用户交互引导大模型生成内容特征,LLM-Rec框架助力个性化推荐!
欢迎来到魔法宝库,传递AIGC的前沿知识,做有格调的分享❗
喜欢的话记得点个关注吧!
今天主要和大家分享一篇使用大语言模型做数据增强来提升推荐系统性能的研究
标题: LLM-Rec: Personalized Recommendation via Prompting Large Language Models
链接: https://arxiv.org/pdf/2307.15780.pdf
公司/机构: University of Rochester/UCLA/Meta AI
摘要
本篇论文主要研究使用大语言模型(LLMs)来提升个性化推荐性能的策略,核心的方式是使用大模型对推荐模型的输入文本做数据增强。论文中提出了LLM-Rec的框架,该框架包括四种prompt策略:基本的prompt、推荐驱动的prompt、交互引导的prompt、推荐驱动+交互引导的混合prompt。通过实验表明,使用LLM增强的文本融入到推荐中可以提升推荐性能。推荐驱动和交互引导的提示策略有助于LLM理解全局和局部特性,凸显了多样化prompt设计和输入增强技术在增强LLM推荐能力方面的重要性。
介绍
以往的研究主要集中在将LLM直接用作推荐模型,或者将LLM用在推荐系统的框架中,而本次则从不同的角度出发。本次研究主要是通过设计不同的prompt策略来改进LLM生成高质量的文本,并将生成后的文本作为特征应用到推荐系统中,最终通过推荐效果来评估增强的质量。作者提出了名字叫做LLM-Rec的prompt设计框架,框架中包含了许多专门为个性化内容推荐而设计的prompt策略。其中包括:基本的prompt、推荐驱动的prompt、交互引导的prompt、推荐驱动+交互引导的prompt。这些策略旨在提升LLM生成文本的能力,提高内容推荐的准确性和相关性。通过实验布置,与基准方法进行了比较,证明了LLM-Rec框架的有效性。同时本研究揭示了不同提示策略对推荐性能的影响,并突显了利用LLMs进行个性化推荐的潜力。
LLM-Rec prompt的设计
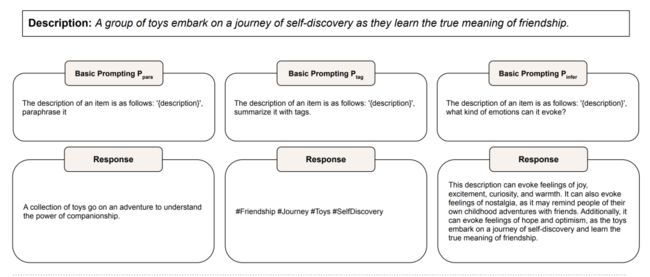
基础的Prompt
基础prompt主要有三种:Ppara、Ptag、Pinfer,其中,Ppara:表示对原有的文本描述做一个改写,但不要引入其他额外的信息。Ptag:表示对原有的文本描述做tag词的提取。Pinfer:表示根据原有的文本描述的特征做推导,得到一些宏观力度上的答复。
推荐驱动的prompt
对应基础的三种prompt,分别引入了推荐驱动的版本,用Precpara、Prectag、Precinfer表示。作者表示为了生成更高质量的内容描述,推荐驱动的prompt引入了一下3个特性:
-
Enhanced Context
-
Guided Generation
-
Improved Relevance
这三个特性总结来说是通过在基础prompt中引入推荐的指令和说明,具体如下图

作者表示引入的额外信息能够给模型起到引导的作用, 使得模型能够捕捉关键信息、用户偏好,提升生成描述的相关性。同时显式的提及生成的内容即将要被用于内容推荐,模型会对最终的目标有个清晰的理解,即可生成和最终应用目的一致的内容。
交互引导的prompt
交互引导的prompt的核心原则是充分利用user-item的交互信息来设计prompt,后续实验中使用Peng表示。交互引导的prompt主要的作用是让大模型更加深入的捕捉到用户的偏好,同时将这些特性融入到生成的文本中。在设计该prompt的之前,需要结合目标item的内容描述和T个items的内容表述,这T个items是根据用户交互行为和相关算法得到的,该部分和推荐系统中使用用户行为序列建模的思想一致,通过这种模式更深入地捕捉用户的兴趣偏好。这种prompt设计能够提升大模型生成内容描述的质量主要原因有如下三方面:
-
Contextual Relevance
-
User Preference Alignment
-
Enhanced Recommendation Quality
总结来说通过引入target和T个items的内容描述,可以让大模型具有一个较为丰富的上下文和较为深入的理解。同时由于T个items是通过用户交互行为而确定出来的,所以模型能够根据这些信息来对齐用户兴趣偏好。通过对比target和用户偏好的相似性、相关性的判断来生成更加高质量的内容描述。
推荐驱动的prompt+交互引导的prompt
指的是将以上两种prompt进行融合的设计,用Prec+eng表示。

