从分布式管理到多租户实现,企业级大数据系统如何利用开源生态构建?

大数据系统的应用领域
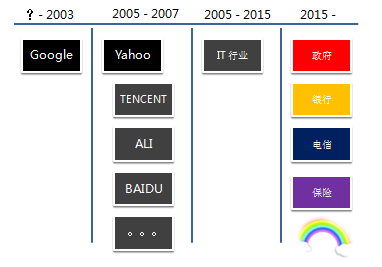
首先回顾一下历史。

从中我们可以看到一些趋势,在大数据生态发展的过程中,大数据系统的管理系统,大数据系统的安全,易用性,机器学习不断的补充到生态系统中来并不断完善。
早期是 Google 一家独有。2003 GFS paper 发表的时候,Google 的集群规模就达到上千台,遥遥领先。
之后是大家都知道的历史,Doug Cutting 在为他的 lucene 分布式化的时候看到了 Google 的这篇论文,并把它实现出来,后来被 Yahoo 收编,得到一个机会和环境把 Hadoop 孵化出来。
随着互联网的兴旺发展,许多互联网公司也逐渐开始把 Hadoop 变成内部大数据处理系统的不二之选。随着大数据概念的火爆,使得开始是行业领头羊的巨头在玩的东西逐渐被有机会普及到传统领域。
现在不断能够听说新的大数据项目冒出来。
Hadoop 零基础的同学会有一个模糊的认识,会把 Hadoop 当初数据库,尤其是在使用 Hive 和 Impala 的时候,会在清醒和迷糊之间徘徊一段时间。
即使是领域内的同学,也会持有一个观点,没有海量数据,搞什么大数据? 我个人愿意把大数据系统这样定义:大数据系统是在大数据的时代背景下,由一个朴素的应用需求催生出的系统,在大数据的浪潮中,被赋予的不同的期待,逐渐成长起来的尚处于青少年期的生态。
总之,我是想说,这是有门槛的。
好处自然很多,横向扩展的能力、机器学习的能力、图计算、流式计算,许许多多的应用场景令人浮想联翩。
门槛也有很多,1) 开源系统,大家知道开源系统如果你不把里里外外全部了然于心,使用的时候碰到的麻烦应该是有所体会的。2) 它还在快速的成长,很多功能可能还没有,或者是 bug 很多,传统行业(在这里我指除 IT 之外的行业)应该是使用商业软件居多。
但毫无疑问这个领域正在蓬勃发展。底层数据类型和格式非常广的兼容性,计算模型的丰富和对于机器学习模型的支持。
那么什么样的领域需要大数据系统?
- 海量数据:例如 IT 企业
- 数据非常杂:传统企业
- 需要有新的数据处理模型的支持:AI 和实时运营决策公司(目前还很超前)。
例如下面这个场景:
- 5 年以上的老公司
- 跨国业务,数据需要到母公司汇总分析
- 数据链条很长,不同的业务会产生数据,数据应用和数据分析没有分开
- 积累了历史数据,还在继续产生不知道如何分析的历史数据
- 积累了一些问题,这些问题可以在数据中找到答案
- 行业竞争激烈,管理层很着急。。。
那么问题来了:
- 搭建这个平台会遇到哪些困难?
- 要一个什么样的数据平台?
- 如何做数据管理和数据流程管理?
- 多久才能带来价值?

这些问题先暂且放一放。
我们先看看这个问题,那么多的大数据系统的服务,如何能统一管理呢?这里的管理是指:
- 初始化安装
- 配置文件修改发布
- 服务启动停止
- 查看分布式的日志
- 服务升级
- 添加新的服务
- 系统调优
- 监控
- 到服务内部不同 web 应用的导航
- 集群元数据管理
还有在公有云和私有云提供创建实例接口的情况下,如何实现一键部署呢?下面以 Cloudera 的产品为例,讲一下这些是如何设计实现的。
分布式系统的管理系统
先来看一下,如果修改一个没有管理系统辅助的社区版的 Hadoop 系统的配置文件,它的复杂度是这样的。

