ClickHouse主键索引最佳实践
在本文中,我们将深入研究ClickHouse索引。我们将对此进行详细说明和讨论:
- ClickHouse的索引与传统的关系数据库有何不同
- ClickHouse是怎样构建和使用主键稀疏索引的
- ClickHouse索引的最佳实践
您可以选择在自己的机器上执行本文给出的所有Clickhouse SQL语句和查询。
这篇文章主要关注稀疏索引。
一、数据集
在本文中,我们将使用一个匿名的web流量数据集。
- 我们将使用样本数据集中的887万行(事件)的子集。
- 未压缩的数据大小为887万个事件和大约700mb。当存储在ClickHouse时,压缩为200mb。
- 在我们的子集中,每行包含三列,表示在特定时间(EventTime列)单击URL (URL列)的互联网用户(UserID列)。
通过这三个列,我们已经可以制定一些典型的web分析查询,如:
- 某个用户点击次数最多的前10个url是什么?
- 点击某个URL次数最多的前10名用户是谁?
- 用户点击特定URL的最频繁时间(比如一周中的几天)是什么?
二、测试环境
本文档中给出的所有运行时数据都是在带有Apple M1 Pro芯片和16GB RAM的MacBook Pro上本地运行ClickHouse 22.2.1。
三、全表扫描
为了了解在没有主键的情况下如何对数据集执行查询,我们通过执行以下SQL DDL语句(使用MergeTree表引擎)创建了一个表:
CREATE TABLE hits_NoPrimaryKey
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY tuple();
INSERT INTO hits_NoPrimaryKey SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
结果:
Ok.
0 rows in set. Elapsed: 145.993 sec. Processed 8.87 million rows, 18.40 GB (60.78 thousand rows/s., 126.06 MB/s.)
ClickHouse客户端输出了执行结果,插入了887万行数据。
最后,为了简化本文后面的讨论,并使图表和结果可重现,我们使用FINAL关键字optimize该表:
OPTIMIZE TABLE hits_NoPrimaryKey FINAL;
一般来说,不需要也不建议在加载数据后立即执行optimize。对于这个示例,为什么需要这样做是很明显的。
现在我们执行第一个web分析查询。以下是用户id为749927693的互联网用户点击次数最多的前10个url:
SELECT URL, count(URL) as Count
FROM hits_NoPrimaryKey
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
结果:
┌─URL────────────────────────────┬─Count─┐
│ http://auto.ru/chatay-barana.. │ 170 │
│ http://auto.ru/chatay-id=371...│ 52 │
│ http://public_search │ 45 │
│ http://kovrik-medvedevushku-...│ 36 │
│ http://forumal │ 33 │
│ http://korablitz.ru/L_1OFFER...│ 14 │
│ http://auto.ru/chatay-id=371...│ 14 │
│ http://auto.ru/chatay-john-D...│ 13 │
│ http://auto.ru/chatay-john-D...│ 10 │
│ http://wot/html?page/23600_m...│ 9 │
└────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.022 sec.
Processed 8.87 million rows,
70.45 MB (398.53 million rows/s., 3.17 GB/s.)
ClickHouse客户端输出表明,ClickHouse执行了一个完整的表扫描!我们的表的887万行中的每一行都被加载到ClickHouse中,这不是可扩展的。
为了使这种(方式)更有效和更快,我们需要使用一个具有适当主键的表。这将允许ClickHouse自动(基于主键的列)创建一个稀疏的主索引,然后可以用于显著加快我们示例查询的执行。
四、包含主键的表
创建一个包含联合主键UserID和URL列的表:
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
DDL详情
上面DDL语句中的主键会基于两个指定的键列创建主索引。
插入数据:
INSERT INTO hits_UserID_URL SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
结果:
0 rows in set. Elapsed: 149.432 sec. Processed 8.87 million rows, 18.40 GB (59.38 thousand rows/s., 123.16 MB/s.)
optimize表:
OPTIMIZE TABLE hits_UserID_URL FINAL;
我们可以使用下面的查询来获取关于表的元数据:
SELECT
part_type,
path,
formatReadableQuantity(rows) AS rows,
formatReadableSize(data_uncompressed_bytes) AS data_uncompressed_bytes,
formatReadableSize(data_compressed_bytes) AS data_compressed_bytes,
formatReadableSize(primary_key_bytes_in_memory) AS primary_key_bytes_in_memory,
marks,
formatReadableSize(bytes_on_disk) AS bytes_on_disk
FROM system.parts
WHERE (table = 'hits_UserID_URL') AND (active = 1)
FORMAT Vertical;
结果:
part_type: Wide
path: ./store/d9f/d9f36a1a-d2e6-46d4-8fb5-ffe9ad0d5aed/all_1_9_2/
rows: 8.87 million
data_uncompressed_bytes: 733.28 MiB
data_compressed_bytes: 206.94 MiB
primary_key_bytes_in_memory: 96.93 KiB
marks: 1083
bytes_on_disk: 207.07 MiB
1 rows in set. Elapsed: 0.003 sec.
