Linux&MySql
结构化查询语言
DDL(数据定义语言)
删除数据库drop database DbName;
创建数据库create database DbName;
使用数据库use DbName;
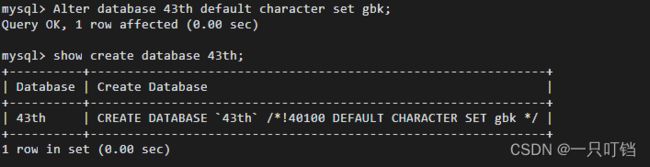
查看创建数据库语句以及字符编码show create database 43th;

修改数据库属性(字符编码改为gbk)alter database DbName default character set gbk;
字符校对集
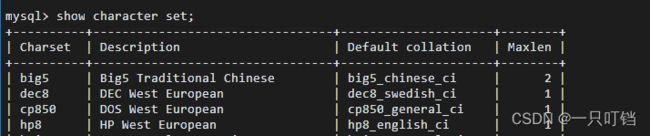
查看数据库支持的字符集show character set;
查看相应字符集的校对规则show collation;

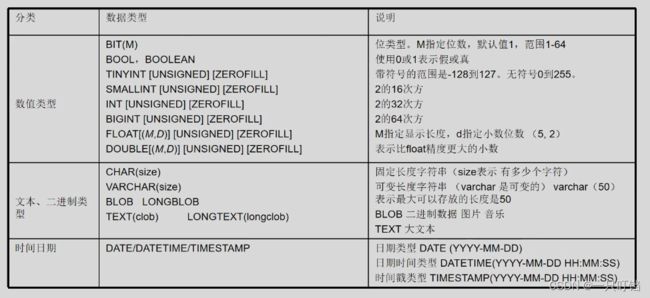
数据类型
TIMESTAMP在进行insert/updata自动记录
创建表结构
create table tName(
field1 datatype,
field2 datatype,
...
);
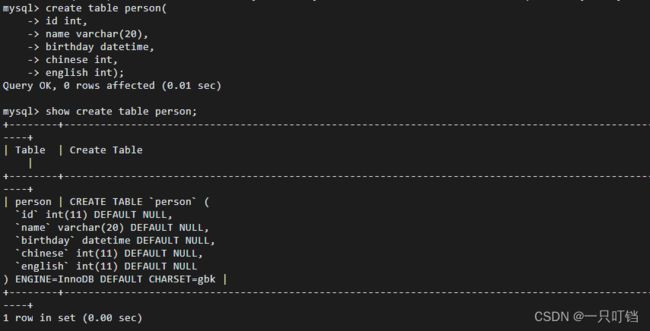
查看表结构desc tName; show create table person;
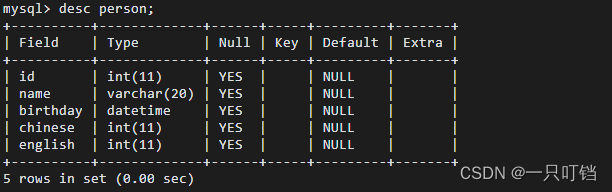
修改表结构
添加列(字段)alter table tName add field datatype;
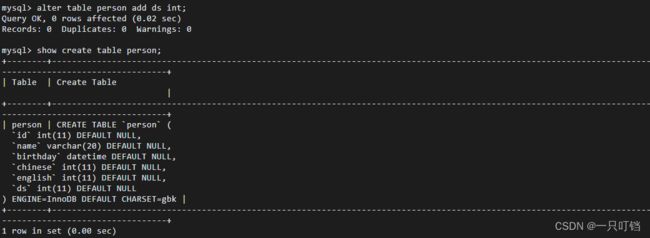
对字段名进行修改alter table tName change field1 field2datatype;