而事实上早期的集群维护的确就是这么做的,即使你用脚本把配置文件推送到其他节点,并且用脚本拉回日志检查的话,还是非常不方便。
下面来看看 Cloudera manager 是怎么来解决这个问题的。
Cloudera manager 可以通过 RPM 手工安装。Cloudera agent 可以通过 Cloudera manager 的界面添加。
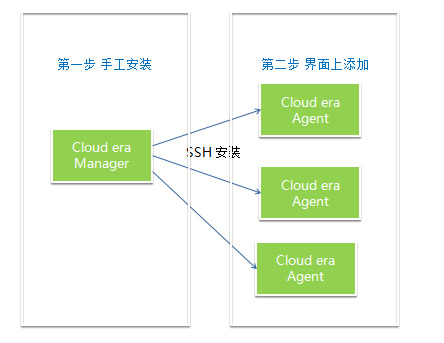
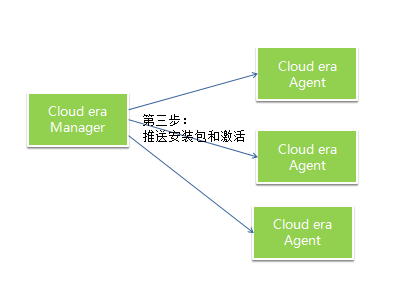

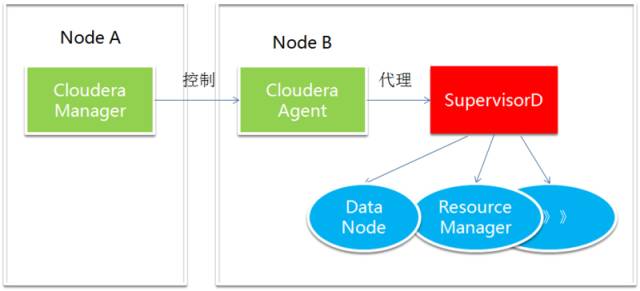
Cloudera manager 通过 cloudera-scm-server 来中央控制整个集群的搭建、维护和监控。每台机器上的管理工作交给 cloudera-scm-agent。
cloudera-scm-agent 借助开源项目 supervisord 来实现每台机器的进程管理。supervisord 的好处是在单台机器上实现对进程的集中管理。Cloudera-scm-agent 通过接受 cloudera-scm-server 的指令,调用 supervisord 的接口来进行控制本机上所有的进程和查询本机上所有进程的状态。
cloudera manager 把新改动与线上环境配置进行对比,如果发现有配置更新,提示用户更新服务配置或者部署客户端配置。

在更新服务配置的同时通过命令调用 cloudera agent,cloudera agent 调用 supervirsord 的接口,重启各个服务器上的进程。在重启完毕以后,cloudera manager 监控管理服务,通过调用服务接口检测服务是否成功启动,显示服务的状态,如果发现服务没有成功启动,用户可以通过检测结果判断服务失败的原因。
Cloudera RPM 安装包中,还提供了监控的服务包。Cloudera manager 管理界面上可以启动 Cloudera 的管理服务。其中有两个监控服务,一个是 host monitor,其作用是接受 agent 上报来的节点数据,如磁盘使用情况,CPU capacity,CPU 用量,内存的大小和内存的用量,机器负载等。Service monitor 则是一个服务健康检测服务,会定期的执行各种不同的检测,把数据汇总到 web 界面供管理员查看。
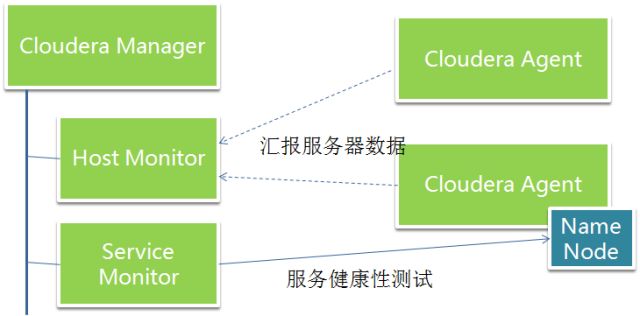
同时 cloudera manager 提供统一入口的日志查询 GUI,以一个搜索接口加过滤器的方式帮助用户排查原因。
在有共有云服务的环境下,可以通过一个描述文件安装整套 cloudera manager,cloudera agent 以及大数据服务。
cloudera director 通过调用云服务 API 创建集群所需要的实例。

