Python 多任务(线程、进程、协程)
多任务:同时执行多个事件(多个任务)
并发:CPU小于当前的执行任务。
并行:CPU大于当前执行的任务。
实现多任务的方式:线程、进程、协程
1.线程
线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
#使用线程完成多任务
import threading # 内置模块
import time
def demo():
for i in range(3):
print("hello world")
time.sleep(1)
if __name__ == '__main__':
t = threading.Thread(target=demo)
t.start()
print("1")
#主线程会等到子线程执行结束之后主线程,才会结束
防护线程:守护线程,也就是说不会等子线程结束
使用方法: t.setDaemon(True)
那是否可以实现子线程结束完毕,主线程才继续执行呢?
使用方法:t.join()
查看线程数量
使用threading.enumerate()来查看当前线程的数量。
import threading
import time
def demo1():
for i in range(3):
print(f"--demo1--{i}")
time.sleep(1)
def demo2():
for i in range(3):
print(f"--demo2--{i}")
time.sleep(1)
def main():
t1 = threading.Thread(target=demo1)
t2 = threading.Thread(target=demo2)
t1.start()
t2.start()
print(threading.enumerate())
if __name__ == '__main__':
main()
验证子线程的执行与创建:
当调用Thread的时候,不会创建线程。
当调用Thread创建出来的实例对象的start方法的时候,才会创建线程以及开始运行这个线程。
继承Thread类创建线程
import threading
import time
class A(threading.Thread):
def __init__(self,name):
super().__init__(name=name)
def run(self):
for i in range(5):
print(i)
if __name__ == "__main__":
t = A('test_name')
t.start()
多线程共享全局变量(线程间通信)
import threading
import time
num = 100
def demo1():
global num # 2.声明为全局变量
num += 1 # 1.函数作用域 访问不到外边的num 所以报错 找不到
print(f"demo----{num}")
def demo2():
print(f"demo1----{num}")
def main():
t1 = threading.Thread(target=demo1)
t2 = threading.Thread(target=demo2)
t1.start()
time.sleep(1)
t2.start()
time.sleep(1)
if __name__ == '__main__':
main()
多线程之间传参
import threading
import time
num = [11, 22]
def demo1(num):
num.append(33)
print(f"demo----{num}" )
def demo2(num):
print(f"demo1----{num}")
def main():
t1 = threading.Thread(target=demo1, args=(num,))
t2 = threading.Thread(target=demo2, args=(num,))
t1.start()
time.sleep(1)
t2.start()
time.sleep(1)
print(f"main----{num}")
2.线程与进程
互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
某个线程要更改共享数据时,先将其锁定,此时资源的状态为"锁定",其他线程不能改变,只到该线程释放资源,将资源的状态变成"非锁定",其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
# 创建锁
mutex = threading.Lock()
# 锁定
mutex.acquire()
# 解锁
mutex.release()
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
import threading
import time
class MyThread1(threading.Thread):
def run(self):
# 对mutexA上锁
mutexA.acquire()
# mutexA上锁后,延时1秒,等待另外那个线程 把mutexB上锁
print(self.name+'----do1---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexB已经被另外的线程抢先上锁了
mutexB.acquire()
print(self.name+'----do1---down----')
mutexB.release()
# 对mutexA解锁
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
