Spring Cloud Docke 项目性能优化
1.1 spring cloud框架
Spring Cloud从技术架构上降低了对大型系统构建的要求,使我们以非常低的成本(技术或者硬件)搭建一套高效、分布式、容错的平台。
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
微服务是可以独立部署、水平扩展、独立访问(或者有独立的数据库)的服务单元,springcloud就是这些微服务的大管家,采用了微服务这种架构之后,项目的数量会非常多,springcloud做为大管家需要管理好这些微服务,自然需要很多组件来帮忙。
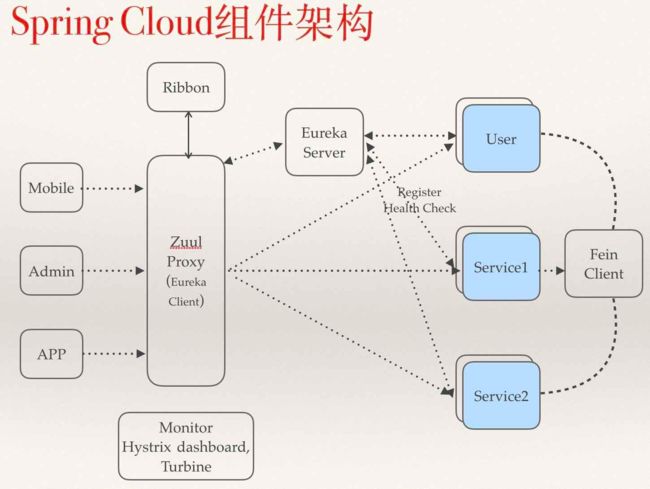
Spring Cloud 为开发人员提供了快速构建分布式系统中一些常见模式的工具,例如:
- 配置管理
- 服务注册与发现
- 断路器
- 智能路由
- 服务间调用
- 负载均衡
- 微代理
- 控制总线
- 一次性令牌
- 全局锁
- 领导选举
- 分布式会话
- 集群状态
- 分布式消息
-
- 项目中使用到的组件
-
Spring Cloud Netflix:针对多种Netflix组件提供的开发工具包,其中包括Eureka、Hystrix、Zuul等。
Netflix Eureka:云端负载均衡,一个基于 REST 的服务,用于定位服务,以实现云端的负载均衡和中间层服务器的故障转移。
Netflix Hystrix:容错管理工具,旨在通过控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。
Netflix Zuul:边缘服务工具,是提供动态路由,监控,弹性,安全等的边缘服务。
Spring Cloud Sleuth:日志收集工具包,封装了Dapper,Zipkin和HTrace操作。
1.1.2 和Spring Boot 是什么关系
Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是一个基于Spring Boot实现的云应用开发工具;Spring Boot专注于快速、方便集成的单个个体,Spring Cloud是关注全局的服务治理框架;Spring Boot使用了默认大于配置的理念,很多集成方案已经帮你选择好了,能不配置就不配置。
1.1.3 Spring Cloud的优势
微服务的框架那么多为什么就要使用Spring Cloud的呢?
※产出于spring大家族,spring在企业级开发框架中无人能敌,来头很大,可以保证后续的更新、完善。
※有Spring Boot 这个独立干将可以省很多事,大大小小的活Spring Boot都搞的挺不错。
※作为一个微服务治理的大家伙,考虑的很全面,几乎服务治理的方方面面都考虑到了,方便开发开箱即用。
※Spring Cloud 活跃度很高,教程很丰富,遇到问题很容易找到解决方案
轻轻松松几行代码就完成了熔断、均衡负载、服务中心的各种平台功能
Spring Cloud 是构建分布式系统的利器,而微服务是当下最火热的分布式系统的类型之一,所以,Spring Cloud 天然是支持微服务的构建的。
1.2 Docker容器
当我们把每个模块的功能微服务化后,会发现项目部署工作是非常头疼的一件事情。使用docker来管理我们项目的发布将会简单很多。
1.2.1 Docker简介
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源。
Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。
1.2.2 Docker 的优点
容器优势总结:
- 敏捷的应用创建与部署:相比虚拟机镜像,容器镜像的创建更简便、更高效。
- 持续的开发、集成,以及部署:在快速回滚下提供可靠、高频的容器镜像编译和部署(基于镜像的不可变性)。
- 开发与运维的关注点分离:由于容器镜像是在编译/发布期创建的,因此整个过程与基础架构解耦。
- 跨开发、测试、产品阶段的环境稳定性:在笔记本电脑上的运行结果和在云上完全一致。
- 在云平台与 OS 上分发的可转移性:可以在 Ubuntu、RHEL、CoreOS、预置系统、Google 容器引擎,乃至其它各类平台上运行。
- 以应用为核心的管理: 从在虚拟硬件上运行系统,到在利用逻辑资源的系统上运行程序,从而提升了系统的抽象层级。
- 松散耦联、分布式、弹性、无拘束的微服务:整个应用被分散为更小、更独立的模块,并且这些模块可以被动态地部署和管理,而不再是存储在大型的单用途机器上的臃肿的单一应用栈。
- 资源隔离:增加程序表现的可预见性。
- 资源利用率:高效且密集。
1.2.3 使用方式
(1)编写dockerfile文件
(2)mvn clean package命令打包
(3)docker build命令创建docker镜像
(4)docker run命令运行容器
1.3 Kubernetes
1.3.1 Kubernetes简介
Kubernetes 是一个自动化部署、伸缩和操作应用程序容器的开源平台。
