协程学习笔记
1 为什么会有协程
在我们现在 CS,BS 开发模式下,服务器的吞吐量是一个很重要的参数。其实吞吐量是 IO 处理时间加上业务处理。为了简单起见,比如,客户端与服务器之间是长连接的,客户端定期给服务器发送心跳包数据。客户端发送一次心跳包到服务器,服务器更新该新客户端状态的。心跳包发送的过程,业务处理时长等于 IO 读取(RECV 系统调用)加上业务处理(更新客户状态)。吞吐量等于 1s 业务处理次数。

业务处理(更新客户端状态)时间,业务不一样的,处理时间不一样,我们就不做讨论。 那如何提升 recv 的性能。若只有一个客户端,recv 的性能也没有必要提升,也不能提升。若在有百万计的客户端长连接的情况,我们该如何提升。以Linux 为例,在这里需要介绍一个“网红”就是 epoll。服务器使用 epoll 管理 百万计的客户端长连接,代码框架如下:
while (1) {
int nready = epoll_wait(epfd, events, EVENT_SIZE, -1);
for (i = 0;i < nready;i ++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
int connfd = accept(listenfd, xxx, xxxx);
setnonblock(connfd);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = connfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev);
} else {
handle(sockfd);
}
}
}对于响应式服务器,所有的客户端的操作驱动都是来源于这个大循环。来源于 epoll_wait 的反馈结果。 对于服务器处理百万计的 IO。Handle(sockfd)实现方式有两种。
第一种,handle(sockfd)函数内部对 sockfd 进行读写动作。代码如下
int handle(int sockfd) {
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
handle 的 io 操作(send,recv)与 epoll_wait 是在同一个处理流程里面的。 这就是 IO 同步操作。
优点: 1. sockfd 管理方便。 2. 操作逻辑清晰。
缺点:1. 服务器程序依赖 epoll_wait 的循环响应速度慢。 2. 程序性能差
第二种,handle(sockfd)函数内部将 sockfd 的操作,push 到线程池中,代码如下:
int thread_cb(int sockfd) {
// 此函数是在线程池创建的线程中运行。
// 与 handle 不在一个线程上下文中运行
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
int handle(int sockfd) {
//此函数在主线程 main_thread 中运行
//在此处之前,确保线程池已经启动。
push_thread(sockfd, thread_cb); //将 sockfd 放到其他线程中运行。
}
Handle 函数是将 sockfd 处理方式放到另一个已经其他的线程中运行,如此做法,将 io 操作(recv,send)与 epoll_wait 不在一个处理流程里面,使得 io 操作(recv,send)与 epoll_wait 实现解耦。这就叫做 IO 异步操作。
优点: 1. 子模块好规划。 2. 程序性能高。
缺点: 正因为子模块好规划,使得模块之间的 sockfd 的管理异常麻烦。每一个子线程都需要管理好 sockfd,避免在 IO 操作的时候,sockfd 出现关闭或其他异常。
2 异步运行的流程是什么
当我们需要异步调用的时候,我们会创建一个协程。比如 accept 返回一个新的 sockfd,创建一个客户端处理的子过程。再比如需要监听多个端口的时候,创建一个 server 的子过程,这样多个端口同时工作的,是符合微服务的架构的。创建协程的时候,进行了如何的工作?创建 API 如下:
int nty_coroutine_create(nty_coroutine **new_co, proc_coroutine func, void *arg)
参数 1:nty_coroutine **new_co,需要传入空的协程的对象,这个对象是由内部创建的,并且在函数返回的时候,会返回一个内部创建的协程对象。
参数 2:proc_coroutine func,协程的子过程。当协程被调度的时候,就会执行该函数。
参数 3:void *arg,需要传入到新协程中的参数。
