A very simple framework for state-of-the-art Natural Language Processing (NLP) ------ note-2
flairNLP-1
Let’s use a pre-trained model for named entity recognition (NER). This model was trained over the English CoNLL-03 task and can recognize 4 different entity types.
All you need to do is use the predict() method of the tagger on a sentence. This will add predicted tags to the tokens in the sentence. Lets use a sentence with two named entities:
from flair.models import SequenceTagger
from flair.data import Sentence
tagger = SequenceTagger.load('ner')
sentence = Sentence('George Washington went to Washington.')
# predict NER tags
tagger.predict(sentence)
# print sentence with predicted tags
print(sentence.to_tagged_string())
输出: George Washington went to Washington .
Many sequence labeling methods annotate spans that consist of multiple words, such as “George Washington” in our example sentence. You can directly get such spans in a tagged sentence like this:
for entity in sentence.get_spans('ner'):
print(entity)
Span [1,2]: "George Washington" [− Labels: PER (0.9968)]
Span [5]: "Washington" [− Labels: LOC (0.9994)]
Which indicates that “George Washington” is a person (PER) and “Washington” is a location (LOC). Each such Span has a text, its position in the sentence and Label with a value and a score (confidence in the prediction). You can also get additional information, such as the position offsets of each entity in the sentence by calling:
print(sentence.to_dict(tag_type='ner'))
{'text': 'George Washington went to Washington.',
'entities': [
{'text': 'George Washington', 'start_pos': 0, 'end_pos': 17, 'type': 'PER', 'confidence': 0.999},
{'text': 'Washington', 'start_pos': 26, 'end_pos': 36, 'type': 'LOC', 'confidence': 0.998}
]}
Sometimes you want to predict several types of annotation at once, for instance NER and part-of-speech (POS) tags. For this, you can use our new MultiTagger object, like this:
from flair.models import MultiTagger
# load tagger for POS and NER
tagger = MultiTagger.load(['pos', 'ner'])
# make example sentence
sentence = Sentence("George Washington went to Washington.")
# predict with both models
tagger.predict(sentence)
print(sentence)
输出: Sentence: "George Washington went to Washington ." [− Tokens: 6 − Token-Labels: "George Washington went to Washington . <.>"]
The sentence now has two types of annotation: POS and NER.
You choose which pre-trained model you load by passing the appropriate string to the load() method of the SequenceTagger class.
A full list of our current and community-contributed models can be browsed on the model hub. At least the following pre-trained models are provided (click on an ID link to get more info for the model and an online demo):

We distribute new models that are capable of handling text in multiple languages within a singular model.
The NER models are trained over 4 languages (English, German, Dutch and Spanish) and the PoS models over 12 languages (English, German, French, Italian, Dutch, Polish, Spanish, Swedish, Danish, Norwegian, Finnish and Czech).

Often, you may want to tag an entire text corpus. In this case, you need to split the corpus into sentences and pass a list of Sentence objects to the .predict() method.
For instance, you can use the sentence splitter of segtok to split your text:
from flair.models import SequenceTagger
from flair.tokenization import SegtokSentenceSplitter
# example text with many sentences
text = "This is a sentence. This is another sentence. I love Berlin."
# initialize sentence splitter
splitter = SegtokSentenceSplitter()
# use splitter to split text into list of sentences
sentences = splitter.split(text)
# predict tags for sentences
tagger = SequenceTagger.load('ner')
tagger.predict(sentences)
# iterate through sentences and print predicted labels
for sentence in sentences:
print(sentence.to_tagged_string())
This is a sentence .
This is another sentence .
I love Berlin .
Using the mini_batch_size parameter of the .predict() method, you can set the size of mini batches passed to the tagger. Depending on your resources, you might want to play around with this parameter to optimize speed.

Relations hold between two entities. For instance, a text like “George was born in Washington” names two entities and also expresses that there is a born_in relationship between both.
We added two experimental relation extraction models, trained over a modified version of TACRED: relations and relations-fast. Use these models together with an entity tagger, like so:
from flair.data import Sentence
from flair.models import RelationExtractor, SequenceTagger
# 1. make example sentence
sentence = Sentence("George was born in Washington")
# 2. load entity tagger and predict entities
tagger = SequenceTagger.load('ner-fast')
tagger.predict(sentence)
# check which entities have been found in the sentence
entities = sentence.get_labels('ner')
for entity in entities:
print(entity)
# 3. load relation extractor
extractor: RelationExtractor = RelationExtractor.load('relations-fast')
# predict relations
extractor.predict(sentence)
# check which relations have been found
relations = sentence.get_labels('relation')
for relation in relations:
print(relation)
PER [George (1)] (0.9971)
LOC [Washington (5)] (0.9847)
born_in [George (1) -> Washington (5)] (0.9998)
Indicating that a born_in relationship holds between “George” and “Washington”!
