sql 字符串函数
Maxcompute odps sql 字符串函数

1.CHAR_MATCHCOUNT
BIGINT CHAR_MATCHCOUNT(STRING str1, STRING str2)
--计算str1中有多少个字符出现在str2中
CHAR_MATCHCOUNT('abd','aabc') = 2
-- str1中的两个字符串'a'和'b'出现在str2中。
2.CHR
STRING CHR(BIGINT ascii)
--将指定ASCII码ascii转换成字符
3.CONCAT
STRING CONCAT(STRING a, STRING b...)
--将参数中的所有字符串连接在一起
CONCAT('ab','c') = 'abc'
CONCAT() = NULL
CONCAT('a', null, 'b') = NULL
4.GET_JSON_OBJECT
STRING GET_JSON_OBJECT(STRING json,STRING path)
--转换JSON格式日志数据
SELECT GET_JSON_OBJECT(src_json.json, '$.owner') FROM src_json;
5.INSTR
BIGINT INSTR(STRING str1, STRING str2[, BIGINT start_position[, BIGINT nth_appearance]])
--用于计算子串str2在字符串str1中的位置
INSTR('Tech on the net', 'e') = 2
INSTR('Tech on the net', 'e', 1, 1) = 2
INSTR('Tech on the net', 'e', 1, 2) = 11
INSTR('Tech on the net', 'e', 1, 3) = 14
6.IS_ENCODING
BOOLEAN IS_ENCODING(STRING str, STRING from_encoding, STRING to_encoding)
--用于判断输入字符串str是否可以从指定的一个字符集from_encoding转为另一个字符集to_encoding。也可以用于判断输入是否为乱码,通常您可以将from_encoding设为UTF-8,to_encoding设为GB
IS_ENCODING('测试', 'utf-8', 'gbk') = true
IS_ENCODING('測試', 'utf-8', 'gbk') = true
-- GBK字库中有这两个繁体字。
IS_ENCODING('測試', 'utf-8', 'gb2312') = false
-- GB2312字库中不包括这两个字。
7.KEYVALUE
KEYVALUE(STRING srcStr,STRING split1,STRING split2, STRING key)
KEYVALUE(STRING srcStr,STRING key) //split1 = ";",split2 = ":"
--将srcStr(源字符串)按split1分成Key-Value对,并按split2将Key-Value对分开,返回key所对应的Value
8.LENGTH
BIGINT LENGTH(STRING str)
--返回字符串str的长度
LENGTH('hi! 中国') = 6
9.LENGTHB
BIGINT LENGTHB(STRING str)
--返回字符串str的以字节为单位的长度
LENGTHB('hi! 中国') = 10
10.MD5
STRING MD5(STRING value)
--计算输入字符串value的MD5值
11.REGEXP_EXTRACT
STRING REGEXP_EXTRACT(STRING source, STRING pattern[, BIGINT occurrence])
--将字符串source按照pattern正则表达式的规则拆分,返回第occurrence个group的字符。
regexp_extract('foothebar', 'foo(.*?)(bar)', 1) = the
regexp_extract('foothebar', 'foo(.*?)(bar)', 2) = bar
regexp_extract('foothebar', 'foo(.*?)(bar)', 0) = foothebar
regexp_extract("阿里巴巴", "([\\x{4e00}-\\x{9fa5}]+)", 1) = 阿里巴巴
regexp_extract('8d99d8', '8d(\\d+)d8') = 99
-- 如果是在MaxCompute客户端上提交正则计算的SQL,需要使用两个"\"作为转义字符。
regexp_extract('foothebar', 'foothebar')
-- 异常返回,pattern中没有指定group。
12.REGEXP_INSTR
BIGINT REGEXP_INSTR(STRING source, STRING pattern[,
BIGINT start_position[, BIGINT nth_occurrence[, BIGINT return_option]]])
--返回字符串source从start_position开始,与pattern第n次(nth_occurrence)匹配的子串的起始、结束位置。
REGEXP_INSTR("i love www.taobao.com", "o[[:alpha:]]{1}", 3, 2) = 14
13.REGEXP_REPLACE
STRING REGEXP_REPLACE(STRING source, STRING pattern, STRING replace_string[, BIGINT occurrence])
-将source字符串中第occurrence次匹配pattern的子串替换成指定字符串replace_STRING后返回结果字符串。
REGEXP_REPLACE("123.456.7890", "([[:digit:]]{3})\\.([[:digit:]]{3})\\.([[:digit:]]{4})",
"(\\1)\\2-\\3", 0) = "(123)456-7890"
REGEXP_REPLACE("abcd", "(.)", "\\1 ", 0) = "a b c d "
REGEXP_REPLACE("abcd", "(.)", "\\1 ", 1) = "a bcd"
REGEXP_REPLACE("abcd", "(.)", "\\2", 1) = "abcd"