对字段名的类型进行修改alter table tName modify field datatype;
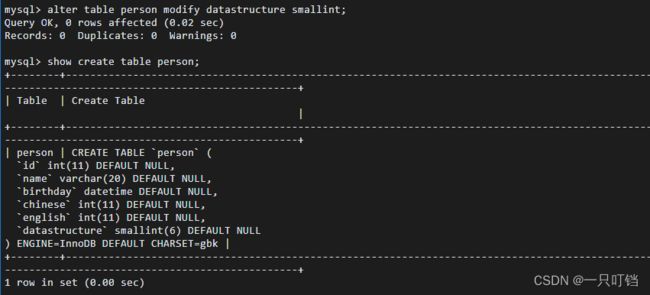
删除一个字段alter yable tName drop field;
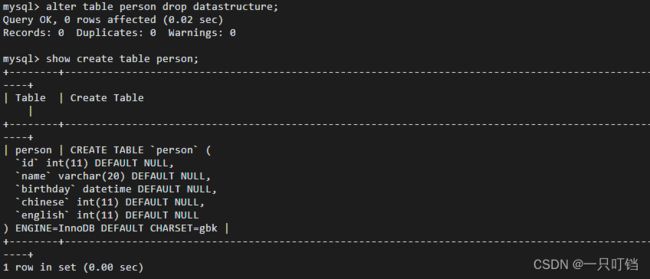
删除表结构drop table tName;
查看数据库中有多少表show tables;

DML(数据控制语言)
在表中对指定的列插入数据insert into tName(field1,field2...) values (field1Vale,field2Vale...);
对所有列都进行数据添加insert into tName values(field1Vale,field2Vale....);
对所有列添加多行数据insert into tName(field1,field2...) values(field1vale,field2vale....),(field1Vale,field2Vale....),...;效率高于每次insert一条语句

修改某一条数据进行修改update tName set field1=XXX[where..];
带where作用于某一行,不带where作用于所有行
添加新的列alter table tName add coluName coluType;

复制表
复制表结构不复制数据create table newTName like oldTName;
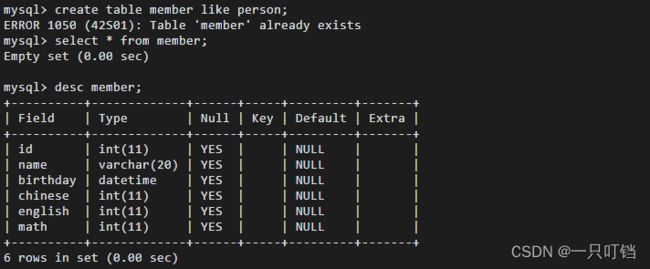
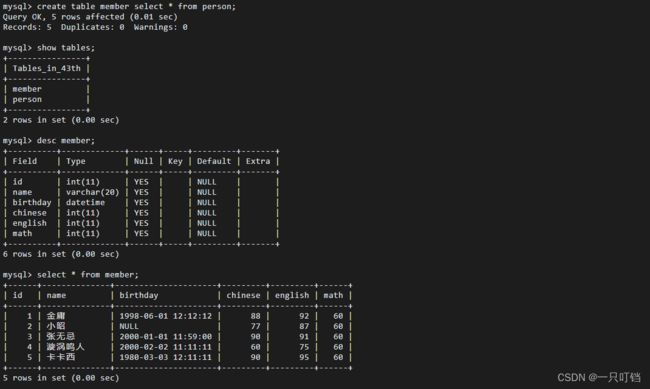
复制表结构和数据create table newTName select * from oldTName;
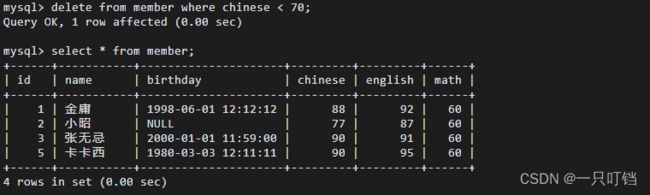
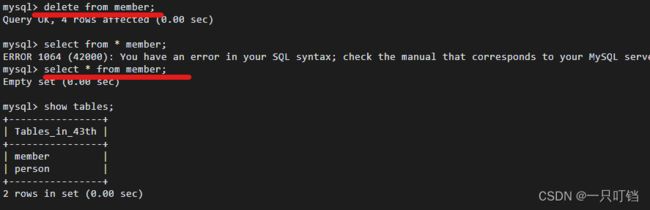
删除表中数据不删除表结构delete from tName[whilecondition];
DQL(数据查询语言)
查询命令select[*]|{field1,field2...}while tName [where condition];
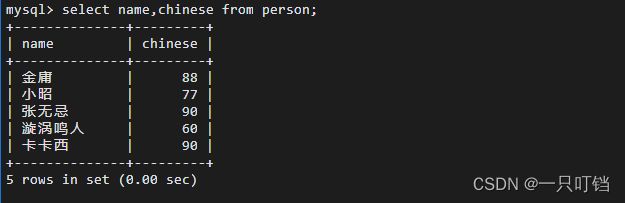
去除重复列,使用distinct关键字,当distinct作用于单个字段时,去除重复的列即可,当distinct作用于多个字段时,必须要所有字段相同才可以消除
distinct必须放在第一个关键字之前,不然会报错
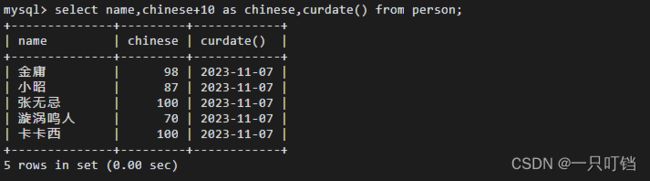
select语句选择的列可以进行运算
使用as还可以对列区别名

