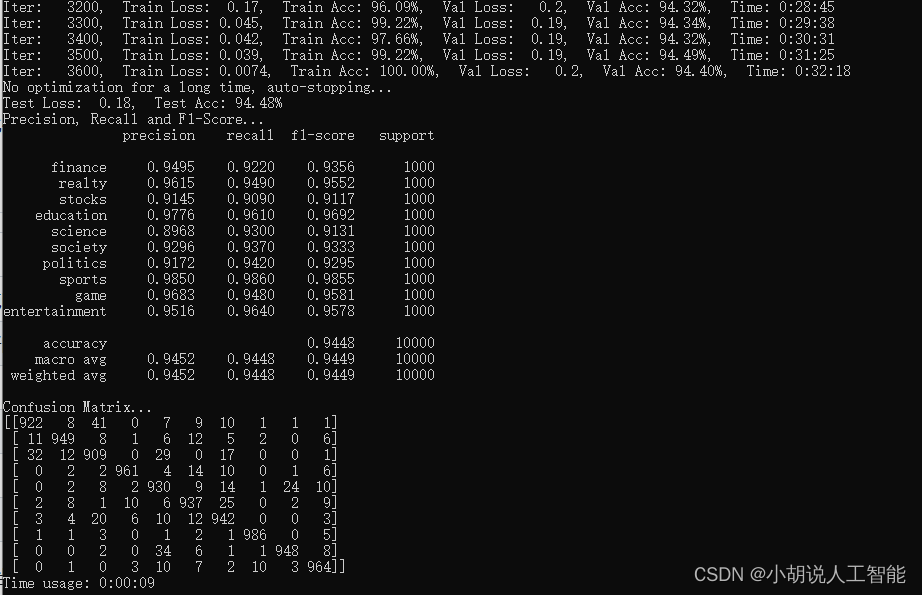
训练及测试结果如下:
使用GPU版本pytorch,耗时32分18秒,准确率94.48%
ERNIE
ERNIE(Enhanced Representation through Knowledge Integration)是百度提出的语义表示模型,同样基于Transformer Encoder。相较于BERT,其预训练过程利用了更丰富的语义知识和更多的语义任务,在多个NLP任务上取得了比BERT等模型更好的效果。
ERNIE 1.0
ERNIE 1.0是通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于BERT学习原始语言信号,ERNIE 1.0 可以直接对先验语义知识单元进行建模,增强了模型语义表示能力。
Bert模型的训练任务之一是掩码语言模型,它将单个的字(中文)、词(英文)进行随机mask标记后,去预测被mask的值。掩码语言模型使得Bert具有良好的效果,但同时巨大的缺陷是将句子的字与字或词与词之间的关系拆散了。
针对Bert模型的缺陷,ERNIE使用的掩码语言模型mask的不是单个的字或词,而是完整的词语、短语、命名实体。遮盖住后预测整体,从而使得语言模型能够训练出较好的全局信息,能够学习到非常先验的结果。
百度经过大量的训练,训练出效果较好的分词模型、短语拼接模型以及命名实体识别的模型,提前将语料中的词语进行标记。(在论文中这个思想称为:知识融合)
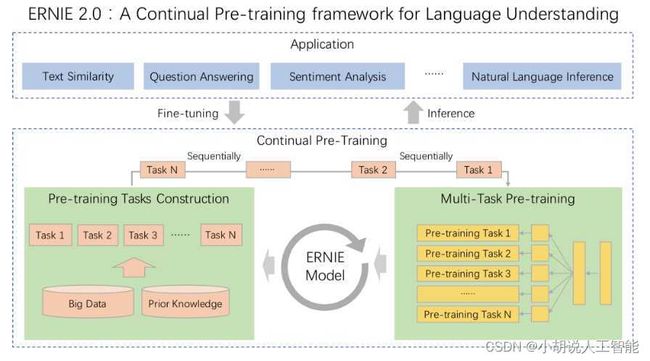
ERNIE2.0
ERNIE 2.0的主要思想: 不断学习预料中的不同层次的任务和知识,从而去增强ERNIE模型语义表示的建模能力。
ERNIE 2.0模型将四大部分作为输入,分别为:
1.Token embedding:词向量本身的embedding
2.Sentence embedding:句子类型的embedding
3.Position embedding:位置信息的embedding
4.Task embedding:任务embedding建模不同的任务
将四大embedding相加,最终的结果作为Transformer的输入,训练不同的子任务。子任务分为三类,分别为:
1.Word-aware Pre-training Task 词法层面的预训练任务;
2.Structure-aware Pre-training Task 结构层面的预训练任务;
3.Semantic-aware Pre-training Task 语义层面的预训练任务。
ERNIE 3.0
与ERNIE 2.0进行比较
- 相同点:
- 采用连续学习
- 采用了多个语义层级的预训练任务
- 不同点:
- ERNIE 3.0 Transformer-XL Encoder(自回归+自编码), ERNIE 2.0 Transformer Encoder(自编码)
- 预训练任务的细微差别,ERNIE3.0里增加的知识图谱