客户端输出表明:
- 表数据以wide format存储在一个特定目录,每个列有一个数据文件和mark文件。
- 表有887万行数据。
- 未压缩的数据有733.28 MB。
- 压缩之后的数据有206.94 MB。
- 有1083个主键索引条目,大小是96.93 KB。
- 在磁盘上,表的数据、标记文件和主索引文件总共占用207.07 MB。
五、针对海量数据规模的索引设计
在传统的关系数据库管理系统中,每个表行包含一个主索引。对于我们的数据集,这将导致主索引——通常是一个B(+)-Tree的数据结构——包含887万个条目。 这样的索引允许快速定位特定的行,从而提高查找点查和更新的效率。在B(+)-Tree数据结构中搜索一个条目的平均时间复杂度为O(log2n)。对于一个有887万行的表,这意味着需要23步来定位任何索引条目。 这种能力是有代价的:额外的磁盘和内存开销,以及向表中添加新行和向索引中添加条目时更高的插入成本(有时还需要重新平衡B-Tree)。 考虑到与B-Tee索引相关的挑战,ClickHouse中的表引擎使用了一种不同的方法。ClickHouseMergeTree Engine引擎系列被设计和优化用来处理大量数据。 这些表被设计为每秒接收数百万行插入,并存储非常大(100 pb)的数据量。 数据被一批一批的快速写入表中,并在后台应用合并规则。
在ClickHouse中,每个数据部分(data part)都有自己的主索引。当他们被合并时,合并部分的主索引也被合并。
在大规模中情况下,磁盘和内存的效率是非常重要的。因此,不是为每一行创建索引,而是为一组数据行(称为颗粒(granule))构建一个索引条目。
之所以可以使用这种稀疏索引,是因为ClickHouse会按照主键列的顺序将一组行存储在磁盘上。
与直接定位单个行(如基于B-Tree的索引)不同,稀疏主索引允许它快速(通过对索引项进行二分查找)识别可能匹配查询的行组。
然后潜在的匹配行组(颗粒)以并行的方式被加载到ClickHouse引擎中,以便找到匹配的行。
这种索引设计允许主索引很小(它可以而且必须完全适合主内存),同时仍然显著加快查询执行时间:特别是对于数据分析用例中常见的范围查询。
下面详细说明了ClickHouse是如何构建和使用其稀疏主索引的。在本文后面,我们将讨论如何选择、移除和排序用于构建索引的表列(主键列)的一些最佳实践。
六、数据按照主键排序存储在磁盘上
上面创建的表有:
- 联合主键 (UserID, URL)
- 联合排序键 (UserID, URL, EventTime)。
-
如果我们只指定了排序键,那么主键将隐式定义为排序键。
-
为了提高内存效率,我们显式地指定了一个主键,只包含查询过滤的列。基于主键的主索引被完全加载到主内存中。
-
为了上下文的一致性和最大的压缩比例,我们单独定义了排序键,排序键包含当前表所有的列(和压缩算法有关,一般排序之后又更好的压缩率)。
-
如果同时指定了主键和排序键,则主键必须是排序键的前缀。
插入的行按照主键列(以及排序键的附加EventTime列)的字典序(从小到大)存储在磁盘上。
ClickHouse允许插入具有相同主键列的多行数据。在这种情况下(参见下图中的第1行和第2行),最终的顺序是由指定的排序键决定的,这里是EventTime列的值。
如下图所示:ClickHouse是列存数据库。
- 在磁盘上,每个表都有一个数据文件(*.bin),该列的所有值都以压缩格式存储,并且
- 在这个例子中,这887万行按主键列(以及附加的排序键列)的字典升序存储在磁盘上
- UserID第一位,
- 然后是URL,
- 最后是EventTime:
UserID.bin,URL.bin,和EventTime.bin是UserID,URL,和EventTime列的数据文件。
-
因为主键定义了磁盘上行的字典顺序,所以一个表只能有一个主键。
-
我们从0开始对行进行编号,以便与ClickHouse内部行编号方案对齐,该方案也用于记录消息。
七、数据被组织成颗粒以进行并行数据处理
出于数据处理的目的,表的列值在逻辑上被划分为多个颗粒。颗粒是流进ClickHouse进行数据处理的最小的不可分割数据集。这意味着,ClickHouse不是读取单独的行,而是始终读取(以流方式并并行地)整个行组(颗粒)。
列值并不物理地存储在颗粒中,颗粒只是用于查询处理的列值的逻辑组织方式。
下图显示了如何将表中的887万行(列值)组织成1083个颗粒,这是表的DDL语句包含设置index_granularity(设置为默认值8192)的结果。
第一个(根据磁盘上的物理顺序)8192行(它们的列值)在逻辑上属于颗粒0,然后下一个8192行(它们的列值)属于颗粒1,以此类推。
-
最后一个颗粒(1082颗粒)是少于8192行的。
-
我们在本指南开头的“DDL 语句详细信息”中提到,我们禁用了自适应索引粒度(为了简化本指南中的讨论,并使图表和结果可重现)。
因此,示例表中所有颗粒(除了最后一个)都具有相同大小。
-
对于具有自适应索引粒度的表(默认情况下索引粒度是自适应的),某些粒度的大小可以小于 8192 行,具体取决于行数据大小。
-
我们将主键列(UserID, URL)中的一些列值标记为橙色。
这些橙色标记的列值是每个颗粒中第一行的主键列值。正如我们将在下面看到的,这些橙色标记的列值将是表主索引中的条目。
-
我们从0开始对行进行编号,以便与ClickHouse内部行编号方案对齐,该方案也用于记录消息。
八、每个颗粒对应主索引的一个条目
主索引是基于上图中显示的颗粒创建的。这个索引是一个未压缩的扁平数组文件(primary.idx),包含从0开始的所谓的数字索引标记。
下面的图显示了索引存储了每个颗粒的最小主键列值(在上面的图中用橙色标记的值)。 例如:
- 第一个索引条目(下图中的“mark 0”)存储上图中颗粒0的主键列的最小值,
- 第二个索引条目(下图中的“mark 1”)存储上图中颗粒1的主键列的最小值,以此类推。
在我们的表中,索引总共有1083个条目,887万行数据和1083个颗粒:
-
最后一个索引条目(上图中的“mark 1082”)存储了上图中颗粒1082的主键列的最大值。
-
索引条目(索引标记)不是基于表中的特定行,而是基于颗粒。例如,对于上图中的索引条目‘mark 0’,在我们的表中没有UserID为240.923且URL为“goal://metry=10000467796a411…”的行,相反,对于该表,有一个颗粒0,在该颗粒中,最小UserID值是240.923,最小URL值是“goal://metry=10000467796a411…”,这两个值来自不同的行。
-
主索引文件完全加载到主内存中。如果文件大于可用的空闲内存空间,则ClickHouse将发生错误。
主键条目称为索引标记,因为每个索引条目都标志着特定数据范围的开始。对于示例表:
-
UserID index marks:
主索引中存储的UserID值按升序排序。
上图中的‘mark 1’指示颗粒1中所有表行的UserID值,以及随后所有颗粒中的UserID值,都保证大于或等于4.073.710。正如我们稍后将看到的, 当查询对主键的第一列进行过滤时,此全局有序使ClickHouse能够对第一个键列的索引标记使用二分查找算法。
-
URL index marks:
主键列UserID和URL有相同的基数,这意味着第一列之后的所有主键列的索引标记通常只表示每个颗粒的数据范围。
例如,‘mark 0’中的URL列所有的值都大于等于goal://metry=10000467796a411..., 然后颗粒1中的URL并不是如此,这是因为‘mark 1‘与‘mark 0‘具有不同的UserID列值。稍后我们将更详细地讨论这对查询执行性能的影响。
九、主索引被用来选择颗粒
现在,我们可以在主索引的支持下执行查询。
下面计算UserID 749927693点击次数最多的10个url。
SELECT URL, count(URL) AS Count
FROM hits_UserID_URL
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
结果:
┌─URL────────────────────────────┬─Count─┐
│ http://auto.ru/chatay-barana.. │ 170 │
│ http://auto.ru/chatay-id=371...│ 52 │
│ http://public_search │ 45 │
│ http://kovrik-medvedevushku-...│ 36 │
│ http://forumal │ 33 │
│ http://korablitz.ru/L_1OFFER...│ 14 │
│ http://auto.ru/chatay-id=371...│ 14 │
│ http://auto.ru/chatay-john-D...│ 13 │
│ http://auto.ru/chatay-john-D...│ 10 │
│ http://wot/html?page/23600_m...│ 9 │
└────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.005 sec.
