10-Docker-分布式存储算法
01-哈希取余算法分区
哈希取余分区(Hash Modulus Partitioning)是一种在分布式计算和数据存储中常用的分区策略,其目的是将数据或计算任务分配到多个节点或服务器上,以实现负载均衡和提高性能。这种分区策略的核心思想是使用哈希函数来将数据或任务的标识(通常是键或标签)映射到一个固定范围的分区中,然后使用取余运算来确定应该分配给哪个分区。
使用 Python 进行哈希取余算法运行代码及结果如下:
def hash_partition(data, num_partitions):
partitions = [[] for _ in range(num_partitions)]
for item in data:
# 计算数据的哈希值,这里使用内置的哈希函数hash()
hash_value = hash(item)
# 取余以确定数据应该分配到哪个分区
partition_index = hash_value % num_partitions
# 将数据添加到相应的分区
partitions[partition_index].append(item)
return partitions
# 示例数据
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 分成3个分区
num_partitions = 3
result = hash_partition(data, num_partitions)
for i, partition in enumerate(result):
print(f'Partition {i}: {partition}')
程序运行后,代码输入如下内容:
哈希取余分区的优点:
- 负载均衡:通过使用哈希函数,可以确保相同标识的数据或任务始终分配到相同的分区,从而分散负载并减少不均匀分布的可能性。
- 易于扩展:当需要增加或减少节点或服务器时,只需重新计算哈希并将数据或任务重新分配到新的分区,而不需要改变哈希函数本身。
- 确定性:相同的标识将始终映射到相同的分区,这对于缓存和数据复制等应用非常有用。
哈希取余分区的缺点:
- 数据倾斜(某些分区可能会处理更多的数据或任务)
- 节点增减可能需要重新分配大量数据的问题,需要重新计算哈希分区,造成计算量上的增加。
02-一致性哈希算法分区
一致性哈希分区是一种在分布式系统中用于数据分布和负载均衡的技术。它的原理基于哈希函数和环形哈希环,主要用于确定数据在分布式系统中的存储位置。
一致性哈希算法必然有个 hash 函数并按照算法产生 hash 值,这个算法的所有可能的哈希值会构成一个全量集,这个集合可以成为一个 hash 空间 [0,2^32-1],这个是一个线性空间,但是在逻辑上我们把它视为环形空间。
一致性哈希分区是在分布式数据库、缓存系统和负载均衡器等场景中广泛使用的技术,它可以有效地分散数据存储负担,提高系统的性能和容错性。
使用 Python 进行哈希取余算法运行代码及结果如下:
import hashlib
class ConsistentHash:
def __init__(self, num_replicas=3):
self.num_replicas = num_replicas
self.ring = {} # 一致性哈希环
self.nodes = set() # 节点集合
def add_node(self, node):
for i in range(self.num_replicas):
# 为每个节点创建多个虚拟节点
virtual_node = f"{node}-{i}"
hash_value = self._hash(virtual_node)
self.ring[hash_value] = node
self.nodes.add(node)
def remove_node(self, node):
for i in range(self.num_replicas):
virtual_node = f"{node}-{i}"
hash_value = self._hash(virtual_node)
del self.ring[hash_value]
self.nodes.remove(node)
def get_node(self, key):
if not self.ring:
return None
hash_value = self._hash(key)
sorted_keys = sorted(self.ring.keys())
for key in sorted_keys:
if hash_value <= key:
return self.ring[key]
# 如果key的哈希值大于所有节点的哈希值,返回第一个节点
return self.ring[sorted_keys[0]]
def _hash(self, key):
# 使用SHA-1哈希函数
return int(hashlib.sha1(key.encode()).hexdigest(), 16)
# 示例
ch = ConsistentHash()
ch.add_node("Node1")
ch.add_node("Node2")
ch.add_node("Node3")
# 将数据分配到节点
data = ["Data1", "Data2", "Data3", "Data4", "Data5"]
for item in data:
node = ch.get_node(item)
print(f"Data '{item}' is assigned to Node '{node}'")
# 移除一个节点
ch.remove_node("Node2")
# 再次分配数据
print("\nAfter removing Node2:")
for item in data:
node = ch.get_node(item)
print(f"Data '{item}' is assigned to Node '{node}'")