通过云服务 API 得到地址信息,进而用 SSH 远程命令调用安装 cloudera manager 和 cloudera agent,并且启动 cloudera manager 和 cloudera agent 服务。

通过调用 cloudera manager 的 REST 服务 API,进行大数据服务的安装,部署和配置。

一些我了解的情况如下:
Cloudera 自己有自己的代码仓库,它的各种服务的代码版本与社区发布的版本不一致。具体多大程度上不一致很难知晓。部分应该是由于 license 的原因,像 SPARKR 没有集成到 cloudera 版本的 Spark 中去,应该是 license 的原因。
社区的大数据服务需要 Cloudera 进行定制才能集成到 Cloudera 的管理平台上,支持的大数据服务的种类有限。
Cloudera 上面的服务版本更新还是比较慢的。
再来看看大数据系统在底层技术上是如何实现多租户的?
数据平台多租户的实现
对于 Hadoop 平台而言,多租户是最大的难点之一。大数据系统最大的一个问题是资源浪费,早期单用户,单任务。多租户的目标可以有效的充分利用资源。多租户的资源分配依赖于两个技术:资源隔离,调度算法,在操作系统层面和服务层面(YARN)都可以做资源隔离。
YARN 在服务层面做资源隔离的是 JVM。YARN 的 node manager 响应 resource manager 的请求创建的 container,其实就是一个 JVM。通过 JVM 的参数来设置资源的大小,这个资源包括内存和 CPU。MR2 可以对于 Map 和 Reducer 的 JVM 大小分别做定义。Spark 的对应的 JVM 叫 executor,大小都是一样的。还有一类 YARN 的框架需求也需要用到 JVM,那就是 application master,同样也是 JVM。这其实就是 YARN 的核心功能,在 YARN 的层面之上的应用框架,无外乎是通过 YARN 和 HDFS 来分发应用程序逻辑,申请资源,把具体的应用层的框架逻辑注入到 JVM 中,而最后用户的业务逻辑再注入到应用层的框架逻辑之中。
应用层框架譬如就是 MR2 和 SPARK,用户逻辑就是你的JAR包

操作系统层 Linux 用 CGROUPS 做静态资源隔离。2006 年 Google 工程师在创建 CGROUPS 这个特性的时候,本来的名字不是 CGROUPS,而是进程容器,这也是这个特性的本意,就是在 Linux 内核级别创建一个容器的概念,使得这些进程只竞争容器内部的资源。容器内的应用不会收到容器外的应用对于操作系统资源,CPU、内存、网络 IO、句柄的侵占,运行出现问题。CGROUPS 同时也是 Docker 的底层技术,Docker 在 CGROUPS 的基础之上,实现了更加广泛和易用的接口,和建立的一个广泛的生态。
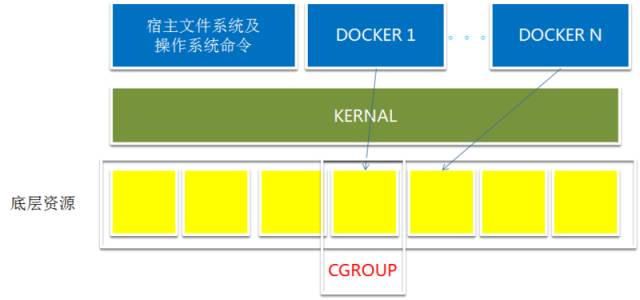
Hadoop 的这些服务中,也广泛的应用 CGROUP 来对服务资源做静态隔离。
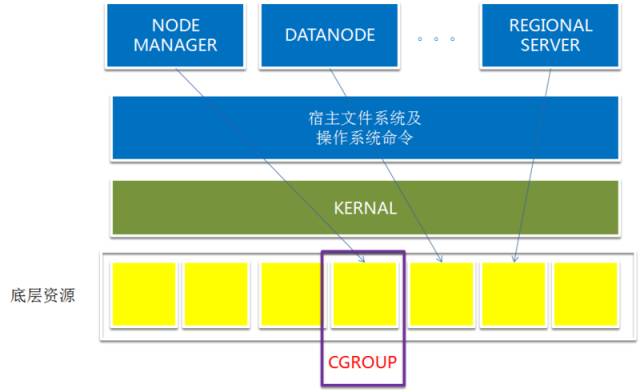
只有革命性的底层技术,才能带来上层应用的突飞猛进。不过 CGROUP 是 2007 年就有了第一个版本,而 Docker 是 2013 年才出第一个版本,中间间隔了 6 年。
对于内存、CPU 等资源,Hadoop 主要用的就是这两种资源隔离的方式。其实想想这两种方法仍然挺朴素的,我也相信,底层一定会有更好的技术来支持资源隔离。
调度算法
然后再讲讲调度算法。
在 YARN 之前,操作系统、数据库都要用到调度算法,所以调度算法在工程领域有很多学术论文可以参考。
下面只是简单以公平调度为例看一下大概是怎么回事。

