草稿 Embedding-based Retrieval in Facebook Search
今天分享的是facebook发表在KDD2020上的推荐论文《Embedding-based Retrieval in Facebook Search》
1. 背景
不同于传统的网络搜索,社交网络上的检索问题不仅仅关注于query的文字信息,还要关注于个人的上下文信息。(例如在facebook场景中搜索“ John Smith”,在Facebook上可能有成千上万个名为“ John Smith”的用户个人资料,但用户使用查询“ John Smith”搜索的实际目标人很可能是他们的朋友或熟人。)
1. Boolean matching model 的整理
本篇文章给出了facebook关于embedding-based retrieval的实践方案。
2. 引言
一般来说,搜索主要包含检索和排序两个阶段。尽管 embedding 技术可以同时被应用在两个阶段,但相对来说应用在召回阶段可以发挥出更大的作用。简单来说,EBR 就是用 embedding 来表示 query 和 doc,然后将检索问题转化为一个在 Embedding 空间的最近邻搜索的问题。它要解决的问题是如何从千万个候选集中找到最相关的 topK 个,难点有如下的两个:
- 如何构建千万级别的超大规模索引以及如何在线上进行服务
- 如何在召回阶段同时考虑语义信息和关键词匹配信息
本文从三个方面详细讲述了在 Facebook 搜索中应用 Embedding 检索技术遇到的挑战及解决方案:
-
model :FaceBook提出了统一embedding,即典型的双塔结构,其中一侧包含查询文本、搜索者和上下文,另一侧则是抽取 document 的特征。 2. 双塔的梳理
-
serving :主要从两个方面研究hard mining,在retrieve和rank阶段都引入ensemble embedding
-
full-stack optimization :可以将embedding KNN和布尔匹配结合起来进行检索的框架,框架使得同时优化embedding和term匹配变得可行。
3. 模型
本文将搜索任务形式化为一个召回优化问题。对于一个搜索query,目标结果文档有 N N N个,记为 T = { t 1 , t 2 , . . . , t N } T = \left \{ t_{1},t_{2},...,t_{N} \right \} T={t1,t2,...,tN},模型返回的Top K K K个结果集合为 { d 1 , d 2 , . . . , d K } \left \{ d_{1},d_{2},...,d_{K} \right \} {d1,d2,...,dK},我们希望使top K K K的召回最大化:
r e c a l l @ K = ∑ i = 1 K d i ∈ T N recall@K=\frac{\sum_{i=1}^{K}d_{i}\in T}{N} recall@K=N∑i=1Kdi∈T
目标结果文档:基于确定标准且与给定查询相关的文档。 例如,它可能是由用户点击过的document,以及人工标注为与当前query相关的document。
因此召回即为:检索出的相关文档数 / 系统中的目标文档总数
召回优化等效为 基于 query 与 doc 距离的优化问题。我们将query和document通过神经网络来映射为稠密向量(即embedding model),将余弦相似度作为距离度量。用triplet loss作为损失函数。
3.1 评估指标
我们采样10000对搜索session作为评估集,并计算这10000个session的平均recall@K,即将Top K召回结果与用户实际点击做交集,然后计算precision/recall
3.2 损失函数
本文采用三元损失函数。 3. 三元损失函数 BPR loss
对于给定的query q ( i ) q^{(i)} q(i), d + ( i ) d_{+}^{(i)} d+(i) d − ( i ) d_{-}^{(i)} d−(i)分别是与之关联的正负样本document,三元损失函数为:
L = ∑ i = 1 N m a x ( 0 , D ( q ( i ) , d + ( i ) ) − D ( q ( i ) , d − ( i ) ) + m ) L=\sum_{i=1}^{N}max(0,D(q^{(i)},d_{+}^{(i)})-D(q^{(i)},d_{-}^{(i)})+m) L=i=1∑Nmax(0,D(q(i),d+(i))−D(q(i),d−(i))+m)
其中, D ( u , v ) D(u,v) D(u,v) 是 uv 之间的向量评估指标。 m m m是正负样本的margin,N是训练样本总数。当 D ( q ( i ) , d + ( i ) ) − D ( q ( i ) , d − ( i ) ) D(q^{(i)},d_{+}^{(i)})-D(q^{(i)},d_{-}^{(i)}) D(q(i),d+(i))−D(q(i),d−(i))大于margin后,对于loss的贡献减少为0。
If we sample n negatives for each one positive in the training data, the model will be optimizing for recall at top one position when the candidate pool size is n. Assuming the actual serving candidate pool size is N , we are approximately optimizing recall at top K ≈ N /n. In Section 2.4, we will verify this hypothesis and provide comparisons of different positive and negative label definitions.
