http://blog.csdn.net/popy007/article/details/1797121
说明:
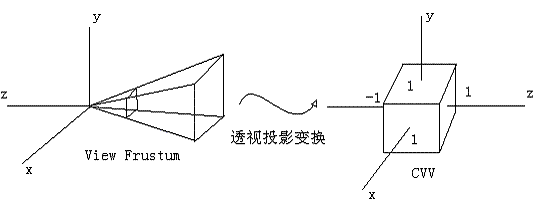
1 从透视坐标系和ndc的图来看是opengl的描述(注意下ndc坐标系是左手系,z轴和opengl的右手系是反的)
2 关于-(az+b)/z的理解

因为是从透视坐标系到近景面的投射,近景面的z是固定的,那么投射后所有点的z值都是近景面的z值,所以第三个参数z就没意义了
那么这里为什么用 -(az+b)z来填充呢
原因是透视投影变换的目的并不是向近景面投射,而是向CVV投射,opengl中cvv xyz范围都是-1~1
首先看下如果是纯粹向近景面投射,而不是CVV,那么4*4变换矩阵应该为
注意近景面的z,w,h会受长宽比影响,而cvv xyz范围都是-1~1(dx的z是0~1),所以这个计算出的映射xyz和最终到cvv的映射的xyz都存在一个线性映射关系
-(az+b)z就是用来处理z的映射关系的
接下来要做的是
1 建立透视投影坐标系中z值和投影后cvv的z值之间的关系,
2然后再构建出相应的矩阵,达到通过一个4*4齐次矩阵就把透视投影坐标系中的视景体,转换到ndc坐标系的cvv的目的(实际这个矩阵还是求出一个w,真正的转换还要除w才能完成)
对于1来说就是左图z和右图z的对应关系
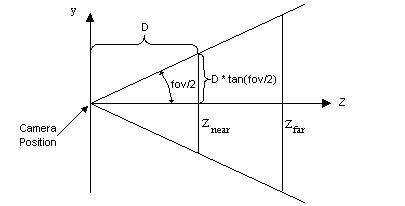

z右 = z左 * a +b(直线斜截式),作用就是将Znear到Zfar的z值,转换到cvv -1~1的z值,z右和z左是线性关系
对于2 构建矩阵,从投影到平面(近景面,xy长宽比1:1的情况下)的矩阵扩展一下,xy已经处理过了,主要扩展对z转换的处理
对于x,y到cvv的映射类似z,也需要对矩阵进行修改
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
深入探索透视投影变换
最近更新:2013年11月22日
-Twinsen编写
-本人水平有限,疏忽错误在所难免,还请各位数学高手、编程高手不吝赐教
-email: [email protected]
透视投影是3D固定流水线的重要组成部分,是将相机空间中的点从视锥体(frustum)变换到规则观察体(Canonical View Volume)中,待裁剪完毕后进行透视除法的行为。在算法中它是通过透视矩阵乘法和透视除法两步完成的。
透视投影变换是令很多刚刚进入3D图形领域的开发人员感到迷惑乃至神秘的一个图形技术。其中的理解困难在于步骤繁琐,对一些基础知识过分依赖,一旦对它们中的任何地方感到陌生,立刻导致理解停止不前。
没错,主流的3D APIs如OpenGL、D3D的确把具体的透视投影细节封装起来,比如
gluPerspective(…)就可以根据输入生成一个透视投影矩阵。而且在大多数情况下不需要了解具体的内幕算法也可以完成任务。但是你不觉得,如果想要成为一个职业的图形程序员或游戏开发者,就应该真正降伏透视投影这个家伙么?我们先从必需的基础知识着手,一步一步深入下去(这些知识在很多地方可以单独找到,但我从来没有在同一个地方全部找到,但是你现在找到了J)。
我们首先介绍两个必须掌握的知识。有了它们,我们才不至于在理解透视投影变换的过程中迷失方向(这里会使用到向量几何、矩阵的部分知识,如果你对此不是很熟悉,可以参考《向量几何在游戏编程中的使用》系列文章)。
齐次坐标表示
透视投影变换是在齐次坐标下进行的,而齐次坐标本身就是一个令人迷惑的概念,这里我们先把它理解清楚。
根据《向量几何在游戏编程中的使用6》中关于基的概念。对于一个向量v以及基oabc,