Processed 8.19 thousand rows,
740.18 KB (1.53 million rows/s., 138.59 MB/s.)
ClickHouse客户端的输出显示,没有进行全表扫描,只有8.19千行流到ClickHouse。
如果trace logging打开了,那ClickHouse服务端日志会显示ClickHouse正在对1083个UserID索引标记执行二分查找以便识别可能包含UserID列值为749927693的行的颗粒。这需要19个步骤,平均时间复杂度为O(log2 n):
...Executor): Key condition: (column 0 in [749927693, 749927693])
...Executor): Running binary search on index range for part all_1_9_2 (1083 marks)
...Executor): Found (LEFT) boundary mark: 176
...Executor): Found (RIGHT) boundary mark: 177
...Executor): Found continuous range in 19 steps
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
1/1083 marks by primary key, 1 marks to read from 1 ranges
...Reading ...approx. 8192 rows starting from 1441792
我们可以在上面的跟踪日志中看到,1083个现有标记中有一个满足查询。Trace Log详情
我们也可以通过使用EXPLAIN来重现这个结果:
EXPLAIN indexes = 1
SELECT URL, count(URL) AS Count
FROM hits_UserID_URL
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
结果如下:
┌─explain───────────────────────────────────────────────────────────────────────────────┐
│ Expression (Projection) │
│ Limit (preliminary LIMIT (without OFFSET)) │
│ Sorting (Sorting for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromMergeTree │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ UserID │
│ Condition: (UserID in [749927693, 749927693]) │
│ Parts: 1/1 │
│ Granules: 1/1083 │
└───────────────────────────────────────────────────────────────────────────────────────┘
16 rows in set. Elapsed: 0.003 sec.
客户端输出显示,在1083个颗粒中选择了一个可能包含UserID列值为749927693的行。
当查询对联合主键的一部分并且是第一个主键进行过滤时,ClickHouse将主键索引标记运行二分查找算法。
正如上面所讨论的,ClickHouse使用它的稀疏主索引来快速(通过二分查找算法)选择可能包含匹配查询的行的颗粒。
这是ClickHouse查询执行的第一阶段(颗粒选择)。
在第二阶段(数据读取中), ClickHouse定位所选的颗粒,以便将它们的所有行流到ClickHouse引擎中,以便找到实际匹配查询的行。
我们将在下一节更详细地讨论第二阶段。
十、标记文件用来定位颗粒
下图描述了上表主索引文件的一部分。
如上所述,通过对索引的1083个UserID标记进行二分搜索,确定了第176个标记。因此,它对应的颗粒176可能包含UserID列值为749.927.693的行。
颗粒选择的具体过程
为了确认(或排除)颗粒176中的某些行包含UserID列值为749.927.693,需要将属于此颗粒的所有8192行读取到ClickHouse。
为了读取这部分数据,ClickHouse需要知道颗粒176的物理地址。
在ClickHouse中,我们表的所有颗粒的物理位置都存储在标记文件中。与数据文件类似,每个表的列有一个标记文件。
下图显示了三个标记文件UserID.mrk、URL.mrk、EventTime.mrk,为表的UserID、URL和EventTime列存储颗粒的物理位置。
我们已经讨论了主索引是一个扁平的未压缩数组文件(primary.idx),其中包含从0开始编号的索引标记。
类似地,标记文件也是一个扁平的未压缩数组文件(*.mrk),其中包含从0开始编号的标记。
一旦ClickHouse确定并选择了可能包含查询所需的匹配行的颗粒的索引标记,就可以在标记文件数组中查找,以获得颗粒的物理位置。
每个特定列的标记文件条目以偏移量的形式存储两个位置:
-
第一个偏移量(上图中的'block_offset')是在包含所选颗粒的压缩版本的压缩列数据文件中定位块。这个压缩块可能包含几个压缩的颗粒。所定位的压缩文件块在读取时被解压到内存中。
-
标记文件的第二个偏移量(上图中的“granule_offset”)提供了颗粒在解压数据块中的位置。
定位到的颗粒中的所有8192行数据都会被ClickHouse加载然后进一步处理。
为什么主索引不直接包含与索引标记相对应的颗粒的物理位置?
