超硬核!史上最好的数据库总结
文章目录
-
- 什么是数据库和数据结构有何关系?
- 常见的数据库软件
- MySQL的概念
- 数据库的增删改查
- 查看表结构的一些细节
- 注释
- MySQL表的增删改查
-
- 插入insert into
- 条件查询中的一些细节!!!
- OR中的小技巧
- Null中的避雷问题
- 修改update
- delete 删除记录(行)
- drop和delete的区别
- 数据库约束
-
- NOT NULL
- UNIQUE
- DEFAULT
- PRIMARY KEY
- Primary key auto_increment(自增主键)
- foreign Key 外键
- 表的设计
-
- 一对一
- 一对多
- 多对多
- 把查询结果作为新增数据
- 聚合查询
-
- COUNT
- SUM
- AVG
- MAX MIN
- 分组聚合
-
- group by
- having
- 联合查询(多表查询)
-
- 笛卡尔积
- join
- 自连接
- 子查询
- 合并查询
- 索引和事务
- 索引背后的数据结构
-
- B+树的特点:
- B+树的优势:
- 事务
- 数据库 事务的四大特性(经典面试题)
-
- 原子性
- 一致性
- 持久性
- 隔离性
-
- 脏读问题
- 不可重复读
- 幻读
- Java的JDBC编程
什么是数据库和数据结构有何关系?
数据结构研究的是数据如何组织,对于少量数据不需要组织,但是对于大量数据而言,就需要好好组织以便于后续的增删改查。
数据库是管理/组织/保存数据的软件,这些数据也是为了后续进行增删改查操作。
常见的数据库软件
关系型数据库
关系型数据库中数据的格式,要求比较严格。
1、Oracle(甲骨文)
2、MySQL
3、SQLServer(微软)
4、SQLite(轻量级数据库)
非关系型数据库
非关系型数据库的功能要比关系型数据库少一些,但是性能高一些。
1、redis
2、MongoDB
3、HBase
MySQL的概念
MySQL是一个“客户端服务器”结构的程序。
比如:我去餐馆去吃饭,到餐馆后我点了一份蛋炒饭,餐馆老板做好后给到我。
我和餐馆发生了交互,我是主动发起交互的这一方称为客户端,餐馆是被动接受交互的这一方称为服务器。
客户端和服务器的定义
客户端和服务器主要是根据主动被动区分的,某个程序当在场景一中是主动的,在场景2中是被动的,我们就称此程序既是客户端也是服务器。
请求与响应
客户端给服务器发数据称为请求,服务器返回给服务器的数据称为响应。
由于服务器是被动的所以不知道主动放什么时候来数据,所以对服务器而言要持续运行(7*24)小时,一个服务器,同一时刻,可能要给多个客户端提供服务。
数据是存储在客户端上还是服务器上的呢?
服务器,服务器是MySQL的本体。

MySQL是使用什么硬件设备进行保存数据的呢?
MySQL包括其他关系型数据库都是通过硬盘保存数据。用户在客户端中输入的命令,最终会转换网络数据传给服务器;数据是存储到服务器的,客服端是命令行程序。
数据库概念
服务器为了更好的管理数据,逻辑上划分了多个数据集合,此集合又称为数据库每个数据库,使用“表”的这样结构来组织数据,每个表有很多记录(record),每个记录就是一行(row)。每一行有很多列(column),每个列也称为一个字段(field)
服务器维护了多个数据库 ,每个数据库是一个逻辑上的集合,每个数据库里包含了很多数据表,每个表里包含了很多行,每个行里有很多列。
数据库的增删改查
| 功能 | 代码 |
|---|---|
| 查看已有数据库 | show databases; |
| 创建数据库 | create database student; |
| 删除数据库 | drop database student; |
| 创建数据库指定字符集 | create database student charset utf8; |
| 选中数据库 | use student; |
| 查看数据库中的表 | show tables; |
| 删除表 | drop table student; |
| 查看表结构 | desc student; |
| 创建表 | create table student(id int ,name varchar(20)); |
数据库的常用数据类型
| 数据类型 | 说明 |
|---|---|
| varchar | 变长字符串 varchar(20);此时并不是直接开辟了20个字符的空间,而是根据你存的数据动态调整。 |
| double | 高精度浮点数double(3,1);一共三位,小数点后占一位 |
| decimal | 比double还要精确,但是占用空间大且运算速度慢,decimal(3,1);一共三位,小数点后占一位 |
| int | 4个字节 |
| datetime | 时间格式:“2023-02-25 15:12:00” / now() |
MySQL是否有无符号类型吗?
有!,但是官方不建议使用无符号类型。
数据库的命名不能是关键字并且数字不能开头,要想用关键字可以用反引号将名字括起来。
不同的字符集下,汉字需要的字节大小是不同的
1、gbk windows简体中文版,默认字符集,两个字节表示一个汉字
2、utf8 更通用的字符集,不仅仅能表示中文 通常3个字节表示一个汉字的。
3、unicode(算是编码方式,更严格的不能算是一个完全的字符集)
查看表结构的一些细节

