SpringBoot整合Kafka (一)
前言
本文主要讲了SpringBoot整合Kafka文章,如果有什么需要改进的地方还请大佬指出⛺️
作者简介:大家好,我是青衿
☁️博客首页:CSDN主页放风讲故事
每日一句:努力一点,优秀一点

目录
文章目录
- 前言
- **目录**
-
- 一、介绍
- 二、主要功能
- 三、Kafka基本概念
- 四、Spring Boot整合Kafka的demo
-
- 1、构建项目
-
- 1.1、引入依赖
- 1.2、YML配置
- 1.3、生产者简单生产
- 1.4、消费者简单消费
- 2、生产者\n\n
-
- 2.1、Kafka生产者消息监听
- 2.2、生产者写入分区策略
-
- 指定写入分区
- 根据key写入分区
- 随机选择分区
- 2.3、带回调的生产者
- 文章末尾
一、介绍
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目
二、主要功能
1.消息系统: Kafka 和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka 还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
2.存储系统: Kafka 把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题的日志压缩功能即可。
3.日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种\nconsumer,例如hadoop、Hbase、Solr等。
三、Kafka基本概念
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。首先,让我们来看一下基础的消息(Message)相关术语:
Broker
消息中间件处理节点,一个Kafka节点就是一个broker,一 个或者多个Broker可以组成一个Kafka集群
Topic
Kafka根据topic对消息进行归类,发布到Kafka集群的每条 消息都需要指定一个topic
Producer
消息生产者,向Broker发送消息的客户端 Consumer 消息消费者,从Broker读取消息的客户端
ConsumerGroup
每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个ConsumerGroup中只能有一个Consumer能够消费该消息
Partition
物理上的概念,一个topic可以分为多个partition,每个 partition内部消息是有序的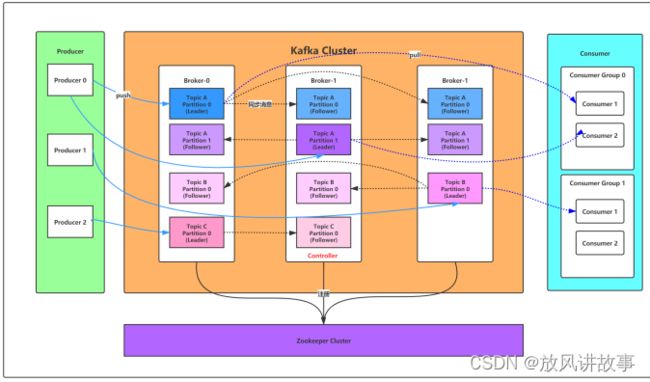
四、Spring Boot整合Kafka的demo
1、构建项目
1.1、引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
1.2、YML配置
spring:
kafka:
bootstrap-servers: 192.168.147.200:9092 # 设置 Kafka Broker 地址。如果多个,使用逗号分隔。
producer: # 消息提供者key和value序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: 3 # 生产者发送失败时,重试发送的次数
consumer: # 消费端反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
group-id: demo # 用来唯一标识consumer进程所在组的字符串,如果设置同样的group id,表示这些processes都是属于同一个consumer group,默认:""
1.3、生产者简单生产
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
void contextLoads() {
ListenableFuture listenableFuture = kafkaTemplate.send("test01-topic", "Hello Wolrd test");
System.out.println("发送完成");
}
1.4、消费者简单消费
@Component
public class TopicConsumer {
@KafkaListener(topics = "test01-topic")
public void readMsg(String msg){
System.out.println("msg = " + msg);
}
}
2、生产者\n\n
2.1、Kafka生产者消息监听
@Component
public class KafkaSendResultHandler implements ProducerListener {
private static final Logger log = LoggerFactory.getLogger(KafkaSendResultHandler.class);
@Override
public void onSuccess(ProducerRecord producerRecord, RecordMetadata recordMetadata) {
log.info("Message send success : " + producerRecord.toString());
}
@Override
public void onError(ProducerRecord producerRecord, Exception exception) {
log.info("Message send error : " + producerRecord.toString());
}
}
2.2、生产者写入分区策略
我们知道,kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。
指定写入分区
100条数据全部写入到2号分区
for (int i = 0; i < 100; i++) {
ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic",2,null, "toString");
listenableFuture.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
SendResult sendResult = (SendResult) result;
int partition = sendResult.getRecordMetadata().partition();
String topic = sendResult.getRecordMetadata().topic();
System.out.println("topic:"+topic+",分区:" + partition);
}
});
Thread.sleep(1000);
}
根据key写入分区
String key = "kafka-key";
System.out.println("根据key计算分区:" + (key.hashCode() % 3));
for (int i = 0; i < 10; i++) {
ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic", key, "toString");
listenableFuture.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
SendResult sendResult = (SendResult) result;
int partition = sendResult.getRecordMetadata().partition();
String topic = sendResult.getRecordMetadata().topic();
System.out.println("topic:" + topic + ",分区:" + partition);
}
});
Thread.sleep(1000);
}
随机选择分区
for (int i = 0; i < 10; i++) {
ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic", "toString");
listenableFuture.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
SendResult sendResult = (SendResult) result;
int partition = sendResult.getRecordMetadata().partition();
String topic = sendResult.getRecordMetadata().topic();
System.out.println("topic:" + topic + ",分区:" + partition);
}
});
Thread.sleep(1000);
}
2.3、带回调的生产者
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理
for (int i = 0; i < 100; i++) {
ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic",2,null, "toString");
listenableFuture.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
SendResult sendResult = (SendResult) result;
int partition = sendResult.getRecordMetadata().partition();
String topic = sendResult.getRecordMetadata().topic();
System.out.println("topic:"+topic+",分区:" + partition);
}
});
Thread.sleep(1000);
}
以上是简单的Spring Boot整合kafka的示例,可以根据自己的实际需求进行调整。