3.3 统一嵌入模型
为了学习可以优化triplet loss 的embedding,模型有三大组件构成:
- query embedding E Q = f ( Q ) E_{Q} =f(Q) EQ=f(Q)
- document embedding E D = g ( Q ) E_{D} =g(Q) ED=g(Q)
- 相似度函数,在这里选择了余弦相似度函数
S ( E D , E Q ) = c o s ( E D , E Q ) = < E D , E Q > ∣ ∣ E D ∣ ∣ ⋅ ∣ ∣ E Q ∣ ∣ S(E_{D},E_{Q})=cos(E_{D},E_{Q})=\frac{
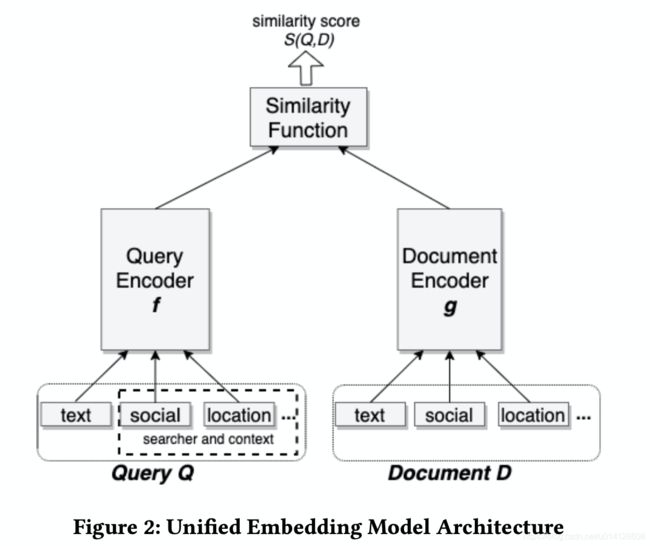
模型框架如上图所示,是典型的双塔结构。
两个encoder是互相独立的,也可以共享一部分网络参数,左边是 user 的塔;右边是 document 的塔。user 塔的输入包括用户的检索 query,以及用户位置、用户社交关系等上下文特征,document 塔的输入包括文档本身,以及文档的 group 信息等上下文特征。其中大部分的特征都是类别型特征,进行 one-hot 或者 multi-hot 的向量化;连续型特征则是直接输入到各自的塔中。
For multi-hot vectors, a weighted combination of multiple embeddings is applied for the final feature-level embedding.
双塔模型不是唯一的,只要
3.4 训练数据挖掘
本文将点击样本作为正例,对比两种定义负样本的方式:
- 随机采样:对每个query,从doc池中随机采样作为负样本
- 未点击的曝光:选择那些在一个session里有曝光但未点击的文档。
实验结果表明,仅仅用第二种方法,效果非常差。
其原因在于,曝光但用户未点击的样本,其实也是经过搜索系统的层层漏斗(例如很多相关性模块)筛选出来的才能展示到用户面前的,这样的样本其实多多少少和query还是沾边的,或者说比较相关的。而对于召回任务来说,整个候选集其实有大量的和query毫不相关、不沾边的doc。这样子模型学习的样本,和真正要召回时的候选集的分布,就是完全不一样的了。
对于正样本的挖掘,本文也做了对比实验:
- click:用点击的样本做正样本
- impressions::用展示的样本做正样本
实验结果表明,两种方法效果基本一致。用了点击的样本做正样本后,再增加展示的样本,也没有额外的收益。
3. 特征工程
The effectiveness of unified embeddings highly depends on the success of identifying and crafting informative features.