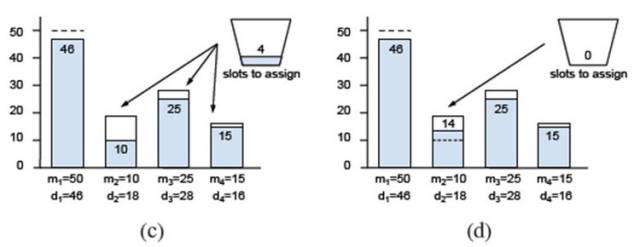
根据上面的图示,公平调度是在不同的 POOL 之间,首先满足最小需求阈值,当实际需求低于最小需求阈值时,以实际需求为准。而实际需求高于最小保证的用量时,仅仅满足最小用量,在整个请求者的最小用量得到满足之后,再进行第二轮分配。第二轮分配以一个“迫切度”来做指标,即实际需求和已满足的资源差额除以实际需求,需求最为迫切的分配剩余的资源。
以上策略是在不同池子中的竞争算法。在同一个池子中,按照时间片轮转的方式为不同用户分配资源。
多租户环境的安全性实现
再讲讲多租户环境的安全性实现。
安全性话题很大,先挑 3 个点讲一下:
- authentication
- authorzation
- 服务层面的 impersonation 和 delegation
首先讲第一个点 authentication。
什么是 authentication 呢?authentication 就是如何证明你是你?可以叫身份验证。
最常见的用户单一服务环境,用的是 simple authentication,就是简单身份验证,方法是用户名加密码的方式。以一个网站服务为例,

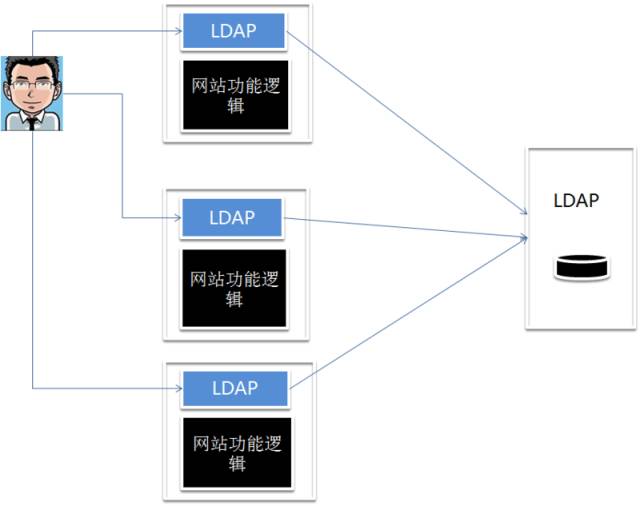
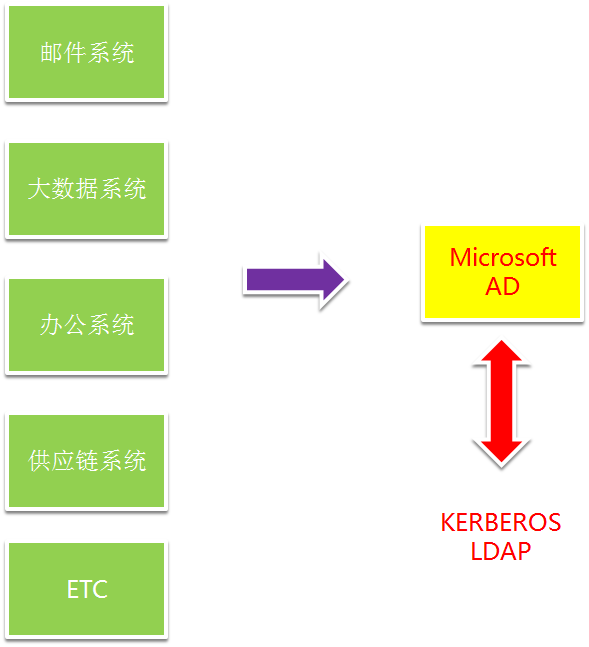
那这种验证方式,网络功能逻辑和身份验证是两个非常解耦的功能,在一个多服务或者是海量服务的环境下,是有严重的效率问题的。看下图。