Field:表示列的名字
Type:列的类型
Null:表示数据允许为空
key:后面说
Default:默认值为Null
Extra:后面说
注释
语句分号后➕两个➖号是注释,注释在源码中存在,并不会在数据库中保存起来。
![]()

MySQL表的增删改查
插入insert into
| 插入操作 | 代码 |
|---|---|
| 插入数据 | |
| 指定列插入 |  |
| 一次插入多条数据 | |
| 插入时间 | |
| 时间设置当前时刻 |
MySQL是客户端服务器结构,一次插入N条记录(客户端和服务器只交互一次),比一次插入一个记录(客服端和服务器多次交互),分N次插入,效率更高一些。
| 查找操作 | 代码 |
|---|---|
| 全列查找 |  |
| 指定列查询 | |
| 查询表达式(列和列之间的运算) | |
| 查询指定别名 | |
| 去重查询(指定多个列的时候,要求这些列都相同才视为重复) |  |
| 查询结果排序(降序)升序去掉desc | |
| 次要关键字排序(主关键字相等时,看次要关键字的大小) |  |
| 条件查询 | |
| 模糊查询(%代表任意多个字符) | |
| 模糊查询(_代表任意一个字符) | |
| 模糊查询(张字结尾) | |
| 模糊查询(包含张的) | |
| 分页查询(limit 3只获取前三条数据) |  |
| 分页查询(从偏移量为2的数据开始查三条数据) | |

当查询结果数据量很大时,瞬间会吃满网络带宽和硬盘带宽,就导致其他程序无法使用硬盘或使用网络。
原始表的数据类型不能约束临时表,也就是说deciaml(3,1)当使用表达式查询将所有成绩+10,注意+10操作产生在临时表中,不会影响原始表中的值,此时超出原有表的数据类型范围时,不会影响临时表 。
条件查询中的一些细节!!!
表达式查询起别名后,别名不能在where出现,因为where比起别名前执行.
❌错误写法
![]()
✅正确写法
![]()
写下一个sql不是从前往后的执行,执行的顺序是有特定的规则的
在上述代码中的执行规则:
1、遍历每一行
2、把这一行带入where条件中
3、符合条件的结果,再根据select这里指定的列,进行查询/计算
如果一个where中同时出现and和or,先执行and后执行or。
Between
between 是一个前闭后闭的区间
![]()
OR中的小技巧
查询数学成绩是58,59,98,99的同学

Null中的避雷问题
null和其他值进行运算时结果都为空,null结果在条件中相当于false,null=null=>结果还是null=>false,但是采用<=>这种运算符可以解决null的比较。
❌错误写法