Unified Embedding 大体上采用了如下三个方面的特征:
3.1 Text features
Text Embedding 采用 char n-gram ,相对于 word n-gram 有两方面的优势,一是有限的词典,char embedding table 会比较小,训练更高效;二是不会有 OOV 问题,subword 可以有效解决拼写错误以及单词的多种变体引入的 OOV 问题。
embedding 善于处理以下两类问题:
- 模糊文字匹配: 有改写、纠错、变换和泛化的作用。
- 可选化:更好的文本理解能力,可以识别哪些term更重要、哪些term可省略。
3.2 Location features
位置特征对于搜索引擎的很多场景是非常重要的,因此本文在 query 和 document 侧的都加入了 location 的特征。
- 对于query侧,我们抽取用户所在的城市,区域,国家和语言。
- 对document侧,我们添加一些公开信息,例如对于group我们添加管理员设置的位置信息。 待完善
3.3 Social embedding features
为了有效利用 Facebook 社交网络中的丰富信息,本文额外地训练了一个社交网络的 Graph Embedding,然后将这个预训练的 Embedding 作为特征输入到模型当中。
4 SERVING
4.1 ANN
本文在系统中部署了基于倒排索引的ANN(近似邻域)搜索算法。这里的ANN不是指某种NN(网络),ANN (approximate near neighbor)是一种近似的K近邻向量检索算法。
待完善
embedding 量化(quantization)主要分为两个部分:
- 粗量化,即用K-means算法将embedding向量粗糙地划分为簇。
- 乘积量化,即细粒度地计算embedding间的距离。在这两个过程中我们需要调整以下几个参数:即细粒度地计算embedding间的距离。在这两个过程中我们需要调整以下几个参数:
- 1)粗量化:需要确定使用IMI或IVF算法,并且调整cluster数
- 2)乘积量化:需要确定使用哪一种乘积量化算法,并且确定pq_bytes
- 3)nprobe:需要确定在query的过程中查询多少个簇
待完善
4.2 系统设计
这一部分Facebook是将向量检索融合到倒排索引中(布尔表达式),但实际上大部分公司都是倒排索引和向量检索应该是分开的两套的检索系统,最后的结果进行融合。所以这一部分暂时没有细读。
4.3 Query 与 Index选择
待完善
5. LATER-STAGE OPTIMIZATION
Facebook 的搜索引擎可以看作是一个复杂的多阶段的排序系统,检索是排序之前的流程,检索得到的结果需要经过排序层的过滤和 ranking。目前的搜索系统是根据目前的倒排索引优化,可能很多向量检索回来的结果,整个搜索系统都没见过。所以需要对系统,根据向量检索做一些调整,以便能更好的将向量检索的结果应用到搜索系统中:
- 将embedding作为排序的特征。引入embedding相似度不仅能够能帮助排序层识别新的检索结果,而且对所有结果都能够对语义相似度进行度量。我们将query和结果的embedding的cosine距离引入排序模型,并且发现能够对性能有所提升。
- 训练数据反馈循环。在提升recall的同时,EBR也可能降低precision,为解决这一问题,我们记录了EBR的结果,然后进行人工标准识别这些结果是否真的与query相关。我们用这些人工标注过的来重新训练模型,这种方法被证明是能够提升保持较高precision的。
6. 高级优化技巧
基于embedding的语义召回需要更加深入的分析才能不断提升性能,facebook给出了其中可以提升的重要方向一个是Hard Mining(主要是 负样本 与正样本的构建),另一个是Embedding Ensemble。
6.1 Hard Mining
6.1.1 Hard negative mining (HNM)
本文发现很多时候同语义召回的结果,大部分都是相似的,而且没有区分度,最相似的结果往往还排不到前面,这些就是之前的训练样本太简单了,导致模型学习的不够充分。我们认为原因在于负样本是随机采样的,因此通常与query的名字是不同的。为了增强模型识别相似结果的能力,我们可以将与正样本在embedding空间距离相近的样本作为负样本。
备注:类比推荐系统,少数热门物料占据了绝大多数的曝光与点击。这就导致了导致所有人的召回结果都向少数热门物料倾斜。