使用 Kubernetes,你可以快速、高效地满足用户以下的需求:
- 快速精准地部署应用程序
- 即时伸缩你的应用程序
- 无缝展现新特征
- 限制硬件用量仅为所需资源
k8s是一个编排容器的工具,其实也是管理应用的全生命周期的一个工具,从创建应用,应用的部署,应用提供服务,扩容缩容应用,应用更新,都非常的方便,而且可以做到故障自愈,例如一个服务器挂了,可以自动将这个服务器上的服务调度到另外一个主机上进行运行,无需进行人工干涉。
k8s可以更快的更新新版本,打包应用,更新的时候可以做到不用中断服务,服务器故障不用停机,从开发环境到测试环境到生产环境的迁移极其方便,一个配置文件搞定,一次生成image,到处运行。
k8s的全生命周期管理
在k8s进行管理应用的时候,基本步骤是:创建集群,部署应用,发布应用,扩展应用,更新应用。
1.4 项目总体架构
1、总体技术架构:Spring Cloud + Docker + Kubernetes
2、数据访问层:JPA、Mybatis
3、业务层:spring + spring mvc + spring boot
4、数据库:mysql
5、前端:vue.js
2、xxx部署方式及运维手段:
2.1 安装部署顺序:
(1)安装CloudOS系统
(2)安装athena-package包
(3)去网站设置服务器IP和存储卷挂载信息
(4)部署nextcloud包
2.2运维相关:
- http://HOSTIP:5941 sleuth链路追踪平台, 查看请求调用链, 用于定位哪个服务出问题
- http://HOSTIP:59411/hystrix hystrix断路器监控平台,监控各个服务的流量和健康状态
- http://HOSTIP:58881/druid/ druid连接池:用户,角色数据库表监控平台
- Http://HOSTIP:58882/druid/ druid连接池:班级,学院,与用户的中间数据库表监控平台
- Matrix日志: /opt/matrix/extend/log/extend
nextcloud Athena-Homework-Service: 执行 shell脚本的时候产生的日志
extend_h3cloud_athena-package.tar.gz.xxx.log xxx部署日志
extend_h3cloud_nextcloud.tar.gz.xxx.log 网盘部署日志
- 命令:
| source /opt/bin/common/tool.sh |
导入k8s命令 |
| pod |
显示所有pod |
| kube logs –f (pod name) |
查看pod日志 |
| docker stats | grep 容器id |
查看docker容器的cpu和内存使用率以及IO |
| docker ps | grep athena-netdisk(服务名) |
查看容器id |
7 /opt/matrix/H3Cloud-component/tars/athena-fronted/ 前端代码/nginx配置文件
2并发优化
对于一个应用系统来说,一定会有极限并发/请求数,即总有一个TPS/QPS阈值,如果超了阈值,则系统就会不响应用户请求或者响应得特别慢,因此我们最好进行过载保护,以防止大量请求涌入击垮系统。
如果有的资源是稀缺资源(如数据库连接、线程),而且可能有多个系统都会去使用它,那么就需要加以限制。可以使用池化技术来限制总资源数,如连接池、线程池。超出的请求可以等待或者抛异常。
2.1 tomcat相关优化
2.1.1 tomcat连接相关参数
调整连接器connector的并发处理能力:
maxThreads :客户请求最大线程数,如果请求处理量一直远远大于最大线程数,则会引起响应变慢甚至会僵死。
minSpareThreads :Tomcat初始化时创建的 socket 线程数
maxSpareThreads: Tomcat连接器的最大空闲 socket 线程数
enableLookups :是否反查域名,取值为: true 或 false 。为了提高处理能力,应设置为 false
redirectPort: 在需要基于安全通道的场合,把客户请求转发到基于SSL 的 redirectPort 端口
acceptAccount: 监听端口队列最大数,满了之后客户请求会被拒绝(不能小于maxSpareThreads )
connectionTimeout: 连接超时
minProcessors: 服务器创建时的最小处理线程数
maxProcessors: 服务器同时最大处理线程数
URIEncoding: URL统一编码
maxConnections: 瞬时最大连接数,超出的会排队等待
2.1.2 在xxx项目中的应用
max-threds:500
max-connections:5000
2.2 http连接池
2.2.1使用http连接池的优点:
1.复用http连接,省去了tcp的3次握手和4次挥手的时间,极大降低请求响应的时间
2.自动管理tcp连接,不用人为地释放/创建连接
