Spark Streaming
Spark Streaming
- Spark Streaming概念
- Spark Streaming操作
-
- 1 netcat传入数据
- 2 DStream 创建
- 3 自定义数据源
- 4 接受kafka数据
- DStream 转换
-
- 1无状态的转换
- 2有状态的转换
-
- updateSateByKey
- WindowOperations
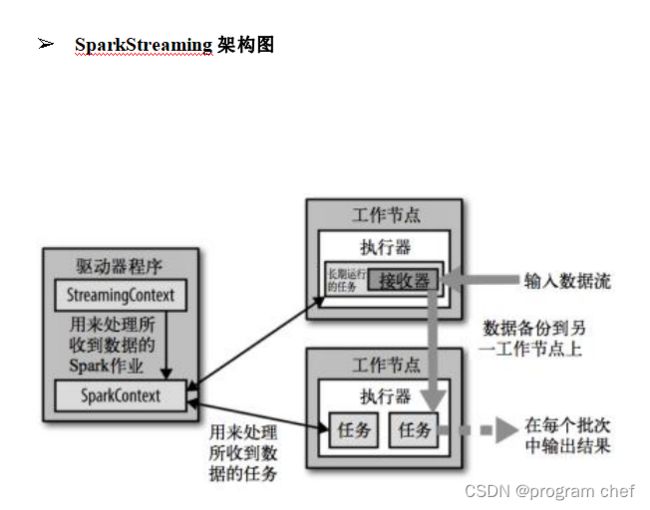
Spark Streaming概念
Spark Streaming 用于流式数据的处理。
Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flume 、Twitter 、ZeroMQ 和简单的 TCP 套接字等等。
数据输入后可以用 Spark 的高度抽象原语。如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。

Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作 DStream 。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收 到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此得名“离散化”)。所以 简单来将, DStream 就是对 RDD 在实时数据处理场景的一种封装。

Spark Streaming操作
1 netcat传入数据
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamWordCount {
def main(args:Array[String])={
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.通过监控端口创建 DStream,读进来的数据为一行行
val lineStreams = ssc.socketTextStream ("localhost", 9999)
//将每一行数据做切分, 形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print()
//启动 SparkStreamingContext
ssc.start ()
ssc.awaitTermination ()
}
}
链接: 配置netcat
下载netcat,解压到英文路径下。
将文件路径添加到环境变量中。
启动netcat。
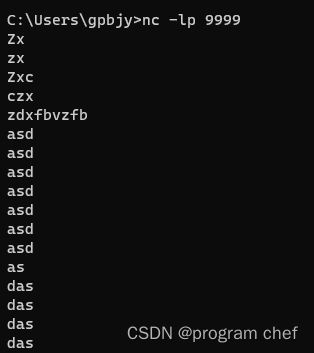
运行StreamWordCount 程序。
2 DStream 创建
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming02_Queue {
def main(args: Array[String]) {
//1.初始化 Spark 配置信息
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(conf, Seconds(4))
//3.创建 RDD 队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//4.创建 QueueInputDStream
val inputStream = ssc.queueStream(rddQueue,oneAtATime = false)
//5.处理队列中的 RDD 数据
val mappedStream = inputStream.map ((_,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//6.打印结果
reducedStream.print()
//7.启动任务
ssc.start()
//8.循环创建并向 RDD 队列中放入 RDD
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
3 自定义数据源
import java.util.Random
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming03_DIY {
def main(args: Array[String]) {
//1.初始化 Spark 配置信息
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
val ssc = new StreamingContext(conf, Seconds(3))
val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())
messageDS.print()
ssc.start()
ssc.awaitTermination()
}
/* 自定义数据采集器
1.继承Receiver,定义泛型,传递参数
2.重写方法
*/
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY){
private var flg =true
override def onStart(): Unit = {
new Thread(new Runnable {
override def run(): Unit = {
while(flg){
val message = "采集的数据为:" + new Random().nextInt(10).toString
store(message)
Thread.sleep(500)
}
}
}).start()
}
override def onStop(): Unit = {
flg=false;
}
}
}
4 接受kafka数据
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming04_kafka {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
val ssc = new StreamingContext(conf, Seconds(3))
//3.定义 Kafka 参数
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" ->"org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" ->"org.apache.kafka.common.serialization.StringDeserializer"
)
//4.读取 Kafka 数据创建 DStream
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe [String, String](Set("atguiguNew"), kafkaPara))
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}
DStream 转换
1无状态的转换
DStream 上的操作与 RDD 的类似,分为 Transformations (转换) 和 Output Operations (输 出)两种。
状态:DStream状态,每一次实时处理都要登录相关配置信息或是有一定初始状态。设置一个状态,这段时间在这个状态下设有一定的权限或记录着某种数值状态,方便后续处理。
//无状态数据操作,只对当前的采集周期内的数据进行处理
//在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming05_State {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
//无状态数据操作,只对当前的采集周期内的数据进行处理
//在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
val datas = ssc.socketTextStream("localhost",9999)
val wordToOne = datas.map((_,1))
val wordToCount = wordToOne.reduceByKey(_+_)
wordToCount.print()
ssc.start()
ssc.awaitTermination()
}
}
转换结构使用了reduceByKey,会直接出结果,不能和缓冲区的数据进行汇总。
val wordToCount = wordToOne.reduceByKey(+)
updateSateByKey:根据key对数据的状态进行更新
传递的参数中含有两个值
第一个值表示相同的key的value数据
第二个值表示缓冲区相同key的value数据
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming05_State {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming2")