✅正确写法

limit可以和where、orderby搭配使用
比如查询班级总分前三名的信息

修改update
update 表名 set 列名=值…where 条件;
| 修改操作 | 代码 |
|---|---|
| 修改数据 | |
| 将总分倒数前三的同学数学成绩+30分 | |
| 重要提示‼️ | 如果加30超出范围则修改失败。上述代码切记不能写成math+=30。 |
| 将每个人的语文成绩增加两倍 | |
| 重要提示‼️ | 上述代码如果小数点位数超出范围采用四舍五入方式进行截断 |
delete 删除记录(行)
delete from 表名 where 条件;
| 删除操作 (行) | 代码 |
|---|---|
| 删除数据(行) | |
drop和delete的区别
drop是表和数据都没了,delete是数据没了表还在。
数据库约束
约束:就是数据库针对里面的数据能写啥,给出一组“检验规则”。
约束的作用:约束,就是为了提高效率,让数据库这个软件集成的一个针对数据校验的功能。
| 约束类型 | 作用 |
|---|---|
| NOT NULL | 指定某列不能为空 |
| UNIQUE | 保证列的值唯一 |
| DEFAULT | 规定默认值 |
| PRIMARY KEY | 主键,表示身份标识 |
| FOREIGN KEY | 外键 |
| CHECK | 在MySQL5中,不支持写了不报错也没效果 |
NOT NULL
当创建表时没有指定not null是可以随意插入null值。
创建NOT NULL表结构
create table teacher(id int not null,name varchar(20) ,salary int);
UNIQUE
当插入/修改的时候,会先查询,先看看数据是否存在,不存在插入/修改成功,存在插入/修改失败。
创建IUNIQUE表结构
create table teacher(id int ,name varchar(20) unique,salary int);
DEFAULT
默认值是当指定列插入时,其他未被指定的列就是按照此默认值填充
创建DEFAULT表结构
create table teacher(id int default 0,name varchar(20));
PRIMARY KEY
主键:主键就是一个标识,比如:身份证号、学号、手机号等等;主键也是要求唯一并且不为空,MySQL要求一个表只能有一个主键,创建表的时候可以指定一个列作为主键,也可以多个列(复合主键)。
主键=unique+ not null
创建主键结构
create table teacher (id int primary key,name varchar(20));
Primary key auto_increment(自增主键)
一个重要问题:
MySQL自身能够检查是否重复,设置还得是程序员,此时就可以使用自增主键。
自增主键就跟i++一样。
创建自增主键格式:
create table teacher(id int primary key auto_increment,name varchar(20));
(注意自增主键从1开始,我之前删过数据所以这里从2开始了)

如果我插入id为122的数据后,我在使用自增主键,则主键从123开始继续i++操作
foreign Key 外键
两张表
Class表
create table class (classId int primary key auto_increment, className varchar(20));
Student表
create table student(studentId int primary key auto_increment,name varchar(20),classId int, foreign key(classId)references class(classId));
此时我们要求Student表中的每个记录的classId得在Class表的classId存在,此时Class表约束着Student表我们就称Class表是Student表的父表,反之Student表是Class表的子表。



父表中的Id并没有10所以修改失败
当你凝视深渊的时候,深渊也在凝视你,也就是说父表约束着子表,子表也约束着父表。

此时的你发现问题了吗?
没错,当我们子表已经依赖的数据时,父表不能修改数据。
表的设计
设计表分两步走
1、梳理清楚需求中的“实体“
2、梳理清楚实体之间的关系
很多时候,每个实体需要对应一张表来进行表示
实体之间的关系,主要有三种:一对一,一对多,多对多
如何判定两个实体之间的关系?
造句
一对一
一个学生有一个学号,一个学号对应一个学生。
如何设计表:
(1)搞一个大表包含学生信息+学号信息
create table student(id int ,name varchar(20));
(2)搞两个表互相关联
create table studentNumber(id int primary key auto_increment);
create table student(id int primary key auto_increment,name varchar(20),numberId int,foreign key(numberId)references studentNumber(id) );
一对多
一个班级包含多个学生,一个学生只能处于一个班级。
如何设计表:
(1)设计两张表互相关联
create table class (classId int primary key auto_increment, className varchar(20));
create table student(studentId int primary key auto_increment,name varchar(20),classId int, foreign key(classId)references class(classId));
多对多
一个学生可以选择多个课程,一个课程可以提供给多个学生。
create table student(studentId int primary key auto_increment,name varchar(20));
create table course (courseId int primary key auto_increment,courseName varchar(20));
create table student_course(studentId int,courseId int,foreign key(studentId)references student(studentId),foreign key(courseId) references course(courseId));
把查询结果作为新增数据
约束要求:查询结果得到的列数,类型需要和插入的表匹配。
insert into student select * from student2;
聚合查询
把查询过程中,表的行和行之间进行运算。
依赖库函数,这些是SQL提供的库函数
| 函数 | 说明 |
|---|---|
| COUNT | 返回查询到的数据的数量 |
| SUM | 返回查询到数据的总和,非数字无意义 |
| AVG | 返回查询到数据的平均值,非数字无意义 |
| MAX | 返回查询到数据的最大值,非数字无意义 |
| MIN | 返回查询到数据的最小值,非数字无意义 |
COUNT
select count(*) from student;--4