-- 因为pattern中只定义了一个组,引用的第二个组不存在。
-- 请避免这样使用,引用不存在的组的结果未定义。
REGEXP_REPLACE("abcd", "(.*)(.)$", "\\2", 0) = "d"
REGEXP_REPLACE("abcd", "a", "\\1", 0) = "bcd"
-- 因为在pattern中没有组的定义,所以\1引用了不存在的组,
-- 请避免这样使用,引用不存在的组的结果未定义。
14.REGEXP_SUBSTR
STRING REGEXP_SUBSTR(STRING source, STRING pattern[, BIGINT start_position[, BIGINT nth_occurrence]])
--从start_position位置开始,source中第nth_occurrence次匹配指定模式pattern的子串。
REGEXP_SUBSTR("I love aliyun very much", "a[[:alpha:]]{5}") = "aliyun"
REGEXP_SUBSTR('I have 2 apples and 100 bucks!', '[[:blank:]][[:alnum:]]*', 1, 1) = " have"
REGEXP_SUBSTR('I have 2 apples and 100 bucks!', '[[:blank:]][[:alnum:]]*', 1, 2) = " 2"
15.REGEXP_COUNT
BIGINT REGEXP_COUNT(STRING source, STRING pattern[, BIGINT start_position])
--计算source中从start_position开始,匹配指定模式pattern的子串的次数。
REGEXP_COUNT('abababc', 'a.c') = 1
REGEXP_COUNT('abcde', '[[:alpha:]]{2}', 3) = 1
16.SPLIT_PART
STRING SPLIT_PART(STRING str, STRING separator, BIGINT start[, BIGINT end])
--依照分隔符separator拆分字符串str,返回从第start部分到第end部分的子串(闭区间)。
SPLIT_PART('a,b,c,d', ',', 1) = 'a'
SPLIT_PART('a,b,c,d', ',', 1, 2) = 'a,b'
SPLIT_PART('a,b,c,d', ',', 10) = ''
17.SUBSTR
STRING SUBSTR(STRING str, BIGINT start_position[, BIGINT length])
--返回字符串str从start_position开始,长度为length的子串。
SUBSTR("abc", 2) = "bc"
SUBSTR("abc", 2, 1) = "b"
SUBSTR("abc",-2,2) = "bc"
SUBSTR("abc",-3) = "abc"
18.SUBSTRING
STRING SUBSTRING(STRING|BINARY str, INT start_position[, INT length])
--返回字符串str从start_position开始,长度为length的子串。
SUBSTRING('abc', 2) = 'bc'
SUBSTRING('abc', 2, 1) ='"b'
SUBSTRING('abc',-2,2) = 'bc'
SUBSTRING('abc',-3,2) = 'ab'
SUBSTRING(BIN(2345),2,3) = '001'
19.TOLOWER
STRING TOLOWER(STRING source)
--输出英文字符串source对应的小写字符串。
tolower("aBcd") = "abcd"
tolower("哈哈Cd") = "哈哈cd"
20.TOUPPER
STRING TOUPPER(STRING source)
--输出英文字符source串对应的大写字符串。
toupper("aBcd") = "ABCD"
toupper("哈哈Cd") = "哈哈CD"
21.TO_CHAR
STRING TO_CHAR(BOOLEAN value)
STRING TO_CHAR(BIGINT value)
STRING TO_CHAR(DOUBLE value)
STRING TO_CHAR(DECIMAL value)
--将BOOLEAN、BIGINT、DECIMAL或DOUBLE类型转为对应的STRING类型表示。
TO_CHAR(123) = '123'
TO_CHAR(true) = 'TRUE'
TO_CHAR(1.23) = '1.23'
TO_CHAR(null) = NULL
22.TRIM
STRING TRIM(STRING str)
--去除字符串str的左右空格。
23.LTRIM
STRING LTRIM(STRING str)
--去除字符串str的左边空格。
24.RTRIM
STRING RTRIM(STRING str)
--去除字符串str的右边空格。
25.REVERSE
STRING REVERSE(STRING str)
--返回倒序字符串。
26.REPEAT
STRING REPEAT(STRING str, BIGINT n)
--返回重复n次后的str字符串。
SELECT REPEAT('abc',5) FROM lxw_dual; --返回abcabcabcabcabc。
27.ASCII
BIGINT ASCII(STRING str)MaxCompute 2.0扩展函数
set odps.sql.type.system.odps2=true;
setproject odps.sql.type.system.odps2=true;
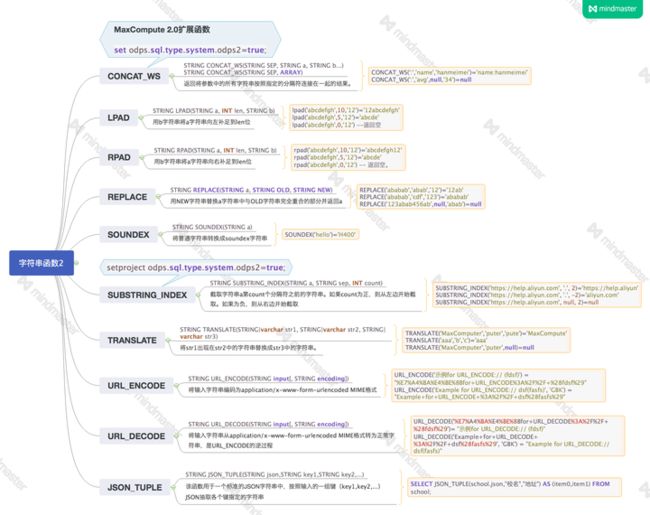
--MaxCompute 2.0扩展函数
--set odps.sql.type.system.odps2=true;
--setproject odps.sql.type.system.odps2=true;
28.CONCAT_WS
set odps.sql.type.system.odps2=true;
STRING CONCAT_WS(STRING SEP, STRING a, STRING b...)
