LeetCode题
文章目录
- 单词分析
- 成绩统计
- 求和
- 九进制转十进制
- 顺子日期
- 青蛙过河
- 1342.将数字变成0的操作次数
- 383.赎金信
- 1615.最大网络轶
- 2373.矩阵中的局部最大值
- 1625.执行操作后字典序最小的字符串
- 704.二分查找
- 面试题 05.02. 二进制数转字符串
- 2. 两数相加
- 283.移动零
- 167.两数之和 II - 输入有序数组
- 1626. 无矛盾的最佳球队
- 567.字符串的排列
- 1574.删除最短的子数组使剩余数组有序
- 733.图像渲染
- 695.岛屿的最大面积
- 1638. 统计只差一个字符的子串数目
- 77.组合
- 784.字母大小写全排列
- 231.2的幂
- 191.位1的个数
- 190. 颠倒二进制位
- 136. 只出现一次的数字
- 70. 爬楼梯
- 120. 三角形最小路径和
- 198.打家劫舍
单词分析
输入:单词
输出:出现次数最多的单词以及其出现次数,当次数相同时取字典序列小的
#eg.1
a = input()
b = [0]*256
for i in a:
b[ord(i)]=b[ord(i)]+1a = input()
print(chr(b.index(max(b))))
print((max(b)))
#eg.2
dic = {}
for item in a:
if dic.get(item) == None:
dic[item] = 1 #item作为key
else:
dic[item] += 1
max_num = 0
max_word = ''
for item in a:
if max_num < dic[item]:
max_num = dic[item]
max_word = item
elif max_num == dic[item]:
if ord(max_word) > ord(item):
max_num = dic[item]
max_word = item
print(max_word)
print(max_num)
成绩统计
输入:人数,分数
输出:及格率(>=60),优秀率(>=85)
#eg.1
num = int(input())
cj_list = [int(input()) for i in range(num)]
def f(x):
return round(len([i for i in cj_list if i>=x])/num*100)
print(f'{f(60)}%')
print(f'{f(85)}%')
#eg.2
num = int(input())
cj_list = []
for i in range(num):
cj_list.append(int(input()))
jige = 0
youxiu = 0
for c in cj_list:
if c >= 60: jige+=1
if c >= 85: youxiu+=1
print(f'{round(jige/num*100)}%')
print(f'{round(youxiu/num*100)}%')
求和
输入:长度n,a_1 a_2 … a_n
输出:相乘和
import os
import sys
'''
暴力解法会超时O(n^2),因此拆分公式
S = a1*a2+a1*a3+a1*a4+a2*a3+a2*a4+a3*a4
= a2*a1+a3*(a2+a1)+a4*(a3+a2+a1)
即:
S = a_i+1 * (a + a_i)
a = a + a_i
'''
n = int(input())
a_list = list(map(int,input().split()))
a_sum = 0
aa = 0
if n == 1:
a_sum = a_list[0]
else:
for i in range(n-1):
aa += a_list[i]
a_sum += a_list[i+1] * aa
print(a_sum)
九进制转十进制
import os
import sys
n = [2,0,2,2]
n_9 = 0
for i in range(len(n)):
n_9 += pow(9, i) * n[len(n) - i - 1]
print(n_9)
import os
import sys
print(int('2022', 9))
#class int(x,base = 10)
#--字符串或者数字
#base-进制数,默认十进制
顺子日期
import os
import sys
import datetime
begin = datetime.date(2022, 1, 1) #开始日期
end = datetime.date(2022, 12, 31) #结束日期
day = datetime.timedelta(days=1)
def judge(x):
x = str(x).replace('-', '')
for i in ['012', '123', '234', '345', '456', '567', '678', '789']:
if i in x:
return True
return False
count = 0
while begin <= end:
if judge(begin):
count += 1
# 加一天
begin += day
print(count)
青蛙过河
输入:河宽n,趟数x,石高H_1 H_2 … H_(n-1)
输出:最小跳跃能力y
import os
import sys
'''
当跳跃能力为y时,从第 i 块石头跳到第 i+y+1 块石头, 最多可以跳 H_i+1 + H_i+2 + ... + H_i+y 趟
例如:
y = 3
n = y + 1
H = [2, 3, 5]
从第0块跳到第4块,即起点到终点
x_max = 2+3+5 = 10
若此时y=2,n不变,H不变
从0到3,最多2+3=5下
从1到4,最多3+5=8下
