java ll1文法分析_语法设计——基于LL(1)文法的预测分析表法
实验二、语法设计——基于LL(1)文法的预测分析表法
一、实验目的
通过实验教学,加深学生对所学的关于编译的理论知识的理解,增强学生对所学知识的综合应用能力,并通过实践达到对所学的知识进行验证。通过对基于LL(1)文法的预测分析表法DFA模拟程序实验,使学生掌握确定的自上而下的语法分析的实现技术,及具体实现方法。通过本实验加深对语词法分析程序的功能及实现方法的理解 。
二、实验环境
供Windows系统的PC机,可用C++/C#/Java等编程工具编写
三、实验内容
1、自己定义一个LL(1)文法
示例如(仅供参考) G[E]:E →TE' E' → +TE' | ε
T →FT' T' → *FT' | ε F → i | ( E )
2、构造其预测分析表,如

3、LL(1)文法的预测分析表的模型示意图
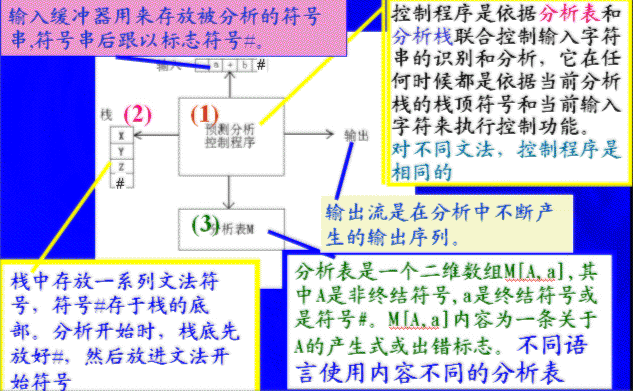
4、预测分析控制程序的算法流程

5、运行结果,示例如下

四、实验方式与要求
1、设计的下推自动机具有通用性,上机编程实现;
2、实验报告格式要求书写要点:概要设计(总体设计思想);详细设计(程序主流程、自动机的存储格式、关键函数的流程图);结果分析(输入与输出结果、存在问题及有待改进善的地方、实验心得);
3、实验报告限4页内。
设计思路:我就讲解一下核心部分代码,首先,进栈函数在 298 行处左右,我们用 ArrayList 去定义一个动态数组 analyzeProduces ,我们定义了一个栈 analyzeStatck ,而这个栈在我们在定义 Analyzer 类中初始化化过了,所以在创建 analyzeStatck 中首先会进行初始化操作, push 了一个 # ,所以analyzeStatck 栈中会存在 # 这个字符(以这个 # 作为标记),然后 302 行,我们向 analyzeStack 中推入开始符号,也就是我们在主函数设置的字符 E ,然后打印出开始符号以及一些格式要求(步骤,符号栈,输入串,产生式等等),设置 index 的值来记录走过的步骤次数 。
从 308 行开始,我们开始对栈进行分析。我们设置一个判断栈 analyzeStatck 是否为空,由前面可知,栈中存在 #E 两个字符,显然字符是非空的,通过 index++ 记录当前的步数,然后我们去通过 peek 函数去弹出当前栈顶元素的第一个字符,通过和剩余输入串 str 的第一个字符进行匹配。
如果栈顶元素与当前输入串的第一个字符不可以匹配,我们就去分析表 TextUtil 中利用函数 findUseExp 去找到这个产生式,而 findUseExp 函数我们通过去定义了一个哈希表去存储查找出来的栈顶元素,用一个集合 keySet 去存储哈希表的所有键值,通过 for 循环,利用定义一个红黑树 treeSet 去存取表达式,然后去进行匹配,如果在红黑树中包含了当前查找的字符,我们就返回当前从哈希表中所获取到的表达式。将当前所找到的产生式存入到 nowUseExpStr 中,打印出此时所进行到的步骤值,符号栈,输入栈,产生式。316 行,我们创建一个分析栈 produce 去记录上一步的值(位置,符号栈,输入串),判断当前的产生式是否为空,如果不为空,设置下当前分析栈的产生式,将整个分析栈加入到动态数组 analyzeProduces 中,再将之前的分析栈中的栈顶弹出,如果当前的表达式不为空且第一个字符不是空字符,我们再将需要用到的表达式进行反序入栈。
如果栈顶元素与当前输入串的第一个字符可以匹配,分析栈出栈,串去掉一位,创建一个新的分析栈 produce ,记录上一步的值(位置,符号栈,输入串),设置当前产生式为当前输入串的第一个字符可以匹配,将整个分析栈加入到动态数组 analyzeProduces 中,再将之前的分析栈中的栈顶弹出,将剩余的字符串记录在 str 字符串中。
注:produce 相当于是一个持久化存储中间参数的一个分析栈
实验代码如下:
package python;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
import java.util.TreeSet;
import java.util.Stack;
/**
* @author Angel_Kitty
* @createTime 2018年11月24日 上午0:46:33
*/
class TextUtil {
/**
* (3)B->aA,=Follow(B)
*
* @param nvSet
* @param itemCharStr
* @param a
* @param expressionMap
* @return
*/
public static boolean containsbA(TreeSet nvSet, String itemCharStr, Character a,
HashMap> expressionMap) {
String aStr = a.toString();
String lastStr = itemCharStr.substring(itemCharStr.length() - 1);
if (lastStr.equals(aStr)) {
return true;
}
return false;
}
/**
* 形如aBb,b=空
*
* @param nvSet
* @param itemCharStr
* @param a
* @param expressionMap
* @return
*/
public static boolean containsbAbIsNull(TreeSet nvSet, String itemCharStr, Character a,
HashMap> expressionMap) {
String aStr = a.toString();
if (containsAB(nvSet, itemCharStr, a)) {
Character alastChar = getAlastChar(itemCharStr, a);
System.out.println("----------------+++++++++++++++++++--" + expressionMap.toString());
ArrayList arrayList = expressionMap.get(alastChar);
if (arrayList.contains("ε")) {
System.out.println(alastChar + " contains('ε')" + aStr);
return true;
}
}
return false;
}
/**
* 是否包含这种的字符串
* (2)Ab,=First(b)-ε,直接添加终结符
*
* @param str
* @param a
* @return
*/
public static boolean containsAb(TreeSet ntSet, String itemCharStr, Character a) {
String aStr = a.toString();
if (itemCharStr.contains(aStr)) {
int aIndex = itemCharStr.indexOf(aStr);
String findStr;
try {
findStr = itemCharStr.substring(aIndex + 1, aIndex + 2);
} catch (Exception e) {
return false;
}
if (ntSet.contains(findStr.charAt(0))) {
return true;
} else {
return false;
}
} else {
return false;
}
}
/**
* 是否包含这种的字符串
* (2).2Ab,=First(b)-ε
*
* @param str
* @param a
* @return
*/
public static boolean containsAB(TreeSet nvSet, String itemCharStr, Character a) {
String aStr = a.toString();
if (itemCharStr.contains(aStr)) {
int aIndex = itemCharStr.indexOf(aStr);
String findStr;
try {
findStr = itemCharStr.substring(aIndex + 1, aIndex