JAVAWEB-NOTE03:JSP、EL、JSTL、 bean组件的概念、Maven、cookie/session、MySQL数据库事务
1 JSP、EL、JSTL
1.1 JSP概述
1.1.1 什么是JSP
JSP和Servlet都是由SUN公司提供的动态Web资源开发技术。 (可以看成能写java代码的网页)
JSP看起来像一个HTML,但和HTML不同的是,JSP中可以书写Java代码,可以通过Java代码展示动态的数据。
静态Web资源:任何人在任何条件下访问时,看到的都是相同的效果,这样的资源叫做静态Web资源。(html、css、js等)
动态Web资源:不同的人,在不同的条件下访问时,看到的都是不同的效果,这样的资源叫做动态Web资源。(Servlet、jsp、php、.NET等)
JSP本质上是一个Servlet程序
思考1:为什么要学习JSP?
-
Servlet是一段Java程序,适合处理业务逻辑,但是Servlet不适合向浏览器输出一个html网页。
虽然他也可以输出html网页,但是因为直接在Servlet里写比较复杂,用jsp它会自己生成这样更简单. 他最终还是通过servlet在想浏览器输出一个网页,但是这个代码是生成的,而我们在编写时像一个html一样去编写一个网页,去编写一个jsp. 写完后它会翻译成servlet,servlet会将里面的html一行一行输出。不用自己写out.write方法输出。 上面那行是jsp的特有内容浏览器无法解析。
业务逻辑:比如下一个订单,先要判断仓库会不会有货. 输入一个密码,要判断格式。
-
html可以作为页面返回,但是html是一个静态Web资源,无法展示动态数据。
-
而JSP也是页面的开发技术,也可以作为页面返回,并且JSP中可以书写Java代码,可以通过Java代码展示动态的数据。
-
因此,JSP的出现即解决了Servlet不适合输出页面的问题,也解决了HTML无法展示动态数据的问题!
-
只用jsp做中小型项目,会造成结构混乱,后期维护很麻烦。已被废弃
思考2:为什么说JSP本质是一个Servlet? jsp在第一次访问时会翻译成servlet
浏览器本身是一个html解析器。 88888888888888(jsp可以当成是一个html也可以当成是servlet)
浏览器不解析java代码,访问jsp时他不会直接把jsp交给浏览器,因为jsp中既可写java代码,也可以包含jsp特有的指令或元素。因此 浏览器访问html网页和jsp文件过程是不一样的?
html:是由服务器发送给浏览器,由浏览器来解析。
jsp:是由在服务器端进行翻译在执行,最后发送给浏览器一个网页。访问的是jsp最后发送给浏览器的是网页。
在JSP第一次被访问时,会翻译成一个Servlet程序,servlet程序里面会想浏览器输出一个网页。访问JSP后看到的html网页,其实是翻译后的Servlet执行的结果。(也就是说,访问JSP后看到的网页,是JSP翻译后的Servlet输出到浏览器的。)
在javaDevelop ----tomact-----work(jsp翻译后的目录)— …
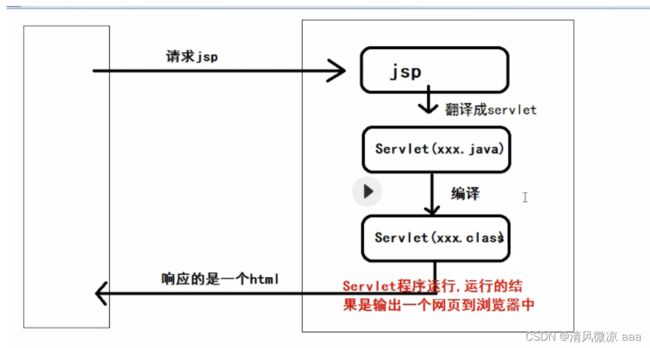
1.1.2 JSP执行过程
访问服务器中的JSP文件,其执行过程为:
-
当浏览器请求服务器中的某一个JSP文件(例如:localhost:8080/day11-jsp/test.jsp),服务器会根据请求资源的路径去寻找该文件:
-
如果找到了,JSP翻译引擎会将JSP翻译成一个Servlet程序 JSP---->编译成Servlet(xxx.java文件)—>编译成 servlet(xxx.class 文件 ) ,然后Servlet程序再执行,执行的结果是向浏览器输出一个HTML网页!
jsp翻译后的文件在tomact的work目录
-
如果没有找到,服务器将会响应一个404页面,通知浏览器请求的资源不存在。
访问服务器中的HTML文件,其执行过程为:
- 当浏览器请求服务器中的某一个HTML文件时(例如:localhost:8080/day11-jsp/test.html),服务器会根据请求资源的路径去寻找该文件:
- 如果找到了,服务器会将html文件的内容作为响应实体发送给浏览器,浏览器再解析html并显示在网页上。
- 如果没有找到,服务器将会响应一个404页面,通知浏览器请求的资源不存在。
1.1.3 修改JSP默认编码
Eclipse中创建JSP默认使用的是latin-1码表,而这个码表中是没有中文数据的,如果在JSP中书写中文数据,会出现乱码提示。
创建jsp文件: 它既可以写java代码也可以写html网页,在动态项目下的WebCount目录下—右键other—jsp File 后缀名是.jsp
而servlet本质是java程序,写在src源码目录下
将JSP使用的编码修改为utf-8,步骤如下:点击菜单栏中的 window --> Preferences,出现如下窗口:

1.2 JSP语法
1.2.1 模版元素
模板元素是指写在JSP中的html内容
或者除了JSP特有内容以外的其他内容称之为模板元素
模板元素在翻译后的Servlet中,被out.write原封不动的发送给浏览器,由浏览器负责解析并显示。

第一行是声明的jsp的属性信息.
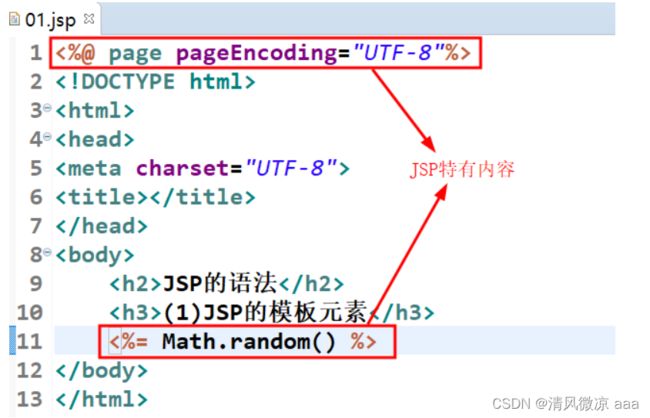
1.2.2 JSP表达式
格式:<%= 常量、变量、表达式 %>
作用:计算表达式的结果,将结果输出到浏览器中,由浏览器负责解析并显示。
<%= "Hello JSP..." %>
<% String name = "林青霞"; %> jsp的脚本片段
<%= name %>
<%= 100+123 %>
<%= Math.random() %> 伪随机数:通过算法算出来的随机数
注意:jsp的表达式中可以书写符合java语法的代码,但是不能写java语句,内部也不能写分号 ; .
1.2.3 JSP脚本片段
格式:<% 若干Java语句 %>
作用:在翻译后的Servlet中,将脚本片段中的Java语句复制粘贴到Servlet的对应的位置执行。例如:
在JSP中代码如下:
<%
for(int i=0; i<5; i++){
out.write("Hello JSP...
"); //往浏览器中写出数据,out
}
%> 加上<%服务器才会当作代码,写在外面会变成普通文本直接输出
在翻译后的Servlet中代码如下:
... 翻译后会把<% 去掉
for(int i=0; i<5; i++){
out.write("Hello JSP...
");
}
...
另外,在某一个脚本片段中的Java代码可以是不完整的,但是在JSP中所有的脚本片段加在一起,必须是完整符合Java语法。例如,在JSP中代码如下:
<% for(int i=0;i<5;i++){ %>
Hello JSP~~~
<% } %>
在翻译后的Servlet中:
for(int i=0;i<5;i++){
out.write("\r\n");
out.write("\t\t\tHello JSP~~~
\r\n");
out.write("\t");
}
1.2.4 JSP注释
格式:<%-- JSP注释内容 --%>
作用:(1)为代码添加解释说明 (2)将一些暂时不需要执行的代码注释掉。
在JSP翻译时,注释内容不会参与翻译,而是直接被丢弃
面试题:考察JSP中的JSP注释、Java注释、html注释
<%--
<% out.write( "aaaaa
" ); %>
--%>
<% //out.write( "bbbbb
" ); %> 注意java注释写在标签里面
<%--
<% name = "郭富城"; %> 这个用html注释还会显示郭富城,用jsp注释
--%>
<%= name %>
问题:(1)上面输出的三行内容,在访问时,会显示哪一行内容? 都不会
第一行被JSP注释给注释了,JSP注释的内容不会参与翻译,也不会执行,更不会发送给浏览器,也不会在浏览器上显示。
第二行被Java注释给注释了,放在脚本片段中的内容会参与翻译,会将其中的Java代码复制到翻译后的Servlet中,但由于代码被注释了,所以不会执行,也不会发送给浏览器,更不会在浏览器上显示。
第三行被html注释给注释了,html注释在JSP中是模板元素,注释本身会发送给浏览器,注释中的脚本片段会参与翻译,其中的java代码也会执行,也会将内容(ccccc)发送给浏览器,但由于发送到浏览器后的ccccc被html注释包裹,因此也不会显示在浏览器上。
(2)上面输出的三行内容,哪一行会发送到浏览器中?(不管是否显示)
其中第三行内容会发送到浏览器中,但不会显示,因为前后有html注释。
1.2.5 JSP指令
指令的格式:<%@ 指令名称 若干属性声明... %>
指令的作用:用于指挥JSP解析引擎如何将一个JSP翻译成一个Servlet程序。
1、page指令:用于声明JSP的基本属性信息(比如JSP使用的编码,JSP使用的开发语言等)
每个jsp必有page指令.通常放在第一行.page写多个的情况是 必须有import属性,一般是导报时写多个.
不导包page指令通常只写一个.
<%@ page language="java"%>
-- language属性用于指定当前JSP使用的开发语言,目前只有java语言支持
可以省略不写默认java.
<%@ page import="java.util.Date"%>
-- import属性用于导入包,如果不导入包,在使用其他包下的类时,就需要在类名前面加上包路径,例如:
java.util.Date date = new java.util.Date();这样写太麻烦
导包快捷键: 在紧跟的类名后 如:date后 alt+/
<%@ page pageEncoding="UTF-8"%>
-- pageEncoding属性是用于指定当前JSP使用的编码,Eclipse工具会根据这个编码保存JSP文件。
保证pageEncoding属性指定的编码和JSP文件保存时使用的编码相同,可以避免JSP文件出现乱码!
2、taglib指令:用于引入JSTL标签库或者其他的自定义标签库
后面讲解JSTL标签库时会讲解!
1.3 JSP标签技术
在JSP页面中写入大量的java代码会导致JSP页面中html代码和java代码混杂在一起,会造成jsp页面结构的混乱,导致后期难于维护,并且代码难以复用。
于是在JSP的2.0版本中,sun提出了JSP标签技术,推荐使用标签来代替JSP页面中java代码,并且推荐,JSP2.0以后不要在JSP页面中出现任何一行java代码。
1.3.1 EL表达式
注意:jquery是$()
格式:${ 常量/表达式/变量 } (放在EL中的变量得先存入域中,才可以获取变量的值)
作用:(1)计算放在其中的表达式的结果,将结果输出在当前位置。
(2)主要作用:用于从域对象中获取数据,将获取到的数据输出在当前位置。
域对象:pageContext、request、session、application
EL缺点:只能从域里取数据,不能存数据.也不能遍历只能一个一个取数据
1、获取常量、表达式、变量的值(变量得先存入域中)不能写java语句(前面是否有变量来接受)
注意往域里面存得数据是任意的 object类型的参数(value)
${ "hello el" } 可能会报错:其实没错,剪贴后在复制
hello el
${ 100+123 }
${ 12*12 > 143 ? "yes" : "no" }
<%
String name = "马云";
request.setAttribute( "name123" , name );
%>
${ name123 }
<%= request.getAttribute("name123") %> attribute:设置属性
<%-- 在EL表达式中书写变量,底层会根据变量名到四个作用域中寻找该名称的属性值
如果找到对应的属性值, 就直接返回, 输出到当前位置; 如果找不到就接着寻找
直到找完四个作用域, 最后还找不到就什么都不输出!
到四个作用域中寻找的顺序为: pageContext->request->session->application
--%>
2、获取作用域中数组或集合中的元素
Servlet中的代码:
//声明一个数组, 为数组添加元素, 并将数组存入到域中
String[] names = {"刘德华", "郭富城", "张学友", "黎明" };
request.setAttribute( "names", names );
//将请求转发到jsp, 在JSP中获取域中的数组中的元素
request.getRequestDispatcher( "/02-el.jsp" ).forward(request, response);
JSP中的代码:
<%-- 获取从Servlet转发带过来的域中的数组中的元素 --%>
${ names[0] } <%-- 刘德华 --%>
${ names[1] } <%-- 郭富城 --%>
${ names[2] } <%-- 张学友 --%>
${ names[3] } <%-- 黎明 --%>
3、获取作用域中map集合中的元素
Servlet中的代码:
//声明一个map集合,为集合添加元素, 并将map集合存入到域中
Map map = new HashMap();
map.put( "name" , "尼古拉斯赵四" );
map.put( "age" , 28 );
map.put( "addr", "中国" );
request.setAttribute( "map1", map );
//将请求转发到jsp, 在JSP中获取域中的数组中的元素
request.getRequestDispatcher( "/02-el.jsp" ).forward(request, response);
JSP中的代码:
${ map1.name } <%-- 尼古拉斯赵四 --%>
${ map1.age } <%-- 28 --%>
${ map1.addr } <%-- 中国 --%>
4、获取作用域中JavaBean对象的属性值
Bean:指可重用的组件
JavaBean:指Java中可重用的组件
业务Bean:专门用于处理业务逻辑(例如:处理注册请求时,在将用户的注册信息保存到数据库之前,需要对注册薪资进行校验)
实体Bean:是专门用于封装数据的(例如:User user = new User() ...)
Servlet中的代码:
//声明一个User对象, 为对象的属性赋值, 并将User对象存入到域中
User u1 = new User();
u1.setName( "刘德华" );
u1.setAge( 18 );
u1.setAddr( "中国香港" );
request.setAttribute( "user" , u1 );
//将请求转发到jsp, 在JSP中获取域中的数组中的元素
request.getRequestDispatcher( "/02-el.jsp" ).forward(request, response);
JSP中的代码:
<%--
${ user.getName() }
${ user.getAge() }
${ user.getAddr() } --%>
<%-- user.name 底层调用的仍然是 getName()方法--%>
${ user.name }
<%-- user.age 底层调用的仍然是 getAge()方法--%>
${ user.age }
<%-- user.addr 底层调用的仍然是 getAddr()方法--%>
${ user.addr }
总测试:
<%@page import="com.tedu.pojo.User"%>
<%@page import="java.util.HashMap"%>
<%@page import="java.util.Map"%>
<%@page import="java.util.ArrayList"%>
<%@page import="java.util.List"%>
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
EL表达式
//注意:这里只是为了测试,先存数据(一般是写在Servlet里面或controller里面),再取出来.(自己给自己发快递)
(1)获取常量、表达式、变量的值(变量得先存入域中)
<%
String name="张学友";
//将name变量的值存入request域中
request.setAttribute("name123", name);
%>
${ "Hello EL" }
${ 100+123 }
${ Math.random() }
${ name123 } //靠前面的数据取数据
${ 30*45>1300 ? "yes" : "No" }
<%-- 如果往EL中书写常量或表达式,EL可输出常量的值,或者计算表达式的结果再输出
如果往EL中书写变量,EL的底层会根据这个变量的名字(比如:name)作为属性名,
到四大作用域中寻找该属性名对应的属性值。寻找时,按照域范围大小,按照从小到
大的顺序去寻找,如果找到就直接返回并输出在当前位置(及时后面有,也不再寻找),
如果找不到就什么也不输出!
域范围大小: pageContext < request < session < application --%>
(2)获取作用域中数组或集合中的元素
<%
//声明一个数组,将数组存入request域中
String[] names = {"刘沛霞","张慎政","齐雷","刘昱江","王海涛","董长春"};
request.setAttribute( "namesArr", names );
//声明一个List集合,将集合存入request域中 导包:在类名后面 alt+/
List list = new ArrayList();
list.add( "韩少云" );
list.add( "陈子枢" );
request.setAttribute( "nameList", list );
%>
${ namesArr[0] }
${ namesArr[1] }
${ namesArr[2] }
${ namesArr[3] }
${ namesArr[4] }
${ namesArr[5] }
${ nameList[0] } 集合
${ nameList[1] }
(3)获取作用域中map集合中的元素
<%
//声明一个map集合,并将map集合存入域中
Map map = new HashMap();
map.put( "name" , "阿凡提" );
map.put( "age" , 28 );
map.put( "addr", "天津" );
request.setAttribute( "map1" , map );
%>
${ map1.name }
${ map1.age }
${ map1.addr }
或者 用EL里写,key不能写数字,普通的可以写。如map.put( 1, "天津" );
${ map1.1 }显然不合适。
${ map1["name"] }
${ map1["age"] }
${ map1["addr"] }
(4)获取作用域中JavaBean对象的属性值
<%
//声明一个User实例,将User实例存入request域中
User u1 = new User();
u1.setName("马云");
u1.setAge(30);
u1.setAddr("杭州");
request.setAttribute( "user", u1 );
%>
${ user.getName() }
${ user.getAge() }
${ user.getAddr() }
简写形式
${ user.name }
${ user.age }
${ user.addr }
package com.tedu.pojo;
/** (4对应的代码)
* POJO: 简单Java对象,比如为了封装用户信息,所提供的User类,就是一个POJO类
* 通过POJO类创建的对象就是一个POJO对象( User u = new User() )
* JavaBean:
* bean:可重用的组件, JavaBean:是指用java语言编写的可重用组件(serice/dao)
* JavaBean还分为: 业务bean和实体bean
* 业务bean: 专门用来处理业务逻辑的
* 实体bean: 专门用来封装数据的(pojo) */
public class User {
private String name;
private int age;
private String addr;
public String getName() {
System.out.println("getName方法执行了......");
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
}
1.3.2 JSTL标签库
JSTL标签库是为JavaWeb开发人员提供的一套标准通用的标签库;
JSTL标签库和EL配合使用可以取代JSP中大部分的Java代码;
在使用JSTL标签库之前需要完成:
注意:java基础项目,没有专门的存jar包的目录,需要我们自己创建。自己右键Build path----add path引用。
动态的Web项目的WEB-INF中的lib目录,是用来专门存jar包的目录,也不用再右键引用(他会自动引入)。
在JSTL标签库的JSP中引入JSTL(taglib指令)。因为它会随着webcont发布到服务器。 不能再像以前一样自己创建lib目录在右键…因为写在外面不会发布到服务器上。
- 导入JSTL的开发包 在lib目录下ctrl+v复制过来 出现 Web App Libraries