In case you need to label classes that are not included you can also try our pre-trained zero-shot classifier TARS (skip ahead to the zero-shot tutorial). TARS can perform text classification for arbitrary classes.
All word embedding classes inherit from the TokenEmbeddings class and implement the embed() method which you need to call to embed your text. This means that for most users of Flair, the complexity of different embeddings remains hidden behind this interface. Simply instantiate the embedding class you require and call embed() to embed your text. All embeddings produced with our methods are PyTorch vectors, so they can be immediately used for training and fine-tuning.
This tutorial introduces some common embeddings and shows you how to use them. For more details on these embeddings and an overview of all supported embeddings, check here
Classic word embeddings are static and word-level, meaning that each distinct word gets exactly one pre-computed embedding. Most embeddings fall under this class, including the popular GloVe or Komninos embeddings.
Simply instantiate the WordEmbeddings class and pass a string identifier of the embedding you wish to load. So, if you want to use GloVe embeddings, pass the string ‘glove’ to the constructor:
Now, create an example sentence and call the embedding’s embed() method. You can also pass a list of sentences to this method since some embedding types make use of batching to increase speed.
This prints out the tokens and their embeddings. GloVe embeddings are PyTorch vectors of dimensionality 100.
You choose which pre-trained embeddings you load by passing the appropriate id string to the constructor of the WordEmbeddings class. Typically, you use the two-letter language code to init an embedding, so ‘en’ for English and ‘de’ for German and so on. By default, this will initialize FastText embeddings trained over Wikipedia. You can also always use FastText embeddings over Web crawls, by instantiating with ‘-crawl’. So ‘de-crawl’ to use embeddings trained over German web crawls:
from flair.embeddings import WordEmbeddings
from flair.data import Sentence
# init embedding
glove_embedding = WordEmbeddings('glove')
# create sentence.
sentence = Sentence('The grass is green .')
# embed a sentence using glove.
glove_embedding.embed(sentence)
# now check out the embedded tokens.
for token in sentence:
print(token)
print(token.embedding)
german_embedding = WordEmbeddings('de-crawl')

Contextual string embeddings are powerful embeddings that capture latent syntactic-semantic information that goes beyond standard word embeddings. Key differences are: (1) they are trained without any explicit notion of words and thus fundamentally model words as sequences of characters. And (2) they are contextualized by their surrounding text, meaning that the same word will have different embeddings depending on its contextual use
With Flair, you can use these embeddings simply by instantiating the appropriate embedding class, same as standard word embeddings:
You choose which embeddings you load by passing the appropriate string to the constructor of the FlairEmbeddings class. For all supported languages, there is a forward and a backward model. You can load a model for a language by using the two-letter language code followed by a hyphen and either forward or backward. So, if you want to load the forward and backward Flair models for German, do it like this:
Check out the full list of all pre-trained FlairEmbeddings models here, along with more information on standard usage.
from flair.embeddings import FlairEmbeddings
from flair.data import Sentence
# init embedding
flair_embedding_forward = FlairEmbeddings('news-forward')
# create a sentence
sentence = Sentence('The grass is green .')
# embed words in sentence
flair_embedding_forward.embed(sentence)
Stacked embeddings are one of the most important concepts of this library. You can use them to combine different embeddings together, for instance if you want to use both traditional embeddings together with contextual string embeddings. Stacked embeddings allow you to mix and match. We find that a combination of embeddings often gives best results.
All you need to do is use the StackedEmbeddings class and instantiate it by passing a list of embeddings that you wish to combine. For instance, lets combine classic GloVe embeddings with forward and backward Flair embeddings. This is a combination that we generally recommend to most users, especially for sequence labeling.
Now instantiate the StackedEmbeddings class and pass it a list containing these two embeddings.
That’s it! Now just use this embedding like all the other embeddings, i.e. call the embed() method over your sentences.