有 N 个服务,就会有 N 套用户信息系统。用户就得记住 N 套密码。而 LDAP 的用户密码验证把验证密码的逻辑后移了,委托给了 LDAP 服务。使得多套密码验证只需要一个用户名和密码。
现在的系统有很多微服务,服务之间的解耦调用,服务和服务之间也需要做身份认证。当请求认证身份的主体由一个“人”变成一个服务的时候应该怎么办呢?怎么防止恶意的服务程序来伪装成一个另一个服务的客户端非法请求数据呢?当海量服务相互调用的时候,采用名称和密码的方式显然是不可行的,所以 KERBEROS 使用秘钥。
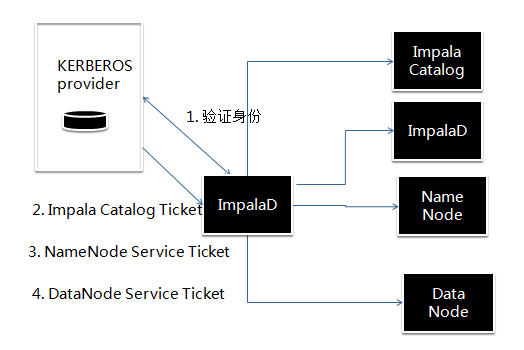
服务在 KDC 上认证,访问其他服务是通过向 KDC 申请 ticket 的方法。秘钥采用非对称加密,秘钥信息不会通过网络传播。KDC 不知道 client 和服务之间通信的秘钥,服务也不知道 client 和 KDC 之间的秘钥。客户的秘钥不会经过服务。
以上是多租户的认证方式。
权限控制
再讲权限控制,在通信层的 SASL 的实现方式 GSSAPI,在底层支持了 impersonation,如下图。

Impernation 也就是说,前端服务连接到后端服务,前端服务根据他本身登录用户的不同,伪装成 Login User 在后端服务上执行任务。这样做的好处是,便于做权限控制,也便于审计用户的行为。在一个安全性要求比较高的平台上,要注意集成到平台上的前端服务是否支持这个特性,否则这个层面上恶意用户可以绕开权限控制。