val ssc = new StreamingContext(sparkConf, Seconds(3))
//无状态数据操作,只对当前的采集周期内的数据进行处理
//在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
val datas = ssc.socketTextStream("localhost",9999)
val wordToOne = datas.map((_,1))
// val wordToCount = wordToOne.reduceByKey(_+_)
// updateSateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值
// 第一个值表示相同的key的value数据
// 第二个值表示缓冲区相同key的value数据
val state = wordToOne updateStateByKey (
(seq:Seq[Int], buff:Option[Int] ) => {
val newCount = buff.getOrElse(0) + seq.sum
Option(newCount)
}
)
state.print()
ssc.start()
ssc.awaitTermination()
}
}
23/10/10 15:26:41 ERROR StreamingContext: Error starting the context, marking it as stopped
java.lang.IllegalArgumentException: requirement failed: The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
Exception in thread "main" java.lang.IllegalArgumentException: requirement failed: The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
这个错误是由于未设置 Spark Streaming 的检查点目录导致的。检查点目录用于存储 Spark Streaming 的元数据和中间状态信息,以便在故障恢复时保持一致性。
要解决这个问题,你需要在创建 StreamingContext 对象之前通过 checkpoint 方法设置检查点目录。
设置一个检查点就好了,填写对应的检查点路径。
ssc.checkpoint(“input”)
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming05_State {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming2")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("input")
//无状态数据操作,只对当前的采集周期内的数据进行处理
//在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
val datas = ssc.socketTextStream("localhost",9999)
val wordToOne = datas.map((_,1))
// val wordToCount = wordToOne.reduceByKey(_+_)
// updateSateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值
// 第一个值表示相同的key的value数据
// 第二个值表示缓冲区相同key的value数据
val state = wordToOne updateStateByKey (
(seq:Seq[Int], buff:Option[Int] ) => {
val newCount = buff.getOrElse(0) + seq.sum
Option(newCount)
}
)
state.print()
ssc.start()
ssc.awaitTermination()
}
}
Transform
Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在 DStream 的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也
就是对 DStream 中的 RDD 应用转换。
使用Transform 的两个原因:
Transform 可以将底层RDD获取到后进行操作。
1.DStream功能不完善
2.需要RDD/代码周期性的执行
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming06_State_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming2")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost",port=9999)
//transform方法可以将底层RDD获取到后 进行操作
val newDs: DStream[String] = lines.transform(
rdd => {
//code:Driver端,(周期性执行)
rdd.map(
str=>{
//Code : Executor端
str
}
)
}
)
val newDs1: DStream[String] = lines.map(
data=>{
data
}
)
ssc.start()
ssc.awaitTermination()
}
}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming2")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val data9999 = ssc.socketTextStream("localhost",port=9999)
val data8888 = ssc.socketTextStream("localhost",port=8888)
val map9999: DStream[(String, Int)] = data9999.map((_, 9))
val map8888: DStream[(String, Int)] = data8888.map((_, 8))
//join操作就是两个RDD的join操作
val joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888)
joinDS.print()
ssc.start()
ssc.awaitTermination()
}
}
2有状态的转换
updateSateByKey
updateSateByKey:根据key对数据的状态进行更新
传递的参数中含有两个值
第一个值表示相同的key的value数据
第二个值表示缓冲区相同key的value数据
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming05_State {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming2")
val ssc = new StreamingContext(sparkConf, Seconds(3))
//无状态数据操作,只对当前的采集周期内的数据进行处理
//在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
val datas = ssc.socketTextStream("localhost",9999)
val wordToOne = datas.map((_,1))
// val wordToCount = wordToOne.reduceByKey(_+_)
// updateSateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值
// 第一个值表示相同的key的value数据
// 第二个值表示缓冲区相同key的value数据
val state = wordToOne updateStateByKey (
(seq:Seq[Int], buff:Option[Int] ) => {
val newCount = buff.getOrElse(0) + seq.sum
Option(newCount)
}
)
state.print()
ssc.start()
ssc.awaitTermination()
}
}
WindowOperations
// An highlighted block
var foo = 'bar';