Words are now embedded using a concatenation of three different embeddings. This means that the resulting embedding vector is still a single PyTorch vector.
from flair.embeddings import WordEmbeddings, FlairEmbeddings
from flair.data import Sentence
# init standard GloVe embedding
glove_embedding = WordEmbeddings('glove')
# init Flair forward and backwards embeddings
flair_embedding_forward = FlairEmbeddings('news-forward')
flair_embedding_backward = FlairEmbeddings('news-backward')
from flair.embeddings import StackedEmbeddings
# create a StackedEmbedding object that combines glove and forward/backward flair embeddings
stacked_embeddings = StackedEmbeddings([
glove_embedding,
flair_embedding_forward,
flair_embedding_backward,
])
sentence = Sentence('The grass is green .')
# just embed a sentence using the StackedEmbedding as you would with any single embedding.
stacked_embeddings.embed(sentence)
# now check out the embedded tokens.
for token in sentence:
print(token)
print(token.embedding)
print(token.embedding.shape)
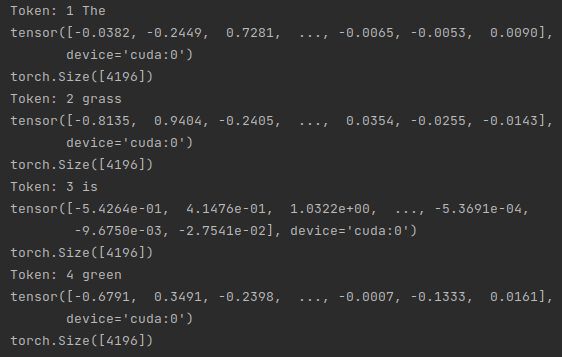
To get more details on these embeddings and a full overview of all word embeddings that we support, you can look into this tutorial. You can also skip details on word embeddings and go directly to document embeddings that let you embed entire text passages with one vector for tasks such as text classification. You can also go directly to the tutorial about loading your corpus, which is a pre-requirement for training your own models.
All word embedding classes inherit from the TokenEmbeddings class and implement the embed() method which you need to call to embed your text. This means that for most users of Flair, the complexity of different embeddings remains hidden behind this interface. Simply instantiate the embedding class you require and call embed() to embed your text.

You can very easily mix and match Flair, ELMo, BERT and classic word embeddings. All you need to do is instantiate each embedding you wish to combine and use them in a StackedEmbedding.
For instance, let’s say we want to combine the multilingual Flair and BERT embeddings to train a hyper-powerful multilingual downstream task model. First, instantiate the embeddings you wish to combine:
Words are now embedded using a concatenation of three different embeddings. This means that the resulting embedding vector is still a single PyTorch vector.
You can now either look into document embeddings to embed entire text passages with one vector for tasks such as text classification, or go directly to the tutorial about loading your corpus, which is a pre-requirement for training your own models.
from flair.embeddings import FlairEmbeddings, TransformerWordEmbeddings
from flair.data import Sentence
# init Flair embeddings
flair_forward_embedding = FlairEmbeddings('multi-forward')
flair_backward_embedding = FlairEmbeddings('multi-backward')
# init multilingual BERT
bert_embedding = TransformerWordEmbeddings('bert-base-multilingual-cased')
from flair.embeddings import StackedEmbeddings
# now create the StackedEmbedding object that combines all embeddings
stacked_embeddings = StackedEmbeddings(
embeddings=[flair_forward_embedding, flair_backward_embedding, bert_embedding])
sentence = Sentence('The grass is green .')
# just embed a sentence using the StackedEmbedding as you would with any single embedding.
stacked_embeddings.embed(sentence)
# now check out the embedded tokens.
for token in sentence:
print(token)
print(token.embedding)
print(token.embedding.shape)
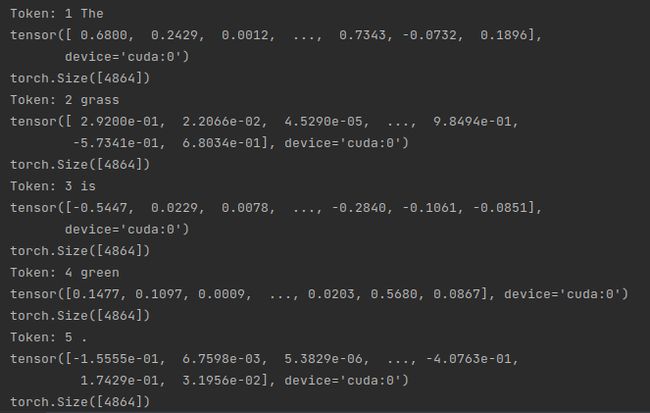
Document embeddings are different from word embeddings in that they give you one embedding for an entire text, whereas word embeddings give you embeddings for individual words.
All document embedding classes inherit from the DocumentEmbeddings class and implement the embed() method which you need to call to embed your text. This means that for most users of Flair, the complexity of different embeddings remains hidden behind this interface.