- 在使用JSTL标签库的JSP中引入JSTL(taglib指令) (在day11jsp资料中有)
- c只是一个前缀,不一定写c .只不过将来这写c,下面标签也要写c.
- 引入库后才可以,使用快捷键 alt+/ 如:

其中常用的标签如下:
1、 – 用于往域中添加属性,或者修改域中已有的属性值
c:set 标签属性总结:
(1)var -- 指定存入作用域中的属性名称
(2)value -- 指定存入作用域中属性的值
(3)scope -- 指定将属性存入哪一个作用域中,默认值是page,表示pageContext域
可取值: a)page表示pageContext域 b)request表示request域
c)session表示session域 d)application表示ServletContext域
代码示例:
注意:如果域名相同 var的值相同,后面的value会覆盖前面的value值.
因为 域里面的结构是 key—value结构.
而EL表达式是从域中取数据是先按照 4个域范围由小到大的来取值的.
<%-- request.setAttribute("name", "张三"); --%>
2、 – 构造简单的 if…else…结构语句
c:if 标签属性总结:
test属性 -- 指定一个布尔表达式,当表达式的结果为true时,将会执行(输出)c:if标签中的内容,如果表达式结果为false,将不会输出c:if标签中的内容 这里面没有else语句
代码示例:往域中存入一个成绩, 根据成绩判断成绩所属的等级
您的成绩属于: 优秀!
您的成绩属于: 中等!
您的成绩属于: 不及格!
您的成绩不合法,请重新输入!
3、 – 对集合或数组等中元素进行循环遍历或者是执行指定次数的循环.
(1) 遍历域中数组或集合中的元素
<%
String[] name = {"王海涛","刘沛霞","陈子枢","齐雷"};
request.setAttribute( "names", name );
%>
${ vs.count }, ${ vs.first }, ${ vs.last }, ${ name }
或者: ${name} 双引号和${}之间不要有空格,因为空格加数组会变成字符串
(2) 遍历域中map集合中的元素
<%
//声明一个map集合并将map集合存入域中
Map map = new HashMap();
map.put( "name" , "尼古拉斯.赵四" );
map.put( "age" , 35 );
map.put( "addr" , "中国" );
request.setAttribute( "map1", map );
%>
${ entry }
或者 单独获取
${ entry.key } : ${ entry.getValue() } 可以简写:get去掉,()去掉,首字母小写但是底层调的还是 getValue()
(3) 遍历0~100之间的整数,将是3的倍数的数值输出到浏览器中
<%-- for(int i=1; i<100; i++){} --%>
${ i%3==0 ? i : "" }
或者
${ i }
c:forEach 标签属性总结:
(1)items: 指定需要遍历的集合或数组,如果是从域中获取要遍历的数组或集合,可以配置EL进行获取
(2)var: 指定用于接收遍历过程中的每一个元素,同时接收的元素会存入到pageContext域中因此在循环标 签内部,可以通过el获取当前正在遍历的元素
(3)begin: 指定循环从哪儿开始
(4)end: 指定循环到哪儿结束
(5)step: 指定循环时的步长, 默认值是1
(6)varStatus: 用于表示循环遍历状态信息的对象, 这个对象上有如下属性:
first属性: 表示当前遍历是否是第一次, 若是, 则返回true,否则返回false;
last属性: 表示当前遍历是否是最后一次, 若是, 则返回true;
count属性: 记录当前遍历是第几次
代码示例:
...
1.4 如何隐藏暂时不用的项目
隐藏项目:选中右键—close projects—在package视图下,右上角Filters----Closed projects–ok
再打开—右上角----取消掉Closed projects—在项目上双击
2 Maven
今日学习目标:
- 了解什么是Maven及Maven的作用
- 掌握Maven安装及整合到Eclipse中
- 掌握如何使用Maven构建Java项目和Web项目
- 掌握使用Eclipse导入现有的Maven项目
- 了解Maven的三种仓库(本地仓库、远程仓库(私服)、中央仓库(公服))
- 了解Maven如何管理依赖(即管理jar包)
2.1 Maven介绍
2.1.1 Maven是什么?

Maven: 翻译为"专家"、“内行”,是Apache下的一个纯Java开发的一个开源项目。
Maven是一个项目管理工具,使用Maven可以来管理企业级的Java项目开发及依赖的管理。
jar包可以称为依赖,为什么?
因为,比如一个项目需要依赖jar包程序才能执行,所以把jar包称为依赖.
有2种使用方式:
1.不和eclipse整合,用命令的方式,需要配置Maven-Home环境变量,这种方式需要记很多命令.(不推荐)
- 把Maven和eclipse做一个整合, 整合后之后可以通过eclipse创建一个Maven项目,通过Maven项目编译,运行打包,测试等等.
使用Maven开发,可以简化项目配置,统一项目结构。总之,Maven可以让开发者的工作变得更简单。
什么是依赖管理?要明白依赖管理,首先要知道什么是依赖?
一个Java项目中往往会依赖一些第三方的jar包。比如JDBC程序中要依赖数据库驱动包,或者在使用c3p0连接池时,要依赖c3p0的jar包等。这时我们称这些Java项目依赖第三方jar包。
而所谓的依赖管理,其实就是对项目中所有依赖的jar包进行规范化管理。
2.1.2 为什么要使用Maven?
传统的项目(工程)中管理项目所依赖的jar包完全靠人工进行管理,而人工管理jar包可能会产生诸多问题。
1、不使用Maven,采用传统方式管理jar包的弊端:
(1)在一些大型项目中会使用一些框架,比如SSM或者SSH框架,而框架中所包含的jar包非常多(甚至还依赖其他第三方的jar包),如果这些jar包我们手动去网上寻找,有些jar包不容易找到,比较麻烦。
(2)传统方式会将jar包添加到工程中,比如Java工程中将jar包放在工程根目录或者放在自建的lib目录下;JavaWeb工程会将jar包放在:/WEB-INF/lib目录下,这样会导致项目文件的体积暴增(例如,有些项目代码本身体积可能仅仅几兆,而加入jar包后,工程的体积可能会达到几十兆甚至百兆)。
(3)在传统的Java项目中是将所有的jar包统一拷贝的同一目录中,可能会存在jar包文件名称冲突的问题!
(4)在进行项目整合时,可能会出现jar包版本冲突的问题。
(5)在传统java项目中通过编译(手动编译或者在eclipse保存自动编译)、测试(手动在main函数中测试、junit单元测试)、打包部署(手动打war包/手动发布)、运行(手动启动tomcat运行),最终访问程序。
2、使用Maven来管理jar包的优势:
(1)Maven团队维护了一个非常全的Maven仓库(中央仓库),其中几乎包含了所有的jar包,使用Maven创建的工程可以自动到Maven仓库中下载jar包,方便且不易出错。
另外,在Maven构建的项目中,如果要使用到一些框架,我们只需要引入框架的核心jar包,框架所依赖的其他第三方jar包,Maven也会一并去下载。
(2)在Maven构建的项目中,不会将项目所依赖的jar包拷贝到每一个项目中,而是将jar包统一放在仓库中管理,在项目中只需要引入jar包的位置(坐标)即可。这样实现了jar包的复用。
(3)Maven采用坐标来管理仓库中的jar包,其中的目录结构为【公司名称+项目/产品名称+版本号】,可以根据坐标定位到具体的jar包。即使使用不同公司中同名的jar包,坐标不同(目录结构不同),文件名也不会冲突。
(4)Maven构建的项目中,通过pom文件对项目中所依赖的jar包及版本进行统一管理,可避免版本冲突。
(5)在Maven项目中,通过一个命令或者一键就可以实现项目的编译(mvn complie)、测试(mvn test)、打包部署(mvn deploy)、运行(mvn install)等。
还有发布到tomcat服务器中运行: mvn tomcat7:run。如果想实现上面的所有过程,只需要记住一个命令:mvn install
总之,使用Maven遵循规范开发有利于提高大型团队的开发效率,降低项目的维护成本,大公司都会优先使用Maven来构建项目.
2.2 Maven安装
2.2.1 下载、安装Maven
-bin .tar.gz:苹果 Linux -bin .zip: window
src.tar.gz src.zip 是它的源码文件