程序运行后,代码输入如下内容: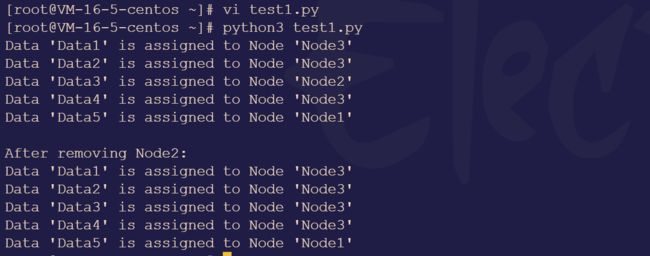
比起哈希取余算法,一致性哈希算法解决了哈希取余的容错性和扩展性。如果某个节点失败,数据可以被映射到下一个最近的节点,而不会造成大规模的数据迁移。
扩展性指的是增加一台 Node X,X 的位置在 A 和** B 之间,那收到影响的也只是 A 到 X 之间的数据,不会导致 Hash 取余全部重新洗牌。
但是一致性 Hash 算法存在数据倾斜**的问题,一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜。
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
03-哈希槽算法分区
哈希槽算法分区是大厂常用的算法,只有会哈希槽算法才会和大厂的认知匹配。
一致性哈希算法存在数据倾斜的问题,哈希槽算法本质上是一个数组,数组 [0,2^14-1] 形成 hash slot 空间。
哈希槽可以解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽,用于管理节点和数据之间的关系,就相当于节点上放的是槽,槽上面放的是数据。
槽解决的是颗粒度的问题,相当于把颗粒度变大,便于数据的移动。
哈希解决的是映射的问题,使用 key 来计算所在的槽,便于数据的分配。
使用 Python 进行哈希槽算法运行代码及结果如下:
class HashSlot:
def __init__(self, size):
self.size = size
self.slots = [None] * size
def _hash_function(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self._hash_function(key)
if self.slots[index] is None:
self.slots[index] = [(key, value)]
else:
for i, (existing_key, existing_value) in enumerate(self.slots[index]):
if existing_key == key:
self.slots[index][i] = (key, value)
break
else:
self.slots[index].append((key, value))
def get(self, key):
index = self._hash_function(key)
if self.slots[index] is not None:
for existing_key, existing_value in self.slots[index]:
if existing_key == key:
return existing_value
raise KeyError(f"Key '{key}' not found")
def delete(self, key):
index = self._hash_function(key)
if self.slots[index] is not None:
for i, (existing_key, _) in enumerate(self.slots[index]):
if existing_key == key:
del self.slots[index][i]
break
else:
raise KeyError(f"Key '{key}' not found")
def __str__(self):
return str(self.slots)
# 示例
hash_slot = HashSlot(8)
hash_slot.insert("apple", 5)
hash_slot.insert("banana", 10)
hash_slot.insert("cherry", 15)
print(hash_slot)
print("Value for 'apple':", hash_slot.get("apple"))
print("Value for 'banana':", hash_slot.get("banana"))
print("Value for 'cherry':", hash_slot.get("cherry"))
hash_slot.delete("banana")
print("After deleting 'banana':", hash_slot)
·· 当运行这段代码后,以下事件将发生:
- 创建哈希槽对象:代码首先创建了一个名为
hash_slot的哈希槽对象,这个哈希槽的大小被初始化为8个槽位。 - 插入键值对:接下来,代码使用
insert方法向哈希槽中插入三个键值对:"apple"对应5,"banana"对应10,"cherry"对应15。这些键值对将被根据它们的键进行哈希,然后存储在合适的槽位中。 - 打印哈希槽:代码使用
print(hash_slot)语句打印哈希槽的内容,显示存储在各个槽位中的键值对。 - 获取键值:代码使用
get方法获取键"apple"、"banana"和"cherry"对应的值,分别为5、10和15。 - 删除键值:代码使用
delete方法删除键"banana"对应的键值对。 - 打印更新后的哈希槽:最后,代码再次使用
print(hash_slot)语句打印哈希槽的内容,显示删除了"banana"键值对后的哈希槽状态。
程序运行后,代码输入如下内容:
04-总结与归纳
在本次学习中,我们一共学习了三种分布式存储常用的算法,它们分别是哈希取余算法、一致性哈希算法、哈希槽算法。这三个算法的优点和缺点后很明显,简单归类如下:
哈希取余算法:优点是负载均衡,易于扩展;缺点是删除增加大量计算量
一致性哈希算法:优点是容错性和扩展性好;缺点是容易出现数据倾斜。
哈希槽算法:优点是快速数据查找,高效的插入和删除操作,数据分布均匀;缺点是哈希冲突,不适合范围查询。