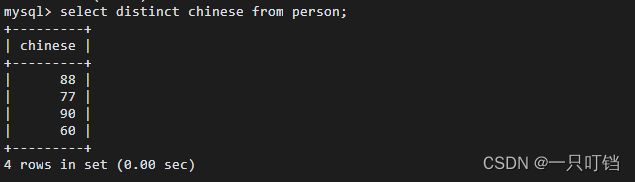
获取当前使用数据库 select database();
获取当前时间,使用curdate()函数
选择查询select id,name,chinese from person where chinese between 10 and 90;
枚举查询select id,name,chinese from person where chinese in(88,77,90,60);
模糊查询like
通配符_:下划线代表一个任意字符select * from person where name like '-i';
通配符%:百分号代表多个字符slelect * from person name like 'z%';
对查询的结果集进行排序默认采用升序ASC方式排序,DESC为降序select [*] from tName orger by culName;
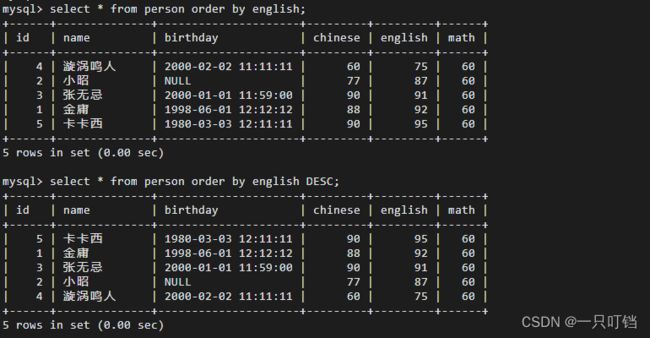
分页查询(常考点)
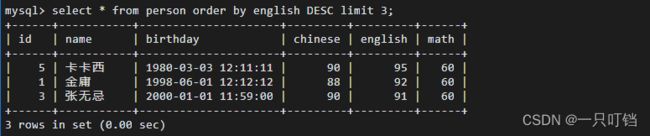
(1)第一种写法limit
只是查看前三名的字段select * from person order by english desc limit 3;
每页三个数据,查看第二页的数据select * from person order by english desc limit 3,3;