使用count时需要注意,需不需要算null值如果需要,建议使用count(*)的方式查询。
SUM
查询到数据的总和,非数字无意义。
行和行之间进行运算。
select sum(chinese) from student;
AVG
查询到数据的平均数,非数字无意义。
行和行之间进行运算。
select avg(chinese) from student;
select avg(chinese+math+english) from student;--求总分的平均数。
MAX MIN
查询到数据的最大值和最小值,非数字无意义。
行和行之间进行运算。
select max(chinese),min(chinese)from student;
分组聚合
group by
指定一个列,就会把列中相同的值分为一组。
求出每个岗位的平均工资,就需要使用group by.
select role,avg(salary) from emp group by role;

having
分组后进行筛选,使用此having条件。
求出每个岗位的平均工资,抛出老板.
group by+ having
select role ,avg(salary) from emp group by role having role!="老板";

where+group
select role avg(salary) from emp where name!="老板" group by role;
可以同时在分组前和分组后筛选
where+group by+having
select role avg(salary) from emp where name!="孙悟空" group by role having role!="老板";
联合查询(多表查询)
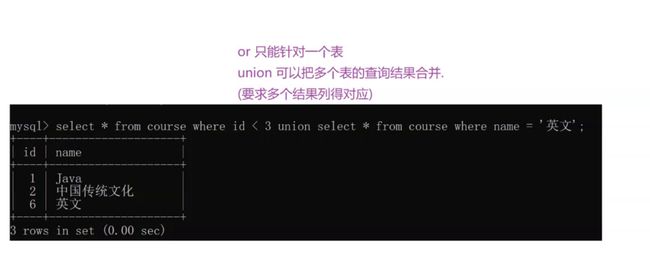
笛卡尔积
把两张表放到一起进行排列组合

笛卡尔积是得到了一张更大的表。
笛卡尔积的列数是两个表列数之和。
行数是两个表行数之积。
由于笛卡尔积是排列组合出来的结果,这里的数据有些是无意义的。
此时就需要 笛卡尔积+条件 进行查询,此时就是联合查询。
查询王五同学的成绩

查找张三同学数据结构课程的成绩

join
之前我们是使用逗号来连接多个表进行笛卡尔积,也可以使用join来连接,条件也不再使用where使用on。
join on结构

查询所有同学的总成绩和个人信息

查询数各科成绩的总分

外连接
再学外连接之前我们需要知道什么是内连接,我们上述写的代码就是内连接的。
内连接和外连接都是做笛卡尔积。




此时就好像取交集一样
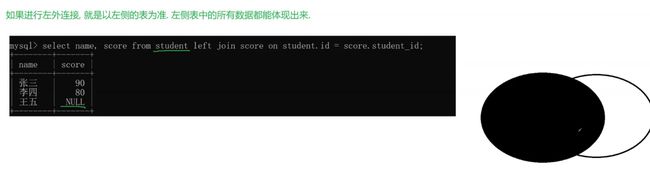


自连接
自己和自己连接,自己和自己进行笛卡尔积。
这个本质上是把行转成列
SQL中进行条件查询,都是指定某一列。多个列进行关系运算,无法进行行和行之间关系运算。
有时候为了实现这种行之间的比较我们就需要把行关系转换成列关系。
显示每个同学的1号课程>3号课程的信息