协程不存在亲属关系,都是一致的调度关系,接受调度器的调度。调用 create API 就会创建一个新协程,新协程就会加入到调度器的就绪队列中。
3 协程的原语操作
在协程的上下文 IO 异步操作(nty_recv,nty_send)函数,步骤如下: 1. 将 sockfd 添加到 epoll 管理中。 2. 进行上下文环境切换,由协程上下文 yield 到调度器的上下文。 3. 调度器获取下一个协程上下文。Resume 新的协程 IO 异步操作的上下文切换的时序图如下:
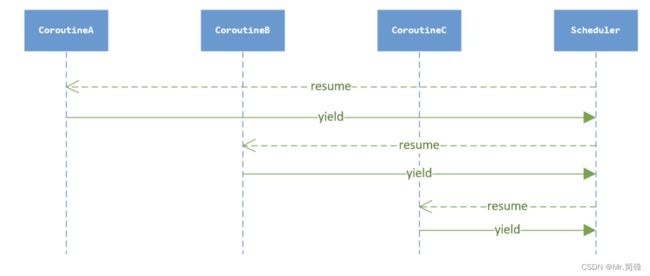
遇到io操作,io没有就绪,就让出到调度器,由调度器决定下一个协程的运行。有Io就绪就处理io。
回调协程的子过程
x86_64 的寄存器有 16 个 64 位寄存器,分别是:%rax, %rbx, %rcx, %esi, %edi, %rbp, %rsp, %r8, %r9, %r10, %r11, %r12, %r13, %r14, %r15。 %rax 作为函数返回值使用的。 %rsp 栈指针寄存器,指向栈顶 %rdi, %rsi, %rdx, %rcx, %r8, %r9 用作函数参数,依次对应第 1 参数,第 2 参数。。。 %rbx, %rbp, %r12, %r13, %r14, %r15 用作数据存储,遵循调用者使用规则,换句话说,就是随便用。调用子函数之前要备份它,以防它被修改%r10, %r11 用作数据存储,就是使用前要先保存原值。
以 NtyCo 的实现为例,来分析这个过程。CPU 有一个非常重要的寄存器叫做 EIP,用来存储 CPU 运行下一条指令的地址。我们可以把回调函数的地址存储到 EIP 中,将相应的参数 存储到相应的参数寄存器中。实现子过程调用的逻辑代码如下:
void _exec(nty_coroutine *co) {
co->func(co->arg); //子过程的回调函数
}
void nty_coroutine_init(nty_coroutine *co) {
//ctx 就是协程的上下文
co->ctx.edi = (void*)co; //设置参数
co->ctx.eip = (void*)_exec; //设置回调函数入口
//当实现上下文切换的时候,就会执行入口函数_exec , _exec 调用子过程 func
}
协程的核心原语操作:create, resume, yield。协程的原语操作有 create 怎么没有 exit?以 NtyCo 为例,协程一旦创建就不能有用户自己销 毁,必须得以子过程执行结束,就会自动销毁协程的上下文数据。以_exec 执 行入口函数返回而销毁协程的上下文与相关信息。co->func(co->arg) 是子 过程,若用户需要长久运行协程,就必须要在 func 函数里面写入循环等操 作。所以 NtyCo 里面没有实现 exit 的原语操作。
1. 调度器是否存在,不存在也创建。调度器作为全局的单例。将调度 器的实例存储在线程的私有空间 pthread_setspecific。
2. 分配一个 coroutine 的内存空间,分别设置 coroutine 的数据项,栈空间,栈大小,初始状态,创建时间,子过程回调函数,子 过程的调用参数。
3. 将新分配协程添加到就绪队列 ready_queue 中
实现代码如下:
int nty_coroutine_create(nty_coroutine **new_co, proc_coroutine func,
void *arg) {
assert(pthread_once(&sched_key_once,
nty_coroutine_sched_key_creator) == 0);
nty_schedule *sched = nty_coroutine_get_sched();
if (sched == NULL) {
nty_schedule_create(0);
sched = nty_coroutine_get_sched();
if (sched == NULL) {
printf("Failed to create scheduler\n");
return -1;
}
}
nty_coroutine *co = calloc(1, sizeof(nty_coroutine));
if (co == NULL) {
printf("Failed to allocate memory for new coroutine\n");
return -2;
}
//
int ret = posix_memalign(&co->stack, getpagesize(),
sched->stack_size);
if (ret) {
