【Azure Data Platform】数据平台的选择
本文属于【Azure Data Platform】系列。
接上文:【Azure Data Platform】Dedicated SQL Pool——导入性能测试(4)——总结
本文谈一下数据平台的选择
前言
云计算已经被广泛接受和使用,那么在关于数据平台方面,很多人会关心数据库,数据仓库,和数据湖的关系,我们都看重数据,也希望使用数据,很多时候我们已经有数据了,但是由于数据的产生形式不一样,数据的使用和存储都有不一样的要求。
另外在工作中也有不少需求要选择数据平台,所以整理了一些关键因素。我们常用的数据的存储介质有上面提到的数据库,数据仓库,和数据湖:
传统数据库(关系型数据库为主)
比如Azure SQL DB
数据库可存储有限的数据。这个很关键,不要试图存储所有的数据到数据库中,最起码从存储的成本而言并不最优化。我们通常存储的数据为活动数据,意味着是当前就要使用的数据。然后随着时间的流逝,数据的“生命”也开始流逝。这时候就要考虑数据的归档。
对于归档数据,可以分开数据库存放,也可以用其他存储来存放。这要根据具体使用决定。通常来说,会对1~5年内还在频繁使用的数据以独立数据库的形式存放。对于更长时间的数据,我们可以用更便宜的文件进行存放。
但是即使选择数据库,也可以细分成很多不同的种类,比如关系数据库(也有人称为Old-SQL), No-SQL, 甚至现在越来越火的New-SQL。
对于关系型数据库,相信大家都不陌生,它的核心特点是强ACID特性。对于No-SQL,比较出名的就是文档型数据库(Document DB)如MongoDB。 存储和处理xml,json格式的数据。还有图形数据库(Graph DB),在科学领域比较常见。
Data Warehouse(数据仓库)
比如微软的Azure SQL DW(目前的官方名字Dedicated SQL Pool)。
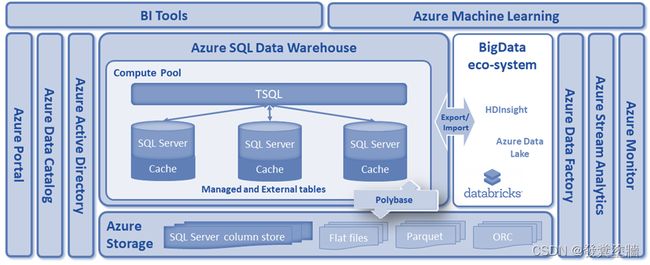
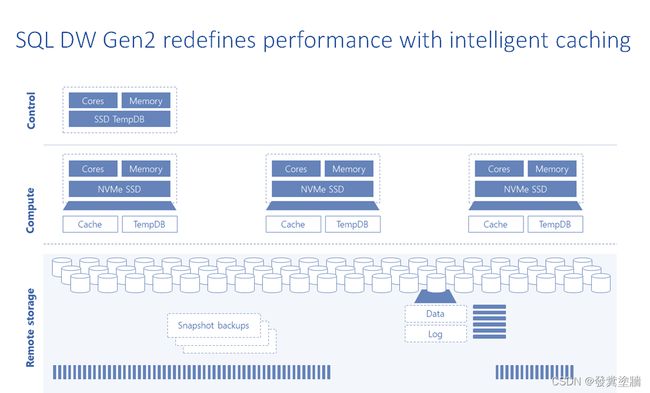
数据仓库可以处理多种格式的数据。它可以存储大量数据。比如Azure SQL DW(Dedicated SQL Pool),它的理论存储值不设限(只对以clustered columnstore index形式存储)。它最适合将历史数据保留很长时间。从历史数据中,可以获得大量分析见解,并使用这些见解来做出关键的业务决策。
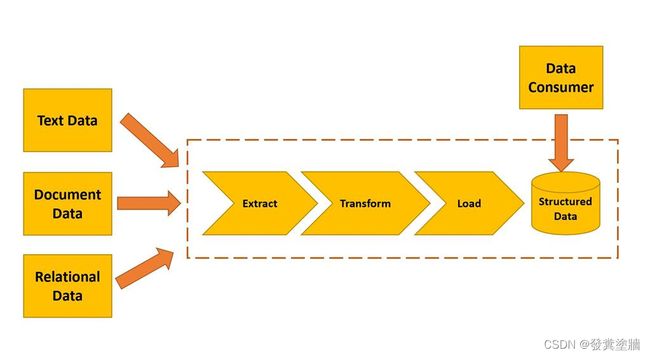
数据仓库在处理数据时遵循提取-转换-加载 (ETL) 的原理。由于数据往往来自于多个应用程序,生成和存储多种格式的数据。所以在集成时首先要提取所有这些不同形式的数据,然后将其转换为数据仓库可以理解的结构化格式,然后将结构化数据加载到数据仓库。多个应用程序可以对存储在数据仓库中的结构化数据进行交互和运行分析。