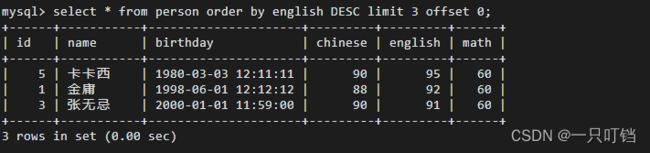
(2)第二种写法limit m offset n n表示的是偏移记录条数,m表示要显示的数据条数
只是查看前三名的字段select * from person order by english desc limit 3 offset 0;
每页三个数据,查看第二页的数据select * from person order by english desc limit 3offset 3;

数据完整性:
(1)实体完整性:表中的每一行数据都是唯一的,不能重复出现,通过主键(PRIMARYKEY)来实现。
(2)域(field 字段,列)完整性:每一行必须要符合某种特定的数据类型或约束,
非空约束 NOT NULL 该字段不能为空
唯一约束 UNIQUE 该字段不允许重复,允许为空
获取唯一约束的名字show create table student;
删除一个唯一约束 alter table tName drop index name ;
(3)参照完整性:外键约束 FOREIGNN KEY,外键 是另一张表的主键
表已经存在的情况下,需要使用alter table tName add constraint fk_1 fGPRRIGNN KEY(s_id) REFERENCES student(id);
数据库的备份和恢复
数据库的备份在终端下使用命令mysqldump -u root -p 43th>43th.sql

恢复数据库在终端下使用命令mysql -u root -p 43th<43th.sql
或者在mysql>中使用source 43th.sql;相当于在当前的空数据库下执行43th.sql中的sql语句导入数据
因为我们备份的数据库文件中不存在创建数据库的语句,因此我们导入数据库之前因该先创建数据库在进行数据数据的导入
联合主键
对某一张表,一条的记录的唯一性由两个或者以上的字段共同决定。
如果是由两个字段决定的,只要其中一个之一不相同,就是一条不同的记录。只有当两个字段都相同时,该记录不能插入到表中
DQL复杂查询
连接查询
针对多张表
交叉连接(笛卡尔积)[三种写法操作结果一致]
select * from letfTable cross join rightTable;
selsct * from leftTable join rightTable;
select * from leftTable,rightTable;
内连接
关键字inner join(一般都会加上on选择条件)
select * from leftTable inner join rightTable on leftTable.id=rightTable.id;
select * from leftTable inner join rightTable on leftTable.id=rightTable.id where leftTable.id>3;
外连接
执行左右外连接需要使用on关键字加入选择条件,如果使用左外连接是,当右表中没有与左表中对应的记录时,查询出的右表数据全部用NULL代替,左表中的所有数据都出现;对于右外连接也是一样的
左外连接letf outer join
select * from leftTable letfr outer join rightTable on leftTable.id=rightTable;
右外连接right outer join
select * from leftTable letfr outer join rightTable on leftTable.id=rightTable;

子查询
子查询也叫嵌套查询,是指在where子句或from子句中又嵌入select查询语句(一般写在where子句)
select * from person where id = (select id from person where id < 4);
select * from (select id,name,chinese from person where name like ‘k%’) as t;
联合查询
联合查询能够合并两条查询语句的查询结果,去掉其中重复数据行,然后返回没有重复数据行的查询结果。联合查询使用union关键字
select * from person where chinese > 80 union select * from person where english > 80;
报表查询
统计函数
cout()计数
sum()求和
avg()求平均值
max()最大值
min()最小值

select count(*) ,chinsesfrom person group by chinese;//对chinese中数值相同的进行统计,打印出相同不同数据的相同数量

select count(*) ,chinsesfrom person group by chinese having chinses >80;//进行分组之后还要对数据进行过滤使用having子句,where是在没有分组之前进行过滤,having是在分组之后进行过滤