可以找到一组坐标(v1,v2,v3),使得
v = v1 a + v2 b + v3 c (1)
而对于一个点p,则可以找到一组坐标(p1,p2,p3),使得
p – o = p1 a + p2 b + p3 c (2)
从上面对向量和点的表达,我们可以看出为了在坐标系中表示一个点(如p),我们把点的位置看作是对这个基的原点o所进行的一个位移,即一个向量——p – o(有的书中把这样的向量叫做位置向量——起始于坐标原点的特殊向量),我们在表达这个向量的同时用等价的方式表达出了点p:
p = o + p1 a + p2 b + p3 c (3)
(1)(3)是坐标系下表达一个向量和点的不同表达方式。这里可以看出,虽然都是用代数分量的形式表达向量和点,但表达一个点比一个向量需要额外的信息。如果我写出一个代数分量表达(1, 4, 7),谁知道它是个向量还是个点!
我们现在把(1)(3)写成矩阵的形式:
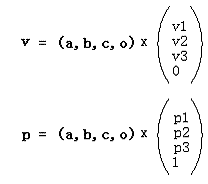
这里(a,b,c,o)是坐标基矩阵,右边的列向量分别是向量v和点p在基下的坐标。这样,向量和点在同一个基下就有了不同的表达:3D向量的第4个代数分量是0,而3D点的第4个代数分量是1。像这种这种用4个代数分量表示3D几何概念的方式是一种齐次坐标表示。
“齐次坐标表示是计算机图形学的重要手段之一,它既能够用来明确区分向量和点,同时也更易用于进行仿射(线性)几何变换。”—— F.S. Hill, JR
这样,上面的(1, 4, 7)如果写成(1,4,7,0),它就是个向量;如果是(1,4,7,1),它就是个点。
下面是如何在普通坐标(Ordinary Coordinate)和齐次坐标(Homogeneous Coordinate)之间进行转换:
从普通坐标转换成齐次坐标时,
如果(x,y,z)是个点,则变为(x,y,z,1);
如果(x,y,z)是个向量,则变为(x,y,z,0)
从齐次坐标转换成普通坐标时,
如果是(x,y,z,1),则知道它是个点,变成(x,y,z);
如果是(x,y,z,0),则知道它是个向量,仍然变成(x,y,z)
以上是通过齐次坐标来区分向量和点的方式。从中可以思考得知,对于平移T、旋转R、缩放S这3个最常见的仿射变换,平移变换只对于点才有意义,因为普通向量没有位置概念,只有大小和方向,这可以通过下面的式子清楚地看出:
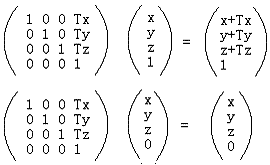
而旋转和缩放对于向量和点都有意义,你可以用类似上面齐次表示来检测。从中可以看出,齐次坐标用于仿射变换非常方便。
此外,对于一个普通坐标的点P=(Px, Py, Pz),有对应的一族齐次坐标(wPx, wPy, wPz, w),其中w不等于零。比如,P(1, 4, 7)的齐次坐标有(1, 4, 7, 1)、(2, 8, 14, 2)、(-0.1, -0.4, -0.7, -0.1)等等。因此,如果把一个点从普通坐标变成齐次坐标,给x,y,z乘上同一个非零数w,然后增加第4个分量w;如果把一个齐次坐标转换成普通坐标,把前三个坐标同时除以第4个坐标,然后去掉第4个分量。
由于齐次坐标使用了4个分量来表达3D概念,使得平移变换可以使用矩阵进行,从而如F.S. Hill, JR所说,仿射(线性)变换的进行更加方便。由于图形硬件已经普遍地支持齐次坐标与矩阵乘法,因此更加促进了齐次坐标使用,使得它似乎成为图形学中的一个标准。
简单的线性插值
这是在图形学中普遍使用的基本技巧,我们在很多地方都会用到,比如2D位图的放大、缩小,Tweening变换,以及我们即将看到的透视投影变换等等。基本思想是:给一个x属于[a, b],找到y属于[c, d],使得x与a的距离比上ab长度所得到的比例,等于y与c的距离比上cd长度所得到的比例,用数学表达式描述很容易理解:
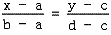
这样,从a到b的每一个点都与c到d上的唯一一个点对应。有一个x,就可以求得一个y。
此外,如果x不在[a, b]内,比如x < a或者x > b,则得到的y也是符合y < c或者y > d,比例仍然不变,插值同样适用。
透视投影变换
好,有了上面两个理论知识,我们开始分析这次的主角——透视投影变换。这里我们选择OpenGL的透视投影变换进行分析,其他的APIs会存在一些差异,但主体思想是相似的,可以类似地推导。经过相机矩阵的变换,顶点被变换到了相机空间。这个时候的多边形也许会被视锥体裁剪,但在这个不规则的体中进行裁剪并非那么容易的事情,所以经过图形学前辈们的精心分析,裁剪被安排到规则观察体(Canonical View Volume, CVV)中进行,CVV是一个正方体,x, y, z的范围都是[-1,1],多边形裁剪就是用这个规则体完成的。所以,事实上是透视投影变换由两步组成:
1) 用透视变换矩阵把顶点从视锥体中变换到裁剪空间的CVV中。
2) CVV裁剪完成后进行透视除法(一会进行解释)。
我们一步一步来,我们先从一个方向考察投影关系。