还有一种方式叫 delegation,代理的方式。譬如 rstudio 在连接 SPARK 的时候就是采用的这种方式。

RStudio 的用户委托 RStudio 在与 Spark 的每个用户 session 建立之前,先到服务器登录用户的 home 目录地下做认证,拿到 ticket,然后到后端服务上执行任务。
企业办公系统,Windows 是不二之选,而其他用户认证和信息都是在微软的 active directory 里面的。 Active Directory 集成了 LDAP 和 KERBEROS 的实现。所以多租户的大数据系统的会跟 AD 集成来为企业用户提供 single sign on。
权限管理
再讲一下多租户的权限管理,以 Apache Sentry 为例。
Apache Sentry 是一个开放性的服务,通过实现 Sentry 的接口可以为新的分布式服务增加权限控制的功能。目前 Hive,Impala,HBASE 等都可以用 Sentry 进行权限控制。
看一下,AD 和 Sentry 的概念图,其中重叠部分是 GROUP。
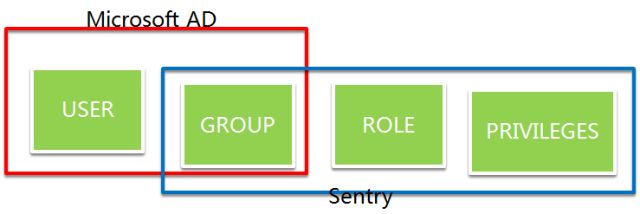
Sentry 通过为 AD 里面的 Group 做 Role 的映射来赋予权限。当你企业的权限模型定义完备之后,那么只需要在 AD 里面操作 User 和 Group 的关系来为用户赋予权限了,这是非常简单的 windows 配置。
Sentry 通过一个接口协议为所有的服务提供权限定义和权限校验。

Hive 是一个 MR 或者 Spark 处理引擎的 SQL 解释接口,那么用户可能绕开 Hive 的权限直接去 HDFS 上访问数据。HDFS 的 name node 上的 Sentry 插件解决了这个问题。

