【GEE】9、在GEE中生成采样数据【随机采样】
1简介
在本模块中,我们将讨论以下概念:
- 如何使用高分辨率图像生成存在和不存在数据集。
- 如何在要素类图层中生成随机分布的点以用作字段采样位置。
- 如何根据参数过滤您的点以磨练您的采样位置。

华盛顿州白杨林旁的落基山麋鹿。 图片来源:美国鱼类和野生动物管理局。
2背景
有充分证据表明,食草动物主要以麋鹿为食,会对白杨的再生率产生负面影响,因为白杨倾向于在大型单型林分中生长。因此,这些林分中的白杨再生率可以决定下层的组成。从一个地区排除麋鹿、鹿和奶牛放牧对白杨再生有可观察到的影响,但在了解白杨林下的存在如何影响从初级生产者到大型哺乳动物的地区的整体生物多样性方面所做的工作有限。在本模块中,我们将使用多个数据集和一米分辨率的图像来开发用于理论实地调查研究的采样位置。我们还将建立一个存在/不存在数据集,我们可以用它来训练一个特定区域的白杨覆盖模型。创建这样一个模型的过程可以在模块 7中找到。
2.1关于数据
National Land Cover Database : (NLCD) 是一个 30 m 的 Landsat 衍生的土地覆盖数据库,可在四个时间段(1992、2001、2006 和 2011)使用。1992 年的数据主要基于陆地卫星数据的无监督分类。其他年份依靠决策树分类来识别土地覆盖类别。
国家农业影像计划(NAIP) 在整个美国大陆的农业生长季节获取航拍图像。NAIP 项目每年根据可用资金和农场服务机构图像采集周期签订合同。从 2003 年开始,NAIP 在大多数州以 5 年为周期被收购。2008 年是一个过渡年,从 2009 年开始以三年为周期。NAIP 图像是在 1 米的地面采样距离处获取的,其水平精度与图像检查期间使用的照片可识别地面控制点的 6 米范围内匹配。它可能取决于给定的位置和时间范围,但 NAIP 图像通常以四个波段收集:蓝色、绿色、红色和近红外。正如我们在之前的一些模块中看到的,近红外波段有助于区分不同类型的植被。
USGS 国家高程数据集 1/3 角秒(NED) 是由 USGS 生成的高程数据集。无缝图层可在 0.33 角秒(约 30 m 像元大小)的空间分辨率下跨 48 个州、阿拉斯加、夏威夷和美国领土的部分地区使用。
3开发您自己的采样点
我们将首先根据相对的物理和生态条件开发我们自己的潜在现场采样位置。
3.1感兴趣区域
该模块的地理区域是科罗拉多州西部的大台地。被认为是世界上面积最大的台地,大台地从科罗拉多州大章克申附近的 4,000 英尺上升到最高点超过 10,000 英尺。从历史上看,大台地曾被冰川覆盖,表面上布满了湖泊。虽然在高海拔地区森林茂密,但沿着陡峭的海拔梯度,灌木林、白杨林和针叶林之间的过渡明显。作为科罗拉多州山地环境最西部的延伸之一,大台地是许多有蹄类动物的重要栖息地。
我们的第一步是在 GEE 中打开一个新脚本。首先创建一个包含 Grand Mesa 的感兴趣区域(您可以在顶部的搜索栏中按名称搜索它)。使用几何工具执行此操作。创建功能后,将其重命名roi。
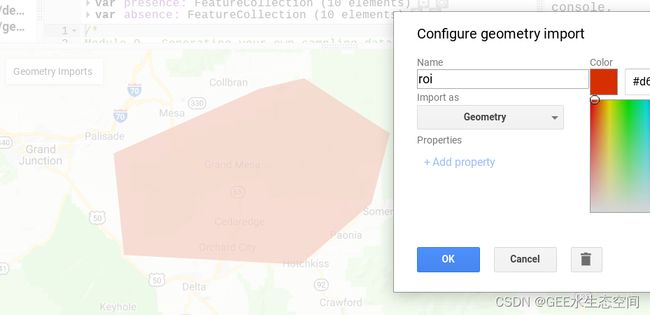
用于此模块的一般感兴趣区域的示例。
3.2加载 NAIP
在此过程中,我们将依赖 NAIP 图像执行多个步骤。NAIP 图像不是每年都收集的,因此在多年内加载以确定可用的时间范围是有意义的。我们将使用打印声明来查看我们所在地区的可用年份。在模块 1中,我们使用了 2011 年的 NAIP 图像,现在我们将查看 2015 年和 2017 年的图像。复制以下代码以启动您的脚本。
// Call in NAIP imagery as an image collection.