实验布置
实验方案
在推荐任务中,会将target_item的描述作为文本的特征(embedding)加入到推荐模型中来提升模型的性能。本次实验主要是对比使用大模型做描述增强后的文本作为特征和原始文本描述作为特征的推荐效果,其中原始文本描述为BaseLine。
数据集

-
MovieLens-1M:数据集中没有关于电影的描述,只有标题和类别标签,所以作者使用GPT3为其生成原始文本描述。
-
Recipe:该数据集中含有关于食谱的描述。
这里的数据集作者均做了低频的过滤,对于交互频次低、被打分频次低的用户和item进行了过滤。
Item模块
-
LLM:GPT3
-
Text encoder:Sentence-BERT
-
T个item的选取:Personalized PageRank (PPR) score作为重要程度的评估,再次选取Top T
User模块
-
Embd表:将用户id转为128维的embedding表
推荐模块
在实验中主要尝试了四种推荐方案:
-
ItemPop:根据item的热度进行排序推荐
-
MLP: 将原始文本的embeddings和增强后文本的embeddings做concat后放入MLP中做推荐
-
AutoInt:使用多头注意力机制网络和残差网络结构在低维空间做特征交叉
-
DCN-V2:进行显示的特征交叉
评估指标
-
Precision@K
-
Recall@K
-
NDCG@K
实验结果
通过以上实验的布置,结果如下图所示:

通过对比,可以看出LLM-Rec(MLP+数据增强)相比其他几种常见的推荐模型在效果上有显著的提升, 甚至超过了一些复杂的特征交叉模型的效果。为了进一步说明不同的prompt的设计策略所带给推荐系统的作用, 作者又进一步做了评估,评估的框架如下图所示:
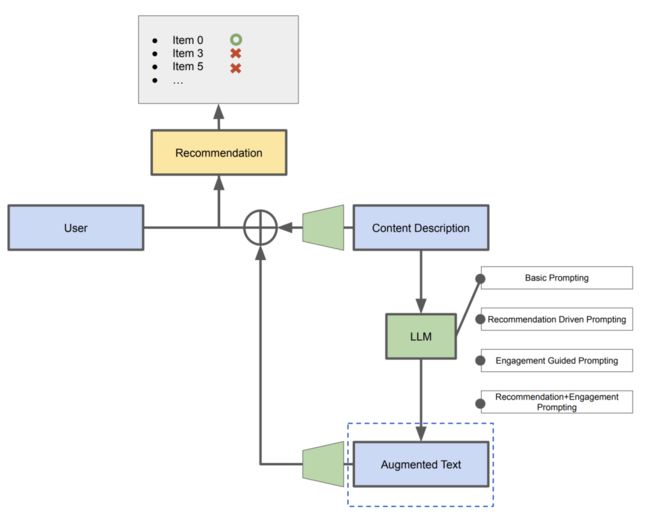
在整个后续的评估中,要保持推荐模块和用户模块不变,仅更改增强的文本(通过不同的prompt设计得到的,图中的虚线部分),然后对比不同prompt策略对推荐效果的影响和产生效果原因。结果如下图:

结论:
-
评估证明,无论哪种prompt设计,所得到的增强文本embedding和原始文本embedding合并后均提升了推荐的效果。说明数据增强给推荐提供了额外的,有效的信息。
-
不同的prompt设计策略的提升是有差异的,具体的差异做了进一步的解释。
策略差异的case study
作者抽取了使用Precpara为prompt生成策略的情况下胜出的3个item(两个数据集),分别对比3个item的Ppara和Precpara策略生成的prompt,寻找差异点。