因为ClickHouse设计的场景就是超大规模数据,非常高效地使用磁盘和内存非常重要。
主索引文件需要放入内存中。
对于我们的示例查询,ClickHouse使用了主索引,并选择了可能包含与查询匹配的行的单个颗粒。只有对于这一个颗粒,ClickHouse才需定位物理位置,以便将相应的行组读取以进一步的处理。
而且,只有UserID和URL列需要这个偏移量信息。
对于查询中不使用的列,例如EventTime,不需要偏移量信息。
对于我们的示例查询,Clickhouse只需要UserID数据文件(UserID.bin)中176颗粒的两个物理位置偏移,以及URL数据文件(URL.data)中176颗粒的两个物理位置偏移。
由mark文件提供的间接方法避免了直接在主索引中存储所有三个列的所有1083个颗粒的物理位置的条目:因此避免了在主内存中有不必要的(可能未使用的)数据。
下面的图表和文本说明了我们的查询示例,ClickHouse如何在UserID.bin数据文件中定位176颗粒。
我们在本文前面讨论过,ClickHouse选择了主索引标记176,因此176颗粒可能包含查询所需的匹配行。
ClickHouse现在使用从索引中选择的标记号(176)在UserID.mark中进行位置数组查找,以获得两个偏移量,用于定位颗粒176。
如图所示,第一个偏移量是定位UserID.bin数据文件中的压缩文件块,该数据文件包含颗粒176的压缩数据。
一旦所定位的文件块被解压缩到主内存中,就可以使用标记文件的第二个偏移量在未压缩的数据中定位颗粒176。
ClickHouse需要从UserID.bin数据文件和URL.bin数据文件中定位(读取)颗粒176,以便执行我们的示例查询(UserID为749.927.693的互联网用户点击次数最多的10个url)。
上图显示了ClickHouse如何定位UserID.bin数据文件的颗粒。
同时,ClickHouse对URL.bin数据文件的颗粒176执行相同的操作。这两个不同的颗粒被对齐并加载到ClickHouse引擎以进行进一步的处理,即聚合并计算UserID为749.927.693的所有行的每组URL值,最后以计数降序输出10个最大的URL组。
十一、查询使用第二位主键的性能问题
当查询对复合键的一部分并且是第一个主键列进行过滤时,ClickHouse将对主键列的索引标记运行二分查找。
但是,当查询对联合主键的一部分但不是第一个键列进行过滤时,会发生什么情况?
我们讨论了这样一种场景:查询不是显式地对第一个主键列进行过滤,而是对第一个主键列之后的任何键列进行过滤。
当查询同时对第一个主键列和第一个主键列之后的任何键列进行过滤时,ClickHouse将对第一个主键列的索引标记运行二分查找。
我们使用一个查询来计算最点击"http://public_search"的最多的前10名用户:
SELECT UserID, count(UserID) AS Count
FROM hits_UserID_URL
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
结果是:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.086 sec.
Processed 8.81 million rows,
799.69 MB (102.11 million rows/s., 9.27 GB/s.)
客户端输出表明,尽管URL列是联合主键的一部分,ClickHouse几乎执行了一一次全表扫描!ClickHouse从表的887万行中读取881万行。
如果启用了trace日志,那么ClickHouse服务日志文件显示,ClickHouse在1083个URL索引标记上使用了通用的排除搜索,以便识别那些可能包含URL列值为"http://public_search"的行。
...Executor): Key condition: (column 1 in ['http://public_search',
'http://public_search'])
...Executor): Used generic exclusion search over index for part all_1_9_2
with 1537 steps
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
1076/1083 marks by primary key, 1076 marks to read from 5 ranges
...Executor): Reading approx. 8814592 rows with 10 streams
我们可以在上面的跟踪日志示例中看到,1083个颗粒中有1076个(通过标记)被选中,因为可能包含具有匹配URL值的行。
这将导致881万行被读取到ClickHouse引擎中(通过使用10个流并行地读取),以便识别实际包含URL值"http://public_search"的行。
然而,稍后仅仅39个颗粒包含匹配的行。
虽然基于联合主键(UserID, URL)的主索引对于加快过滤具有特定UserID值的行的查询非常有用,但对于过滤具有特定URL值的行的查询,索引并没有提供显著的帮助。
原因是URL列不是第一个主键列,因此ClickHouse是使用一个通用的排除搜索算法(而不是二分查找)查找URL列的索引标志,和UserID主键列不同,它的算法的有效性依赖于URL列的基数。
为了说明,我们给出通用的排除搜索算法的工作原理:
通用排除搜索算法
下面将演示当通过第一个列之后的任何列选择颗粒时,当前一个键列具有或高或低的基数时,ClickHouse通用排除搜索算法 是如何工作的。
作为这两种情况的例子,我们将假设:
- 搜索URL值为"W3"的行。
- 点击表抽象简化为只有简单值的UserID和UserID。
- 相同联合主键(UserID、URL)。这意味着行首先按UserID值排序,具有相同UserID值的行然后再按URL排序。
- 颗粒大小为2,即每个颗粒包含两行。
在下面的图表中,我们用橙色标注了每个颗粒的最小键列值。
前缀主键低基数
假设UserID具有较低的基数。在这种情况下,相同的UserID值很可能分布在多个表行和颗粒上,从而分布在索引标记上。对于具有相同UserID的索引标记,索引标记的URL值按升序排序(因为表行首先按UserID排序,然后按URL排序)。这使得有效的过滤如下所述:
在上图中,我们的抽象样本数据的颗粒选择过程有三种不同的场景:
-