var NAIP = ee.ImageCollection("USDA/NAIP/DOQQ")
.filterBounds(roi)
.filterDate("2015-01-01", "2017-12-31");
print(NAIP);
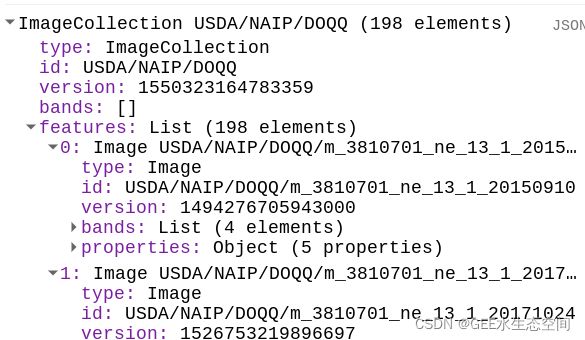
一份打印声明,标识此感兴趣区域的可用图像年份。
打印声明向我们展示了 2015 年和 2017 年的图像,但是如果不将数据可视化,就很难确定存在的覆盖范围。现在,我们将把这两个集合添加到地图中,以查看图像可用性的样子。将以下代码添加到您现有的脚本中。
// Filter the data based on date.
var naip2017 = NAIP
.filterDate("2017-01-01", "2017-12-31");
var naip2015 = NAIP
.filterDate("2015-01-01", "2015-12-31");
// Define viewing parameters for multi band images.
var visParamsFalse = {bands:['N', 'R', 'G']};
var visParamsTrue = {bands:['R', 'G', 'B']};
// Add both sets of NAIP imagery to the map to compare coverage.
Map.addLayer(naip2015,visParamsTrue,"2015_true",false );
Map.addLayer(naip2017,visParamsTrue,"2017_true",false );

2015 NAIP 图像捕捉到了我们研究区域范围内的白杨林。

2017 NAIP 图像捕捉到了白杨林变黄的情况,但由于捕捉给定图像的时间不同,植被覆盖显示出明显的不同。
我们还将在 2015 年的数据中添加假彩色图像,因为这种波段组合可视化对于区分落叶林和常绿林非常有帮助。我们通过将naip2015具有不同可视化参数集的对象添加到地图来做到这一点。将以下代码添加到您现有的脚本中。
-
// Add 2015 false color imagery.
-
Map.
addLayer(naip2015, visParamsFalse,
"2015_false",
false);

如果您的图像加载缓慢,这里有一个如何注释代码的示例。
3.3阿斯彭围栏
在我们的假设研究中,土地管理者在大梅萨南部靠近 65 号高速公路的范围内建立了一些白杨围栏。土地管理者没有围栏的具体形状文件,但他们确实有四个角落的 GPS 位置。我们将使用这些数据通过在脚本中创建几何特征来将边界添加到地图中。在这种情况下,我们正在创建 ee.Geometry.MultiPolygon 特征。将以下代码添加到您现有的脚本中。
// Creating a geometry feature.
var enclosure = ee.Geometry.MultiPolygon(
[
[
[-107.91079184,39.012553345],
[-107.90828129,39.012553345],
[-107.90828129,39.014070552],
[-107.91079184,39.014070552],
[-107.91079184,39.012553345]
],
[
[-107.9512176,39.00870162],
[-107.9496834,39.00870162],
[-107.9496834,39.00950196],
[-107.95121765,39.00950196],
[-107.95121765,39.00870162]
]
]);
print(enclosure)
Map.addLayer(enclosure, {}, "exclosures");
该ee.Geometry.MultiPolygon功能的结构有点复杂,但它实际上是一组嵌套列表。存在三层列表:
//Nested list example.