1、官方下载地址:http://maven.apache.org/download.cgi

2、下载绿色版,解压之后就可以使用。

原则: 安装的路径中不要有中文和空格!!
3、若要下载旧版本Maven,可以访问:
https://archive.apache.org/dist/maven/maven-3/

2.3 Maven的相关配置
在开发中更多是通过Eclipse+Maven来构建Maven项目,所以这里我们需要将Maven配置到Eclipse开发工具中。
在将安装好的Maven工具配置的Eclipse开发工具中之前,需要做一些相关的配置。
2.3.1 配置本地仓库位置
本地仓库:其实就是本地硬盘上的某一目录,该目录中会**包含maven项目中所需要的所有jar包及插件。**当所需jar包在本地仓库没有时,从网络上下载下来的jar包也会存放在本地仓库中。
因此**本地仓库其实就是一个存放jar包的目录,**我们可以指定Maven仓库的位置。
该目录不需要创建,只需要配置时会自动创建你所指定的目录。
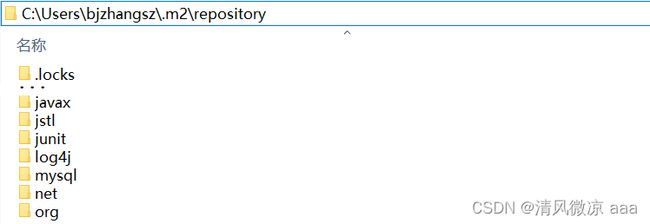
如果不指定,maven本地仓库的默认位置是在c盘,在:
Administrator
C:/Users/{当前用户}/.m2/repository,例如: 这个文件隐藏的比较深所以我们可以更该它的目录路径,更容易找到。
可以保持默认,当然也可以修改本地仓库的位置到别的盘符路径。
修改方法:找到[MAVEN_HOME]/conf/目录中的配置文件settings.xml,修改maven仓库的路径。 (Maven软件的核心配置文件,比如配置本地仓库 ,远程仓库 ,jdk版本)
编辑器打开,浏览器打开不能编辑。 只要有d盘它会自动帮你创建这两个目录,我们不需要手动创建。

配置该目录后,以后通过maven下载的jar包将会保存在配置的目录下。
以上内容可以总结为:
- 什么是本地仓库?
- 本地仓库的默认位置在哪儿?
- 配置和不配置本地仓库有什么区别?
2.3.2 配置远程(镜像)仓库(私服)
当maven项目中需要依赖jar包时,如果本地仓库中没有,就会到远程仓库去下载jar包。
如果不配置远程仓库,默认连接的是中央仓库,由于中央仓库面向的是全球用户,所以在下载jar包时,速度可能会比较慢,效率会比较低。
可以在settings.xml文件中配置连接达内远程仓库(前提是在达内教室,连接的是达内内网)或者连接阿里云远程仓库(需要有外网)。
1、如果连接的是达内内网,可以连接达内远程仓库(如果不配置,默认连接中央仓库,没有外网,连接不了中央仓库,会导致jar包无法下载)。
需要做的是,在settings.xml文件中的
<mirror> 147行
<id>nexus-teduid>
<name>Nexus teduname>
<mirrorOf>centralmirrorOf>
<url>http://maven.tedu.cn/nexus/content/groups/public/url>
mirror>
2、如果在家里、在公司连接的是外网,是无法连接达内的远程仓库,可以选择什么都不配置,默认连接中央仓库,或者可以配置连接阿里云远程仓库(不要使用手机热点网络连接,jar包下不全),配置如下:
配置阿里云远程仓库:
<mirror>
<id>nexus-aliyunid>
<name>Nexus aliyunname>
<mirrorOf>centralmirrorOf>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
mirror>
注意: xml文件对语法要求严格,放开配置的注释标签前后都要放开.
配置完成后要保存.
远程仓库配置总结:
-
当所需jar包在本地仓库没有时,会从网络上下载。配置远程仓库其实就是配置,去网络中哪个位置下载jar包到本地。
-
如果在公司,并且公司有搭建镜像服务器,推荐使用公司的镜像服务器下载jar包,速度会更快。(如果在达内,使用的是内网,只能配置达内的远程仓库。否则,没有外网也连接不了中央仓库,下载jar包会失败!)
-
如果在家里,使用的是外网,可以不配置远程仓库,默认连接中央仓库下载jar包,或者配置阿里云的远程仓库。连接阿里云服务器下载jar包。(注意,如果配置阿里云镜像服务器,不可使用手机热点网络!)
2.3.3 配置JDK版本
通过 Maven创建的工程,JDK版本默认是JDK1.5,每次都需要手动改为更高的版本。
注意:这个jdk版本跟你的eclipse的jdk版本没关系。
这里可以通过修改maven的settings.xml文件, 达到一劳永逸的效果。
配置方式为:打开 {maven根目录}/conf/settings.xml 文件并编辑,在 settings.xml文件内部的
<profile> 220行
<id>developmentid>
<activation>
<jdk>1.8jdk>
<activeByDefault>trueactiveByDefault>
activation>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<maven.compiler.compilerVersion>1.8maven.compiler.compilerVersion>
properties>
profile>
2.3.4 将Maven配置到Eclipse中
将Maven工具配置到Eclipse中,就可以通过Eclipse和自己安装的Maven创建Maven项目了。
1、window右键–> Preferences:

**2、点击Maven选项,在右侧选项中勾选 “Download Artifact Sources”:**因为有些时候可能要看源码。

3、点击add将自己安装的Maven添加进来: eclipse内置的Mavan功能不全,不用!

4、添加自己安装的Maven:
安装的根目录 路径 错了会自动提示 directory:目录
安装的名字,可以就用这个目录名

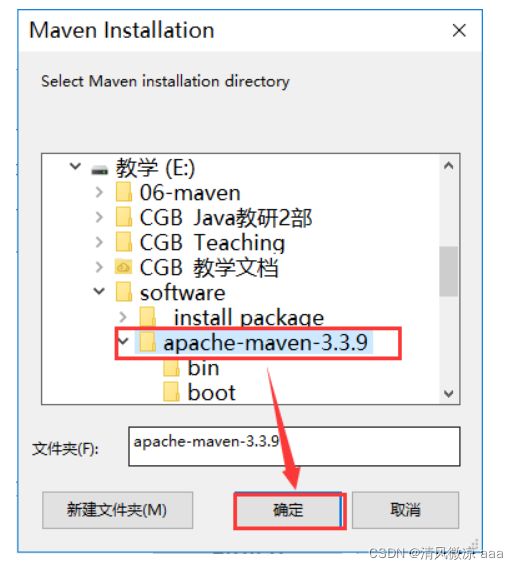
一定要注意:自己安装的Maven不要放在桌面上(容易丢失,并且路径中往往有空格),maven的安装路径中也不要包含中文和空格!!

5、将默认的maven切换为自己配置的maven: 上面只是安装
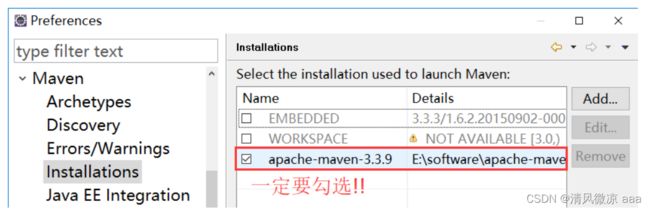
6、设置maven的settings文件的位置:
推荐使用都指向 setting的安装根目录,将来不管用那个不会出现问题。
这2个配置好,本地的仓库位置会自动显示。

**7、测试是否配置成功:**window—> show view —> other中搜索"maven",点击下面的选框中的选项

在弹出的窗口中,查看自己配置的本地仓库和远程仓库镜像:
下面的是中心仓库,配置完远程仓库后优先级高于中心仓库。

2.4 Maven的项目构建
通过Maven构建Java项目分为两种方式:
(1)使用简单方式创建:创建Maven的简单Java工程以及创建Maven的简单Web工程
(2)使用模板方式创建:创建使用模板的Java工程以及创建使用模板的Web工程( 2种结果一样,最终建的项目一样)
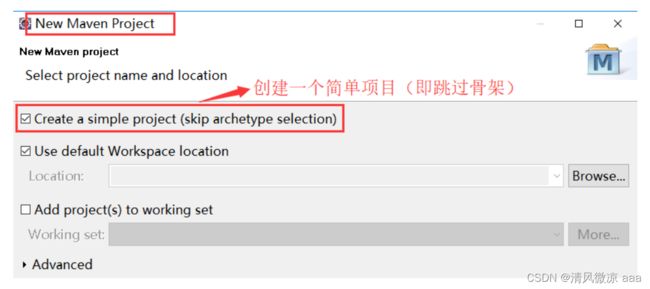
在利用Maven构建项目时分两种,第一种是:创建简单工程**(Create a simple
project)**,即在创建时勾选前面的框。

(不勾选前面的框,即创建使用骨架(其实就是模版)创建Maven工程)
另,在创建简单工程时,还分为创建Java工程和JavaWeb工程。下面分别进行演示。
2.4.1 创建简单工程—Java工程
1、空白处右键New —> Maven Project:

2、在弹出的窗口中,勾选前面的框,创建一个简单工程(即不使用骨架),进入下一步。
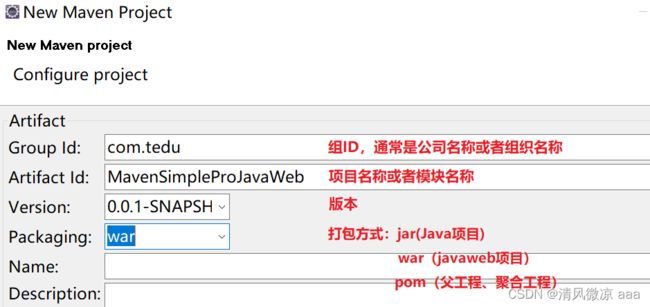
3、在弹出的窗口中,填写内容(Package选择jar,即创建java工程),点击完成即可。

在上述内容中,必填的内容有四项:
(1)Group Id – 组的名称,通常填写公司名称(比如com.tedu)或者组织名称(org.apache…)
(2)Artifact Id – 项目名称或者模块名称
(3)Version – 项目的版本,创建的项目默认是0.0.1-SNAPSHOT快照,也叫非正式版,正式版是RELEASE)
(4)Package – 项目的类型:jar表示创建的是Java工程,war表示创建的是web工程,pom表示创建的是父工程(当然相对的还有子工程)或者聚合工程,pom目前我们不讨论。
父项目可以进行一些配置,子项目继承这些配置更简单。不用再分开各个配置。
填写完毕后,点击完成即可完成创建简单Java工程
Progress(进程进展) :点击下右下角的绿色进度条会出现 这个窗口下看到绿色进度条表示正在帮你下载的jar包是什么。
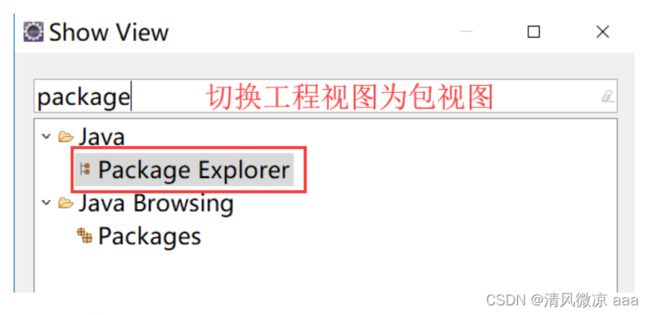
4、切换工程视图为包视图:window --> show view,在弹出的窗口中搜索:
2.4.2 创建简单工程—Web工程
1、空白处右键New —> Maven Project:

2、在弹出的窗口中,勾选前面的框,创建一个简单工程(即不使用骨架),进入下一步。

3、在弹出的窗口中,填写内容(Package选择war,即创建web工程),点击完成即可。
4、创建完成后pom.xml文件会报错,说找不到web.xml文件,例如:
创建Web项目下都会报错。注意在包视图下
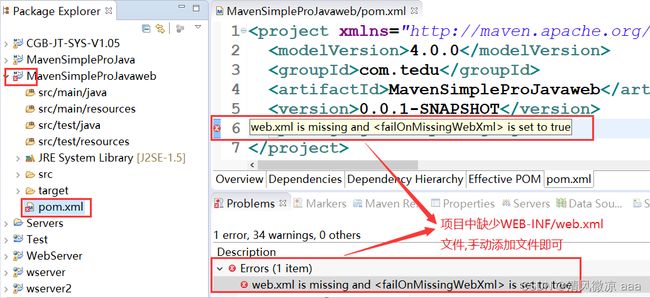
手动添加(拷贝)即可,例如:
因为缺少web.xml文件,它是在webcount目录下的 web-INF目录下,这是以前创建web文件需要发布的目录,Maven 中的webapp相当于 以前的webcontent目录:在项目上右键java EE Tools ---- Generate Deployment Descriptor Stub自动生成.(在包视图下)
用maven创建java项目和web项目的区别?
1.用Maven创建的web项目比创建的java项目结构多了个main下面的webapp目录,包括里面的内容.
2.pom文件的打包方式,如果没写打包方式(默认是jar包)或写了是jar包则是java的项目.
如果打包方式是war包则是web项目.