# 对mutexB上锁
mutexB.acquire()
# mutexB上锁后,延时1秒,等待另外那个线程 把mutexA上锁
print(self.name+'----do2---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexA已经被另外的线程抢先上锁了
mutexA.acquire()
print(self.name+'----do2---down----')
mutexA.release()
# 对mutexB解锁
mutexB.release()
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
避免死锁:程序设计时要尽量避免,添加超时时间等
线程同步
我们使用 threading.Condition() 完成线程同步。
# 线程同步
cond = threading.Condition()
# 等待
cond.wait()
# 唤醒
cond.notify()
进程
定义
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。并且进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
概念
• 进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。
• 进程是一个“执行中的程序”。
• 进程是操作系统中最基本、重要的概念。
进程与程序区别
• 进程:正在执行的程序。动态的,暂时的
• 程序:没有执行的代码,是一个静态的,永久的
进程状态介绍
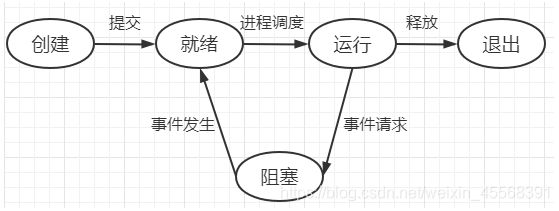
Python实现多进程
通过 multiprocessing.Process模块
• group:参数未使用,默认值为None。
• target:表示调用对象,即子进程要执行的任务。
• args:表示调用的位置参数元祖。
• kwargs:表示调用对象的字典。
• name:子进程名称
import multiprocessing
import time
def demo():
while True:
print("--1--")
time.sleep(1)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=demo)
p1.start()
#注意:多个进程同时执行的顺序是随机的。
通过继承Process类创建进程
class Demo(multiprocessing.Process):
def run(self):
while True:
print("--1--")
time.sleep(1)
if __name__ == '__main__':
p1 = Demo()
p1.start()
守护主线程
class Demo(multiprocessing.Process):
def run(self):
while True:
print("--1--")
time.sleep(1)
if __name__ == '__main__':
p1 = Demo()
p1.daemon = True
p1.start()
print("1")
子线程结束,再执行主线程
class Demo(multiprocessing.Process):
def run(self):
while True:
print("--1--")
time.sleep(1)
if __name__ == '__main__':
p1 = Demo()
p1.start()
p1.join()
print("1")
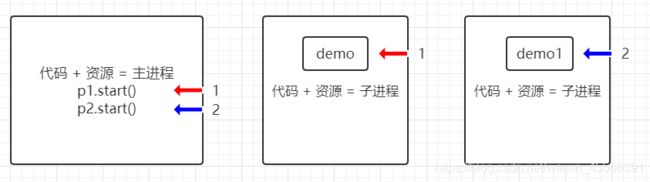
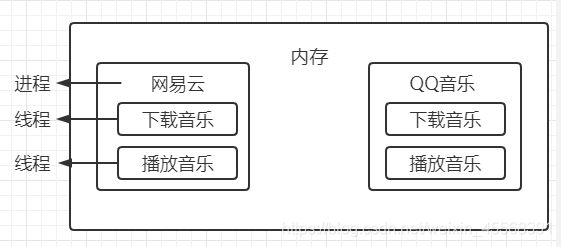
进程与线程区别
- 根本区别
进程:操作系统资源分配的基本单位
线程:任务调度和执行的基本单位 - 开销
• 进程:通过复制代码+资源创建子进程 每个进程都有独立的代码和数据空间,程序之间的切换会有较大的开销
• 线程:在同一份代码里 创建线程 共享内存 开销较小 - 分配内存
• 进程:系统在运行的时候为每个进程分配不同的内存空间
• 线程:线程所使用的资源是它所属的进程的资源 - 包含关系
• 进程:一个进程可以拥有多个线程
• 线程:线程是进程的一部分

3.进程
多进程共享全局变量
import threading
import time
import multiprocessing
num = 100
def demo1():
global num
num += 1
print(f"demo----{num}")
def demo2():
print(f"demo1----{num}")
p1 = multiprocessing.Process(target=demo1)
p2 = multiprocessing.Process(target=demo2)
p1.start()
p2.start()
if __name__ == '__main__':
main()
进程间的通信
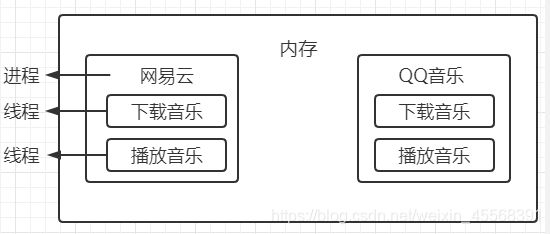
这个时候就可以使用到队列进行通信。
需求:
• 实现在函数 download 中,将list元素保存到队列中
• 实现在函数 manage_data 中,将list元素从队列中取出,并且添加到新的列表中。
import multiprocessing
# 下载数据
def download(q):
lis = [11, 22, 33]
for item in lis:
q.put(item)
print("下载完成,并且保存到队列中...")