['tier 1'
[ 'tier 2'
['tier 3']
]
]
-
第 1 层:单一列表一个包含所有数据的列表。该
ee.Geometry.MultiPolygon()函数要求输入是一个列表。 -
第 2 层:每个多边形的列表每个唯一的坐标集都需要保存在列表中。
-
第 3 层:每个 x,y 坐标对的列表每个多边形由一系列 x,y 点组成,其中一个点与第一个坐标对完全重叠。最后一个坐标对是必不可少的,并且是完成该功能的原因。
如果您正在尝试制作几何特征并且遇到问题,您始终可以使用绘制形状工具创建一个,并将打印语句中的值作为模板查看。
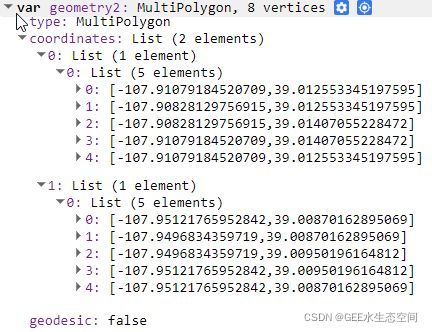
enclosure来自 print 语句的对象坐标详细信息的视图。
3.4确定相似的采样区域
现在我们已经加载了我们的白杨围栏,我们将引入一些额外的层来帮助量化围栏的景观特征。我们将使用这些值来查找附近的类似区域,以用作隔离区之外的采样点。通过保持相似的环境条件,我们可以就放牧对白杨林内生物多样性的影响做出更有力的陈述。
我们将使用三个数据集来量化站点内的条件:
-
国家高程数据集 (NED):选择相似高程范围内的区域。海拔与许多环境条件相关,因此我们将其用作温度、降水和太阳辐射等特征的代表。
-
国家农业影像计划 (NAIP):计算 NDVI 指数以衡量植被生产力。
-
国家土地覆盖数据库 (NLCD):选择落叶林类作为限制采样点位置的一种方式。
3.5加载数据集
首先,我们将通过其唯一 ID 调用 NED。我们可以通过搜索功能并阅读元数据来收集这些详细信息。将以下代码添加到您现有的脚本中。
// Load in elevation dataset clip it to general area.
var elev = ee.Image("USGS/NED")
.clip(roi);
print(elev, "elevation");
Map.addLayer(elev, {min: 1500, max: 3300}, "elevation", false);
我们已经加载了 NAIP 图像,但我们需要将其转换为图像并计算 NDVI。我们已将 NAIP 图像过滤为一年,每个区域只有一张图像。我们可以应用 reducer 将图像集合转换为图像,但不需要仅使用单层 reducer。单个值的中位数就是那个值。一个更合乎逻辑的选择是应用mosaic()函数将图像集合转换为图像。将以下代码添加到您现有的脚本中。
// Apply mosaic, clip, then calculate NDVI.
var ndvi = naip2015
.mosaic()
.clip(roi)
.normalizedDifference(["N","R"])
.rename("ndvi");
Map.addLayer(ndvi, {min:-0.8, max:0.8}, "NDVI" , false);
print(ndvi,"ndvi");
我们引入的最后一个数据集是 NLCD。将以下代码添加到您现有的脚本中。
// Add National Land Cover Database (NLCD) with color palette.
var dataset = ee.ImageCollection('USGS/NLCD');
print(dataset, "NLCD");

显示 NLCD 图像集合结构的打印语句。
从打印语句中我们可以看到,图像 3 是最新的数据集,并且该图像有一个称为土地覆盖的带。我们不会尝试将其从特征集合中提取出来,而是通过其唯一 ID 调用 2011 NLCD 图像并选择土地覆盖带。
// Wrap the selected image in ee.Image, which redefines datatype for proper visualization.
var landcover = ee.Image("USGS/NLCD/NLCD2011")
.select("landcover")
.clip(roi);
print(landcover, "Landcover Image");
//
Map.addLayer(landcover, {}, "Landcover" , false);
3.6生成随机点
加载我们的三个数据集后,我们现在可以生成一系列潜在的调查站点。我们将通过在给定区域内生成随机点来做到这一点。我们希望这些站点可以访问,靠近两个外壳,并且在公共土地边界内。让我们创建另一个几何特征,我们将使用它来包含随机生成的点。将鼠标悬停在几何导入框上,然后单击 + 新图层。一定要命名这第二个几何特征sampleArea。

第二个样本区域几何特征应该是什么样子的示例。
有了几何特征,我们可以使用该randomPoints()函数创建点。将以下代码添加到您现有的脚本中。
// Generate random points within the sample area.