5、创建Servlet程序,测试运行环境。 它是在src/main/java目录下创建java文件(servlet本质是java文件) 同时在web.xml文件中生成最少8行的配置.
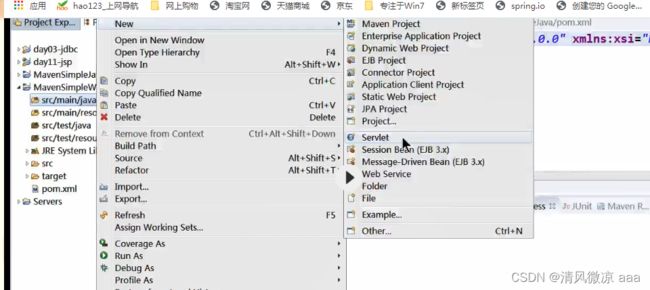


上面的错误是因为运行环境中缺少Servlet的jar包可能没下完,将tomcat运行环境添加过来即可!
!!缺少Servlet运行环境解决方案:
在包视图下----右键—build path—add libraries----server runtime (服务器运行环境) 或者jre system library(jre的系统类库)
在项目上点击鼠标右键,选择 “Properties” —> “Targeted Runtimes”:

或者,在项目中的pom.xml文件中的根标签下添加Servlet的jar包的坐标,引入Servlet的jar包,如下:
<dependencies>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>servlet-apiartifactId>
<version>2.5version>
<scope>providedscope>
dependency>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>jsp-apiartifactId>
<version>2.0version>
<scope>providedscope>
dependency>
dependencies>
添加后保存pom文件。若还报错,在项目上右键选择 “Maven” —> “UpdateProject…” 更新工程即可!
(若缺少其他的jar包:“Maven” —> UpdateProject 会下载没下的jar包,但有可能不生效。
用本地下发得本地仓库去替换你得本地仓库,需要先关闭ecliose,因为不管可能会正在占文件删不掉。然后在pom.xml文件换行 ctrl+s 在**“Maven”** —> UpdateProject)
6、实现Servlet程序 day13 156

**7、测试访问:**打开浏览器访问地址:http://localhost/MavenSimpleProJavaweb/HelloServlet

正确显示说明运行环境没有问题,
2.4.3 Maven的目录结构
使用Maven创建的工程我们称它为Maven工程,Maven工程具有一定的目录规范,对目录结构有严格的要求,一个Maven工程要具有如下目录结构:
查看目录的工作空间的位置:选中项目右键—show in—System Explorer
java项目和web项目结构几乎一样,区别 名字不同,在web项目的src下多了个webapp目录相当于以前普通创建webcontent目录存放web类型的资源的。

下面的src目录跟上面的src是同一个目录,只不过显示的内容不一样(好比,重正面看一个人和侧面看一个人效果不一样)
maven项目没有lib目录,它是通过pom文件引入的.
下面以Maven的Web项目为例,介绍Maven项目中的目录结构:
Maven项目名称(Web项目)
|-- src/main/java(源码目录):用于存放程序/项目所需要的java源码文件
|-- src/main/resources(源码目录):用于存放程序/项目所需要的配置文件
|-- src/test/java(源码目录):用于存放测试程序的java源文件
|-- src/test/resources(源码目录):用于存放测试程序所需要配置文件
|-- src/main/webapp:(Web应用的根目录,作用类似于WebContent)
|-- WEB-INF:(受保护的目录)
|-- web.xml:(Web应用的核心配置文件)
|-- target/classes(类目录):源码目录中的资源经过编译后,会输出到类目录下。
|-- pom.xml:Maven项目中非常重要的文件,将来项目需要任何jar包或插件,都可以通过pom文件来导入这些jar包或插件。
注意不同的项目编译后的输出文件位置不一样.
java基础工程: 编译后的class文件输出到bin目录下.
web项目:里面的java文件输出到builid里面的classes目录,发布后web-inf目录下.
Maven项目的java源文件编译后会输出到target里面的classes目录.发布后放在服务器的web-inf目录.
2.5 导入已有的Maven项目
现将后面通过SSM框架实现的<<永和大王门店管理系统>>(Maven)项目导入到我们的Eclipse开发环境中。
先把sql语句写入到数据库中。这里就用import,可以选中Copy projects into workspase 会复制到工作空间中,即使将来删了工作空间里还有一份。
改当前项目的编码—选中项目–右键—Properties—resource—other
在导入项目时我们通常会通过 “File” --> “Import…” 来导入项目,但是这样能会产生环境问题等,例如:如果项目本身自带的环境和我们当前使用的开发环境不一致,就会产生问题。可以按照下面的方式来进行导入。 (如果不报错用这种方式也行,忘了百度一下)
下面是导入的步骤: 这个导入是在建一个Maven项目,然后把文件复制进来。
1、创建一个新的Maven工程(JavaWeb工程)
确保已经配置好Maven的环境后,在Eclipse中创建一个新的Maven工程(Javaweb工程),新工程的名字和所导入的工程的名字可以相同也可以不同,例如:

2、解压yonghe-ssm.zip压缩包
将下发的 yonghe-ssm 项目解压出来,解压后的结构如下:

打开 yonghe-ssm 目录:

3、将解压后的目录中的src目录选中并复制。

4、点击新创建的Maven工程右键粘贴,将复制的src目录粘贴到新建的工程中
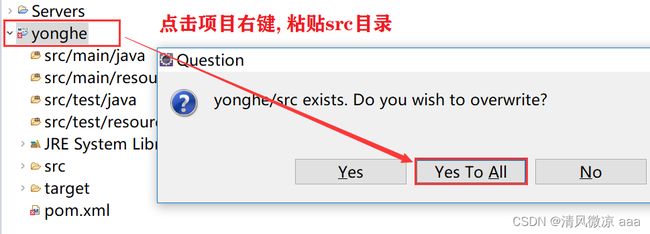
5、打开解压后的目录中的pom.xml文件, 复制其中的内容:
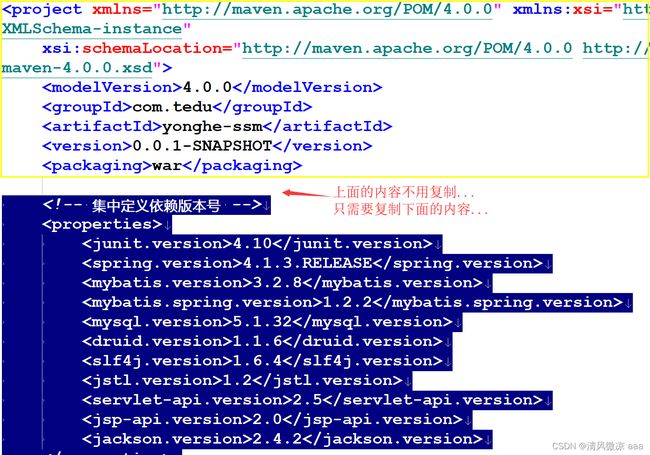
如果复制后项目或pom文件仍然报错, 可以更新Maven工程
**更新Maven工程:**在项目上右键选择 “Maven” —> “Update
Project…”,在弹出的窗口中直接点击OK即可!
6、执行SQL脚本文件,导入数据
打开cmd,连接mysql数据库,执行yonghedb.sql中的SQL语句,创建数据库、表及插入记录。
7、部署项目到服务器并启动服务器,访问测试
在正确完成上面的操作后,打开浏览器访问如下地址:http://localhost/yonghe-ssm/index
,可以看到如下界面:
在src/main/resources----jdbc.properties可以更改密码,用户名
web-INF目录下的文件不能直接访问, 我们可以用在项目上运行右键run —as—但这个路径不全,出现404,加个index

还可以改变当前项目的编码.
在项目上—右键—properties—出现以下弹窗–other–utf-8—apply and close

2.6 Maven的依赖管理
2.6.1 依赖(jar包)管理
依赖管理即jar包的管理,那么通过Maven创建的工程是如何管理jar包的?
1、在Maven项目中如何引入jar包?
在Maven创建的项目中,如果需要引用jar包,只需要在项目的pom.xml文件中添加jar包的坐标(GroupID + ArtifactID + Version)即可将jar包引进项目中,之后就可以在项目中使用所引入的jar包了。
例如,现在我们在pom.xml文件中,添加servlet的jar包的坐标如下:
可以根据坐标的位置在本地仓库中找到jar包.
<dependencies>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>servlet-apiartifactId>
<version>2.5version>
<scope>providedscope> provided表示jar包的作用范围:在编译器需要,在运行时期不会发布到服务器,因为服务器有这个jar包,发布过去有可能会冲突.
dependency>
dependencies>
在pom.xml文件中,添加mysql驱动包的坐标如下:
<dependencies>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.32version>
dependency>
dependencies>
引入之后再左侧多个目录:
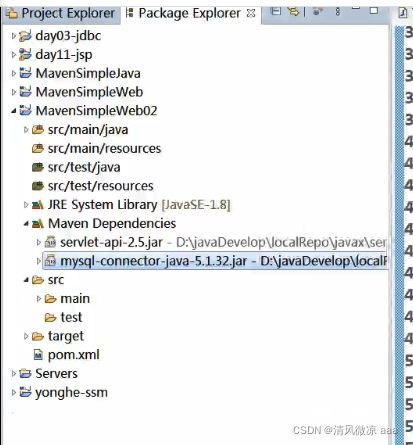
2、项目中引入的jar包存放在哪里?
那么问题来了,在pom文件中添加的servlet的jar包坐标,添加的仅仅是一个jar包对应的坐标,而这个jar包到底存放在哪里呢?
了解Maven管理jar包的规则之后,我们可以找到jar包的存放位置是在本地仓库(仓库默认是在:C:\Users\{当前用户}\.m2\repository)的 /javax/servlet/servlet-api/2.5/目录下,例如:

总结:
- 在Maven中,所有的jar包全都存放在本地仓库的目录中,如果项目中需要使用某一个jar包,直接在项目的pom.xml文件中通过坐标(GroupID + ArtifactID + Version)引入指定位置的jar包即可。
- 这样可以将项目中所有使用的jar包集中在一个目录(本地仓库)中统一进行管理,需要时通过坐标直接引入即可,而不是在每个项目中都拷贝一份,减少了项目体积,也节省了磁盘空间。
- 将来如果别人需要导入你的项目,只需要将项目(当然包括pom.xml文件)代码整体传给对方,无需将jar包发送给对方,对方在配置Maven的环境后,Maven会自动根据项目中pom.xml文件里配置的坐标,引入(或下载后再引入)对应的jar包。
3、如果引入的jar包在本地仓库中没有呢?
-
如果是刚配置的Maven环境,本地仓库中还没有太多jar包,此时在pom文件中通过坐标引入jar包,而本地仓库中没有这个jar包,这时会怎么样呢?
-
若本地仓库没有所需要的jar包,则会到远程仓库(也叫私服)或者到中央仓库(也叫公服)中下载。下面我们就来介绍Maven的这三种仓库。
2.6.2 Maven三种仓库
在上面所提到的本地仓库、远程仓库、中央仓库是用来Maven用来更好的管理jar包的所采用的一种方式。下面来了解Maven的三种仓库,以及三种仓库之间的潜在联系。
通过maven构建的项目,会通过项目中的pom.xml文件从远程仓库下载,并保存到本地仓库
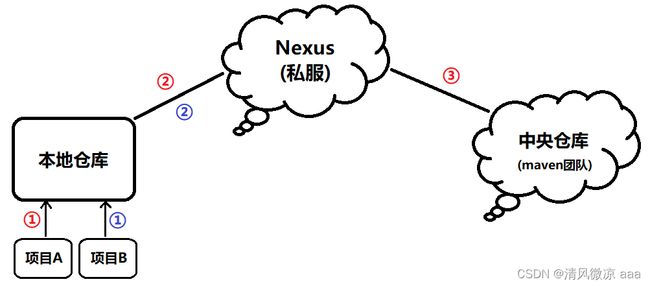
本地仓库:默认的本地仓库位置在:c:/${user.dir}/.m2/repository,其中${user.dir}表示windows下的用户目录。本地仓库的作用是,用于保存(存储)从私服或者从中央仓库下载下来的jar包(或插件)。当项目中需要使用jar包和插件时,优先从本地仓库查找。
如果本地仓库中没有所需的jar包,可以到私服或者到中央仓库中下载后再保存到本地仓库。
远程仓库:远程仓库也叫做私服(Nexus),私服一般由公司搭建并维护(也可以自己搭建)。比如达内有搭建自己的私服服务器(http://maven.tedu.cn/nexus/content/groups/public/),以及阿里云私服服务器(http://maven.aliyun.com/nexus/content/groups/public/)。
如果项目中使用到的jar包或者插件本地仓库中没有,则可以到私服中下载,如果私服中有就直接将jar包保存到本地仓库中;而如果私服中也没有所需的jar包,就到中央仓库(公服)上下载所需要的jar包,下载之后先在私服上保存一份,最后再保存到本地仓库。
中央仓库:中央仓库也叫做公服,在maven软件中内置了一个仓库地址(http://repo1.maven.org/maven2)它就是中央仓库,服务于整个互联网,由Maven团队自己搭建并维护,里面存储了非常全的jar包,它包含了世界上大部分流行的开源项目的jar包。
那么我们在使用Maven构建的Java项目,项目中所使用的jar包会来自哪里呢?例如,通过Maven先后构建项目A和项目B,在项目中都需要依赖第三方jar包:
-
如果项目A中需要依赖第三方jar包,只需要在项目下的pom文件中引入jar包在本地仓库中的坐标即可使用。如果本地仓库没有所需要的jar包,则会连接私服(需要提前配置)下载所需jar包到本地仓库供项目使用。
-
如果私服上也没有所需的jar包,则会连接中央仓库下载所需要的jar包保存到私服,再将jar包从私服下载至本地仓库,供项目使用。
-
如果没有配置私服,则默认连接中央仓库下载所需要的jar包到本地仓库中供项目使用
-
当项目B也需要依赖第三方jar包时,先到本地仓库中查找所需jar包,如果有则直接引用而无需再次下载,如果仍有部分jar包本地仓库中没有,则同上,即连接私服下载所需jar包到本地仓库。若私服中也没有所需jar包,则连接中央仓库下载jar包到私服,再从私服下载jar包到本地仓库中,供项目使用。
jar包执行流程?
Maven会扫描pom文件,根据pom文件的坐标挨个去本地仓库中去找相应的jar包,如果能找到直接引入,如果找不到Maven会根据你配置的镜像仓库到远程仓库去下载jar包.如果远程仓库没有对应的jar包先从中心仓库下载到远程仓库在下载到本地仓库. 如果没有配置就直接连接中心仓库.
2.6.3 添加依赖:方式一
使用maven插件的索引功能快速添加jar包
这种方式需要本地仓库中已经包含了该jar包,否则搜索不到!!!
1、如果本地仓库中有我们需要的jar包,可以在项目中的pom.xml文件中空白处右键–> Maven --> Add Dependency在弹出的窗口中添加所需要的依赖(jar包),如图:

**2、**添加依赖示例:添加spring的jar包的坐标到项目中
(1) 在项目中的pom.xml文件中右键 -> Maven -> Add Dependency,在弹出的窗口中输入
“spring”: 在本地仓库中搜索 jar包。

选中要添加的jar包(坐标会自动填写),点击OK即可完成添加**(前提是本地仓库有对应的jar包**)

(2)如果搜索不到jar包(保证本地仓库中已经下载了该jar包,即本地仓库有jar包,但下载不下来),可以尝试重建索引。
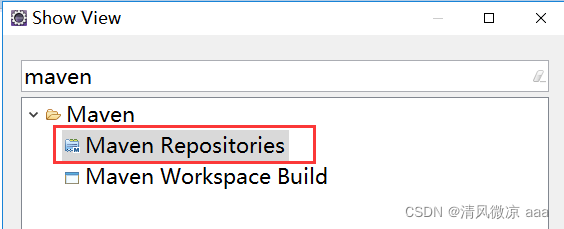
“Maven Repositories” 视图窗口中可以看到如下内容:

在"Local Repositories"上右键选择 “Rebuild Index” 即可重建索引。
完成后,再尝试搜索jar包进行添加。
2.6.4 添加依赖:方式二
1、直接在pom.xml文件中的标签内部添加。例如:在pom.xml文件中添加如下配置,就可以将junit单元测试的jar包引入到项目中来了。
添加依赖:
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.9version>
<scope>testscope>
<dependency>
<dependencies>
2、手动添加依赖需要指定所依赖jar包的坐标,但是在大部分情况下,我们是不知道jar包的坐标的。可以通过访问如下网址,在互联网上搜索查询:
http://mvnrepository.com
或者在公司远程仓库中搜索查询:
http://maven.tedu.cn/nexus
3、示例:添加c3p0的jar包的坐标到项目中
-
访问上面其中的一个网址,在搜索框中搜索 “c3p0”
-
在搜索出来的内容中,选择所需要的版本并点击版本,查看该版本的c3p0
jar包所对应的坐标: -
将坐标直接拷贝到项目的pom.xml文件中即可:


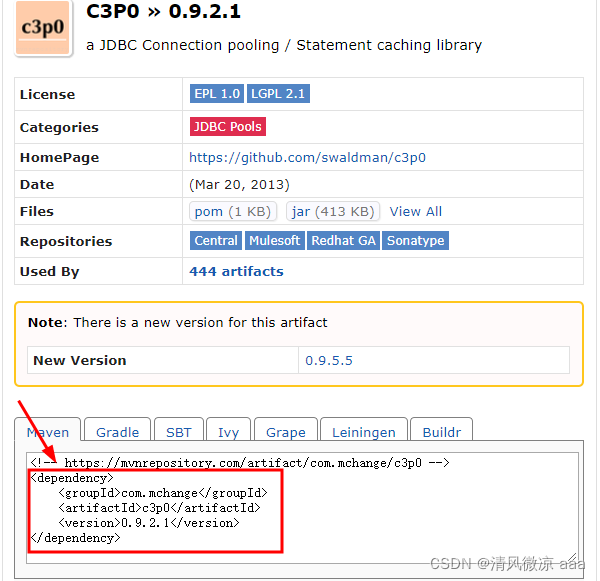
4、将上图中右侧选中的坐标拷贝到pom.xml文件中:
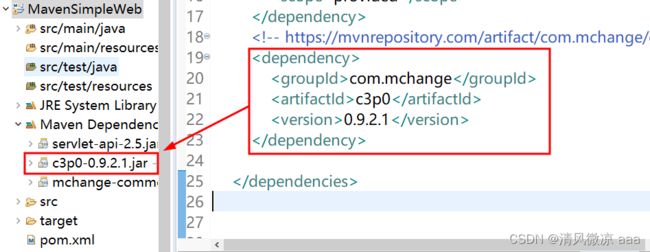
2.7 扩展:Maven常见问题
2.7.1 拷贝Maven仓库
如果因为网络环境的问题(比如:电脑没有网络),导致jar包无法下载,也可以将别人下载好的(完整的)Maven的本地仓库拷贝过来,放在自己配置的本地仓库中。因为Maven可以支持拷贝别人的仓库。
2.7.2 常见环境问题 8888888888888
问题描述1:
- 创建Maven项目时报如下错误:


- 或者创建Maven项目目录结构不全(比如只有src目录),如下图:

- 导入已有的Maven项目,项目运行不了(jar没有下载完全)
此时是因为maven的环境被破坏了,导致Maven基础运行环境不全,无法创建Maven项目,或者无法下载所需要的jar包。解决方法:
(1)在项目的pom文件中敲一个空白行,再保存文件,目的是让maven检测到pom文件发生变化,再根据pom文件中的配置到本地仓库中寻找对应的jar包,如果没有相应的jar包,maven会重新下载。
(2)如果上面的方式不行,可以尝试在项目上,右键---> Maven ---> Update Project...,强制更新项目,此时maven也会检查pom文件,在本地仓库中有没有相应的jar包。
(3)如果上面的方式仍然没有解决问题,检查当前网络环境是否能连接上所配置的远程仓库。(比如在家里使用外网,无法连接达内的远程仓库,或者使用手机热点网络无法连接阿里云的远程仓库等)
a) 在达内教室,连接的是达内内网:在settings.xml文件中配置连接达内的远程仓库
b) 在家里,用的是外网(不是手机热点):可以不配置,默认连接中央仓库,或者 在settings.xml文件中配置连接阿里云仓库
c) 用的是手机热点网络:不可以配置连接达内远程仓库或者阿里云仓库,连不上!!
(4)如果网络能够连接上所配置的远程仓库,到本地仓库的目录下,将本地仓库中所有的目录都删除,删除时,eclipse正在使用本地仓库中的资源文件,所以会阻止删除,此时将eclipse关闭,再将本地仓库中的所有目录删除,重启eclipse。
(5)启动eclipse后,再将上面的第(1)步和第(2)步再做一遍!
(6)如果还不行就用老师下发的本地仓库替换掉你的本地仓库。
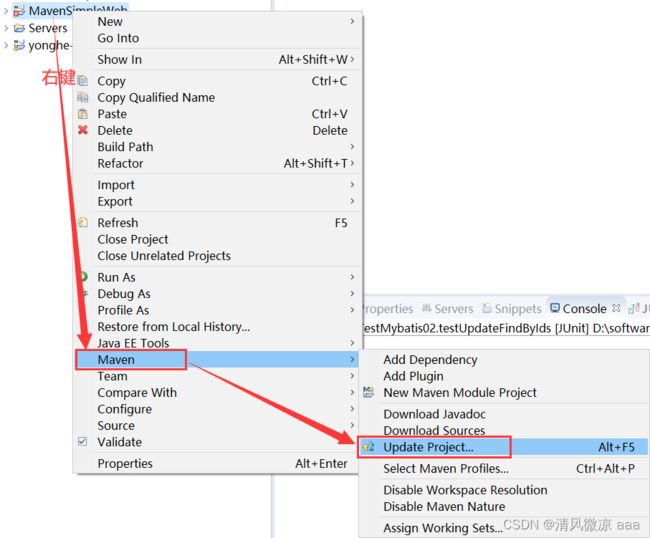
**问题描述2:**每天第一次打开Eclipse发现之前创建的Maven工程报错(比如项目上有叉号或者叹号,但项目之前是OK的),解决方法:在菜单栏中找到 Project —> Clean…

或者是:在报错的项目上鼠标右键 --> Maven --> Update Project:
2.7.3 找不到jar包问题
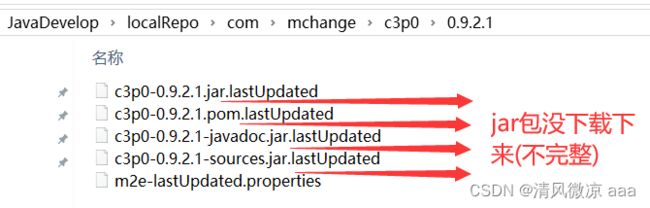
在项目中通过坐标引入了jar包(或者插件),并且本地仓库中也存在对应的jar包,但是项目还是报错,提示内容说找不到。
解决方法:如果引入的jar包,在本地仓库中存在,但是还是提示找不到,可以将本地仓库中jar包或插件的所在目录整个删除(如果删除时提示文件正在被占用,关闭eclipse再删除即可),重新保存pom.xml文件,并更新工程,让maven再次下载上面的jar包即可!
未下载完全示例:
正常下载完全示例:

2.7.4 Maven的依赖范围
下面添加了一个 jsp-api 的依赖,maven就会去下载 jsp-api 的jar包及它依赖的一些jar包。
<dependency>
<groupId>javax.servletgroupId>
<artifactId>jsp-apiartifactId>
<version>2.0version>
<scope>providedscope>
dependency>
依赖配置中有一个scope之前没讲过,它就是依赖范围。
1、什么是依赖范围:就是指定你这个jar包在哪个阶段时才有效。
-
compile - 编译依赖范围。默认的范围,可以不填,表示在所有过程中都有效,如编译期、测试过程中、运行期间等。
-
provided - 已提供依赖范围。这个范围表示只提供编译和测试阶段有效,运行期间不需要,像tomcat等容器本身已经提供的 servlet-api、jsp-api 等依赖。
-
runtime - 运行时依赖范围。这个范围表示只有在运行和测试期间才有效,编译期间不需要,像连接数据库的jdbc驱动程序等。
-
test - 测试依赖范围。这个范围只有测试阶段有效,编译和运行不需要,像单元测试提供的junit包。
-
system - 系统依赖范围。这个范围表示不依赖本地仓库,jar在其他的目录,需要通过systemPath指定路径,这个不建议使用。
-
import - 引用依赖范围。Maven2.0.9之后新增的范围,只能用在中,并且导入的type为pom类型的父工程配置,一般用来解决多继承问题。
2、什么是依赖传递:
依赖的传递前面讲过通过继承和聚合的方式可以达到,通过继承的方式可以轻松的从父项目继承过来,通过聚合的方式也可以间接的传递过来。
继承:A继承B,A就可以继承B的dependencies依赖。
聚合:A依赖C,C依赖D,那么A就要依赖D自然也就获取了D的依赖。
3、什么是依赖排除:
在依赖传递过程中,如 A 依赖 B、S2.0,B 依赖C、S1.0,这样A就有了S1.0和S2.0两个依赖,这样某些情况下会造成冲突需要手动把B间接传递过来的依赖排除掉,就是不依赖B带过来的S1.0的包。
<dependency>
<groupId>org.testgroupId>
<artifactId>BartifactId>
<version>1.0version>
<exclusions>
<exclusion>
<groupId>com.testgroupId>
<artifactId>SartifactId>
exclusion>
exclusions>
dependency>
或者直接设置 排除所有间接依赖:
<dependency>
<groupId>org.testgroupId>
<artifactId>BartifactId>
<version>1.0version>
<exclusions>
<exclusion>
<groupId>*groupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
3. Cookie、Session
=====================
3.1 什么是会话
什么是会话:当浏览器发请求访问服务器开始,一直到访问服务器结束,浏览器关闭为止,这期间浏览器和服务器之间产生的所有请求和响应加在一起,就称之为浏览器和服务器之间的一次会话。
在一次会话中往往会产生一些数据,而这些数据往往是需要我们保存起来的,如何保存会话中产生的这些数据呢?
- 比如在购物过程中,将商品加入购物车,其实就是将商品信息保存到数据库中。(不讨论)
- 如果在没有登录时,将商品加入购物车,其实就是将商品信息保存到了cookie或session中。
- 因为登录会绑定是哪一个用户存入数据,不登录没有存入到数据库中。
可以使用cookie或者session保存会话中产生的数据。
如何将会话中产生的数据保存到cookie或者是session中?
3.2 cookie原理及应用
3.2.1 cookie的工作原理

- Cookie是将会话中产生的数据保存在客户端,是客户端技术。
- Cookie是基于两个头进行工作的:分别是Set-Cookie响应头和Cookie请求头
- 通过Set-Cookie响应头将cookie从服务器端发送给浏览器,让浏览器保存到内部;而浏览器一旦保存了cookie,以后浏览器每次访问服务器时,都会通过cookie请求头,将cookie信息再带回服务器中。在需要时,在服务器端可以获取请求中的cookie中的数据,从而实现某些功能。
3.2.2 cookie的API及应用
1、创建Cookie对象
Cookie c = new Cookie(String name, String value);
// 创建cookie的同时需要指定cookie的名字和cookie要保存的值
// Cookie的名字一旦指定后,就无法修改!
2、将Cookie添加到response响应中
response.addCookie( Cookie c );
// 将cookie添加到响应中,由服务器负责将cookie信息发送给浏览器,再由浏览器保存到内部(可以多次调用该方法,添加一个以上的cookie)
3、获取请求中的所有cookie对象组成的数组
Cookie[] cs = request.getCookies();
// 获取请求中携带的所有cookie组成的cookie对象数组,如果请求中没有携带任何cookie,调用该方法会返回null。
4、删除浏览器中的Cookie
// cookie的API中没有提供直接删除cookie的方法,可以通过别的方式间接删除cookie
// 删除名称为cart的cookie:可以向浏览器再发送一个同名的cookie(即名称也叫做cart),
//并设置cookie的最大生存时间为零,由于浏览器是根据cookie的名字来区分cookie,如果前后两次向浏览器发送同名的cookie,后发送的cookie会覆盖之前发送的cookie。
//而后发送的cookie设置了生存时间为零,因此浏览器收到后也会立即删除!
代码示例:
//创建一个名称为cart的cookie
Cookie c = new Cookie("cart", "");
//设置cookie的最大生存时间为零
c.setMaxAge( 0 );
//将cookie添加到响应中,发送给浏览器
response.addCookie( c );
out.write( "成功删除了名称为cart的cookie..." );
5、Cookie的常用方法
cookie.getName(); // 获取cookie的名字 一旦指定名字不能修改
cookie.getValue(); // 获取cookie中保存的值
cookie.setValue(); // 设置/修改cookie中保存的值(没有setName方法,因为cookie的名字无法修改)
cookie.setMaxAge(); //设置cookie的最大生存时间(如果不设置,cookie默认在一次会话结束时销毁!) API中没有提供直接删除Cookie的方法,设置为0间接删除
6、setMaxAge方法:设置cookie的最大生存时间
如果不设置该方法,cookie默认是会话级别的cookie,即生存时间是一次会话。当浏览器关闭,会话结束时,cookie也会被销毁(cookie默认存在浏览器的内存中,当浏览器关闭,内存释放,cookie也会随着内存的释放而销毁。)
如果设置了该方法,cookie将不会保存到浏览器的内存中,而是以文件形式保存到浏览器的临时文件夹中(也就是硬盘上),这样再关闭浏览器,内存释放,保存到硬盘上的cookie文件不会销毁,再次打开浏览器,还可以获取硬盘上的cookie信息。
如果是 负值:表示Cookie 存在浏览器的内存中,默认就是存在浏览器内存中可以不用设置
如果 为0: 表示立即删除Cookie
代码示例:
//创建一个Cookie对象,将商品信息保存到cookie中
Cookie cookie = new Cookie( "cart", prod );
//设置cookie的最大生存时间, 单位:秒
cookie.setMaxAge( 60*60*24 );
//将cookie对象添加到response响应中
response.addCookie( cookie );
3.2.3 案例:使用cookie模拟购物车
1.index.html 在 webapp上创建html文件(使用maven创建html文件)

DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>商品列表title>
head>
<body>
<h3>点击下列商品将商品加入购物车h3>
<p>HUAWEI P30 <a href="CartServlet?prod=HUAWEI P30">加入购物车a>p>
<p>Iphone11 <a href="CartServlet?prod=Iphone11">加入购物车a>p>
<p>VIVONEX3s <a href="CartServlet?prod=VIVONEX3s">加入购物车a>p>
<p>xiaomi <a href="CartServlet?prod=xiaomi">加入购物车a>p>
<p>小 米 <a href="CartServlet?prod=小 米">加入购物车a>p>
<h3>点击支付链接,为购物车商品进行支付h3>
<a href="PayServlet">为购物车商品进行支付a>
body>
html>
2.CartServlet 在src/main/java目录下创建一个servlet 因为它是java程序 servlet报错会=要引入运行环境。 F12 Network Application ----Cookies 可以查看携带的信息
在这里可以删除,改名字等.

package com.tedu;
import java.io.IOException;
import java.io.PrintWriter;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* datetime: 2020年7月15日 上午11:05:32
*/
public class CartServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
//=====================================
//1.获取要加入购物车的商品信息(prod=xxx)
String prod = request.getParameter( "prod" );
//对商品名称进行URL编码(将其中的中文以及空格进行URL编码)
String temp = URLEncoder.encode( prod , "utf-8");
//2.创建一个Cookie对象,将商品信息保存到cookie中
Cookie cookie = new Cookie( "cart", temp );
//设置cookie的最大生存时间! 秒/单位
cookie.setMaxAge( 60*60*24*30 );
//3.将cookie添加到响应(response)中,发送给浏览器保存
response.addCookie( cookie );
//4.做出响应
out.write( "成功将 ["+prod+"] 加入了购物车..." );
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
3.PayServlet
package com.tedu;
import java.io.IOException;
import java.io.PrintWriter;
import java.net.URLDecoder;
import javax.servlet.ServletException;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* datetime: 2020年7月15日 上午11:06:19
*/
public class PayServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
//获取请求中的所有cookie组成的数组
Cookie[] cs = request.getCookies(); //null
//遍历cookie数组
String prod = null;
if( cs != null ) {
for (Cookie cookie : cs) {
//判断当前正在遍历的cookie的名字是否为 cart
if( cookie.getName().equals( "cart" ) ) {
//如果是,则获取cookie中保存的值
prod = cookie.getValue();
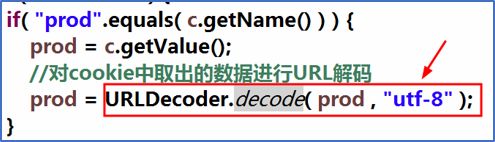
//对cookie中取出的商品名称进行URL解码
prod = URLDecoder.decode(prod , "utf-8");
}
}
}
if( prod == null ) {
out.write( "您还没有商品加入到购物车..." );
}else { //prod!=null
out.write( "成功为 ["+prod+"] 支付了 "+ (int)(Math.random()*10000) +" 元..." );
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
删除Cookie:
package com.tedu;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* datetime: 2020年7月15日 下午2:32:20
*/
public class DeleteCookie extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
//删除名称为cart的cookie
//创建一个名称为cart的cookie 同一个服务器发送给浏览器的Cookie名字不能重复,重复会覆盖Cookie,不同的服务器可以重复。这里是为了覆盖
Cookie c = new Cookie("cart", "");
//指定cookie的存活时间为零
c.setMaxAge( 0 );
//再将cookie发送给浏览器
response.addCookie( c );
out.write( "删除成功!" );
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
3.3 session原理及应用
3.3.1 session的工作原理

- Session是将会话中产生的数据保存在服务器端,是服务器端技术
- Session是一个域对象,session中也保存了一个map集合,往session中存数据,其实就是将数据保存到session的map集合中。
- 通过session.setAttribute()方法可以将数据保存到session中,通过session.getAttribute()方法可以将数据从session中取出来。
- 一个服务器只对应一个session(浏览器第一次访问服务器,会创建Session,下次在访问会用以前的,除非销毁了才会创建)
注意web项目最好不要复制,想用最好建一个新的.因为他会发不到服务器上.如果单纯的只是更改名字,它的发布路径没有改变. 解决:
在项目上右键----properties(最后一个选项)—
改一下发布路径默认是项目名.