printf("Failed to allocate stack for new coroutine\n");
free(co);
return -3;
}
co->sched = sched;
co->stack_size = sched->stack_size;
co->status = BIT(NTY_COROUTINE_STATUS_NEW); //
co->id = sched->spawned_coroutines ++;
co->func = func;
co->fd = -1;
co->events = 0;
co->arg = arg;
co->birth = nty_coroutine_usec_now();
*new_co = co;
TAILQ_INSERT_TAIL(&co->sched->ready, co, ready_next);
return 0;
}
yield: 让出 CPU。
void nty_coroutine_yield(nty_coroutine *co)
参数:需要恢复运行的协程实例 调用后该函数也不会立即返回,而是切换到运行协程实例的 yield 的位 置。返回是在等协程相应事务处理完成后,主动 yield 会返回到 resume 的地方。
协程的实现之切换
x86_64 的寄存器有 16 个 64 位寄存器,分 别是:%rax, %rbx, %rcx, %esi, %edi, %rbp, %rsp, %r8, %r9, %r10, %r11, %r12, %r13, %r14, %r15。
%rax 作为函数返回值使用的。
%rsp 栈指针寄存器,指向栈顶
%rdi, %rsi, %rdx, %rcx, %r8, %r9 用作函数参数,依次对应第 1 参数,第 2 参数。。。
%rbx, %rbp, %r12, %r13, %r14, %r15 用作数据存储,遵循调用者使用规则,换句话说,就是随便用。调用子函数之前要备份它,以防它被修改
%r10, %r11 用作数据存储,就是使用前要先保存原值。
上下文切换,就是将 CPU 的寄存器暂时保存,再将即将运行的协程的上下文寄存器,分别 mov 到相对应的寄存器上。此时上下文完成切换。如下图所示:
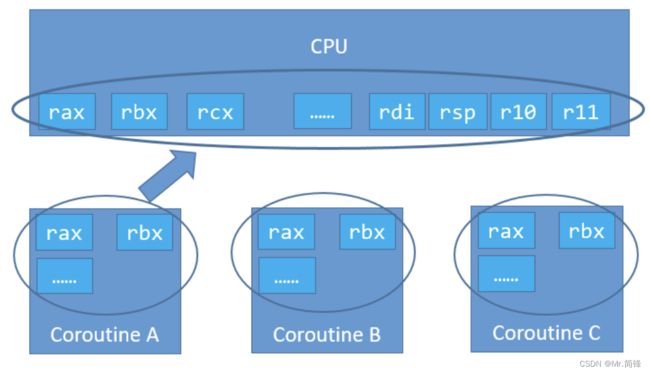
切换_switch 函数定义:
int _switch(nty_cpu_ctx *new_ctx, nty_cpu_ctx *cur_ctx);
参数 1:即将运行协程的上下文,寄存器列表
参数 2:正在运行协程的上下文,寄存器列表
我们 nty_cpu_ctx 结构体的定义,为了兼容 x86,结构体项命令采用的是 x86 的寄存器名 字命名。
typedef struct _nty_cpu_ctx {
void *esp; //
void *ebp;
void *eip;
void *edi;
void *esi;
void *ebx;
void *r1;
void *r2;
void *r3;
void *r4;
void *r5;
} nty_cpu_ctx;_switch 返回后,执行即将运行协程的上下文。是实现上下文的切换
_switch 的实现代码:
0: __asm__ (
1: " .text \n"
2: " .p2align 4,,15 \n"
3: ".globl _switch \n"
4: ".globl __switch \n"
5: "_switch: \n"
6: "__switch: \n"
7: " movq %rsp, 0(%rsi) # save stack_pointer \n"
8: " movq %rbp, 8(%rsi) # save frame_pointer \n"
9: " movq (%rsp), %rax # save insn_pointer \n"
10: " movq %rax, 16(%rsi) \n"
11: " movq %rbx, 24(%rsi) # save rbx,r12-r15 \n"
12: " movq %r12, 32(%rsi) \n"
13: " movq %r13, 40(%rsi) \n"
14: " movq %r14, 48(%rsi) \n"
15: " movq %r15, 56(%rsi) \n"
16: " movq 56(%rdi), %r15 \n"
17: " movq 48(%rdi), %r14 \n"
18: " movq 40(%rdi), %r13 # restore rbx,r12-r15 \n"
19: " movq 32(%rdi), %r12 \n"
20: " movq 24(%rdi), %rbx \n"
21: " movq 8(%rdi), %rbp # restore frame_pointer \n"