Online hard negative mining
因为模型是采用mini-batch的方式进行更新的,所以对每个batch中的positive pairs,都随机一些非常相似的负样本作为训练集,模型效果提升非常明显,同时也注意到了每个 positive的pairs,最多只能有两个hard negative,不然的模型的效果会下降。
但是这种方法始终还是有局限,可能还是产生不了任意难度的负样本(batch-size也不能无限开大),随意需要offline部分的产出难的负样本。
Offline hard negative mining
离线HNM分为以下四步:
-
对于每个query,生成top K results
-
依据hard selection 策略选择hard negatives
在offline的hard negative mining中发现,用hardest的负样本效果不是最好的。而是用排在101-500的是最好的。(排名太靠前那是正样本,不能用;太靠后,与随机无异,也不能用;只能取中段。)第二个策略是融合easy/hard样本。
-
利用新生成的triplet重训练model
-
重复整个过程
6.1.2 Hard positive mining
模型采用了用户点击的样本为正样本,但是还有一些用户未点击但是也能被认为是正样本的样本。这块他们从用户的session日志中挖掘到潜在的正样本。(这里paper其实也没有讲清楚是如何挖掘的)
挖掘完Hard positive mining,和展示样本一起用,有进一步的提升。
6.1.3 本章小结
匹配度最低的,那是随机抽取的。能被一眼看穿,没难度,所谓的easy negative,达不到锻炼模型的目的。因此这里的随机抽样并不是等概率抽样。所以要选取一部分匹配度适中的,能够增加模型在训练时的难度,让模型能够关注细节,这就是所谓的hard negative。
6.2 Embedding Ensemble
6.2.1 Weighted Concatenation
6.2.2 Cascade Model
?????FAISS调优经验
7. 总结
召回建模时,需要一些压根没有曝光过的样本。而线上很多数据流,设计时只考虑了排序的要求,线上的未曝光样本,线下不可能获取到。
如果说排序是特征的艺术,那么召回就是样本的艺术,特别是负样本的艺术。FaceBook的这篇文章在第六章重点阐述了负样本的问题,提出了easy negative/hard negative的样本分级思路。
采用随机负样本的一大原因为:离线训练数据的分布,应该与线上实际的数据分布保持一致。因此,随机抽样能够很好地模拟这一分布。但这里的随机抽样并不是等概率抽样。
?????待补充
因此,当热门物料做正样本时,要降采样,减少对正样本集的绑架。
- 比如,某物料成为正样本的概率 P p o s = ( z ( w i ) 0.001 + 1 ) 0.001 z ( w i ) P_{pos}=(\sqrt{\frac{z(w_i)}{0.001}}+1)\frac{0.001}{z(w_i)} Ppos=(0.001z(wi)+1)z(wi)0.001,其中 z ( w i ) z(w_i) z(wi)是第i个物料的曝光或点击占比。
当热门物料做负样本时,要适当过采样,抵销热门物料对正样本集的绑架;同时,也要保证冷门物料在负样本集中有出现的机会。
- 比如,某物料成为负样本的概率 P n e g = n ( w i ) α ∑ j n ( w j ) α P_{neg}=\frac{n(w_i)^\alpha}{\sum_j{n(w_j)}^\alpha} Pneg=∑jn(wj)αn(wi)α。其中n(w)是第i个物料的出现次数,而 α \alpha α一般取0.75
成为***的概率表示什么意思呢?
参考链接
[1] 负样本为王:评Facebook的向量化召回算法
[2] Embedding-based Retrieval in Facebook Search
[3] 语义索引(向量检索)的几类经典方法
[4] Embedding-based Retrieval in Facebook Search
[5] KDD2020 | 揭秘Facebook搜索中的语义检索技术
[6] Triplet Loss and Online Triplet Mining in TensorFlow
[7] Triplet-Loss原理及其实现、应用