如果索引标记0的(最小)URL值小于W3,并且紧接索引标记的URL值也小于W3,则可以排除索引标记0,因为标记0、标记1和标记2具有相同的UserID值。注意,这个排除前提条件确保颗粒0和下一个颗粒1完全由U1 UserID值组成,这样ClickHouse就可以假设颗粒0中的最大URL值也小于W3并排除该颗粒。
-
如果索引标记1的URL值小于(或等于)W3,并且后续索引标记的URL值大于(或等于)W3,则选择索引标记1,因为这意味着粒度1可能包含URL为W3的行)。
-
可以排除URL值大于W3的索引标记2和3,因为主索引的索引标记存储了每个颗粒的最小键列值,因此颗粒2和3不可能包含URL值W3。
前缀主键高基数
当UserID具有较高的基数时,相同的UserID值不太可能分布在多个表行和颗粒上。这意味着索引标记的URL值不是单调递增的:
正如在上面的图表中所看到的,所有URL值小于W3的标记都被选中,以便将其关联的颗粒的行加载到ClickHouse引擎中。
这是因为虽然图中的所有索引标记都属于上面描述的场景1,但它们不满足前面提到的排除前提条件,即两个直接随后的索引标记都具有与当前标记相同的UserID值,因此不能被排除。
例如,考虑索引标记0,其URL值小于W3,并且其直接后续索引标记的URL值也小于W3。这不能排除,因为两个直接随后的索引标记1和2与当前标记0没有相同的UserID值。
请注意,随后的两个索引标记需要具有相同的UserID值。这确保了当前和下一个标记的颗粒完全由U1 UserID值组成。如果仅仅是下一个标记具有相同的UserID,那么下一个标记的URL值可能来自具有不同UserID的表行——当您查看上面的图表时,确实是这样的情况,即W2来自U2而不是U1的行。
这最终阻止了ClickHouse对颗粒0中的最大URL值进行假设。相反,它必须假设颗粒0可能包含URL值为W3的行,并被迫选择标记0。
同样的情况也适用于标记1、2和3。
当查询对联合主键的一部分列(但不是第一个键列)进行过滤时,ClickHouse使用的通用排除搜索算法(而不是二分查找)在前一个键列基数较低时最有效。
在我们的示例数据集中,两个键列(UserID、URL)都具有类似的高基数,并且,如前所述,当URL列的前一个键列具有较高基数时,通用排除搜索算法不是很有效。
因为UserID和URL具有较高的基数,根据URL过滤数据不是特别有效,对URL列创建二级跳数索引同样也不会有太多改善。
例如,这两个语句在我们的表的URL列上创建并填充一个minmax跳数索引。
ALTER TABLE hits_UserID_URL ADD INDEX url_skipping_index URL TYPE minmax GRANULARITY 4;
ALTER TABLE hits_UserID_URL MATERIALIZE INDEX url_skipping_index;
ClickHouse现在创建了一个额外的索引来存储—每组4个连续的颗粒(注意上面ALTER TABLE语句中的GRANULARITY 4子句)—最小和最大的URL值:
第一个索引条目(上图中的mark 0)存储属于表的前4个颗粒的行的最小和最大URL值。
第二个索引条目(mark 1)存储属于表中下一个4个颗粒的行的最小和最大URL值,依此类推。
(ClickHouse还为跳数索引创建了一个特殊的标记文件,用于定位与索引标记相关联的颗粒组。)
由于UserID和URL的基数相似,在执行对URL的查询过滤时,这个二级跳数索引不能帮助排除选择的颗粒。
正在寻找的特定URL值('http://public_search')很可能是索引为每组颗粒存储的最小值和最大值之间的值,导致ClickHouse被迫选择这组颗粒(因为它们可能包含匹配查询的行)。
因此,如果我们想显著提高过滤具有特定URL的行的示例查询的速度,那么我们需要使用针对该查询优化的主索引。
此外,如果我们想保持过滤具有特定UserID的行的示例查询的良好性能,那么我们需要使用多个主索引。
下面是实现这一目标的方法。
十二、使用多个主键索引进行调优
如果我们想显著加快我们的两个示例查询——一个过滤具有特定UserID的行,一个过滤具有特定URL的行——那么我们需要使用多个主索引,通过使用这三个方法中的一个:
- 新建一个不同主键的新表。
- 创建一个物化视图。
- 增加projection。
这三个方法都会有效地将示例数据复制到另一个表中,以便重新组织表的主索引和行排序顺序。
然而,这三个选项的不同之处在于,附加表对于查询和插入语句的路由对用户的透明程度。
当创建有不同主键的第二个表时,查询必须显式地发送给最适合查询的表版本,并且必须显式地插入新数据到两个表中,以保持表的同步:
在物化视图中,额外的表被隐藏,数据自动在两个表之间保持同步:
projection方式是最透明的选项,因为除了自动保持隐藏的附加表与数据变化同步外,ClickHouse还会自动选择最有效的表版本进行查询:
下面我们使用真实的例子详细讨论下这三种方式。
十三、通过辅助表使用联合主键索引
我们创建一个新的附加表,其中我们在主键中切换键列的顺序(与原始表相比):
CREATE TABLE hits_URL_UserID
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (URL, UserID)
ORDER BY (URL, UserID, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
写入887万行源表数据:
INSERT INTO hits_URL_UserID
SELECT * from hits_UserID_URL;
结果:
Ok.
0 rows in set. Elapsed: 2.898 sec. Processed 8.87 million rows, 838.84 MB (3.06 million rows/s., 289.46 MB/s.)
最后optimize下:
OPTIMIZE TABLE hits_URL_UserID FINAL;
因为我们切换了主键中列的顺序,插入的行现在以不同的字典顺序存储在磁盘上(与我们的原始表相比),因此该表的1083个颗粒也包含了与以前不同的值:
主键索引如下:
现在计算最频繁点击URL"http://public_search"的前10名用户,这时候的查询速度是明显加快的:
SELECT UserID, count(UserID) AS Count
FROM hits_URL_UserID
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
结果:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.017 sec.