22: " movq 0(%rdi), %rsp # restore stack_pointer \n"
23: " movq 16(%rdi), %rax # restore insn_pointer \n"
24: " movq %rax, (%rsp) \n"
25: " ret \n"
26: );按照 x86_64 的寄存器定义,%rdi 保存第一个参数的值,即 new_ctx 的值,%rsi 保存第二个参数的值,即保存 cur_ctx 的值。X86_64 每个寄存器是 64bit,8byte。
Movq %rsp, 0(%rsi) 保存在栈指针到 cur_ctx 实例的 rsp 项
Movq %rbp, 8(%rsi)
Movq (%rsp), %rax #将栈顶地址里面的值存储到 rax 寄存器中。Ret 后出栈,执行栈顶 Movq %rbp, 8(%rsi) #后续的指令都是用来保存 CPU 的寄存器到 new_ctx 的每一项中
Movq 8(%rdi), %rbp #将 new_ctx 的值
Movq 16(%rdi), %rax #将指令指针 rip 的值存储到 rax 中
Movq %rax, (%rsp) # 将存储的 rip 值的 rax 寄存器赋值给栈指针的地址的值。
ret # 出栈,回到栈指针,执行 rip 指向的指令。 上下文环境的切换完成。
4 协程的定义
设计一个协程的运行体 R 与运行体调度器 S 的结构体
1. 运行体 R:包含运行状态{就绪,睡眠,等待},运行体回调函数, 回调参数,栈指针,栈大小,当前运行体
2. 调度器 S:包含执行集合{就绪,睡眠,等待} 这道设计题拆分两个个问题,一个运行体如何高效地在多种状态集合更 换。调度器与运行体的功能界限。
新创建的协程,创建完成后,加入到就绪集合,等待调度器的调度;协程 在运行完成后,进行 IO 操作,此时 IO 并未准备好,进入等待状态集合;IO 准 备就绪,协程开始运行,后续进行 sleep 操作,此时进入到睡眠状态集合。
就绪(ready),睡眠(sleep),等待(wait)集合该采用如何数据结构来存 储?
就绪(ready)集合并不没有设置优先级的选型,所有在协程优先级一致,所 以可以使用队列来存储就绪的协程,简称为就绪队列(ready_queue)。
睡眠(sleep)集合需要按照睡眠时长进行排序,采用红黑树来存储,简称睡眠树(sleep_tree)红黑树在工程实用为, key 为睡眠时长, value 为对应的协程结点。
等待(wait)集合,其功能是在等待 IO 准备就绪,等待 IO 也是有时长的, 所以等待(wait)集合采用红黑树的来存储,简称等待树(wait_tree),此处借鉴 nginx 的设计。
数据结构如下图所示:
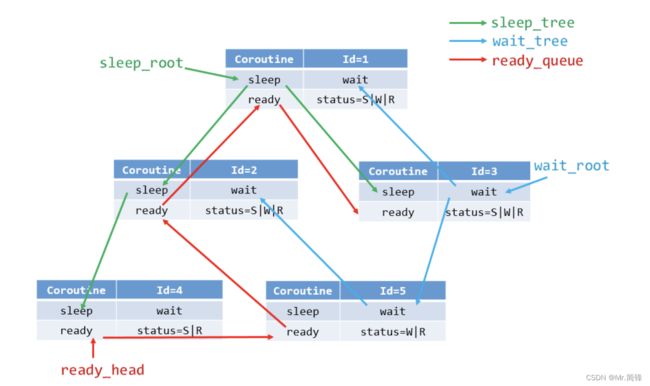
Coroutine 就是协程的相应属性,status 表示协程的运行状态。sleep 与 wait 两颗红黑树,ready 使用的队列,比如某协程调用 sleep 函数,加入睡 眠树(sleep_tree),status |= S 即可。比如某协程在等待树(wait_tree) 中,而 IO 准备就绪放入 ready 队列中,只需要移出等待树(wait_tree),状态更改 status &= ~W 即可。有一个前提条件就是不管何种运行状态的协程, 都在就绪队列中,只是同时包含有其他的运行状态。
每一协程都需要使用的而且可能会不同属性的,就是协程属性。每一协程 都需要的而且数据一致的,就是调度器的属性。比如栈大小的数值,每个协程 都一样的后不做更改可以作为调度器的属性,如果每个协程大小不一致,则可 以作为协程的属性。 用来管理所有协程的属性,作为调度器的属性。比如 epoll 用来管理每一 个协程对应的 IO,是需要作为调度器属性。
定义一个协程结构体需要多少域,我们描述了每一 个协程有自己的上下文环境,需要保存 CPU 的寄存器 ctx;需要有子过程的回 调函数 func;需要有子过程回调函数的参数 arg;需要定义自己的栈空间 stack;需要有自己栈空间的大小 stack_size;需要定义协程的创建时间 birth;需要定义协程当前的运行状态 status;需要定当前运行状态的结点 (ready_next, wait_node, sleep_node);需要定义协程 id;需要定义调 度器的全局对象 sched。 协程的核心结构体如下:
typedef struct _nty_coroutine {
nty_cpu_ctx ctx;
proc_coroutine func;
void *arg;
size_t stack_size;
nty_coroutine_status status;