var points = ee.FeatureCollection.randomPoints({
region: sampleArea,
points:1000,
seed: 1234}
);
print(points,"points");
Map.addLayer(points, {}, "Points" , false);
我们使用字典来定义函数的参数。region是创建点的区域。在我们的例子中,我们将把它设置为sampleArea。该points参数定义要生成的点数。该seed参数用于指示特定的随机值字符串。将此视为一组随机值的唯一 ID。种子编号(本例中为 1234)指的是现有的随机值列表。设置种子非常有用,因为您仍在使用随机值,但该过程是可重现的。如果您想了解更多信息,可以查看此资源。
3.7提取值到点
要将景观特征与点位置相关联,我们将调用该ee.Image.sampleRegions()函数。此功能在单个图像上执行。我们将把所有这些图像加在一起以创建多波段图像,而不是在我们的三个独特图像(高程、NDVI 和 NLCD)上调用三次,这样我们就可以一次调用这个函数。将以下代码添加到您现有的脚本中。
// Add bands of elevation and NAIP.
var ndviElev = ndvi
.addBands(elev)
.addBands(landcover);
print(ndviElev, "Multi band image");
使用多波段图像集,我们将调用该sampleRegions()函数。将以下代码添加到您现有的脚本中。
// Extract values to points.
var samples = ndviElev.sampleRegions({
collection: points,
scale: 30 ,
geometries: true
});
print(samples,'samples');
Map.addLayer(samples,{}, "samples" , false);
在此函数中,collection参数是将添加提取值的特征集合。在此示例中,它是一个点数据集。该scale参数是指数据的像素大小。该geometries参数说明您是否要为集合中的每个元素维护 xy 坐标对。默认值为 false,但我们在这里将其设置为 true,因为我们最终希望在地图上显示这些点,因为它们将代表合适的采样点位置。
Segue on Scale:尺度在遥感中非常重要。事实上,规模有多种类型。地图比例尺,地图上测量的距离与景观上的实际距离之间的关系,是地理工作中最常见的。图像范围有时被称为图像的比例或空间比例。对于上述函数中的 scale 参数,scale 是指图像的像素大小。在我们的示例中,多波段图像具有两个像素大小为 30 m 的波段和一个像素大小为一米的波段。在处理不同比例的数据时,最好始终使用最大的像素大小。这意味着您有效地将一米图像放大到 30 m。这意味着您的数据会丢失很多精度,但您可以确信,该放大单元格中的数字代表了所有单元格的平均值。如果您朝相反的方向走并缩小图像,您可以有效地弥补数据以填补空白。因为 NAIP 图像的像素大小为 1 m,所以它包含的信息(像素)多 30 x 30 条,而不是单个 30 m 像素。请看下面的示例,以帮助可视化这些过程。
升级获取可用数据并找到平均值。
| 3 | 7 | 8 |
| 4 | 2 | 2 |
| 1 | 3 | 2 |
平均 = 3.56
缩小采用这个单一值 (3.56) 并找到网格中所有位置的值。
| ? | ? | ? |
| ? | ? | ? |
| ? | ? | ? |
有许多不同的值集可以平均到 3.56,问题变成了哪一组值是正确的。为了增加这种复杂性,集合中的每个值都可以放置在 9 个不同的位置。缩小比例时获得实际值的可能性可以通过导致已知平均值的潜在组合的数量和可以放置值的数量空间的阶乘来粗略估计。我们的数据正在讨论将单个值缩减为 900 个不同的值。这种可变性清楚地表明,如果不对数据进行一些补充,就无法缩小规模。如果你的数据是编造出来的,它就没有多少量化价值。

我们的抽样函数结果为我们提供了 1,000 个潜在站点可供选择。我们将通过将我们在这些站点拥有的可测量数据与来自我们的外壳的这些数据的平均值进行比较来限制这个池。
从我们的打印声明中我们可以看到,我们的 1,000 个点位置中的每一个都具有三个属性:高程、土地覆盖和 NDVI。我们希望使用这些值来过滤掉与外壳条件不匹配的站点。土地覆盖数据是分类的,因此很容易过滤,因为我们从 NLCD 上的元数据中知道白杨林的土地覆盖类别是单个值 (41)。
我们将使用该filterMetadata()函数来选择白杨林内的所有站点。将以下代码添加到您现有的脚本中。