从0到4则取最短板,即x_max=5下
以此类推,求出不同y下的x_max值,找到满足x_max>=2x的y最小值即可(可用二分法)
'''
a = list(map(int,input().split()))
stone_high = list(map(int,input().split()))
n = a[0]
x_2 = a[1] * 2
high_sum = [0] * n
for i in range(n-1):
high_sum[i+1] = high_sum[i] + stone_high[i]
# 获取跳跃能力为y时的最大可过河的趟数
def get_x_max(high_sum_list, test_y):
min_x = sys.maxsize
for i in range(test_y, n):
min_x = min(min_x, high_sum_list[i]-high_sum_list[i-y])
return min_x
# 二分法去找最小y值
y_l = 0
y_r = n
while y_l < y_r - 1: # 区间[n, n+1]时停止循环
y = int((y_r - y_l) / 2) + y_l #int为向0取整
if get_x_max(high_sum, y) >= x_2:
y_r = y
else:
y_l = y
y = y_r #由于进入区间[n, n+1]时会停止循环,且由于向0取整,此时若循环结束y=y_l,y_l并不满足条件,因此需令y=y_r
print(y)
1342.将数字变成0的操作次数
给你一个非负整数 num ,请你返回将它变成 0 所需要的步数。 如果当前数字是偶数,你需要把它除以 2 ;否则,减去 1 。
class Solution(object):
def numberOfSteps(self, num):
"""
:type num: int
:rtype: int
"""
# count = 0
# while num:
# if num == 0:
# return count
# if num % 2 ==0:
# num /= 2
# count += 1
# else:
# num -= 1
# count += 1
'''
bin(num).count('1') bin()函数得到num的2进制数 .count('1')得到2进制数中1的个数
num.bit_length() 得到num 2进制数的长度
'''
return max(0, bin(num).count('1') + num.bit_length() - 1)
383.赎金信
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
class Solution(object):
def canConstruct(self, ransomNote, magazine):
'''
该题意思即magazine中各字母的出现次数肯定比ransomNote中各字母的出现次数大或相等
如果ransomNote比magazine长度大,肯定不够
collections.Counter用来统计某序列中每个元素出现的次数,以键值对的方式存在字典中
'''
if len(ransomNote) > len(magazine):
return False
return not collections.Counter(ransomNote) - collections.Counter(magazine)
1615.最大网络轶
n 座城市和一些连接这些城市的道路 roads 共同组成一个基础设施网络。每个 roads[i] = [ai, bi] 都表示在城市 ai 和 bi 之间有一条双向道路。
两座不同城市构成的 城市对 的 网络秩 定义为:与这两座城市 直接 相连的道路总数。如果存在一条道路直接连接这两座城市,则这条道路只计算 一次 。
整个基础设施网络的 最大网络秩 是所有不同城市对中的 最大网络秩 。
给你整数 n 和数组 roads,返回整个基础设施网络的 最大网络秩
示例 1:
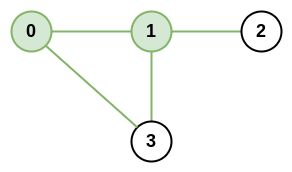
输入:n = 4, roads = [[0,1],[0,3],[1,2],[1,3]]
输出:4
解释:城市 0 和 1 的网络秩是 4,因为共有 4 条道路与城市 0 或 1 相连。位于 0 和 1 之间的道路只计算一次。
示例 2:
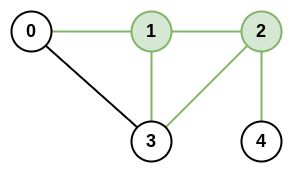
输入:n = 5, roads = [[0,1],[0,3],[1,2],[1,3],[2,3],[2,4]]
输出:5
解释:共有 5 条道路与城市 1 或 2 相连。
方法一:枚举法
connect二维列表记录节点相连状态
degree一维列表记录各节点相连道路数量
用穷举的方式记录节点间道路相加数最大的(connect为True需-1)值,即为最大网络轶
方法二:贪心算法
同样得到connect和degree
贪心思想是做出在当前看来是最好的选择,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性,即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
思想:
对于最大网络轶的两个节点,他们的节点相连数一定是最大或最大和第二大的,因此仅记录最大和次大节点及其相连数即可。
first:最大相连数 first_list:最大相连数的节点列表
second:次大相连数 second_list:次大相连数的节点列表
最大网络轶计算:
(1)first_list只有一个,判断改节点和second_list中是否有不相连的,有则为first+second,无则为first+second-1