Name Node 上的 Sentry 的插件会去把 Hive 的权限控制语转换成 HDFS 层面的 ACL。HDFS 层面的 ACL 和 Linux 的类似的,都是扩展了简单的 POSIX 用户权限管理。ACL 跟 Linux 上的 ACL 原理一致,都是基于 POSIX 权限管理的补充。
企业级数据平台的实践
数据平台需要有哪些参与者?用户类型。
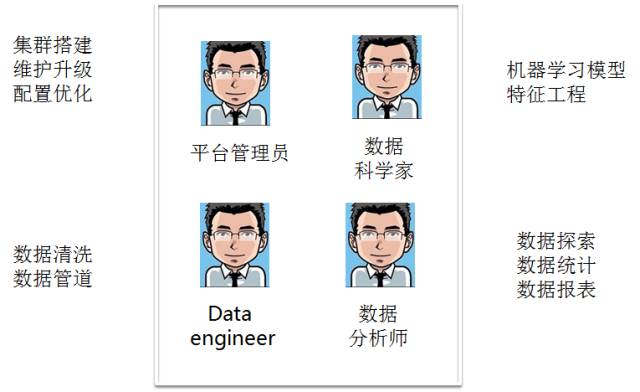
现在对于软件开发生命周期都有比较成熟的系统和工具。源代码管理工具,软件开发版本特性 Bug 管理,开发环境和可持续交付与集成的测试框架和自动化部署。
数据管理和数据开发比较欠缺一个行业的标准流程。数据管理包括对于数据的权限控制和内容管理。在一个多租户的环境下,经年累月平台上会出现越来越多的数据,不知道 owner 是谁,也没有数据的版本,长久以往一个平台的环境就逐渐被破坏了。
如何进行数据管理?来参考下图的例子。
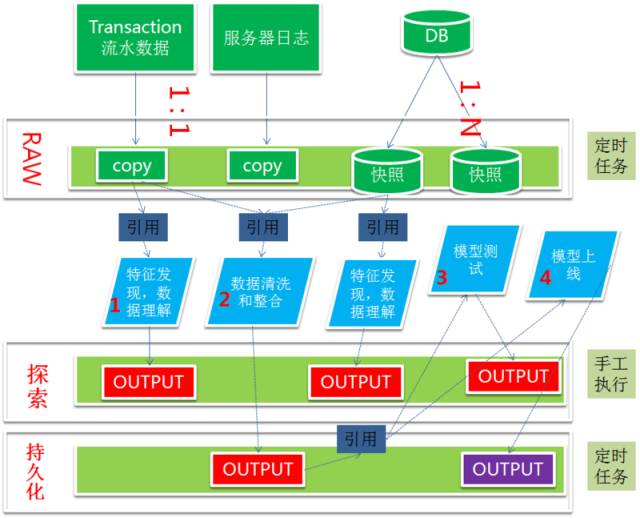
大数据平台是只写的系统,不能在文件内部进行更新。数据源主要有两个类别,一个是历史记录,例如服务器的日志或者是流水账;另外一个类别是元数据快照,快照的频率越高,那么数据量会线性增长。中间数据有平台应用存储的中间结果,也可能是平台服务的中间结果,资源文件、日志记录、服务函数库等等。
上图的例子中,可以按照数据特征把大数据平台划分成几个区域。RAW 这个区域的特点是存储的是日志或者流水,或者元数据快照,这块数据的特点是数据量大,内容比较稳定不易改变。数据是由 ETL 或者数据管道来的。
第二层主要是用于一些测试的目的,在这个区域发现数据的特征,发现一些坏数据,或者发现数据的分布规律,或者是用来测试你的数据处理逻辑,数据格式是否得当。在这个区域用户可以比较自由的发挥。也可以用来测试机器学习模型。
第三层是持久化层。主要是用来生产一些数据清洗完毕的宽表,统计结果。也用来跑每天的模型。
这么分层的好处是,在实际使用中,往往是“探索”这一类需求把数据平台从 data lake 变成 data swamp。
“探索层”可以配一个脚本,扫描文件最近更新时间。可以参考如下配置,1 个月的归档并发送邮件提醒给数据 owner,二个月的时候发送删除提醒,3 个月的时候删除并发送邮件提醒。
“RAW”和“持久化”两个区,需要有适合于企业的配套的流程。
1. checklist,问例如下面的问题:
- 该数据处理流程的元数据?
- 该数据处理流程的 owner?
- 该数据属于哪个项目?
- 该数据的依赖和下游依赖?
2. 写入这个区的数据必须要 approval,这两个区的数据的元数据和数据相关的信息应该有程序化的集中的管理。
对于“持久化”区,以项目为单位。当项目开始时,就需要有项目的退出和结束策略。不同的项目之间因不要有数据依赖。当项目结束时,需要有方法根据项目的名称找到所有的处理逻辑和产生的数据,然后删除这些流程和对应的数据。
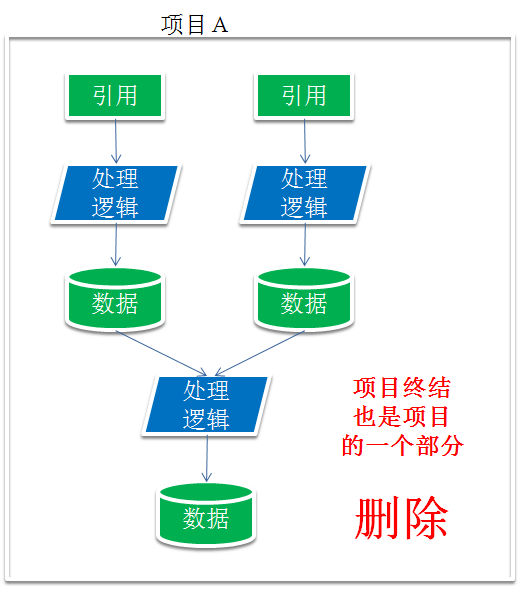
流程的执行需要有软件和系统来保证,“用户不应该做”和“用户做不了”是两码事,目前这方面还缺少数据管理的配套软件和系统。这也是在实践中碰到的难点。
在大数据平台实践的过程中,发现的问题还有一些是来源于底层系统的集成。譬如 Linux 和 Windows 做 Single Sign On 的时候,SSSD 的 BUG,Linux 平台与 window AD 集成的问题。
选型,除了 Cloudera 同类型的方案,Amazon 的 EMR 也是不错的选择。
bluedata 的基于 container 和 mesos 的大数据设计很好,但是具体实现还在成熟当中。而且 Cloudera 等一些大数据发行商目前并不打算支持基于 container 的方案。多久才能带来价值?这个问题很难回答,其一价值很难度量,没有办法做 AB 测试,但是我想说的是,在数据驱动的这个浪潮下,只有在实践和学习中拥抱数据,事实上很多企业也是这样做的。
本文作者:陈冬
来源:51CTO