// Filter metadata for sites that fall with the NLCD deciduous forest layer
var aspenSites = samples
.filterMetadata({name:"landcover", operator:"equals", value: 41});
print(aspenSites, "Sites");
从打印的声明中我们可以看到,这将潜在站点的总数从 1,000 个减少到 578 个。对于这项研究,我们希望减少到大约 10 个潜在站点,因此仍有很多工作要做。
基于高程和 NDVI 的过滤有点棘手,因为这两个变量都是连续数据。您希望找到与附件中的值具有相似值但不需要完全相同的站点。对于这个例子,我们会说如果一个值在外壳内找到的平均值的 +/- 10% 范围内,我们会将其视为相似。在我们过滤潜在的采样点之前,需要计算一些因素。
- 附件中的平均值
- 高于和低于平均水平 10%
我们将首先处理 NDVI 图像,然后将此过程应用于高程数据集。
- 第 1 步:找到我们要在外壳内部区域应用平均缩减器的平均值。将以下代码添加到您现有的脚本中。
// Set the NDVI range.
var ndvi1 = ndvi
.reduceRegion(
{reducer:ee.Reducer.mean(),
geometry: enclosure,
scale: 1,
crs:'EPSG:4326'}
);
print(ndvi1, "Mean NDVI");
该reduceRegion()函数接收图像并返回字典,其中键是波段的名称,值是减速器的输出。
- 第 2 步:确定平均值附近的可接受变异性。
我们依靠简单的数学函数来找到 +/- 10% 的值。将以下代码添加到您现有的脚本中。
// Generate a range of acceptable NDVI values.
var ndviNumber = ee.Number(ndvi1.get("ndvi"));
var ndviBuffer = ndviNumber.multiply(0.1);
var ndviRange = [ndviNumber.subtract(ndviBuffer),
ndviNumber.add(ndviBuffer)];
print(ndviRange, "NDVI Range");
这个过程的第一步就是理解数据类型。这ndvi1是一个字典,因此我们调用该get()函数以根据已知键提取值。然后我们将该值转换为ee.Number类型对象,以便我们可以应用数学函数。我们的输出是一个包含最小值和最大值的列表(平均 NDVI 值的 +/- 10%)。
3.8创建自己的函数
我们确定了 NDVI 的可接受范围,但我们还需要对高程应用相同的过程。在这种特定情况下,我们只应用了这个过程两次,但它似乎是一个有用的代码块,可能会在路上派上用场。我们将创建一个具有灵活参数的函数,而不是一次又一次地复制和粘贴代码,以便我们可以有效地应用这些有用的代码。我们将在模块 10中广泛使用函数。
函数具有以下要求:参数、操作和返回值。以下是 Google 地球引擎官方文档中的函数结构示例。在这种情况下,该语句指的是一个动作。
仅示例! 不要在代码编辑器中运行
var myFunction = function(parameter1, parameter2, parameter3) {
statement;
statement;
var value = statement;
return value;
};
如果我们将此结构应用于按面积减少 NDVI 的目标(使用我们在上面创建的代码),我们将构建以下内容:
- 参数:图像、几何对象和像素大小。
- 行动:
reduceRegion()功能。 - 返回值:
reduceRegion()函数的输出。
使用函数时,在参数中生成通用术语很重要,但要给出所需数据类型的一些指示。我们希望这是可重现的,因此我们在定义函数时提供了更多信息作为注释。将以下代码添加到您现有的脚本中。
/*
This function is used to determine the mean value of an image within a given area.
image: an image with a single band of ordinal or interval level data
geom: geometry feature that overlaps with the image
pixelSize: a number that defines the cell size of the image
Returns a dictionary with the median values of the band, the key is the band name.
