【Linux内核】内存管理——虚拟内存、分段、分页机制
转载请注明出处: https://www.cnblogs.com/Ethan-Code/p/16613018.html
虚拟内存
为什么要有虚拟内存?
- 让每个进程都有独立的内存空间,每个进程都有自己的私有页表,提供一个可以执行多进程的环境。
- 利用程序运行局部性原理,允许进程的内存空间超过物理内存大小。
- 页表中维护着页的权限属性,使内存访问更安全。
假如没有虚拟内存,则会有进程空间不隔离的问题,比如进程A会改写进程B的内容造成进程B崩溃。并且会有内存效率和内存不足的问题,物理内存有限,如果进程在休眠,不需要用的内存但是还是占用了物理内存,新的进程可能会因为内存不足而起不来。
物理内存到虚拟内存的映射工作是由 MMU(内存管理单元)这颗硬件实现的。倘若没有MMU,例如单片机上不存在虚拟内存,在上面跑多个程序,每个程序的内存空间不独立,谈若访问了同一个地址内容,会直接影响到其他程序的运行,造成程序崩溃。
所以才会出现这样的结论:
- 单片机上只能跑多线程,线程是调度的基本单位
- 要实现多进程环境还需要MMU加入提供虚拟内存环境,进程是资源分配的基本单位
内存分段
在没有分段时,内存的换入换出都是以整个进程内存空间为单位,非常的耗时并且对内存的利用率也不高。
内存分段下,程序是由若干个逻辑分段组成的,如可由代码段、数据段、栈段、堆段组成。
不同的段是有不同的属性的,所以就用分段(Segmentation)的形式把这些段分离出来。
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量。

- 段选择子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
- 虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
内存分段下的地址映射过程:
- 虚拟地址由段选择子和段偏移量组成
- 通过段选择子中的段号从段表中找到对应的段内描述符
- 段描述符里提供了段基址,加上虚拟地址上的段偏移量得到物理地址

不足之处:
- 产生外部内存碎片
- 内存交换的效率低
内存分页
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。
虚拟地址与物理地址之间通过页表来映射

页表是存储在内存里的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的工作。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
采用了分页,由于内存空间都是预先划分好的,页与页之间是紧密排列的,所以不会有外部碎片。
不足之处:
- 产生内部内存碎片
换入和换出:

分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。只有在程序运行中需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址。

对于一个内存地址转换的三个步骤:
- 把虚拟内存地址,切分成页号和偏移量;
- 根据页号,从页表里面,查询对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
多级页表
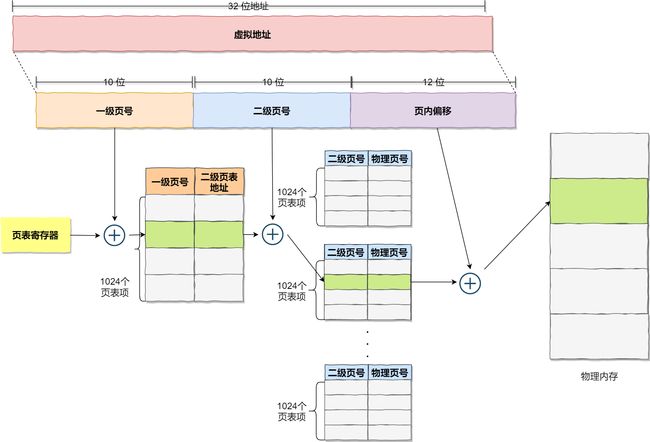
多级页表节约内存:页表要覆盖全部虚拟地址空间,不分级的页表就需要有 100 多万个页表项来映射,而二级分页则只需要 1024 个页表项。
举个具体的例子:VA代表虚拟地址,PA代表物理地址。
VA切分成3段
mmu_table[VA1][VA2] + VA3 = PA
等效做法
VA =0xC1203040;
VA1 = 0xC12;
VA2 = 0x03;
VA3 = 0x40;
mmu_table = 0x40004000 (PA);
mmu_table[0xC12] = ((u32*)0x40004000)[0xC12]
= 0x41224000 (PA);
mmu_table[0xC12][0x03] = ((u32*)0x41224000)[0x03]
= 0x42240000 (PA);
mmu_table[0xC12][0x03] + 0x40 = 0x42240040(PA);
对于 64 位的系统,两级分页肯定不够了,就变成了四级目录,分别是:

- 全局页目录项 PGD(Page Global Directory);
- 上层页目录项 PUD(Page Upper Directory);
- 中间页目录项 PMD(Page Middle Directory);
- 页表项 PTE(Page Table Entry);
页表缓存
CPU里有一个专门存放程序最常访问的页表项的 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为页表缓存、转址旁路缓存、快表。
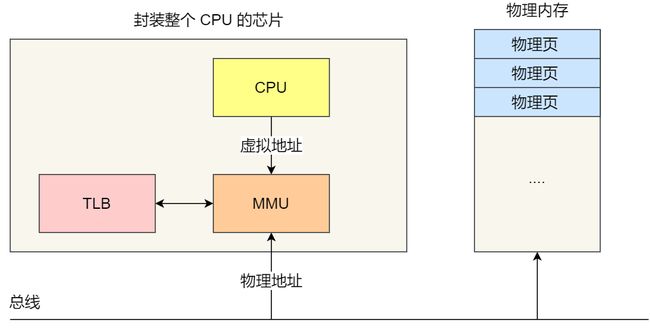
在 CPU 芯片里面,封装了内存管理单元(Memory Management Unit)芯片,它用来完成地址转换和 TLB 的访问与交互。
有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的页表。
段页式内存管理
先分段后分页,地址结构就由段号、段内页号和页内位移三部分组成。
用于段页式地址变换的数据结构是每一个程序一张段表,每个段又建立一张页表,段表中的地址是页表的起始地址,而页表中的地址则为某页的物理页号

段页式地址变换中要得到物理地址须经过三次内存访问:
- 第一次访问段表,得到页表起始地址;
- 第二次访问页表,得到物理页号;
- 第三次将物理页号与页内位移组合,得到物理地址。
用一下良许的图:
、
内存管理
Linux 操作系统中,虚拟地址空间被分为内核空间和用户空间两部分
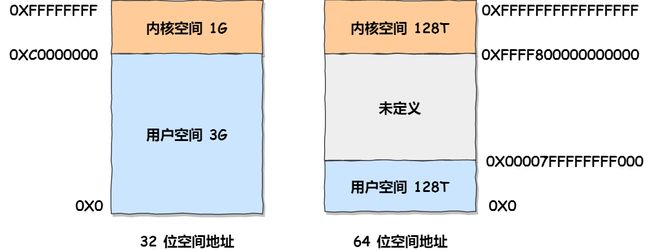
每个虚拟内存中的内核地址,其实关联的都是相同的物理内存

虚拟空间的划分情况
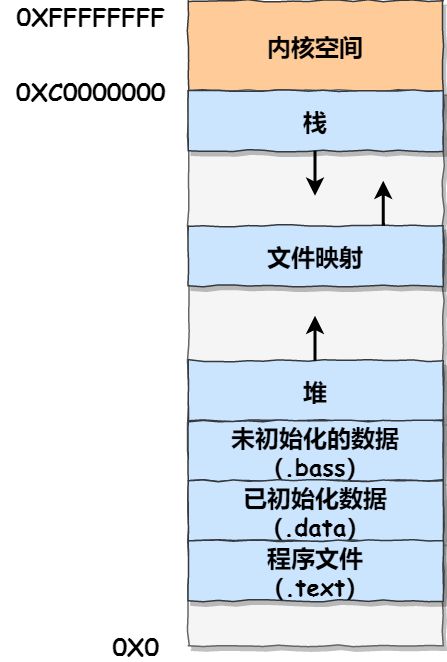
用户空间内存,从低到高分别是 6 种不同的内存段:
- 程序文件段(.text),包括二进制可执行代码;
- 已初始化数据段(.data),包括静态常量;
- 未初始化数据段(.bss),包括未初始化的静态变量;
- 堆段,包括动态分配的内存,从低地址开始向上增长;
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关 (opens new window));
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。当然系统也提供了参数,以便我们自定义大小;
堆 和 文件映射段 的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
好文推荐:图解操作系统