子查询
套娃,把多个查询语句合并成一个。
查询”不想毕业“同学的同班同学。
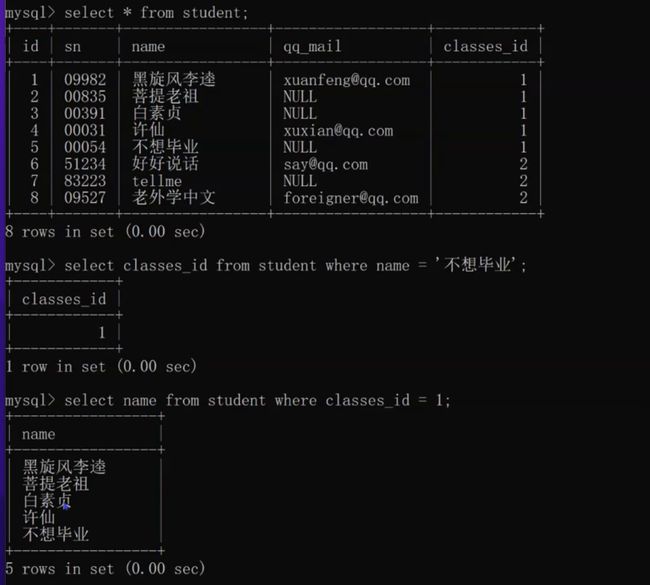

查询语文或英文课程的成绩信息


合并查询

索引和事务
索引 index => 目录
索引存在的意义,就是为了加快查找速度。
1、需要付出额外的空间代价来保存索引数据
2、索引可能会拖慢新增,删除,修改的速度
整体来说,还是利大于弊的,
查看索引
show index from 表名;
创建索引
create index 索引名 on 表名(列名);

删除索引
drop index 索引名 on 表名;
索引背后的数据结构
B+树:为了数据库索引,量身定做的数据结构
先了解B数,再了解B+书,B树也叫B-书(此处-是连接符不是减号)。
B树可以认为是一个N叉搜索树,当结点的子树多了,节点上保存的key多了(每个结点每个key都是保存的完整数据记录),意味着在同样key的个数的前提下 ,B树的高度就要比二叉搜索树低很多,树的高度越高,进行查询比较的时候访问磁盘的次数就越多
B+树又再B树上进行了改良,B+树也是一个N叉搜索树,几个key引出几个区间

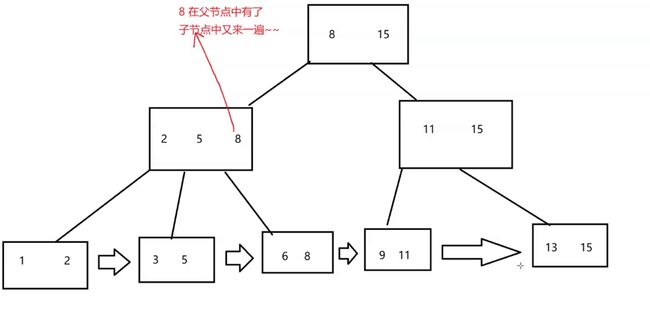
B+树的特点:
1、一个结点,可以存储N个key,N个Key划分出N个区间
2、每个节点中的Key值,都会在子结点中存在(同时该key是子结点最大值)
3、B+树的叶子结点是首尾相连,类似于链表
4、整个树的的所有数据都包含在叶子结点中的
B+树的优势:
1、当一个结点保存多个key,最终树的高度是相对更矮的,查询的时候IO(输入输出)访问次数减少。
2、所有的查询最终都会落到叶子结点上(查询任何一个数据,经过的IO访问次数是一样的,而B树有可能一次就能找到!),所以B+树查询很稳定,稳定是很重要的它能够让我们程序员更准确的评估执行效率。
3、B+树的所有的叶子结点,构成链表,此时更方便进行范围查询。