*/
var reduceRegionFunction = function(image, geom, pixelSize){
var dict = image.reduceRegion(
{reducer:ee.Reducer.mean(),
geometry: geom,
scale: pixelSize,
crs:'EPSG:4326'}
)
return(dict)
};
这定义了函数,现在我们可以在高程数据集上调用它。将以下代码添加到您现有的脚本中。
// Call function on elevation dataset.
var elev1 = reduceRegionFunction(elev, enclosure, 30);
print(elev1, "elev1 ");
当您需要多次应用流程时,这是一种非常简洁的编码方式。让我们定义第二个函数来确定平均值附近的可接受变异性。
- 参数:图像、乐队名称、比例
- 行动:多个步骤
- 返回值:列表
将以下代码添加到您现有的脚本中。
/*
Generate a range of acceptable values.
dictionary: a dictionary object
key: key to the value of interest, must be a string
proportion: a percentile to define the range of the values around the mean
Returns a list with a min and max value for the given range.
*/
var efffectiveRange = function(dictionary, key, proportion){
var number = ee.Number(dictionary.get(key))
var buffer = number.multiply(proportion)
var range = [number.subtract(buffer),
number.add(buffer)]
return(range)
};
让我们在effectiveRange()函数的输出上调用reduceRegionFunction()函数。将以下代码添加到您现有的脚本中。
// Call function on elevation data.
var elevRange = efffectiveRange(elev1, "elevation", 0.1);
print(elevRange);
现在我们的 NDVI 和高程值都有一个有效范围,我们可以应用一组额外的过滤器来精简潜在样本站点的列表。我们可以通过将多个filterMetadata函数链接在一起来做到这一点。将以下代码添加到您现有的脚本中。
// Apply multiple filters to get at potential locations.
var aspenSites2 = aspenSites
.filterMetadata({name:"ndvi", operator:"greater_than", value: ndviRange[0]})
.filterMetadata({name:"ndvi", operator:"less_than", value: ndviRange[1]})
.filterMetadata({name:"elevation", operator:"greater_than", value: elevRange[0]})
.filterMetadata({name:"elevation", operator:"less_than", value: elevRange[1]});
print(aspenSites2, "aspenSites2");
Map.addLayer(aspenSites2, {}, "aspenSites2" , false);
这个过滤过程使我们在 1,000 个原始站点中减少到不到 100 个。通过查看图像或根据您在该领域的经验主观选择站点,这个数字可以减少到 10。此外,您可以提供更严格的范围,可能是海拔和 NDVI 的 +/- 5%,以获得更有限的一组位置。
这个知情的选址过程是确保您在现场取样时比较苹果与苹果的良好第一步。
4生成您自己的训练数据集。
当您一直在研究这个景观时,您可能已经注意到 NLCD 土地覆盖层中的一些错误分类。这些类型的错误分类在任何土地覆盖数据集中都会出现。虽然 NLCD 经过培训可以对美国特定的土地覆盖组合进行分类,但我们正在检查的白杨林包含在更大的森林类型组中。另一个重要点是 NLCD 显示了 2011 年检测到的土地覆盖。虽然森林随着时间的推移相当稳定,但我们可以预期已经发生了某种程度的变化。这些现实让您思考基于该特定区域的遥感模型生成您自己的白杨土地覆盖产品的可能性。这个过程有很多内容,我们不打算在这里介绍。然而,
4.1眼部采样
生成您自己的训练数据依赖于您可以使用高分辨率图像自信地识别您感兴趣的物种的假设。我们在这个过程中使用 NAIP,因为它是免费提供的,并且有一个已知的收集日期,允许我们将白杨林区域标记为“存在”,将没有白杨的区域标记为“不存在”。然后可以使用这些数据来训练景观中的白杨发生模型。
4.2添加存在点和不存在点
首先,我们需要创建特定的层来保存我们的眼部采样点。添加存在和不存在图层是一个相当简单的过程,通过在地图上的代表性位置创建和放置几何特征来完成。将鼠标悬停在几何导入框上,然后单击+ new layer。几何特征geometry将添加到您现有的几何特征下方,作为您感兴趣的区域。选择旁边的齿轮图标geometry,将打开一个弹出窗口。import as将类型更改为FeatureCollection,然后按Add property按钮。用存在填写方框| 1 并按“确定”保存您的功能。

