SpringBoot3 整合 ElasticSearch7 示例
项目需求
做仿牛客项目需要使用 es 做搜索,但是老师示例的是 SpringBoot2 + es6 去做的,然而我用的是 Spring3 + es7.17.10,于是踩了很多的坑。
在 es7 中,配置文件和查询所需的实现类都做了很大的改动,我以能成功运行的代码为例,大概说一下怎么配置和使用。
yml 配置文件
# ElasticsearchProperties
#spring.data.elasticsearch.cluster-name=my-cluster
#spring.data.elasticsearch.cluster-nodes=centos:9300
spring.elasticSearch.uris=centos:9200
spring.elasticsearch.connection-timeout=20000ms
spring.data.elasticsearch.repositories.enabled=true
首先 yml 配置文件发生了变化,不能使用原来的集群名称和节点的配置了。
搜索的变化
在需要使用搜索的功能时,原来的 ElasticsearchTemplate 被弃用了,也不能使用 SearchQuery 类去做查询了。在 es7.17.10 中,要使用 SearchRequest 和 SearchResponse 搭配 RestHighLevelClient 来完成查询。
写配置类将 RestHighLevelClient 注入容器管理
首先应该写一个配置类,将 RestHighLevelClient 创建出来,交给容器进行管理。
@Configuration
public class EsConfig {
@Value("${spring.elasticsearch.uris}")
private String esUrl;
//localhost:9200 写在配置文件中,直接用 <- spring.elasticsearch.uris
@Bean
RestHighLevelClient client() {
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(esUrl)//elasticsearch地址
.build();
return RestClients.create(clientConfiguration).rest();
}
}
不带高亮的搜索
在需要搜索的地方注入 RestHighLevelClient ,需要使用 SearchRequest 、 SearchResponse 和 searchSourceBuilder 来搭配 RestHighLevelClient 完成查询。
SearchRequest 根据索引名构建请求,searchSourceBuilder 负责构建搜索条件。
搜索条件构建完成后,用 SearchRequest 请求来接收。最后接收了搜索条件的 SearchRequest 通过 restHighLevelClient 的 client 方法完成了搜索,返回一个 SearchResponse 对象。
代码如下:
@Test
public void noHighlightQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("discusspost");//discusspost是索引名,就是表名
//构建搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
//在discusspost索引的title和content字段中都查询“互联网寒冬”
.query(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))
// matchQuery是模糊查询,会对key进行分词:searchSourceBuilder.query(QueryBuilders.matchQuery(key,value));
// termQuery是精准查询:searchSourceBuilder.query(QueryBuilders.termQuery(key,value));
.sort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.sort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.sort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
//一个可选项,用于控制允许搜索的时间:searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
.from(0)// 指定从哪条开始查询
.size(10);// 需要查出的总记录条数
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSONObject.toJSON(searchResponse));
List<DiscussPost> list = new LinkedList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
DiscussPost discussPost = JSONObject.parseObject(hit.getSourceAsString(), DiscussPost.class);
System.out.println(discussPost);
list.add(discussPost);
}
System.out.println(list.size());
for (DiscussPost post : list) {
System.out.println(post);
}
}
那么又有新的问题了,搜索出来的 searchResponse 是个啥玩意呢,我们通过 Json 格式字符串来看一下:
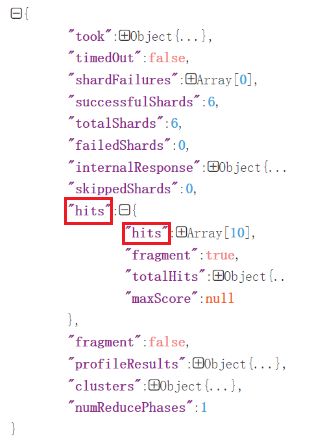
我们所需要搜索的实体在 hits 中的 hits 数组中,我们看看数组里是什么样子的:

我们发现, hits 数组中,每个数组也有非常多的信息,我们需要的实体对象就存在数组中的 sourceAsMap 和 sourceAsString 中,一个是 map 形式,一个是 Json 字符串的形式。这样就明白我们为什么这么写代码了。
当然,第一个 hits 中还有其他很多数据:

其中常用的还有 totalHits 的 value ,代表命中的数据量,一般用来判断是否命中数据。
高亮搜索
当然如果需要高亮搜索,则可以通过构建 HighlightBuilder 来实现,代码如下:
@Test
public void highlightQuery() throws Exception{
SearchRequest searchRequest = new SearchRequest("discusspost");//discusspost是索引名,就是表名
Map<String,Object> res = new HashMap<>();
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.field("content");
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("");
highlightBuilder.postTags("");
//构建搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))
.sort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.sort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.sort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.from(0)// 指定从哪条开始查询
.size(10)// 需要查出的总记录条数
.highlighter(highlightBuilder);//高亮
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
List<DiscussPost> list = new ArrayList<>();
long total = searchResponse.getHits().getTotalHits().value;
for (SearchHit hit : searchResponse.getHits().getHits()) {
DiscussPost discussPost = JSONObject.parseObject(hit.getSourceAsString(), DiscussPost.class);
// 处理高亮显示的结果
HighlightField titleField = hit.getHighlightFields().get("title");
if (titleField != null) {
discussPost.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if (contentField != null) {
discussPost.setContent(contentField.getFragments()[0].toString());
}
// System.out.println(discussPost);
list.add(discussPost);
}
res.put("list",list);
res.put("total",total);
if(res.get("list")!= null){
for (DiscussPost post : list = (List<DiscussPost>) res.get("list")) {
System.out.println(post);
}
System.out.println(res.get("total"));
}
}
其中处理高亮显示结果的逻辑如下:

至于为什么 titleField.getFragments()[0].toString() 直接就是 Title 高亮后的结果,我也没搞明白…
如果有知道的大佬,欢迎留言,不尽感激。