但是,数据仓库当然也有它的不足,在于它只能垂直缩放(如提升DWU)。由于数据的关系性质,数据之间存在很强的依赖性,并且很多时候,水平扩展数据会带来挑战。如果数据是结构化的,则我们无法将数据分布在多个服务器上。虽然无法水平扩展数据,但可以跨服务器复制数据。数据仓库可以处理多种格式的数据,但只能存储特定格式或结构的数据。
现代应用程序以各种格式生成数据。我们需要一个能够保持所有这些格式数据的数据存储。此外,数据存储应水平扩展,以便处理大量数据。数据仓库可以对处理数据的大小(如数据库)有限制。但是,和数据库相比,数据仓库还是可以存储大量数据。因为即使在10年前,数据仓库的设计都已经是为了应付数十年的数据存储了。当然,很多年前的数据的规模都不大。
ETL过程:
Data Lake(数据湖)
比如微软的Azure Data Lake Storage。
随着大数据的出现和成熟,数据的存放形式已经不仅限于范式化数据。各种IoT,语音,视频等等的数据格式对关系型数据库来说,成了不小的挑战。数据湖可以处理和存储多种格式的数据。它解决了数据库和数据仓库的所有不足之处。它可以水平扩展,并且可以存储数据仓库和数据库都无法存储的更多数据。它的工作原理是提取-负载-转换 (ELT)。
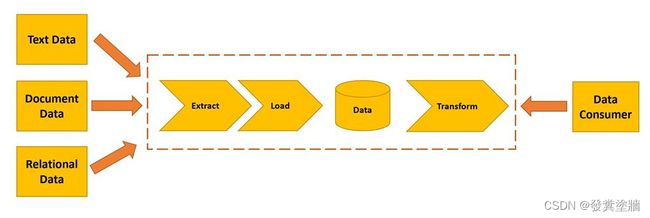
从多个源中提取不同格式的各种数据,然后将这些数据加载或存储在数据湖中。根据需要,从数据湖中读取数据并进行转换。一旦数据转换为结构化格式,它就可以被应用程序使用或加载回数据湖中。理论上它没有限制。数据湖中的数据可以根据需要增长,并且可以保留大量历史数据。
ELT过程:
总结
- 如果数据量有限,并且处理速度有要求,那么选择数据库。
- 如果数据量已经明显很大但是又还是可控,同时只用于处理特定时间的历史数据,以分析(有延时)为主,那么选择数据仓库。
- 如果需要处理的数据量已经无法预估或者控制,数据格式也千变万化,同时不仅要分析,还要引入一些类似人工智能等应用,数据湖是目前的首要选择。
还有一个在使用过程中发现的问题,由于SQL DW存储空间更大,对大数据的“处理”速度更快,所以往往很多人会以为使用SQL DW可以完全替代传统BI项目中的ODS层,但是实践表明,SQL DW的“启动”速度往往不如常规数据库,这里指的是OLTP使用的库。因为分布式的原因,SQL DW即使对于一个普通的简单的SQL,要编译,生成执行计划(这里是分布式执行计划)还有运行,都会明显比OLTP类型的库慢,所以不要想着通过一个数据库产品就可以替代所有。ODS层还是建议使用关系型数据库,而不是数据仓库。