上图是右手坐标系中顶点在相机空间中的情形。设P(x,z)是经过相机变换之后的点,视锥体由eye——眼睛位置,np——近裁剪平面,fp——远裁剪平面组成。N是眼睛到近裁剪平面的距离,F是眼睛到远裁剪平面的距离。投影面可以选择任何平行于近裁剪平面的平面,这里我们选择近裁剪平面作为投影平面。设P’(x’,z’)是投影之后的点,则有z’ = -N。通过相似三角形性质,我们有关系:
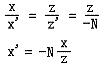
同理,有

这样,我们便得到了P投影后的点P’

从上面可以看出,投影的结果z’始终等于-N,在投影面上。实际上,z’对于投影后的P’已经没有意义了,这个信息点已经没用了。但对于3D图形管线来说,为了便于进行后面的片元操作,例如z缓冲消隐算法,有必要把投影之前的z保存下来,方便后面使用。因此,我们利用这个没用的信息点存储z,处理成:

这个形式最大化地使用了3个信息点,达到了最原始的投影变换的目的,但是它太直白了,有一点蛮干的意味,我感觉我们最终的结果不应该是它,你说呢?我们开始结合CVV进行思考,把它写得在数学上更优雅一致,更易于程序处理。假入能够把上面写成这个形式:
那么我们就可以非常方便的用矩阵以及齐次坐标理论来表达投影变换:
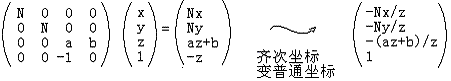
其中