nty_schedule *sched;
uint64_t birth;
uint64_t id;
void *stack;
RB_ENTRY(_nty_coroutine) sleep_node;
RB_ENTRY(_nty_coroutine) wait_node;
TAILQ_ENTRY(_nty_coroutine) ready_next;
TAILQ_ENTRY(_nty_coroutine) defer_next;
} nty_coroutine;
调度器是管理所有协程运行的组件,协程与调度器的运行关系。
调度器的属性,需要有保存 CPU 的寄存器上下文 ctx,可以从协程运行状态 yield 到调度器运行的。从协程到调度器用 yield,从调度器到协程用 resume 以下为协程的定义。
ypedef struct _nty_coroutine_queue nty_coroutine_queue;
typedef struct _nty_coroutine_rbtree_sleep nty_coroutine_rbtree_sleep;
typedef struct _nty_coroutine_rbtree_wait nty_coroutine_rbtree_wait;
typedef struct _nty_schedule {
uint64_t birth;
nty_cpu_ctx ctx;
struct _nty_coroutine *curr_thread;
int page_size;
int poller_fd;
int eventfd;
struct epoll_event eventlist[NTY_CO_MAX_EVENTS];
int nevents;
int num_new_events;
nty_coroutine_queue ready;
nty_coroutine_rbtree_sleep sleeping;
nty_coroutine_rbtree_wait waiting;
} nty_schedule;5 多核的模式
协程不能设置cpu亲缘性,可以借助线程和进程来实现。
6 协程的性能
不是协程的性能高,而是异步的性能高。
协程不能超越reactor/epoll,他的调度器底层是epoll,他只能无限接近于epoll,因为中间会有一些切换。
7 要有哪些案例?
在做网络 IO 编程的时候,有一个非常理想的情况,就是每次 accept 返回 的时候,就为新来的客户端分配一个线程,这样一个客户端对应一个线程。就 不会有多个线程共用一个 sockfd。每请求每线程的方式,并且代码逻辑非常易 读。但是这只是理想,线程创建代价,调度代价就呵呵了。 先来看一下每请求每线程的代码如下:
while(1) {
socklen_t len = sizeof(struct sockaddr_in);
int clientfd = accept(sockfd, (struct sockaddr*)&remote, &len);
pthread_t thread_id;
pthread_create(&thread_id, NULL, client_cb, &clientfd);
}如果我们有协程,我们就可以这样实现。参考代码如下:
while (1) {
socklen_t len = sizeof(struct sockaddr_in);
int cli_fd = nty_accept(fd, (struct sockaddr*)&remote, &len);
nty_coroutine *read_co;
nty_coroutine_create(&read_co, server_reader, &cli_fd);
}
NtyCo 封装出来了若干接口,一类是协程本身的,二类是 posix 的异步封装 协程 API:while
1. 协程创建
int nty_coroutine_create(nty_coroutine **new_co, proc_coroutine func, void *arg)
2. 协程调度器的运行
void nty_schedule_run(void)
POSIX 异步封装 API:
int nty_socket(int domain, int type, int protocol)
int nty_accept(int fd, struct sockaddr *addr, socklen_t *len)
int nty_recv(int fd, void *buf, int length)
int nty_send(int fd, const void *buf, int length)
int nty_close(int fd)接口格式与 POSIX 标准的函数定义一致。