- ERNIE 3.0考虑到不同的预训练任务具有不同的高层语义,而共享着底层的语义(比如语法,词法等),为了充分地利用数据并且实现高效预训练,ERNIE 3.0中对采用了多任务训练中的常见做法,将不同的特征层分为了通用语义层(Universal Representation)和任务相关层(Task-specific Representation)。
对比ERNIE 与 Bert

ERNIE 2.0 原理图如下:
ERNIE 3.0 原理图如下:
# coding: UTF-8
import torch
import torch.nn as nn
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'ERNIE'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './ERNIE_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
print(self.tokenizer)
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
终端运行下面命令,进行训练和测试:
python run.py --model ERNIE
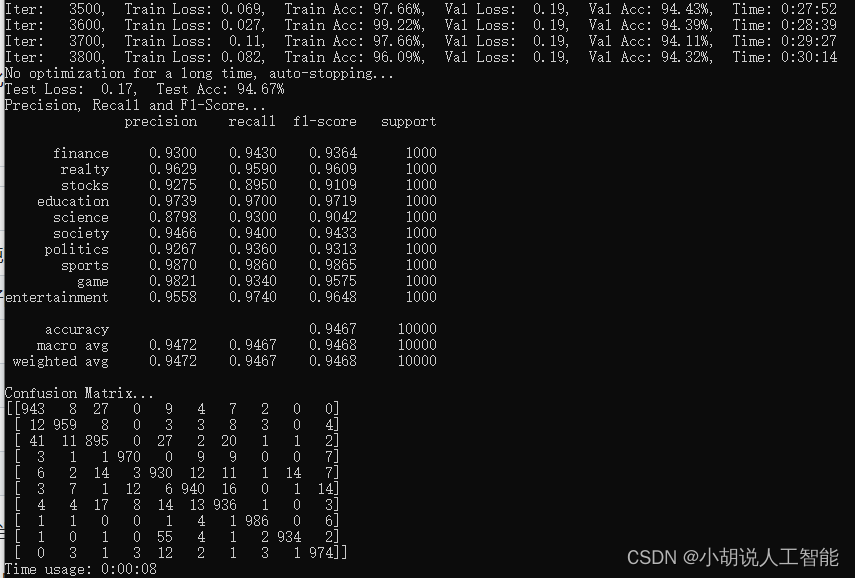
训练及测试结果如下:
使用GPU版本pytorch,耗时30分14秒,准确率94.67%
bert_CNN、bert_RNN、bert_RCNN、bert_DPCNN
模型说明
- bert_CNN:把bert当作embedding层送入CNN模型
- bert_RNN:把bert当作embedding层送入RNN模型
- bert_RCNN:把bert当作embedding层送入RCNN模型
- bert_DPCNN:把bert当作embedding层送入DPCNN模型
关于CNN、RNN、RCNN、DPCNN模型的详细说明和相关原理图,详见我另外一个博客:NLP实战:Pytorch实现7大经典深度学习中文文本分类-TextCNN+TextRNN+FastText+TextRCNN+TextRNN_Attention+DPCNN+Transformer
bert_CNN模型代码:
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
self.dropout = 0.1
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.hidden_size)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc_cnn = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = encoder_out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc_cnn(out)