接着改下pom.xml文件
3.3.2 session是一个域对象
获取session对象:
request.getSession()
// 获取一个session对象;如果在服务器内部有当前浏览器对应的session,则直接返回该session对象;如果没有对应session,则会创建一个新的session对象再返回;
Session是一个域对象,session中也保存了一个map集合,并且session中也提供了存取数据的方法。
如下:
session.setAttribute(String attrName, Object attrValue);
// 往session域中添加一个域属性,属性名只能是字符串类型,属性值可以是任意类型。
session.getAttribute(String attrName);
// 根据属性名获取域中的属性值,返回值是一个Object类型
Session域对象的三大特征:
(1)生命周期:
创建session:第一次调用request.getSession()方法时,会创建一个session对象。(当浏览器在服务器端没有对应的session时,调用request.getSession()方法服务器会创建一个session对象。)
销毁session: (类似人)
-
超时销毁:默认情况下,当超过30分钟没有访问session,session就会超时销毁。(30分钟是默认时间,可以修改,但不推荐修改 有3种 :具体百度一下)
-
自杀:调用session的invalidate方法时,会立即销毁session。 (invalidate:使作废)
-
意外身亡:当服务器非正常关闭时(硬件损坏,断电,内存溢出等导致服务器非正常关闭),session会随着服务器的关闭而销毁;
当服务器正常关闭,在关闭之前,服务器会将内部的session对象序列化保存到服务器的work目录下,变为一个文件。这个过程叫做session的钝化(序列化);再次将服务器启动起来,钝化着的session会再次回到服务器,变为服务器中的对象,这个过程叫做session的活化(反序列化)。
(2)作用范围:在一次会话范围内(获取到的都是同一个session对象) 而cookie是在一次请求中,范围更小。
(3)主要功能:在整个会话范围内实现数据的共享
注意:
如果是web项目 复制一份创建新的web项目有可能发布到浏览的路径不会改变,最好不要复制,若是java项目不用发送到浏览器可以复制。
解决:在项目上右键Properties(最后一个选项) —Web Project Settings—Context root 这是橡木发布路径,默认和项目名一致。复制的项目还是用的之前的发布路径,在这进行更改。然后再Poem.xml文件中也改一下发布路径。
3.3.3 案例:使用session模拟购物车
1、index.html
DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>商品列表title>
head>
<body>
<h3>点击下列商品将商品加入购物车h3>
<p>HUAWEI P30 <a href="CartServlet?prod=HUAWEI P30">加入购物车a>p>
<p>Iphone11 <a href="CartServlet?prod=Iphone11">加入购物车a>p>
<p>VIVONEX3s <a href="CartServlet?prod=VIVONEX3s">加入购物车a>p>
<p>xiaomi <a href="CartServlet?prod=xiaomi">加入购物车a>p>
<p>小 米 <a href="CartServlet?prod=小 米">加入购物车a>p>
<h3>点击支付链接,为购物车商品进行支付h3>
<a href="PayServlet">为购物车商品进行支付a>
body>
html>
2、CartServlet
package com.tedu;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
/**
* datetime: 2020年7月15日 下午3:40:44
*/
public class CartServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
//获取要添加的购物车商品
String prod = request.getParameter( "prod" );
//获取一个session对象,将商品保存到session对象中
//request.getSession():一定会返回一个session,有session则返回,如果没有则创建之后再返回 可能是用以前创建的,也可能是如果没有会自动创建一个session
HttpSession session = request.getSession();
//临时将session的超时时间改为30秒
//session.setMaxInactiveInterval( 30 );
session.setAttribute( "cart", prod );
//做出相应(由于session是服务器内部的对象,所以不用发送给浏览器)
out.write( "成功将 ["+prod+"] 加入了购物车~~~~~" );
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
3、PayServlet
package com.tedu;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
/**
* datetime: 2020年7月15日 下午3:41:03
*/
public class PayServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
//=====================================
//获取之前的session( 有session则返回,没有则返回null )这个地方是为了获取数据的,在创建新的session没有意义.
HttpSession session = request.getSession(false);
//从session中获取之前添加的商品信息
String prod = null;
if( session != null ) {
System.out.println("session不为null........");
//返回值是object类型,存的是字符串类型.强转为String
prod = (String)session.getAttribute( "cart" );
}
//做出响应
if( prod == null ) {
out.write( "您还没有将商品加入购物车~~~~~" );
}else {
//为商品模拟支付(支付之前,将session销毁,同时购物车中的商品数据也会跟着销毁)
session.invalidate();
out.write( "成功为 ["+prod+"] 支付了 "+(int)(Math.random()*10000)+" 元~~~~~" );
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
3.4 总结:两者的区别
Cookie和session都属于会话技术,都可以保存会话中产生的数据,但由于cookie和session的工作原理和特点不同,因此两者的应用场景也不一样。
Cookie的特点:
-
cookie是将会话中产生的数据保存在浏览器客户端, 是客户端技术(JS可以访问cookie)
-
cookie是将数据保存在客户端浏览器,容易随着用户的操作导致cookie丢失或者被窃取,因此cookie中保存的数据不太稳定,也不太安全。
-
但cookie将数据保存在客户端,对服务器端没有太多影响,可以将数据保存很长时间。
-
总结:因此cookie中适合存储需要长时间保存(长短取决于服务器的压力)、但对安全性要求不高的数据。
-
浏览器对cookie的大小和个数都有限制,一般推荐每一个站点给浏览器发送的cookie数量不超过20个,每一个cookie的大小不超过1kb。
-
Cookie的应用:实现购物车、记住用户名、30天内自动登录等。
Session的特点
- session是将会话中产生的数据保存在服务器端,是服务器端技术
- session将数据存在服务器端的session对象中,相对更加的安全,而且更加稳定。不容易随着用户的操作而导致session中的数据丢失或者是被窃取。
- 但session是服务器端的对象,在并发量较高时每一个浏览器客户端在服务器端都要对应一个session对象,占用服务器的内存空间,影响效率。
- 总结:因此session中适合存储对安全性要求较高,但不需要长时间保存的数据。
- Session的应用:保存登录状态、保存验证码
3.5 扩展内容
3.5.1 cookie中保存中文 空格 数据的问题
Session存数据没有中文空格 的问题。
以下问题是针对Tomcat8.0及8.0以下的版本,在Tomcat8.5及8.5以后的版本中已经解决了该问题!
HTTP协议中规定了请求信息和响应信息中不能包含中文数据!
还有另一个问题: 在Tomact8.5存的数据中间有空格也会抛出异常?
解决:把空格进行转码 可以转为 + 在取来进行解码变为空格 乱码可能解析不回来,但URL编码可以解析回来。
//对商品名称进行URL编码(将其中的中文以及空格进行URL编码)
String temp = URLEncoder.encode( prod , "utf-8");
//对cookie中取出的商品名称进行URL解码
prod = URLDecoder.decode(prod , "utf-8");
因此通过浏览器向服务器发送中文数据时,浏览器会将中文数据进行URL编码,编码为下面这种格式:

http://localhost/day13-cookie/index.html?user=%E5%BC%A0%E9%A3%9E%E9%A3%9E
将中文数据转成下面这种格式,叫做URL编码:
张飞飞 ---> URL编码 ---> %E5%BC%A0%E9%A3%9E%E9%A3%9E
将下面这种格式再次转回中文数据,叫做URL解码:
%E5%BC%A0%E9%A3%9E%E9%A3%9E ---> URL解码---> 张飞飞
问题:当cookie中保存中文数据,将cookie添加到响应中时,会报一个500异常,如下:

解决方法是:
将存入cookie中的先进行URL编码,再存入Cookie中,例如:

从cookie取出来的数据是进行URL编码后的数据,在使用之前需要进行URL解码,例如:
3.5.2 获取不到之前的session的问题
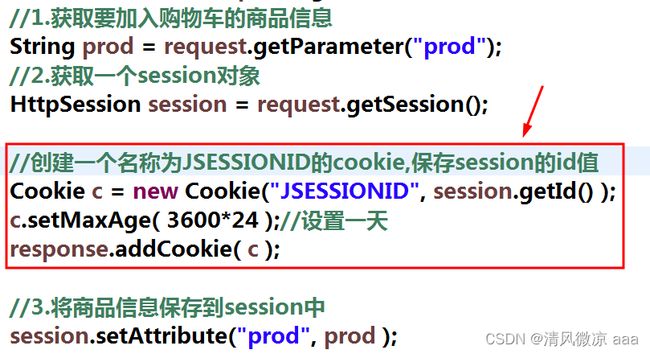
将商品保存到session中后,关闭浏览器再打开浏览器,访问服务器,此时获取不到之前的session。因为session是基于Cookie工作的。
在服务器创建一个session后,会为session分配一个独一无二的编号,称之为session的id,在此次响应时,服务器会将session的id以一个名称为JSESSIONID的cookie发送给浏览器保存到浏览器内部。
由于保存sessionid的cookie默认是会话级别的cookie,在浏览器关闭后,cookie会跟着销毁,sessionid也丢失了。因此下次访问服务器,没有session的id就获取不到之前的session。也获取不到session中的商品信息
解决方法:我们可以创建一个名称为JSESSIONID的cookie,其中保存session的ID,并设置cookie的最大存活时间,让cookie保存到硬盘上(即使浏览器关闭,cookie也不会销毁),这样下次访问服务器时,还可以将sessionid带给服务器,服务器可以通过sessionid获取到之前的session。 从session中获取到商品信息
4. MySQL数据库事务
今日目标:
-
了解事务的作用
-
掌握事务的四大特性(面试)
-
了解事务的三个并发读问题
-
掌握mysql开启和结束事务
-
了解事物的四个隔离级别
4.1 事务及四大特性
4.1.1 什么是事务
数据库事务(Database Transaction),是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。
简单的说:事务就是将一堆的SQL语句(通常是增删改操作)绑定在一起执行,要么都执行成功,要么都执行失败,即都执行成功才算成功,否则就会恢复到这堆SQL执行之前的状态。
下面以银行转账为例,张三转100块到李四的账户,这至少需要两条SQL语句:
- 给张三的账户减去100元;
update 账户表 set money=money-100 where name='张三';
- 给李四的账户加上100元。
update 账户表 set money=money+100 where name='李四';
如果在第一条SQL语句执行成功后,在执行第二条SQL语句之前,程序被中断了(可能是抛出了某个异常,也可能是其他什么原因),那么李四的账户没有加上100元,而张三却减去了100元,在现实生活中这肯定是不允许的。
如果在转账过程中加入事务,则整个转账过程中执行的所有SQL语句会在一个事务中,而事务中的所有操作,要么全都成功,要么全都失败,不可能存在成功一半的情况。
也就是说给张三的账户减去100元如果成功了,那么给李四的账户加上100元的操作也必须是成功的;否则,给张三减去100元以及给李四加上100元都是失败的。
4.1.2 事务的四大特性
事务的四大特性(ACID)是:
(1)原子性(Atomicity):事务中所有操作是不可再分割的原子单位。事务中所有操作要么全部执行成功,要么全部执行失败。
(2)一致性(Consistency):事务执行后,数据库状态与其它业务规则保持一致。如转账业务,无论事务执行成功与否,参与转账的两个账户金额的总和在事务前后应该是保持不变的。
张三:1000 1000-500=500 1000
李四:1000 1000+500=1500 1000
(3)隔离性(Isolation):隔离性是指在并发操作中,不同事务之间应该隔离开来,使每个并发中的事务不会相互干扰。也就是说,在事中务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。例如:在A事务中,查看另一B事务(正在修改张三的账户金额)中张三的账户金额,要查看到B事务之前的张三的账户金额,要么查看到B事务之后张三的账户金额。
2个人在不同房间考试,只能看到进入考试的房间之前和 考完试出了房间的状态.
它跟隔离等级有关.
事务1: 查询A、B账户金额之和(1000+1000、500+1500、1000+1000)
事务2: A转账给B 500元
A - 500 = 500
B + 500 = 1500
(4)持久性(Durability):一旦事务提交成功,事务中所有的数据操作都必须被持久化到数据库中,即使提交事务后,数据库马上崩溃,在数据库重启时,也必须能保证通过某种机制恢复数据。
数据提交后才会更新数据,没提交之前只是看起来更改只是记录了实际上没有更改仍然是原来的数据.
如:A转账给B 100元,2人个有1000元 , a变为900元,b变为1100但实际上这时2人的账户上仍是1000元,只有2人都转账成功后,并且提交2人的金额才会改变. 如果中间一方执行失败,整个事物失败.
开启事务---A给B转账500元
A: 1000 - 500 = 500 (成功了) 在日志中记录,事务成功,A账户金额更新为500
B: 1000 + 500 = 1500 (成功了) 在日志中记录,事务成功,B账户金额更新为1500
结束事务---回滚/提交 回滚 ,即取消之前的操作
4.2 MySQL中的事务
在默认情况下,**MySQL每执行一条SQL语句,都是一个单独的事务。**因为底层在执行SQL语句之前会自动开启事务,在SQL语句执行完后,会立即结束事务! (这个结束是提交事物结束)
如果需要在一个事务中包含多条SQL语句,那么需要手动开启事务和结束事务。
-
开启事务:start transaction; transaction:业务
-
结束事务:commit(提交事务)或 rollback(回滚事务)。
在执行SQL语句之前,先执行 strat transaction,这就开启了一个事务(事务的起点),然后可以去执行多条SQL语句,最后要结束事务,commit表示提交,即事务中的多条SQL语句所做出的影响会持久化到数据库中。或者rollback,表示回滚,即回滚到事务的起点,之前做的所有操作都被撤消了!
下面演示A账户给B账户转账的例子:
准备数据:
set names gbk; 防止插入数据出现乱码.
-- 1、创建数据库jt_db数据库(如果不存在才创建)
create database if not exists jt_db charset utf8;
use jt_db; -- 选择jt_db数据库
-- 2、在 jt_db 库中创建 acc 表(银行账户表),要求有id(主键),name(姓名),money(账户金额)
drop table if exists acc;
create table acc(
id int primary key auto_increment,
name varchar(50),
money double
);
-- 3、往 acc 表中, 插入2条记录
insert into acc values(null,'B',1000);
-- 查询acc表中的所有记录
select * from acc;
下面分别演示事务开启及执行一系列SQL之后,回滚事务、提交事务及中断操作的效果。
– rollback(回滚事务):
-- 查询acc账户表中A和B的金额
select * from acc;
-- 开启事务
start transaction;
-- 开始转账,A账户减去100元
update acc set money=money-100 where name='A';
-- 查询acc账户表中A和B的金额
select * from acc;
-- B账户增加100元
update acc set money=money+100 where name='B';
-- 查询acc账户表中A和B的金额
select * from acc;
-- 回滚事务
rollback; comit 提交数据
-- 再次查询acc账户表中A和B的金额
select * from acc;
– commit(提交事务):将上面的操作再做一次,最后将rollback替换为commit,即提交事务
commit; 提交之后才是成功保存到数据库,可以进行查询,如果没有提交事物如:在另一个Dos窗口查询到没更新之前的数据.
– 中断操作:将上面的操作再做一次,最后将rollback替换为quit,即中断操作
quit;
4.3 事务并发读问题
4.3.1 事务并发读问题
多个事务对相同的数据同时进行操作,这叫做事务并发。
在事务并发时,如果没有采取必要的隔离措施,可能会导致各种并发问题,破坏数据的完整性等。这些问题中,其中有三类是读问题,分别是:脏读、不可重复读、幻读。
(1)脏读(dirty read):在一个事务中**,读取到另一个事务未提交更新的数据,**即读取到了脏数据;
例如:在一个事务中,A给B转账100元但未提交事务,在另一事务中B查询账户金额,查询到了A未提交更新的数据,我们称之为脏读。
提示:需要将数据库的事务隔离级别设置为最低,才能够看到脏读现象
事务1:开启事务; A - 100 = 900; B + 100 = 1100; (没有提交事务)
事务2:开启事务; 查询B账户的金额 1100, 这个过程叫做脏读, 1100就是一个脏数据
(2)不可重复读(unrepeatable read):对同一记录的两次读取结果不一致,因为在两次查询期间,有另一事务对该记录做了修改(是针对修改操作)
例如:在事务1中,前后两次查询A账户的金额,在两次查询之间,另一事物2对A账户的金额做了修改(并且也提交了事务),此种情况可能会导致事务1中,前后两次查询的结果不一致。这就是不可重复读。
事务1:开启事务---
第一次读取A账户的金额:1000
第二次读取A账户的金额:900
事务2:开启事务---
A账户 - 100 = 900;
提交事务---
(3)幻读(虚读)(phantom read):对同一张表的两次查询结果不一致,因为在两次查询期间,有另一事务进行了插入或者是删除操作(是针对插入或删除操作);
事务1:开启事务---
select * from acc where id=3;//不存在id为3的记录 插入删除时会出错.
insert into acc value(3,'C',2000);
select * from acc where id=3;//存在id为3的记录
事务2:开启事务---
insert into acc value(3,'C',2000);
提交事务---
注意:mysql默认的是不允许出现脏读和不可重复读,所以在下面演示之前需要设置mysql允许出现脏读、不可重复读等。
set tx_isolation='read-uncommitted'; -- 设置mysql的事务隔离级别
//这个是最低级别,最低级别才有可能出现脏读.
1、脏读示例:
-- 在窗口1中,开启事务,执行A给B转账100元
set tx_isolation='read-uncommitted'; -- 允许脏读、不可重复读、幻读
use jt_db; -- 选择jt_db库
start transaction; -- 开启事务
update acc set money=money-100 where name='A';
update acc set money=money+100 where name='B';
-- 在窗口2中,开启事务,查询B的账户金额
set tx_isolation='read-uncommitted'; -- 允许脏读、不可重复读、幻读
use jt_db; -- 选择jt_db库
start transaction; -- 开启事务
select * from acc where name='B'; -- 出现脏数据
-- 切换到窗口1,回滚事务,撤销转账操作。
rollback; -- 回滚事务
-- 切换到窗口2,查询B的账户金额
select * from acc where name='B';
在窗口2中,B看到自己的账户增加了100元(此时的数据A操作事务并未提交),此种情况称之为"脏读"。
2、不可重复读示例:
-- 在窗口1中,开启事务,查询A账户的金额
set tx_isolation='read-uncommitted'; -- 允许脏读、不可重复读、幻读
use jt_db; -- 选择jt_db库
start transaction; -- 开启事务
select * from acc where name='A';
-- 在窗口2中,开启事务,查询A的账户金额减100
set tx_isolation='read-uncommitted'; -- 允许脏读、不可重复读、幻读
use jt_db; -- 选择jt_db库
start transaction; -- 开启事务
update acc set money=money-100 where name='A'; -- A账户减去100
select * from acc where name='A';
commit; -- 提交事务
-- 切换到窗口1,再次查询A账户的金额。
select * from acc where name='A'; -- 前后查询结果不一致
在窗口1中,前后两次对同一数据(账户A的金额)查询结果不一致,是因为在两次查询之间,另一事务对A账户的金额做了修改。此种情况就是"不可以重复读"
3、幻读示例:
-- 在窗口1中,开启事务,查询账户表中是否存在id=3的账户
set tx_isolation='read-uncommitted'; -- 允许脏读、不可重复读、幻读
use jt_db; -- 选择jt_db库
start transaction; -- 开启事务
select * from acc where id=3;
-- 在窗口2中,开启事务,往账户表中插入了一条id为3记录,并提交事务。
-- 设置mysql允许出现脏读、不可重复度、幻读
set tx_isolation='read-uncommitted';
use jt_db; -- 选择jt_db库
start transaction; -- 开启事务
insert into acc values(3, 'C', 1000);
commit; -- 提交事务
-- 切换到窗口1,由于上面窗口1中查询到没有id为3的记录,所以可以插入id为3的记录。
insert into acc values(3, 'C', 1000); -- 插入会失败!
在窗口1中,查询了不存在id为3的记录,所以接下来要执行插入id为3的记录,但是还未执行插入时,另一事务中插入了id为3的记录并提交了事务,所以接下来窗口1中执行插入操作会失败。
探究原因,发现账户表中又有了id为3的记录(感觉像是出现了幻觉)。这种情况称之为"幻读"
以上就是在事务并发时常见的三种并发读问题,那么如何防止这些问题的产生?
可以通过设置事务隔离级别进行预防。
4.3.2 事务隔离级别
事务隔离级别分四个等级,在相同数据环境下,对数据执行相同的操作,设置不同的隔离级别,可能导致不同的结果。不同事务隔离级别能够解决的数据并发问题的能力也是不同的。
set tx_isolation='read-uncommitted';
1、READ UNCOMMITTED(读未提交数据)
安全性最差,可能出现任何事务并发问题(比如脏读、不可以重复读、幻读等)
但性能最好**(不使用!!)**
2、READ COMMITTED(读已提交数据)(Oracle默认)
安全性较差
性能较好
可以防止脏读,但不能防止不可重复读,也不能防止幻读;
3、REPEATABLE READ(可重复读)(MySQL默认)
安全性较高
性能较差
可以防止脏读和不可重复读,但不能防止幻读问题;
4、SERIALIZABLE(串行化)
安全性最高,不会出现任何并发问题,因为它对同一数据的访问是串行的,非并发访问;
性能最差;(不使用!!)
MySQL的默认隔离级别为REPEATABLE READ,即可以防止脏读和不可重复读
4.3.3 设置隔离级别(了解)
0、MySQL查询当前的事务隔离级别
select @@tx_isolation;
1、MySQL设置事务隔离级别(了解)
(1) set tx_isolation=‘read-uncommitted’;
安全性最差,容易出现脏读、不可重复读、幻读,但性能最高
(2) set tx_isolation=‘read-committed’;
安全性一般,可防止脏读,不能防止不可重复读、幻读
(3) set tx_isolation=‘repeatable-read’;
安全性较好,可防止脏读、不可重复读,但不能防止幻读
(4) set tx_isolation=‘serialiable’;
安全性最好,可以防止一切事务并发问题,但是性能最差。
2、JDBC设置事务隔离界别
JDBC中通过Connection提供的方法设置事务隔离级别:
Connection.setTransactionIsolation(int level)
参数可以是 1 2 4 8 0, 这5个值对应的常量 和传前面的参数形式效果一样.
参数可选值如下:
Connection.TRANSACTION_READ_UNCOMMITTED 1(读未提交数据) 最低级别
Connection.TRANSACTION_READ_COMMITTED 2(读已提交数据)
Connection.TRANSACTION_REPEATABLE_READ 4(可重复读)
Connection.TRANSACTION_SERIALIZABLE 8(串行化) 最高的级别
Connection.TRANSACTION_NONE 0(不使用事务) 如,只需要作查询的时候可以不用事物
提示:在开发中,一般情况下不需要修改事务隔离级别
3、JDBC中实现转账例子
提示:JDBC中默认是自动提交事务,所以需要关闭自动提交,改为手动提交事务
也就是说, 关闭了自动提交后, 事务就自动开启, 但是执行完后需要手动提交或者回滚!!
(1)执行下面的程序,程序执行没有异常,转账成功!A账户减去100元,B账户增加100元。
(2)将第4步、5步中间的代码放开,再次执行程序,在转账过程中抛异常,转账失败!由于事务回滚,所以A和B账户金额不变。
先在pom.xml文件中添加 mysql驱动包 如果本地仓库有 在pom.xml–右键–maven—add dependency–
在弹出的窗口进行收索,具体看前面的笔记.
package com.tedu;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import com.tedu.util.JdbcUtil;
/**
* 测试Jdbc事务
*/
public class TestTransaction {
public static void main(String[] args) throws SQLException {
Connection conn = null;
Statement stat = null;
ResultSet rs = null;
try {
//1.获取连接
conn = JdbcUtil.getConn();
//2.关闭JDBC自动提交事务 如果不关闭会帮你自动提交事物,会帮你自动开启
//2条sql语句不在同一个事物,无法控制
conn.setAutoCommit(false);
//3.获取传输器
stat = conn.createStatement();
/* ***** A给B转账100元 ***** */
//4.A账户减去100元
String sql = "update acc set money=money-100 where name='A'";
stat.executeUpdate(sql);
// int i = 1/0; // 让程序抛出异常,中断转账操作
//5.B账户加上100元
sql = "update acc set money=money+100 where name='B'";
stat.executeUpdate(sql);
//6.手动提交事务
conn.commit();
System.out.println("转账成功!提交事务...");
} catch (Exception e) {
e.printStackTrace();
//一旦其中一个操作出错都将回滚,使两个操作都不成功
conn.rollback();
System.out.println("执行失败!回滚事务...");
} finally{
//JdbcUtil.close(conn, stat, rs); 框架会帮你自动关闭资源
//rs.close(); 查询用了rs需要关闭资源,更新操作没有用到rs,不需要关闭资源.
stat.close();
conn.close();
}
}
}
注意:给Maven添加依赖方式时,如果本地仓库中用jar包,却收索不到,可以作重建索引:
Maven Repositories 窗口 (在window show view 中找)-----第一个点开---Local
Repositoru (本地仓库)---Rebuild Index(重建索引)
ctrl shift +o :导包快捷键
性较好,可防止脏读、不可重复读,但不能防止幻读
(4) set tx_isolation=‘serialiable’;
安全性最好,可以防止一切事务并发问题,但是性能最差。
2、JDBC设置事务隔离界别
JDBC中通过Connection提供的方法设置事务隔离级别:
Connection.setTransactionIsolation(int level)
参数可以是 1 2 4 8 0, 这5个值对应的常量 和传前面的参数形式效果一样.
参数可选值如下:
Connection.TRANSACTION_READ_UNCOMMITTED 1(读未提交数据) 最低级别
Connection.TRANSACTION_READ_COMMITTED 2(读已提交数据)
Connection.TRANSACTION_REPEATABLE_READ 4(可重复读)
Connection.TRANSACTION_SERIALIZABLE 8(串行化) 最高的级别
Connection.TRANSACTION_NONE 0(不使用事务) 如,只需要作查询的时候可以不用事物
提示:在开发中,一般情况下不需要修改事务隔离级别
3、JDBC中实现转账例子
提示:JDBC中默认是自动提交事务,所以需要关闭自动提交,改为手动提交事务
也就是说, 关闭了自动提交后, 事务就自动开启, 但是执行完后需要手动提交或者回滚!!
(1)执行下面的程序,程序执行没有异常,转账成功!A账户减去100元,B账户增加100元。
(2)将第4步、5步中间的代码放开,再次执行程序,在转账过程中抛异常,转账失败!由于事务回滚,所以A和B账户金额不变。
先在pom.xml文件中添加 mysql驱动包 如果本地仓库有 在pom.xml–右键–maven—add dependency–
在弹出的窗口进行收索,具体看前面的笔记.
package com.tedu;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import com.tedu.util.JdbcUtil;
/**
* 测试Jdbc事务
*/
public class TestTransaction {
public static void main(String[] args) throws SQLException {
Connection conn = null;
Statement stat = null;
ResultSet rs = null;
try {
//1.获取连接
conn = JdbcUtil.getConn();
//2.关闭JDBC自动提交事务 如果不关闭会帮你自动提交事物,会帮你自动开启
//2条sql语句不在同一个事物,无法控制
conn.setAutoCommit(false);
//3.获取传输器
stat = conn.createStatement();
/* ***** A给B转账100元 ***** */
//4.A账户减去100元
String sql = "update acc set money=money-100 where name='A'";
stat.executeUpdate(sql);
// int i = 1/0; // 让程序抛出异常,中断转账操作
//5.B账户加上100元
sql = "update acc set money=money+100 where name='B'";
stat.executeUpdate(sql);
//6.手动提交事务
conn.commit();
System.out.println("转账成功!提交事务...");
} catch (Exception e) {
e.printStackTrace();
//一旦其中一个操作出错都将回滚,使两个操作都不成功
conn.rollback();
System.out.println("执行失败!回滚事务...");
} finally{
//JdbcUtil.close(conn, stat, rs); 框架会帮你自动关闭资源
//rs.close(); 查询用了rs需要关闭资源,更新操作没有用到rs,不需要关闭资源.
stat.close();
conn.close();
}
}
}
注意:给Maven添加依赖方式时,如果本地仓库中用jar包,却收索不到,可以作重建索引:
Maven Repositories 窗口 (在window show view 中找)-----第一个点开---Local
Repositoru (本地仓库)---Rebuild Index(重建索引)
ctrl shift +o :导包快捷键