-
Ppara和Precpara的差异:Precpara策略生成的增强文本会包含一些特殊的词, 这些词和用户偏好具有一定的相关性,而在Ppara策略生成的文本中没有。因此作者推断是因为这些词使得推荐效果变得更好了。
为了证明这些词的真实作用,作者对prompt进行了改写,设计出了Pmaskpara、Pkeywordpara。其中Pmaskpara是将Precpara中生成的关键词在prompt屏蔽掉,而Pkeywordpara是将在Precpara中生成的这些词和其他预定义的能够代表用户偏好的标签词汇一起拼接到Ppara中,根据新prompt生成的数据的推荐效果如下图:
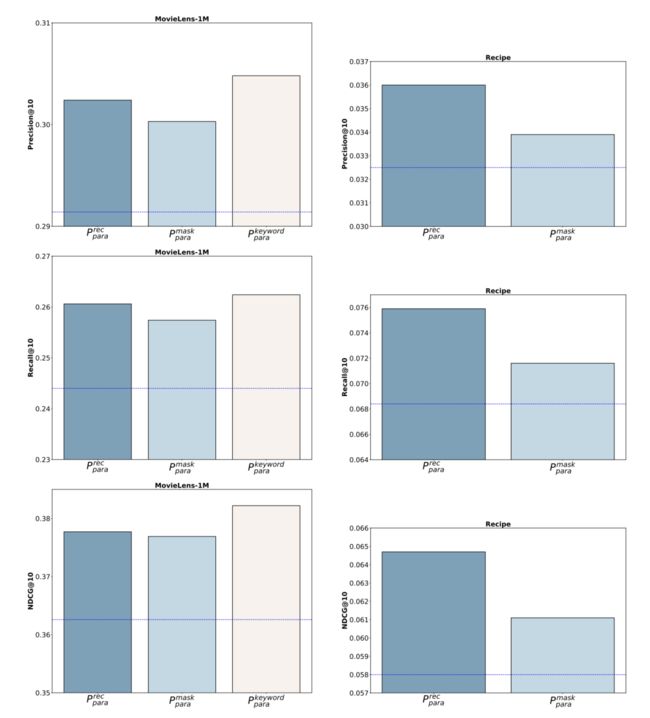
很明显,当和用户偏好相关的词被屏蔽后,效果出现了折损。同时,新增一些和用户偏好相关预定义的词,效果有明显的提升。
• Pinfer和Precinfer的差异:Precinfer相比Pinfer的推荐效果变差了,作者认为推导的方式所获取的增强文本和原始文本的差异性导致了最终效果变差。
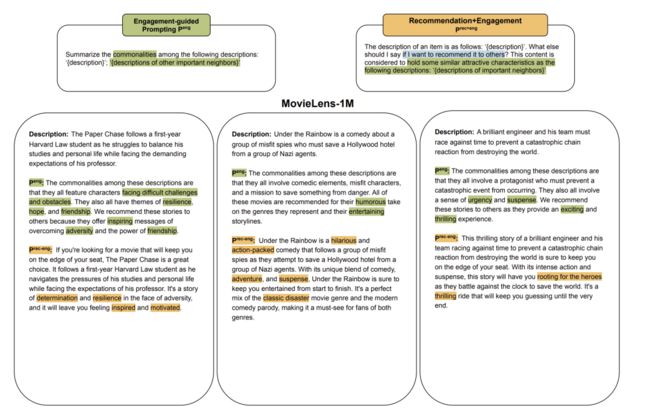
• Prec和Prec+eng的差异:相比Prec而言Peng能够合成更细粒度的用户偏好相关的词汇, 而两者的结合也会引入一些预定义的词汇,具体如下图:
策略组合的效果
最后作者又进行了一次组合的实验,将之前几种prompt的设计所生成的增强文本进行了排列组合,确定当所有数据全部组合到一起的情况下,效果是最好的。同时,考虑到和base实验embedding维度对齐的问题,作者还额外增加了附属对比组。比如:将原始文本的embedding直接翻倍。最终组合效果如下图:


这个结果也直接证明了通过大模型做数据增强的有效性,同时多种策略组合的叠加也能够显著提升推荐效果。图中的蓝色线表示仅使用原始文本embedding的MLP,而红色线表示仅使用原始文本embedding的DCN-V2。
总结
本篇论文主要研究了使用大模型做数据增强对内容推荐性能的影响,通过实验对比可以得出:
-
通过大模型生成的文本结合原始文本可以提升推荐的性能
-
大模型生成文本的策略决定了生成数据的质量,推荐驱动的 prompt设计策略和交互引导的prompt设计策略均从不同的角度增强了数据的可用信息量, 使得生成的文本质量更好,更适合推荐。
-
所有的策略生成的文本合并到一起的作用最明显,说明不同的策略生成的数据是可互补的。
如果对AIGC感兴趣,请关注我们的微信公众号“我有魔法WYMF”,我们会定期分享AIGC最新资讯和经典论文精读分享,让我们一起交流学习!!