There are four main document embeddings in Flair:
- DocumentPoolEmbeddings that simply do an average over all word embeddings in the sentence,
- DocumentRNNEmbeddings that train an RNN over all word embeddings in a sentence
- TransformerDocumentEmbeddings that use pre-trained transformers and are recommended for most text classification tasks
- SentenceTransformerDocumentEmbeddings that use pre-trained transformers and are recommended if you need a good vector representation of a sentence
The simplest type of document embedding does a pooling operation over all word embeddings in a sentence to obtain an embedding for the whole sentence. The default is mean pooling, meaning that the average of all word embeddings is used.
To instantiate, you need to pass a list of word embeddings to pool over:
This prints out the embedding of the document. Since the document embedding is derived from word embeddings, its dimensionality depends on the dimensionality of word embeddings you are using. For more details on these embeddings, check here.
One advantage of DocumentPoolEmbeddings is that they do not need to be trained, you can immediately use them to embed your documents.
from flair.embeddings import WordEmbeddings, DocumentPoolEmbeddings
from flair.data import Sentence
# initialize the word embeddings
glove_embedding = WordEmbeddings('glove')
# initialize the document embeddings, mode = mean
document_embeddings = DocumentPoolEmbeddings([glove_embedding])
# create an example sentence
sentence = Sentence('The grass is green . And the sky is blue .')
# embed the sentence with our document embedding
document_embeddings.embed(sentence)
# now check out the embedded sentence.
print(sentence.embedding)
print(sentence.embedding.shape)
torch.Size([100])
These embeddings run an RNN over all words in sentence and use the final state of the RNN as embedding for the whole document. In order to use the DocumentRNNEmbeddings you need to initialize them by passing a list of token embeddings to it:
By default, a GRU-type RNN is instantiated. Now, create an example sentence and call the embedding’s embed() method.
This will output a single embedding for the complete sentence. The embedding dimensionality depends on the number of hidden states you are using and whether the RNN is bidirectional or not. For more details on these embeddings, check here.
Note that when you initialize this embedding, the RNN weights are randomly initialized. So this embedding needs to be trained in order to make sense.
from flair.embeddings import WordEmbeddings, DocumentRNNEmbeddings
from flair.data import Sentence
glove_embedding = WordEmbeddings('glove')
document_embeddings = DocumentRNNEmbeddings([glove_embedding])
# create an example sentence
sentence = Sentence('The grass is green . And the sky is blue .')
# embed the sentence with our document embedding
document_embeddings.embed(sentence)
# now check out the embedded sentence.
print(sentence.get_embedding())
print(sentence.get_embedding().shape)
torch.Size([128])
You can get embeddings for a whole sentence directly from a pre-trained transformer. There is a single class for all transformer embeddings that you instantiate with different identifiers get different transformers. For instance, to load a standard BERT transformer model, do:
from flair.embeddings import TransformerDocumentEmbeddings
from flair.data import Sentence
# init embedding
embedding = TransformerDocumentEmbeddings('bert-base-uncased')
# create a sentence
sentence = Sentence('The grass is green .')
# embed the sentence
embedding.embed(sentence)
# now check out the embedded sentence.
print(sentence.get_embedding())
print(sentence.get_embedding().shape)
torch.Size([768])
from flair.embeddings import TransformerDocumentEmbeddings
from flair.data import Sentence
# init embedding
embedding = TransformerDocumentEmbeddings('roberta-base')
# create a sentence
sentence = Sentence('The grass is green .')
# embed the sentence
embedding.embed(sentence)
# now check out the embedded sentence.
print(sentence.get_embedding())
print(sentence.get_embedding().shape)
torch.Size([768])
Here is a full list of all models (BERT, RoBERTa, XLM, XLNet etc.). You can use any of these models with this class.
You can also get several embeddings from the sentence-transformer library. These models are pre-trained to give good general-purpose vector representations for sentences.
from flair.data import Sentence
from flair.embeddings import SentenceTransformerDocumentEmbeddings
# init embedding
embedding = SentenceTransformerDocumentEmbeddings('bert-base-nli-mean-tokens')
# create a sentence
sentence = Sentence('The grass is green .')
# embed the sentence
embedding.embed(sentence)
# now check out the embedded sentence.
print(sentence.get_embedding())
print(sentence.get_embedding().shape)
torch.Size([768])
You can find a full list of their pretained models here
You can now either look into the tutorial about loading your corpus, which is a pre-requirement for training your own models or into training your own embeddings.