更改参数以创建存在几何特征的示例。
将功能集名称更改为存在并选择您喜欢的颜色。
重复此过程以创建缺席特征集合,其中添加的属性为:presence | 0
我们将使用两个数据集的存在列中的二进制值来定义该位置所指的内容,存在:1 = 是,这是白杨,0 = 否,这不是白杨。
创建要素集合后,我们可以通过选择特定要素集合(存在或不存在)并使用标记工具在图像上放置点来进行采样。您使用的抽样方法将取决于您的研究。在此示例中,绿色存在点代表白杨森林,而蓝色点不是白杨(缺席)。
将 2015 年假彩色图像与 NDVI 或 NLCD 结合使用,以区分白杨与其他土地覆盖类型。与大多数其他植被类型相比,白杨林的红色更亮,并且在图像中往往具有比草本植被更复杂的纹理。在您认为是白杨林的地方丢掉一些分数。
使用标记工具创建的 NAIP 图像上存在和不存在位置的示例。尽力选择对您来说正确的位置。
随意对任意数量的地点进行采样。同样,这些数据的质量将取决于用户区分存在的多个土地覆盖类别的能力。
4.3导出点
目前,我们的点位置存储在两个不同的要素类中。在导出数据之前,让我们将这些要素合并到一个要素类中。我们可以毫无问题地合并图层,因为它们共享相同的数据类型(点几何特征)和相同的属性数据(带有数字数据值的存在)。将以下代码添加到您现有的脚本中。
// Merge presence and absence datasets.
var samples = presence.merge(absence)
print(samples, 'Samples');
现在采样特征类已合并,让我们将特征导出到我们的 Google Drive。当您运行下面的代码时,控制台右上角的任务栏会亮起。除非您指示 Google 地球引擎从任务栏中执行任务,否则它不会运行任务。将以下代码添加到您现有的脚本中。
// Export presence points.
Export.table.toDrive({
collection: samples,
description:'presenceAbsencePointsForForest',
fileFormat: 'csv'
});
5结论
在本模块中,我们介绍了识别具有相似环境特征的位置并生成我们自己的采样数据。这两个过程在理论上都很简单,但如果无法在一个地方访问所有数据,则工作起来可能会有些复杂。在这两种情况下,我们都在生产增值产品,这些产品通过遥感提供信息,但本质上不是遥感过程。这种在如何使用遥感数据方面具有创造性的能力是 Google 地球引擎平台之美的一部分。
5.1完整代码
// Call in NAIP imagery as an image collection.
var NAIP = ee.ImageCollection("USDA/NAIP/DOQQ")
.filterBounds(roi)
.filterDate("2015-01-01", "2017-12-31");
print(NAIP);
// Filter the data based on date.
var naip2017 = NAIP
.filterDate("2017-01-01", "2017-12-31");
var naip2015 = NAIP
.filterDate("2015-01-01", "2015-12-31");
// Define viewing parameters for multi band images.
var visParamsFalse = {bands:['N', 'R', 'G']};
var visParamsTrue = {bands:['R', 'G', 'B']};
// Add both sets of NAIP imagery to the map to compare coverage.
Map.addLayer(naip2015,visParamsTrue,"2015_true",false );
Map.addLayer(naip2017,visParamsTrue,"2017_true",false );
// Add 2015 false color imagery.
Map.addLayer(naip2015, visParamsFalse, "2015_false", false);
// Creating a geometry feature.
var enclosure = ee.Geometry.MultiPolygon(
[
[
[-107.91079184,39.012553345],
[-107.90828129,39.012553345],
[-107.90828129,39.014070552],
[-107.91079184,39.014070552],
[-107.91079184,39.012553345]
],
[
[-107.9512176,39.00870162],
[-107.9496834,39.00870162],
[-107.9496834,39.00950196],
[-107.95121765,39.00950196],
[-107.95121765,39.00870162]
]
]);
print(enclosure)
Map.addLayer(enclosure, {}, "exclosures");
// Load in elevation dataset clip it to general area.
var elev = ee.Image("USGS/NED")
.clip(roi);
print(elev, "elevation");
Map.addLayer(elev, {min: 1500, max: 3300}, "elevation", false);
// Apply mosaic, clip, then calculate NDVI.