哈,看到了齐次坐标的使用,这对于你来说已经不陌生了吧?这个新的形式不仅达到了上面原始投影变换的目的,而且使用了齐次坐标理论,使得处理更加规范化。注意在把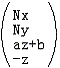 变成
变成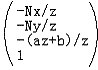 的一步我们是使用齐次坐标变普通坐标的规则完成的。这一步在透视投影过程中称为透视除法(Perspective Division),这是透视投影变换的第2步,经过这一步,就丢弃了原始的z值(得到了CVV中对应的z值,后面解释),顶点才算完成了投影。而在这两步之间的就是CVV裁剪过程,所以裁剪空间使用的是齐次坐标
的一步我们是使用齐次坐标变普通坐标的规则完成的。这一步在透视投影过程中称为透视除法(Perspective Division),这是透视投影变换的第2步,经过这一步,就丢弃了原始的z值(得到了CVV中对应的z值,后面解释),顶点才算完成了投影。而在这两步之间的就是CVV裁剪过程,所以裁剪空间使用的是齐次坐标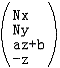 ,主要原因在于透视除法会损失一些必要的信息(如原始z,第4个-z保留的)从而使裁剪变得更加难以处理,这里我们不讨论CVV裁剪的细节,只关注透视投影变换的两步。
,主要原因在于透视除法会损失一些必要的信息(如原始z,第4个-z保留的)从而使裁剪变得更加难以处理,这里我们不讨论CVV裁剪的细节,只关注透视投影变换的两步。
矩阵
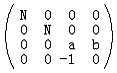
就是我们投影矩阵的第一个版本。你一定会问为什么要把z写成

有三个原因:
0)后面投影之后的光栅化阶段,要通过x'和y'对z进行线性插值,以求出三角形内部片元的z,进行z缓冲深度测试。在数学上,投影后的x'和y',与z不是线性关系,与1/z才是线性关系。而正是1/z的线性关系,即-a+b/z。用这个1/z的线性组合值和x'、y'进行插值才是正确的。(2013年11月补充条目。对此感到迷惑的读者可以参考《深入探索透视纹理映射》,里面从细节上说明了这个问题。)
1) P’的3个代数分量统一地除以分母-z,易于使用齐次坐标变为普通坐标来完成,使得处理更加一致、高效。
2) 后面的CVV是一个x,y,z的范围都为[-1,1]的规则体,便于进行多边形裁剪。而我们可以适当的选择系数a和b,使得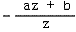 这个式子在z = -N的时候值为-1,而在z = -F的时候值为1,从而在z方向上构建CVV。
这个式子在z = -N的时候值为-1,而在z = -F的时候值为1,从而在z方向上构建CVV。
接下来我们就求出a和b:
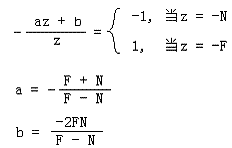
这样我们就得到了透视投影矩阵的第一个版本:
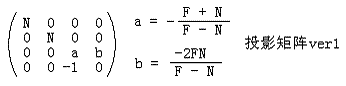
使用这个版本的透视投影矩阵可以从z方向上构建CVV,但是x和y方向仍然没有限制在[-1,1]中,我们的透视投影矩阵的下一个版本就要解决这个问题。
为了能在x和y方向把顶点从Frustum情形变成CVV情形,我们开始对x和y进行处理。先来观察我们目前得到的最终变换结果:
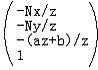
我们知道-Nx / z的有效范围是投影平面的左边界值(记为left)和右边界值(记为right),即[left, right],-Ny / z则为[bottom, top]。而现在我们想把-Nx / z属于[left, right]映射到x属于[-1, 1]中,-Ny / z属于[bottom, top]映射到y属于[-1, 1]中。你想到了什么?哈,就是我们简单的线性插值,你都已经掌握了!我们解决掉它:

则我们得到了最终的投影点:
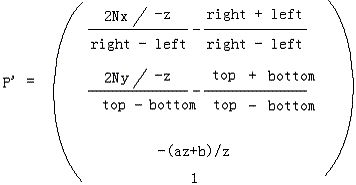
下面要做的就是从这个新形式出发反推出下一个版本的透视投影矩阵。注意到 是
是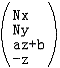 经过透视除法的形式,而P’只变化了x和y分量的形式,az+b和-z是不变的,则我们做透视除法的逆处理——给P’每个分量乘上-z,得到
经过透视除法的形式,而P’只变化了x和y分量的形式,az+b和-z是不变的,则我们做透视除法的逆处理——给P’每个分量乘上-z,得到
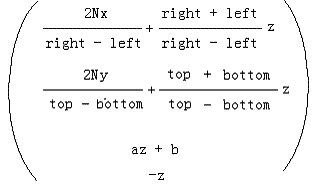
而这个结果又是这么来的:
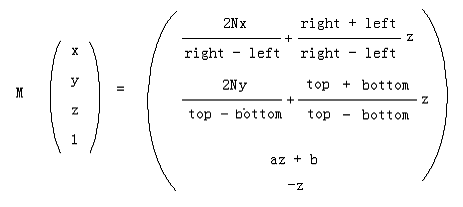
则我们最终得到:
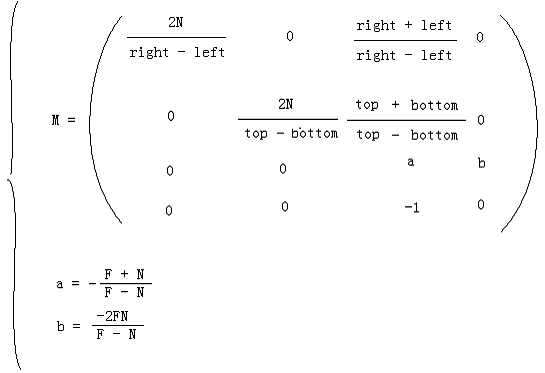
M就是最终的透视变换矩阵。相机空间中的顶点,如果在视锥体中,则变换后就在CVV中。如果在视锥体外,变换后就在CVV外。而CVV本身的规则性对于多边形的裁剪很有利。OpenGL在构建透视投影矩阵的时候就使用了M的形式。注意到M的最后一行不是(0 0 0 1)而是(0 0 -1 0),因此可以看出透视变换不是一种仿射变换,它是非线性的。另外一点你可能已经想到,对于投影面来说,它的宽和高大多数情况下不同,即宽高比不为1,比如640/480。而CVV的宽高是相同的,即宽高比永远是1。这就造成了多边形的失真现象,比如一个投影面上的正方形在CVV的面上可能变成了一个长方形。解决这个问题的方法就是在对多变形进行透视变换、裁剪、透视除法之后,在归一化的设备坐标(Normalized Device Coordinates)上进行的视口(viewport)变换中进行校正,它会把归一化的顶点之间按照和投影面上相同的比例变换到视口中,从而解除透视投影变换带来的失真现象。进行校正前提就是要使投影平面的宽高比和视口的宽高比相同。
便利的投影矩阵生成函数
3D APIs都提供了诸如gluPerspective(fov, aspect, near, far)或者D3DXMatrixPerspectiveFovLH(pOut, fovY, Aspect, zn, zf)这样的函数为用户提供快捷的透视矩阵生成方法。我们还是用OpenGL的相应方法来分析它是如何运作的。
gluPerspective(fov, aspect, near, far)
fov即视野,是视锥体在xz平面或者yz平面的开角角度,具体哪个平面都可以。OpenGL和D3D都使用yz平面。
aspect即投影平面的宽高比。
near是近裁剪平面的距离
far是远裁剪平面的距离。

上图中左边是在xz平面计算视锥体,右边是在yz平面计算视锥体。可以看到左边的第3步top = right / aspect使用了除法(图形程序员讨厌的东西),而右边第3步right = top x aspect使用了乘法,这也许就是为什么图形APIs采用yz平面的原因吧!
到目前为止已经完成了对透视投影变换的阐述,我想如果你一直跟着我的思路下来,应该能够对透视投影变换有一个细节层次上的认识。当然,很有可能你已经是一个透视投影变换专家,如果是这样的话,一定给我写信,指出我认识上的不足,我会非常感激J。Bye!