4、由于数据都在叶子结点上,非叶子结点只存储key,导致非叶子结点,占用空间是比较小的,这些非叶子结点就可能在内存中缓存(或者是缓存一部分),又进一步减少了IO的次数!
5、叶子节点都存放在硬盘上,非叶子结点都放在内存中。
B+树就是MySQL组织数据的方式,当你看到一张“表“的时候,实际上这个表不易等就是按照“表格”这样的数据结构在硬盘上组织的,也有可能是按照这种树型结构组织(具体哪种组织结构,取决于你表里有没有索引,以及数据库使用了那种存储引擎)



事务
比如经典场景:转账

1 给 2 转账500

假设,在执行过程中,执行完1后 ,数据库崩溃了/ 主机宕机了,此时转账就僵硬了
!(1的钱扣了,2的钱没到账)。

事务就是解决上述问题
事务的本质就是把多个sql语句打包成一个整体(称为事务的原子性),要么全部执行成功,要么就一个都不执行(不是真的没执行,而是看起来没执行一样,也就是说,执行了,执行出错了,出错之后,进行了恢复现场也称为“回滚”)。而不会出现“执行一半”这样的中间状态。
进行回滚的时候,咋知道滚到是恢复到啥样的的状态呢?
此时需要额外的部分来记录事务中的操作步骤。(数据库里有专门用来记录事务的日志),正是如此使用事务效率更低,开销更大。
start transaction;--开启事务
...
commit;--提交事务
数据库 事务的四大特性(经典面试题)
原子性
定义指事务的不可分割性,一个事务的所有操作要么不间断地全部被执行,要么一个也没有执行。
一致性
事务执行前后,数据得是靠谱的
持久性
事务修改的内容是写在硬盘上的,持久存在的,重启也不丢失。
隔离性
这个隔离性是为了解决“并发”执行事务,引起的问题。
并发:一个餐馆(服务器)同一时刻给多个顾客(客户端)提供服务,也就是说服务器同时处理多个客户端发出的请求就称为“并发”。
如果并发的这些事务,是修改不同的表/不同的数据,没啥事
但是修改的是同一个表/同一个数据,就可能带来一定的问题。
脏读问题
一个事务A正在对数据进行修改的过程中,还么提交之前,另一个事务B,也对同一个数据进行了读取。此时B的读操作称为“脏读”,读到的数据也称为“脏数据”。
解决方法
为了解决脏读问题,mysql引入了“写操作加锁”这样的机制,降低了并发程度(降低了效率),提高了隔离性(数据准确性)
不可重复读
事务A提交了数据后,事务B去读数据,在读的过程中,事务C又提交了新数据,此时意味着同一个事务B多次读入,读出来的结果是不一样的,此时称为“不可重复读”。
解决方法
为了解决不可重复读的问题,数据库引入“读操作加锁”机制。
幻读
在读加锁和写加锁的前提下,一个事务两次读取同一个数据,发现读取的数据值是一样的,但是结果集不一样。

解决方法
数据库使用“串行化”这样的方式来解决幻读,彻底放弃并发处理事务,一个接一个的串行的处理事务,这样做,并发程度最低,隔离性最高。

Java的JDBC编程
各种数据库,MySQL,Oracle,SQL Server 在开发的时候,就会提供一组编程接口(API)
API的概念:给你个软件,你能对他干啥,基于他提供的这些功能,就可以写一些其他代码。
public static void main(String[] args) throws SQLException {
//创建并初始化一个数据源
DataSource dataSource=new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/java100?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("*****");
//建立连接
Connection connection=dataSource.getConnection();
//构造 SQL 语句
String sql="insert into student values(1,'张三')";
PreparedStatement statement=connection.prepareStatement(sql);//提前对sql语句进行预编译,服务器做的工作就简单一些;
//执行SQL语句(发送按钮)
int ret= statement.executeUpdate();
System.out.println("ret="+ret);//影响到的行数
//释放必要的资源
statement.close();
connection.close();
}