2.2.2使用http连接池的大致流程 :
1.创建PoolingHttpClientConnectionManager连接池管理器实例
2.给manager设置参数(最大连接数、单个路由最大连接数)
3.给manager设置重试策略
4.给manager设置连接管理策略(连接超时,socket超时)
5.开启监控线程,及时关闭被服务器单向断开的连接
6.构建HttpClient实例
7.创建HttpPost/HttpGet实例,并设置参数
8.获取响应,做适当的处理
9.将用完的连接放回连接池
2.2.3 在xxx项目的应用
1、对nextcloud官方提供的restful api的调用
2、应用内部服务之间feign调用
根据服务器和CPU配置和服务提供者的响应速度来调整http超时时间和并发请求数。
2.3 数据库连接池
2.3.1 数据库连接池的意义:
建立数据库连接是相当耗时和耗费资源的,而且一个数据库服务器能够同时建立的连接数也是有限的,在大型的Web应用中,可能同时会有成百上千个访问数据库的请求,如果Web应用程序为每一个客户请求分配一个数据库连接,将导致性能的急剧下降。为了能够重复利用数据库连接,提高对请求的响应时间和服务器的性能,可以采用连接池技术。连接池技术预先建立多个数据库连接对象,然后将连接对象保存到连接池中,当客户请求到来时,从池中取出一个连接对象为客户服务,当请求完成后,客户程序调用close()方法,将连接对象放回池中。
在普通的数据库访问程序中,客户程序得到的连接对象是物理连接,调用连接对象的close()方法将关闭连接,而采用连接池技术,客户程序得到的连接对象是连接池中物理连接的一个句柄,调用连接对象的close()方法,物理连接并没有关闭,数据源的实现只是删除了客户程序中的连接对象和池中的连接对象之间的联系。
2.3.2 Druid连接池的优势
Druid首先是一个数据库连接池,但它不仅仅是一个数据库连接池,它还包含一个ProxyDriver,一系列内置的JDBC组件库,一个SQLParser。Druid支持所有JDBC兼容的数据库,包括Oracle、MySql、Derby、Postgresql、SQLServer、H2等等。
Druid针对Oracle和MySql做了特别优化,比如Oracle的PSCache内存占用优化,MySql的ping检测优化。Druid在监控、可扩展性、稳定性和性能方面都有明显的优势。Druid提供了Filter-Chain模式的扩展API,可以自己编写Filter拦截JDBC中的任何方法,可以在上面做任何事情,比如说性能监控、SQL审计、用户名密码加密、日志等等。
2.3.3 在xxx项目的应用
(1)根据实际需要增大了最大数据库连接数配置。
(2)使用druid提供的界面,查看sql运行状态。
2.4 自定义线程池
根据任务类型和CPU线程数动态调整自定义线程池的大小。
因为网盘大部分操作都是IO密集型任务,因此,核心线程数设置得比较大,为CPU线程数*10。队列大小为1024。拒绝策略为抛出异常。
2.5 限流某个接口的总并发/请求数
如果接口可能会有突发访问情况,但又担心访问量太大造成崩溃,这时候就要限制这个接口的总并发/请求数了。
在xxx项目中,上传下载比较耗费磁盘IO,需要利用redis计数器限制上传下载请求的总并发数。
调用redisTemplate.opsForValue().increment(key, delta);实现计数。
2.6 使用缓存提升响应速度
使用业界使用最广泛的Redis缓存,同时便于分布式部署。
对于读多写少的场景,使用redis缓存,比如参数配置中的配置信息。
2.7 Java代码优化
2.7.1 使用CompletableFuture并行化&异步化
在Java8中,CompletableFuture提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,并且提供了函数式编程的能力,可以通过回调的方式处理计算结果,也提供了转换和组合 CompletableFuture 的方法。
在同一个方法中对多个接口的串行调用优化为异步并发调用,然后对结果合并处理,不阻塞主线程。
2.7.2 全面使用java8语法
3 内存优化
3.1 容器内存优化
在k8s配置文件中加入对容器内存的限制
3.2 JVM内存优化
根据服务器内存大小和服务运行繁忙程度调整jvm内存大小,在dockerfile中加入相关jvm参数
1、ParallelGCThreads参数修改
如果有多个JVM(或其他耗CPU的系统)在同一台机器上运行,我们应该使用-XX:ParallelGCThreads来减少垃圾收集线程数到一个适当的值。 例如,如果4个以服务器方式运行的JVM同时跑在在一个具有16核处理器的机器上,设置-XX:ParallelGCThreads=4是明智的,它能使不同JVM的垃圾收集器不会相互干扰
2、-Xmx -Xms MetaspaceSize 修改
显式制定jvm使用server模式:
JVM Server模式与client模式启动的差别?