# 处理数据
def manage_data(q):
ana_data = list()
while True:
data = q.get()
ana_data.append(data)
if q.empty():
break
print(ana_data)
def main():
q = multiprocessing.Queue()
t1 = multiprocessing.Process(target=download, args=(q,))
t2 = multiprocessing.Process(target=manage_data, args=(q,))
t1.start()
t2.start()
if __name__ == '__main__':
main()
注意:如果使用普通队列,不是使用 start() 方法,而是 run() 方法。
start() 与 run() 区别
• start() 方法来启动进程,真正实现了多进程运行,这时无需等待 run 方法体代码执行完毕而直接继续执行下面的代码:调用 Process 类的 start() 方法来启动一个进程,这时此进程处于就绪(可运行)状态,并没有运行,一旦得到 cpu 时间片,就开始执行 run() 方法,这里方法 run() 称为进程体,当进程结束后,不可以重新启动。
• run() 方法只是类的一个普通方法,如果直接调用 run 方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待 run 方法体执行完毕后才可继续执行下面的代码,这样就没有达到写线程的目的。
进程池
当需要创建的子进程数量不多时,可以直接利用 multiprocessing 中的 Process 动态生成多个进程, 但是如果是上百甚至上千个目标,手动的去创建的进程的工作量巨大,此时就可以用到 multiprocessing 模块提供的 Pool 方法。也就是进程池。

初始化 Pool 时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求,但是如果进程池中的进程已经达到指定的最大值,那么该请求 就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
如下代码,使用进程池体现。
import os, time
def worker(msg):
t_start = time.time()
print(f"{msg}开始执行,进程号为{os.getpid()}")
time.sleep(2)
t_stop = time.time()
print(msg, f"执行完成,耗时{t_stop-t_start}")
worker()
进程池通信
使用进程池通信时,要使用进程池的队列。
• multiprocessing.Manager().Queue()
import multiprocessing
def demo1(q):
q.put("a")
def demo2(q):
data = q.get()
print(data)
if __name__ == '__main__':
q = multiprocessing.Manager().Queue()
po = multiprocessing.Pool(2)
po.apply_async(demo1, args=(q,))
po.apply_async(demo2, args=(q,))
po.close()
po.join()
4.协程
协程,又称为微线程,它是实现多任务的另一种方式,只不过是比线程更小的执行单元。因为它自带CPU的上下文,这样只要在合适的时机,我们就可以把一个协程切换到另一个协程。
CPU上下文(CPU寄存器和程序计数器):
• CPU寄存器是CPU的内置的容量小,但速度极快的内存。
• 程序计数器则是用来存储CPU正在执行的指令位置、或者即将执行的下一条指令位置。
协程与线程差异
• 线程:每个线程都有自己缓存Cache等等数据,操作系统还会做这些数据的恢复操作。所以线程的切换非常消耗性能。
• 协程:单纯的操作CPU的上下文,所以一秒切换上百万次系统都能抗住。所以完成多任务的效率比线程和进程都高
yield实现协程
import time
def task1():
while True:
print("--1--")
time.sleep(0.1)
yield
def task2():
while True:
print("--2--")
time.sleep(0.1)
yield
def main():
t1 = task1()
t2 = task2()
while True:
next(t1)
next(t2)
if __name__ == '__main__':
main()
生成器扩展
• next(g)预激活
• g.send(None)预激活
• g.send(“需发送的值”)激活yield并且发送值
• 注意:此前必须有预激活也就是next(g)或g.send(None)
• 生成器函数的返回值在异常中
def create_num(num):
a, b = 0, 1
current_num = 0
while current_num < num:
yield a
a, b = b, a + b
current_num += 1
return 'hello world'
g = create_num(5)
yield from
作用:
• 1.替代产出值的嵌套for循环
• 2.yield from的主要功能是打开双向通道,把最外层的调用方与最内层的子生成器连接起来。因为yield from的异常捕获更为完善。
替代产出值的嵌套for循环
需求
lis = [1, 2, 3]
dic = {
"name":"amy",
"age":18
}
输出:
1
2
3
name
age
实现
def my_chain(*args, **kwargs):
for my_iterable in args:
yield from my_iterable
for value in my_chain(lis, dic):
print(value)
yield from的主要功能是打开双向通道
def generator_1():
total = 0