Processed 319.49 thousand rows,
11.38 MB (18.41 million rows/s., 655.75 MB/s.)
现在没有全表扫描了,ClickHouse执行高效了很多。
对于原始表中的主索引(其中UserID是第一个键列,URL是第二个键列),ClickHouse在索引标记上使用了通用排除搜索来执行该查询,但这不是很有效,因为UserID和URL的基数同样很高。
将URL作为主索引的第一列,ClickHouse现在对索引标记运行二分搜索。ClickHouse服务器日志文件中对应的跟踪日志:
...Executor): Key condition: (column 0 in ['http://public_search',
'http://public_search'])
...Executor): Running binary search on index range for part all_1_9_2 (1083 marks)
...Executor): Found (LEFT) boundary mark: 644
...Executor): Found (RIGHT) boundary mark: 683
...Executor): Found continuous range in 19 steps
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
39/1083 marks by primary key, 39 marks to read from 1 ranges
...Executor): Reading approx. 319488 rows with 2 streams
ClickHouse只选择了39个索引标记,而不是使用通用排除搜索时的1076个。
请注意,辅助表经过了优化,以加快对url的示例查询过滤的执行。
像之前我们查询过滤URL一样,如果我们现在对辅助表查询过滤UserID,性能同样会比较差,因为现在UserID是第二主索引键列,所以ClickHouse将使用通用排除搜索算法查找颗粒,这对于类似高基数的UserID和URL来说不是很有效。
点击下面了解详情:
对UserID的查询过滤性能较差
现在我们有了两张表。优化了对UserID和URL的查询过滤,分别:
十四、通过物化视图使用联合主键
在原表上创建物化视图:
CREATE MATERIALIZED VIEW mv_hits_URL_UserID
ENGINE = MergeTree()
PRIMARY KEY (URL, UserID)
ORDER BY (URL, UserID, EventTime)
POPULATE
AS SELECT * FROM hits_UserID_URL;
结果:
Ok.
0 rows in set. Elapsed: 2.935 sec. Processed 8.87 million rows, 838.84 MB (3.02 million rows/s., 285.84 MB/s.)
- 我们在视图的主键中切换键列的顺序(与原始表相比)
- 物化视图由一个隐藏表支持,该表的行顺序和主索引基于给定的主键定义
- 我们使用POPULATE关键字,以便用源表hits_UserID_URL中的所有887万行立即导入新的物化视图
- 如果在源表hits_UserID_URL中插入了新行,那么这些行也会自动插入到隐藏表中
- 实际上,隐式创建的隐藏表的行顺序和主索引与我们上面显式创建的辅助表相同:
ClickHouse将隐藏表的列数据文件(.bin)、标记文件(.mrk2)和主索引(primary.idx)存储在ClickHouse服务器的数据目录的一个特殊文件夹中:
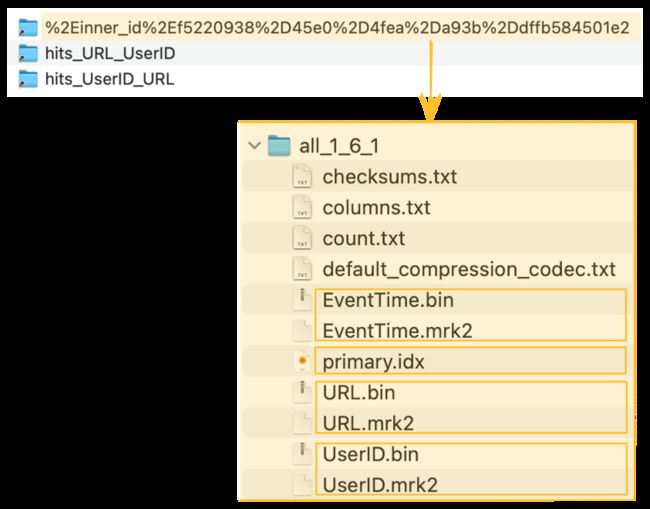
物化视图背后的隐藏表(和它的主索引)现在可以用来显著加快我们在URL列上查询过滤的执行速度:
SELECT UserID, count(UserID) AS Count
FROM mv_hits_URL_UserID
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
结果:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.026 sec.
Processed 335.87 thousand rows,
13.54 MB (12.91 million rows/s., 520.38 MB/s.)
物化视图背后隐藏表(及其主索引)实际上与我们显式创建的辅助表是相同的,所以查询的执行方式与显式创建的表相同。
ClickHouse服务器日志文件中相应的跟踪日志确认了ClickHouse正在对索引标记运行二分搜索:
...Executor): Key condition: (column 0 in ['http://public_search',
'http://public_search'])
...Executor): Running binary search on index range ...
...
...Executor): Selected 4/4 parts by partition key, 4 parts by primary key,
41/1083 marks by primary key, 41 marks to read from 4 ranges
...Executor): Reading approx. 335872 rows with 4 streams
十五、通过projections使用联合主键索引
在原表上创建projection:
ALTER TABLE hits_UserID_URL
ADD PROJECTION prj_url_userid
(
SELECT *
ORDER BY (URL, UserID)
);
物化projection:
ALTER TABLE hits_UserID_URL
MATERIALIZE PROJECTION prj_url_userid;
- 该projection正在创建一个隐藏表,该表的行顺序和主索引基于该projection的给定order BY子句
SHOW TABLES语句查询是不会列出这个隐藏表的- 我们使用
MATERIALIZE关键字,以便立即用源表hits_UserID_URL的所有887万行导入隐藏表 - 如果在源表hits_UserID_URL中插入了新行,那么这些行也会自动插入到隐藏表中
- 查询总是(从语法上)针对源表hits_UserID_URL,但是如果隐藏表的行顺序和主索引允许更有效地执行查询,那么将使用该隐藏表
- 请注意,投影(projections)不会使
ORDER BY查询语句的效率更高,即使ORDER BY匹配上了 projection 的ORDER BY语句(请参阅:https://github.com/ClickHouse/ClickHouse/issues/47333) - 实际上,隐式创建的隐藏表的行顺序和主索引与我们显式创建的辅助表相同:
ClickHouse将隐藏表的列数据文件(.bin)、标记文件(.mrk2)和主索引(primary.idx)存储在一个特殊的文件夹中(在下面的截图中用橙色标记),紧挨着源表的数据文件、标记文件和主索引文件:
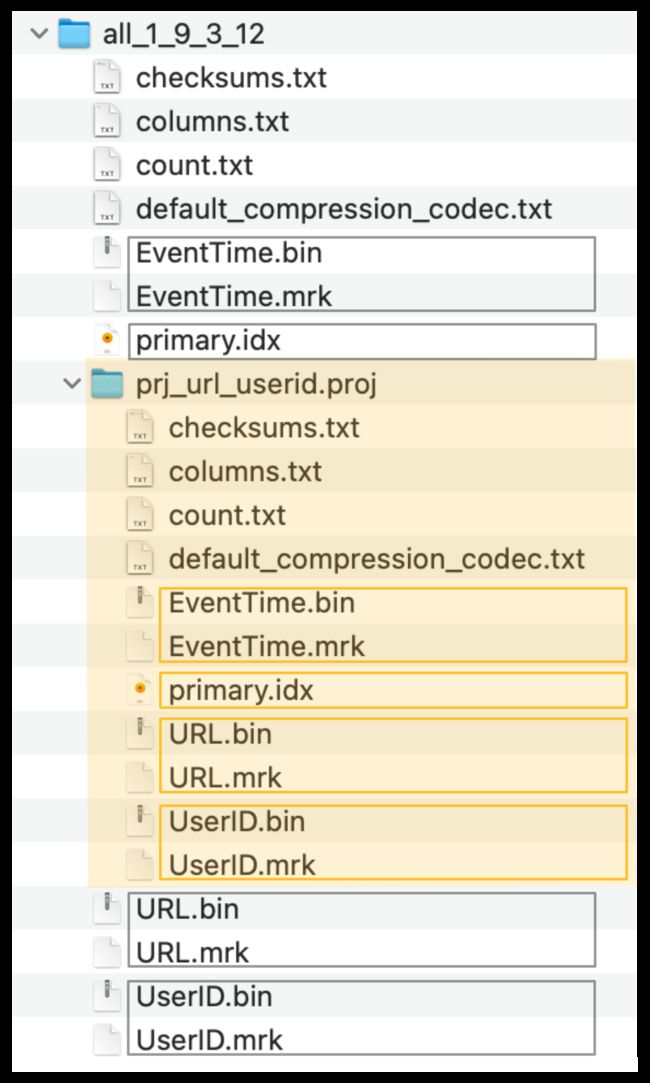
由投影创建的隐藏表(以及它的主索引)现在可以(隐式地)用于显著加快URL列上查询过滤的执行。注意,查询在语法上针对投影的源表。
SELECT UserID, count(UserID) AS Count
FROM hits_UserID_URL
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
结果:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.029 sec.
Processed 319.49 thousand rows, 1
1.38 MB (11.05 million rows/s., 393.58 MB/s.)
因为由投影创建的隐藏表(及其主索引)实际上与我们显式创建的辅助表相同,所以查询的执行方式与显式创建的表相同。
ClickHouse服务器日志文件中跟踪日志确认了ClickHouse正在对索引标记运行二分搜索:
...Executor): Key condition: (column 0 in ['http://public_search',
'http://public_search'])
...Executor): Running binary search on index range for part prj_url_userid (1083 marks)
...Executor): ...
...Executor): Choose complete Normal projection prj_url_userid
...Executor): projection required columns: URL, UserID
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
39/1083 marks by primary key, 39 marks to read from 1 ranges
...Executor): Reading approx. 319488 rows with 2 streams
十六、小结
带有联合主键(UserID, URL)的表的主索引对于加快UserID的查询过滤非常有用。但是,尽管URL列是联合主键的一部分,但该索引在加速URL查询过滤方面并没有提供显著的帮助。
反之亦然:具有复合主键(URL, UserID)的表的主索引加快了URL上的查询过滤,但没有为UserID上的查询过滤提供太多支持。
由于主键列UserID和URL的基数同样很高,过滤第二个键列的查询不会因为第二个键列位于索引中而受益太多。
因此,从主索引中删除第二个键列(从而减少索引的内存消耗)并使用多个主索引是有意义的。
但是,如果复合主键中的键列在基数上有很大的差异,那么查询按基数升序对主键列进行排序是有益的。
主键键列之间的基数差得越大,主键中的列的顺序越重要。我们将在下一章节对此进行演示。
十七、高效地为键列排序
在复合主键中,键列的顺序会对以下两方面产生重大影响:
- 查询中过滤次关键字列的效率,以及
- 表数据文件的压缩率。
为了演示这一点,我们将使用我们的网络流量样本数据集(web traffic sample data set)这个版本, 其中每一行包含三列,分别表示互联网用户(UserID 列)对 URL(URL列)的访问是否被标记为僵尸流量(IsRobot 列)。 我们将使用一个包含上述所有三列的复合主键,该主键可用于加快计算以下内容的典型网络分析查询速度 特定 URL 有多少(百分比)流量来自机器人,或 我们对特定用户是否为僵尸用户有多大把握(来自该用户的流量中有多大比例被认为是(或不是)僵尸流量) 我们使用该查询来计算我们要用作复合主键中三个列的基数(注意,我们使用 URL 表函数 来即席查询 TSV 数据,而无需创建本地表)。在 clickhouse client中运行此查询:
SELECT
formatReadableQuantity(uniq(URL)) AS cardinality_URL,
formatReadableQuantity(uniq(UserID)) AS cardinality_UserID,
formatReadableQuantity(uniq(IsRobot)) AS cardinality_IsRobot
FROM
(
SELECT
c11::UInt64 AS UserID,
c15::String AS URL,
c20::UInt8 AS IsRobot
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != ''
)
响应如下:
┌─cardinality_URL─┬─cardinality_UserID─┬─cardinality_IsRobot─┐
│ 2.39 million │ 119.08 thousand │ 4.00 │
└─────────────────┴────────────────────┴─────────────────────┘
1 row in set. Elapsed: 118.334 sec. Processed 8.87 million rows, 15.88 GB (74.99 thousand rows/s., 134.21 MB/s.)
我们可以看到,各列之间的基数,尤其是 URL 列和 IsRobot 列之间,存在着很大的差异,因此,在复合主键中,这些列的顺序对于有效加快对这些列的查询过滤速度,以及实现表中列数据文件的最佳压缩比都非常重要。
为了证明这一点,我们为僵尸流量分析数据创建了两个版本的表:
- 带有复合主键
(URL、UserID、IsRobot)的表hits_URL_UserID_IsRobot,其中的键列按基数降序排列 - 使用复合主键
(IsRobot, UserID, URL)创建表hits_IsRobot_UserID_URL,其中的键列按基数升序排列
创建具有复合主键(URL、UserID、IsRobot)的表 hits_URL_UserID_IsRobot:
CREATE TABLE hits_URL_UserID_IsRobot
(
`UserID` UInt32,
`URL` String,
`IsRobot` UInt8
)
ENGINE = MergeTree
PRIMARY KEY (URL, UserID, IsRobot);
然后,填充887万行数据:
INSERT INTO hits_URL_UserID_IsRobot SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c20 AS IsRobot
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
响应如下:
0 rows in set. Elapsed: 104.729 sec. Processed 8.87 million rows, 15.88 GB (84.73 thousand rows/s., 151.64 MB/s.)