return out
bert_RNN模型代码:
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
self.dropout = 0.1
self.rnn_hidden = 768
self.num_layers = 2
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm = nn.LSTM(config.hidden_size, config.rnn_hidden, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.dropout = nn.Dropout(config.dropout)
self.fc_rnn = nn.Linear(config.rnn_hidden * 2, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out, _ = self.lstm(encoder_out)
out = self.dropout(out)
out = self.fc_rnn(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
bert_RCNN模型代码:
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
self.dropout = 0.1
self.rnn_hidden = 256
self.num_layers = 2
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm = nn.LSTM(config.hidden_size, config.rnn_hidden, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.rnn_hidden * 2 + config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out, _ = self.lstm(encoder_out)
out = torch.cat((encoder_out, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).squeeze()
out = self.fc(out)
return out
bert_DPCNN模型代码:
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.num_filters = 250 # 卷积核数量(channels数)
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
# self.fc = nn.Linear(config.hidden_size, config.num_classes)
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.hidden_size), stride=1)
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1)
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
x = encoder_out.unsqueeze(1) # [batch_size, 1, seq_len, embed]
x = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
while x.size()[2] > 2:
x = self._block(x)
x = x.squeeze() # [batch_size, num_filters(250)]
x = self.fc(x)
return x
def _block(self, x):
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
x = x + px # short cut
return x
终端运行下面命令,进行训练和测试:
python run.py --model <模型名称>
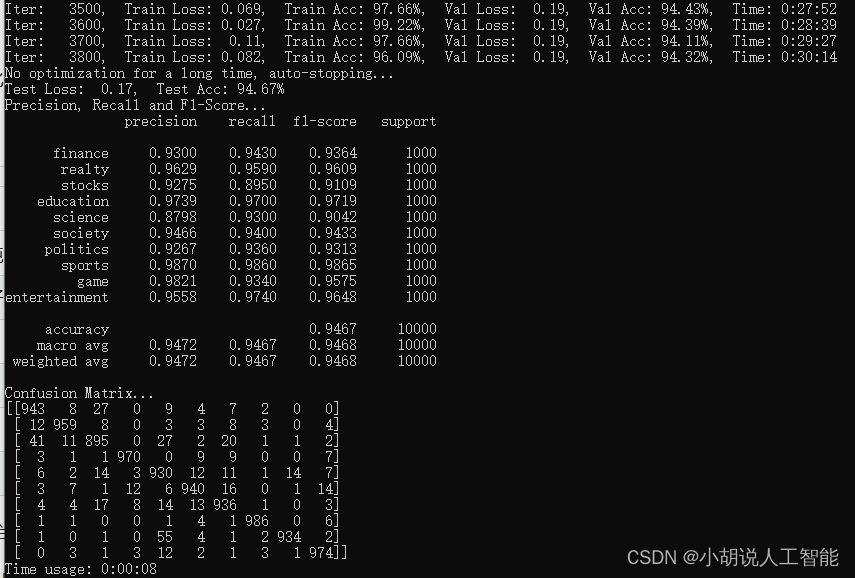
使用GPU版本pytorch,bert_CNN、bert_RNN、bert_RCNN、bert_DPCNN的训练及测试结果分别如下:
bert_CNN:
bert_RNN:
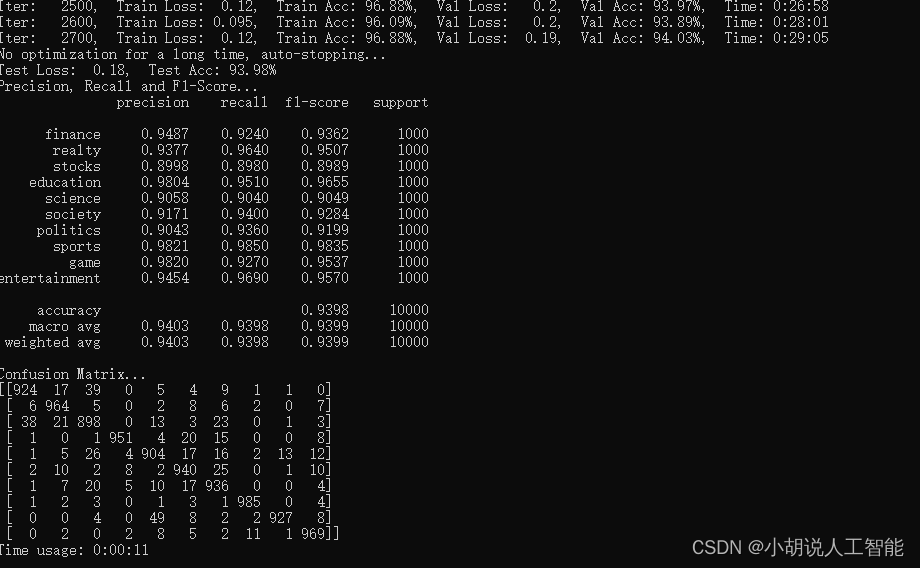
bert_RCNN:
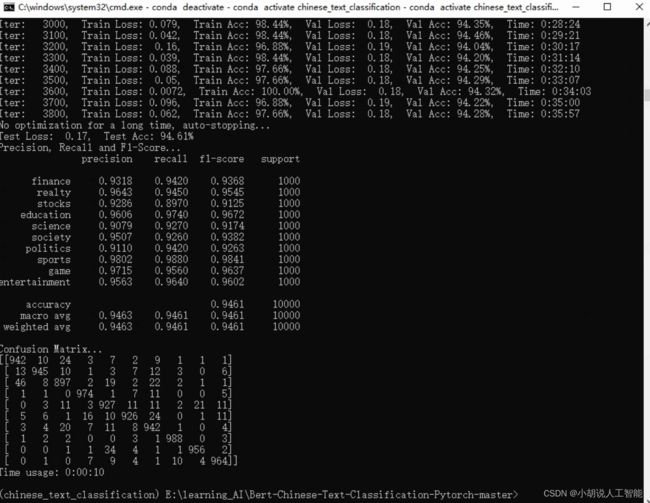
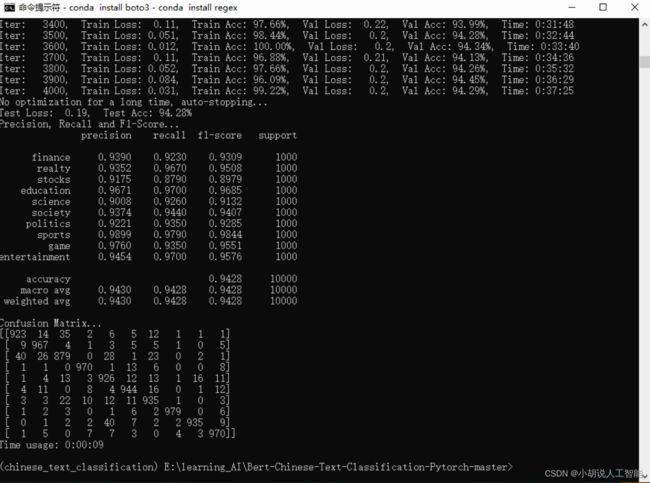
bert_DPCNN:
各模型效果对比
| 模型 | acc | 备注 |
|---|---|---|
| bert | 94.48% | bert + fc |
| ERNIE | 94.67% | 使用的是ERNIE 1.0,比bert略好(不像传闻中的中文碾压bert) |
| bert_CNN | 94.67% | bert+经典CNN文本分类 |
| bert_RNN | 93.98% | bert+BiLSTM |
| bert_RCNN | 94.61% | bert+BiLSTM+池化 |
| bert_DPCNN | 94.28% | bert+深层金字塔CNN |
参考资料
ERNIE 2.0 理解与使用
中文预训练大模型—文心Ernie技术原理
ERNIE3.0刷新50多个NLP任务基准!
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。