STRING CONCAT_WS(STRING SEP, ARRAY)
--返回将参数中的所有字符串按照指定的分隔符连接在一起的结果。
CONCAT_WS(':','name','hanmeimei')='name:hanmeimei'
CONCAT_WS(':','avg',null,'34')=null
29.LPAD
STRING LPAD(STRING a, INT len, STRING b)
--用b字符串将a字符串向左补足到len位
lpad('abcdefgh',10,'12')='12abcdefgh'
lpad('abcdefgh',5,'12')='abcde'
lpad('abcdefgh',0,'12') --返回空
30.RPAD
STRING RPAD(STRING a, INT len, STRING b)
--用b字符串将a字符串向右补足到len位
rpad('abcdefgh',10,'12')='abcdefgh12'
rpad('abcdefgh',5,'12')='abcde'
rpad('abcdefgh',0,'12') -- 返回空。
31.REPLACE
STRING REPLACE(STRING a, STRING OLD, STRING NEW)
--用NEW字符串替换a字符串中与OLD字符串完全重合的部分并返回a
REPLACE('ababab','abab','12')='12ab'
REPLACE('ababab','cdf','123')='ababab'
REPLACE('123abab456ab',null,'abab')=null
32.SOUNDEX
STRING SOUNDEX(STRING a)
--将普通字符串转换成soundex字符串
SOUNDEX('hello')='H400'
33.SUBSTRING_INDEX
setproject odps.sql.type.system.odps2=true;
STRING SUBSTRING_INDEX(STRING a, STRING sep, INT count)
--截取字符串a第count个分隔符之前的字符串。如果count为正,则从左边开始截取。如果为负,则从右边开始截取
SUBSTRING_INDEX('https://help.aliyun.com', '.', 2)='https://help.aliyun'
SUBSTRING_INDEX('https://help.aliyun.com', '.', -2)='aliyun.com'
SUBSTRING_INDEX('https://help.aliyun.com', null, 2)=null
34.TRANSLATE
STRING TRANSLATE(STRING|varchar str1, STRING|varchar str2, STRING|varchar str3)
--将str1出现在str2中的字符串替换成str3中的字符串。
TRANSLATE('MaxComputer','puter','pute')='MaxCompute'
TRANSLATE('aaa','b','c')='aaa'
TRANSLATE('MaxComputer','puter',null)=null
35.URL_ENCODE
STRING URL_ENCODE(STRING input[, STRING encoding])
--将输入字符串编码为application/x-www-form-urlencoded MIME格式
URL_ENCODE('示例for URL_ENCODE:// (fdsf)') = "%E7%A4%BA%E4%BE%8Bfor+URL_ENCODE%3A%2F%2F+%28fdsf%29"
URL_ENCODE('Example for URL_ENCODE:// dsf(fasfs)', 'GBK') = "Example+for+URL_ENCODE+%3A%2F%2F+dsf%28fasfs%29"
36.URL_DECODE
STRING URL_DECODE(STRING input[, STRING encoding])
--将输入字符串从application/x-www-form-urlencoded MIME格式转为正常字符串,是URL_ENCODE的逆过程
URL_DECODE('%E7%A4%BA%E4%BE%8Bfor+URL_DECODE%3A%2F%2F+%28fdsf%29')= "示例for URL_DECODE:// (fdsf)"
URL_DECODE('Example+for+URL_DECODE+%3A%2F%2F+dsf%28fasfs%29', 'GBK') = "Example for URL_DECODE:// dsf(fasfs)"
37.JSON_TUPLE
STRING JSON_TUPLE(STRING json,STRING key1,STRING key2,...)
--该函数用于一个标准的JSON字符串中,按照输入的一组键(key1,key2,...)JSON抽取各个键指定的字符串
SELECT JSON_TUPLE(school.json,"校名","地址") AS (item0,item1) FROM school;