while True:
x = yield
print("加", x)
if not x:
break
total += x
return total
def main():
g1 = generator_1()
g1.send(None)
g1.send(2)
g1.send(3)
g1.send(None)
if __name__ == '__main__':
main()
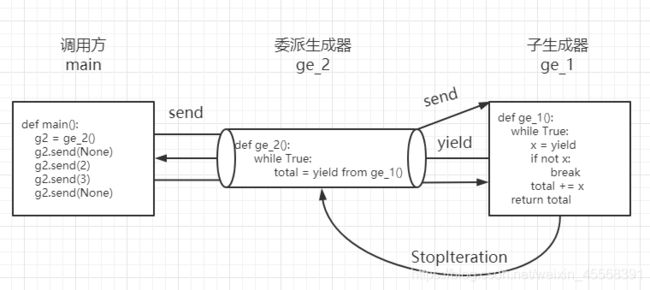
greenlet实现协程
from greenlet import greenlet #greenlet库 需要安装
import time
def demo1():
while True:
print("demo1")
gr2.switch()
time.sleep(0.5)
def demo2():
while True:
print("demo2")
gr1.switch()
time.sleep(0.5)
if __name__ == '__main__':
gr1 = greenlet(demo1)
gr2 = greenlet(demo2)
gr1.switch()
gevent实现协程
介绍
greenlet已经实现了协程,但是这个还的人工切换,就很麻烦,python还有一个比greenlet更强大的并且能够自动切换任务的模块gevent
原理: 当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
import gevent
import time
def f1(n):
for i in range(n):
print(gevent.getcurrent(),i)
gevent.sleep(0.5)
def f2(n):
for i in range(n):
print(gevent.getcurrent(),i)
gevent.sleep(0.5)
g1 = gevent.spawn(f1, 5) # 创建协程
g2 = gevent.spawn(f2, 5)
g1.join()
g2.join()
异步编程
同步与异步
同步:是指代码调用IO操作时,必须等待IO操作完成才返回的调用方式,多个任务之间执行的时候要求有先后顺序,必须一个先执行完成之后,另一个才能继续执行, 只有一个主线
异步:是指代码调用IO操作时,不必等IO操作完成就返回的调用方式,多个任务之间执行没有先后顺序,可以同时运行,执行的先后顺序不会有什么影响,存在的多条运行主线
async/await实现协程
Python中使用协程最常用的库就是asyncio
• async/await 关键字:python3.5用于定义协程的关键字,async定义一个协程,await用于挂起阻塞的异步调用接口。
• coroutine 协程:协程对象,只一个使用async关键字定义的函数,他的调用不会立即执行函数,而是会返回一个协程对象。协程对象需要注册到事件循环中,由事件循环调用。
• event_loop 事件循环:相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件时,就会调用对应的处理方法。
• task 任务:一个协程对象就是一个原生可以挂起的函数,任务则是对协程的进一步封装,其中包含任务的各种状态。
• future:代表将来执行或没有执行的任务结果。它与task没有本质的区别。
快速上手
协程函数,定义函数时候 async def 函数名 。
协程对象,执行 协程函数() 得到的协程对象。
async def func():
pass
result = func()
如果想要运行协程函数内部代码,必须要讲协程对象交给事件循环来处理。
import asyncio
async def func():
print("快来搞我吧!")
result = func()
loop = asyncio.get_event_loop()
loop.run_until_complete( result )
await
import asyncio
async def func():
print("来呀")
response = await asyncio.sleep(2)
print("结束",response)
result = func()
loop = asyncio.get_event_loop()
loop.run_until_complete( result )
Tasks
Tasks用于并发调度协程,通过asyncio.create_task(协程对象)的方式创建Task对象,这样可以让协程加入事件循环中等待被调度执行。除了使用asyncio.create_task()函数以外,还可以用低层级的loop.create_task()或 ensure_future() 函数。不建议手动实例化 Task 对象。
注意:asyncio.create_task()函数在 Python 3.7 中被加入。在 Python 3.7 之前,可以改用低层级的 asyncio.ensure_future()函数。
import asyncio
async def func():
print(1)
await asyncio.sleep(2)
print(2)
return "返回值"
async def main():
print("main开始")
task1 = asyncio.ensure_future( func() )
task2 = asyncio.ensure_future( func() )
print("main结束")
ret1 = await task1
ret2 = await task2
print(ret1, ret2)
result = main()
loop = asyncio.get_event_loop()
loop.run_until_complete( result )
简单总结
• 进程是资源分配的单位
• 线程是操作系统调度的单位
• 进程切换需要的资源很最大,效率很低
• 线程切换需要的资源一般,效率一般
• 协程切换任务资源很小,效率高
• 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发