最主要的差别在于:-Server模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升.原因是:
当虚拟机运行在-client模式的时候,使用的是一个代号为C1的轻量级编译器, 而-server模式启动的虚拟机采用相对重量级,代号为C2的编译器. C2比C1编译器编译的相对彻底,,服务起来之后,性能更高.
所以通常用于做服务器的时候我们用服务端模式,如果你的电脑只是运行一下java程序,就客户端模式就可以了。当然这些都是我们做程序优化程序才需要这些东西的,普通人并不关注这些专业的东西了。其实服务器模式即使编译更彻底,然后垃圾回收优化更好,这当然吃的内存要多点相对于客户端模式。
4隔离术
4.1 hystrix线程隔离
4.1.1 hystrix简述
使用Hystrix实现隔离分布式服务故障。提供线程和信号量隔离,以减少不同服务之间资源竞争带来的相互影响;提供优雅降级机制;提供熔断机制使得服务可以快速失败,而不是一直阻塞等待服务响应,并能从中快速恢复。Hystrix通过这些机制来阻止级联失败并保证系统弹性、可用。
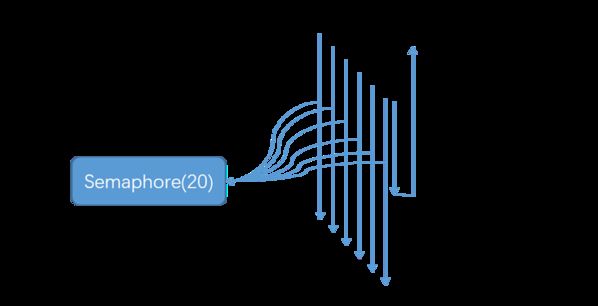
4.1.2 信号量隔离
信号量模式从始至终都只有请求线程自身,是同步调用模式,不支持超时调用,不支持直接熔断,由于没有线程的切换,开销非常小。
4.1.3 线程隔离
线程池模式可以支持异步调用,支持超时调用,支持直接熔断,存在线程切换,开销大。

4.1.4隔离方式选择
|
|
线程池隔离 |
信号量隔离 |
| 线程 |
与调用线程非相同线程 |
与调用线程相同(jetty线程) |
| 开销 |
排队、调度、上下文开销等 |
无线程切换,开销低 |
| 异步 |
支持 |
不支持 |
| 并发支持 |
支持(最大线程池大小) |
支持(最大信号量上限) |
当请求的服务网络开销比较大的时候,或者是请求比较耗时的时候,我们最好是使用线程隔离策略,这样的话,可以保证大量的tomcat线程可用,不会由于服务原因,一直处于阻塞或等待状态,快速失败返回。而当我们请求缓存这些服务的时候,我们可以使用信号量隔离策略,因为这类服务的返回通常会非常的快,不会占用容器线程太长时间,而且也减少了线程切换的一些开销,提高了缓存服务的效率。
4.2 Zuul网关线程隔离
zuul默认每个路由直接用信号量做隔离,并且默认值是100,也就是当一个路由请求的信号量高于100那么就拒绝服务了,返回500。
线程池提供了比信号量更好的隔离机制,并且从实际测试发现高吞吐场景下可以完成更多的请求。但是信号量隔离的开销更小,对于本身就是10ms以内的系统,信号量更合适。