var ndvi = naip2015
.mosaic()
.clip(roi)
.normalizedDifference(["N","R"])
.rename("ndvi");
Map.addLayer(ndvi, {min:-0.8, max:0.8}, "NDVI" , false);
print(ndvi,"ndvi");
// Add National Land Cover Database (NLCD) with color palette.
var dataset = ee.ImageCollection('USGS/NLCD');
print(dataset, "NLCD");
// Wrap the selected image in ee.Image, which redefines datatype for proper visualization.
var landcover = ee.Image("USGS/NLCD/NLCD2011")
.select("landcover")
.clip(roi);
print(landcover, "Landcover Image");
Map.addLayer(landcover, {}, "Landcover" , false);
// Generate random points within the sample area.
var points = ee.FeatureCollection.randomPoints({
region: sampleArea,
points:1000,
seed: 1234}
);
print(points,"points");
Map.addLayer(points, {}, "Points" , false);
// Add bands of elevation and NAIP.
var ndviElev = ndvi
.addBands(elev)
.addBands(landcover);
print(ndviElev, "Multi band image");
// Extract values to points.
var samples = ndviElev.sampleRegions({
collection: points,
scale: 30 ,
geometries: true
});
print(samples,'samples');
Map.addLayer(samples,{}, "samples" , false);
// Filter metadata for sites that fall with the NLCD deciduous forest layer
var aspenSites = samples
.filterMetadata({name:"landcover", operator:"equals", value: 41});
print(aspenSites, "Sites");
// Set the NDVI range.
var ndvi1 = ndvi
.reduceRegion(
{reducer:ee.Reducer.mean(),
geometry: enclosure,
scale: 1,
crs:'EPSG:4326'}
);
print(ndvi1, "Mean NDVI");
// Generate a range of acceptable NDVI values.
var ndviNumber = ee.Number(ndvi1.get("ndvi"));
var ndviBuffer = ndviNumber.multiply(0.1);
var ndviRange = [ndviNumber.subtract(ndviBuffer),
ndviNumber.add(ndviBuffer)];
print(ndviRange, "NDVI Range");
/*
This function is used to determine the mean value of an image within a given area.
image: an image with a single band of ordinal or interval level data
geom: geometry feature that overlaps with the image
pixelSize: a number that defines the cell size of the image
Returns a dictionary with the median values of the band, the key is the band name.
*/
var reduceRegionFunction = function(image, geom, pixelSize){
var dict = image.reduceRegion(
{reducer:ee.Reducer.mean(),
geometry: geom,
scale: pixelSize,
crs:'EPSG:4326'}
)
return(dict)
};
// Call function on elevation dataset.
var elev1 = reduceRegionFunction(elev, enclosure, 30);
print(elev1, "elev1 ");
/*
Generate a range of acceptable values.
dictionary: a dictionary object
key: key to the value of interest, must be a string
proportion: a percentile to define the range of the values around the mean
Returns a list with a min and max value for the given range.
*/
var efffectiveRange = function(dictionary, key, proportion){
var number = ee.Number(dictionary.get(key))
var buffer = number.multiply(proportion)
var range = [number.subtract(buffer),
number.add(buffer)]
return(range)
};
// Call function on elevation data.
var elevRange = efffectiveRange(elev1, "elevation", 0.1);
print(elevRange);
// Apply multiple filters to get at potential locations.
var aspenSites2 = aspenSites
.filterMetadata({name:"ndvi", operator:"greater_than", value: ndviRange[0]})
.filterMetadata({name:"ndvi", operator:"less_than", value: ndviRange[1]})
.filterMetadata({name:"elevation", operator:"greater_than", value: elevRange[0]})
.filterMetadata({name:"elevation", operator:"less_than", value: elevRange[1]});
print(aspenSites2, "aspenSites2");
Map.addLayer(aspenSites2, {}, "aspenSites2" , false);
// Merge presence and absence datasets.
var samples = presence.merge(absence)
print(samples, 'Samples');
// Export presence points.
Export.table.toDrive({
collection: samples,
description:'presenceAbsencePointsForForest',
fileFormat: 'csv'
});