接下来,创建带有复合主键 (IsRobot,UserID,URL)的表 hits_IsRobot_UserID_URL:
CREATE TABLE hits_IsRobot_UserID_URL
(
`UserID` UInt32,
`URL` String,
`IsRobot` UInt8
)
ENGINE = MergeTree
PRIMARY KEY (IsRobot, UserID, URL);
并在其中填入与上一个表相同的 887 万行数据:
INSERT INTO hits_IsRobot_UserID_URL SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c20 AS IsRobot
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
响应如下:
0 rows in set. Elapsed: 95.959 sec. Processed 8.87 million rows, 15.88 GB (92.48 thousand rows/s., 165.50 MB/s.)
1、在次关键字列上高效过滤
当查询对至少一列进行过滤时,该列是复合关键字的一部分,并且是第一关键字列,那么 ClickHouse 将在关键字列的索引标记上运行二分查找算法。 当查询(仅)过滤属于复合关键字的某一列,但不是第一关键字列时,ClickHouse 将在关键字列的索引标记上使用通用排除搜索算法。 对于第二种情况,复合主键中关键列的排序对通用排除搜索算法的有效性很重要。
这是一个对表中的 UserID 列进行过滤的查询,我们对该表的关键字列(URL、UserID、IsRobot)按基数进行了降序排序:
SELECT count(*)
FROM hits_URL_UserID_IsRobot
WHERE UserID = 112304
响应如下:
┌─count()─┐
│ 73 │
└─────────┘
1 row in set. Elapsed: 0.026 sec.
Processed 7.92 million rows,
31.67 MB (306.90 million rows/s., 1.23 GB/s.)
对关键字列(IsRobot, UserID, URL)按基数升序排列的表,进行相同的查询:
SELECT count(*)
FROM hits_IsRobot_UserID_URL
WHERE UserID = 112304
响应如下:
┌─count()─┐
│ 73 │
└─────────┘
1 row in set. Elapsed: 0.003 sec.
Processed 20.32 thousand rows,
81.28 KB (6.61 million rows/s., 26.44 MB/s.)
2、数据文件的最佳压缩率
此查询将比较上面创建的两个表中 UserID 列的压缩率:
SELECT
table AS Table,
name AS Column,
formatReadableSize(data_uncompressed_bytes) AS Uncompressed,
formatReadableSize(data_compressed_bytes) AS Compressed,
round(data_uncompressed_bytes / data_compressed_bytes, 0) AS Ratio
FROM system.columns
WHERE (table = 'hits_URL_UserID_IsRobot' OR table = 'hits_IsRobot_UserID_URL') AND (name = 'UserID')
ORDER BY Ratio ASC
这是响应:
┌─Table───────────────────┬─Column─┬─Uncompressed─┬─Compressed─┬─Ratio─┐
│ hits_URL_UserID_IsRobot │ UserID │ 33.83 MiB │ 11.24 MiB │ 3 │
│ hits_IsRobot_UserID_URL │ UserID │ 33.83 MiB │ 877.47 KiB │ 39 │
└─────────────────────────┴────────┴──────────────┴────────────┴───────┘
2 rows in set. Elapsed: 0.006 sec.
我们可以看到,在按关键字列(IsRobot、UserID、URL) 按基数升序排列的表中,UserID 列的压缩率明显更高。
虽然两个表中存储的数据完全相同(我们在两个表中插入了相同的 887 万行),但复合主键中关键字列的顺序对表的 列数据文件中的 压缩数据所需的磁盘空间有很大影响:
- 在具有复合主键
(URL, UserID, IsRobot)的表hits_URL_UserID_IsRobot中,我们按照键列的基数降序排列,此时UserID.bin数据文件占用11.24MB的磁盘空间。 - 在具有复合主键
(IsRobot, UserID, URL)的表hits_IsRobot_UserID_URL中,我们按照键列的基数升序排列,UserID.bin数据文件仅占用877.47 KiB的磁盘空间。
对磁盘上表的列数据进行良好的压缩比不仅能节省磁盘空间,还能使需要从该列读取数据的查询(尤其是分析查询)更快,因为将列数据从磁盘移动到主内存(操作系统的文件缓存)所需的 i/o 更少。
下面我们将说明,为什么主键列按基数升序排列有利于提高表列的压缩率。
下图阐述了主键的磁盘上行顺序,其中键列是按基数升序排列的:
我们讨论过 表的行数据按主键列有序存储在磁盘上。
在上图中,表格的行(它们在磁盘上的列值)首先按其 cl 值排序,具有相同 cl 值的行按其 ch 值排序。由于第一键列 cl 的基数较低,因此很可能存在具有相同 cl 值的行。因此,ch值也很可能是有序的(局部地--对于具有相同cl值的行而言)。
如果在一列中,相似的数据被放在彼此相近的位置,例如通过排序,那么这些数据将得到更好的压缩。 一般来说,压缩算法会受益于数据的运行长度(可见的数据越多,压缩效果越好)和局部性(数据越相似,压缩率越高)。
与上图不同的是,下图阐述了主键的磁盘上行顺序,其中主键列是按基数降序排列的:
现在,表格的行首先按其 ch 值排序,具有相同 ch 值的行按其 cl 值排序。 但是,由于第一键列 ch 的基数很高,因此不太可能存在具有相同 ch 值的行。因此,cl值也不太可能是有序的(局部地--对于具有相同ch值的行而言)。
因此,cl值很可能是随机排序的,因此局部性和压缩比都很差。
小结
为了在查询中有效地过滤次关键字列和提高表列数据文件的压缩率,按基数升序排列主键中的列是有益的。