(2)first_list中不止一个,此时无需考虑second_list,因为2\*first>2*first-1>first+second。判断len(first_list) * (len(first_list) - 1) / 2 > len(roads),大于则为2\*first,小于则判断first_list中各节点是否有不相连的,有则为2\*first,无则为2\*first-1
class Solution(object):
def maximalNetworkRank(self, n, roads):
"""
:type n: int
:type roads: List[List[int]]
:rtype: int
"""
connect = [[False] * n for _ in range(n)]
degree = [0] * n
for a, b in roads:
connect[a][b] = True
connect[b][a] = True
degree[a] += 1
degree[b] += 1
# 枚举法
# maxRank = 0
# for i in range(n):
# for j in range(i + 1, n):
# rank = degree[i] + degree[j] - connect[i][j]
# maxRank = max(maxRank, rank)
# return maxRank
# 贪心
first_list = []
second_list = []
first = -1
second = -2
for i in range(n):
if degree[i] > first:
second = first
second_list = first_list
first = degree[i]
first_list = [i]
elif degree[i] == first:
first_list.append(i)
elif degree[i] > second:
second = degree[i]
second_list = [i]
elif degree[i] == second:
second_list.append(i)
else:
continue
if len(first_list) == 1:
a = first_list[0]
for b in second_list:
if not connect[a][b]:
return first + second
return first + second - 1
else:
if len(first_list) * (len(first_list) - 1) / 2 > len(roads):
return first * 2
for i in range(len(first_list)):
a = first_list[i]
for j in range(i+1, len(first_list)):
b = first_list[j]
if not connect[a][b]:
return first * 2
return first * 2 - 1
2373.矩阵中的局部最大值
给你一个大小为 n x n 的整数矩阵 grid 。
生成一个大小为 (n - 2) x (n - 2) 的整数矩阵 maxLocal ,并满足:
maxLocal[i][j]等于grid中以i + 1行和j + 1列为中心的3 x 3矩阵中的 最大值 。
换句话说,我们希望找出 grid 中每个 3 x 3 矩阵中的最大值。
返回生成的矩阵。
示例 1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KokStbfv-1680883363622)(null)]
输入:grid = [[9,9,8,1],[5,6,2,6],[8,2,6,4],[6,2,2,2]]
输出:[[9,9],[8,6]]
解释:原矩阵和生成的矩阵如上图所示。
注意,生成的矩阵中,每个值都对应 grid 中一个相接的 3 x 3 矩阵的最大值。
方法一:暴力求解
方法二:单调队列
思路:固定行或列,计算每行3个的最大值并存在列表里, 计算该列表里每3个的最大值,即为最终矩阵
class Solution(object):
def largestLocal(self, grid):
"""
:type grid: List[List[int]]
:rtype: List[List[int]]
"""
# n = len(grid)
# maxLocal = [[0] * (n - 2) for _ in range(n - 2)]
# for i in range(1,n-1):
# for j in range(1,n-1):
# maxLocal[i-1][j-1] = max(grid[i-1][j-1],grid[i-1][j],grid[i-1][j+1],grid[i][j-1], grid[i][j],grid[i][j+1],grid[i+1][j-1],grid[i+1][j],grid[i+1][j+1])
# return maxLocal
ll = len(grid[0])
tm = [0 for _ in xrange(ll)]
ret = [[0 for _ in xrange(ll-2)] for _ in xrange(ll-2)]
for i in xrange(ll-2):
for j in xrange(ll):
tm[j] = max(grid[i][j], grid[i+1][j], grid[i+2][j])
if j >= 2:
ret[i][j-2] = max(tm[j-2], tm[j-1], tm[j])
return ret
1625.执行操作后字典序最小的字符串
给你一个字符串 s 以及两个整数 a 和 b 。其中,字符串 s 的长度为偶数,且仅由数字 0 到 9 组成。
你可以在 s 上按任意顺序多次执行下面两个操作之一:
- 累加:将
a加到s中所有下标为奇数的元素上(下标从 0 开始)。数字一旦超过9就会变成0,如此循环往复。例如,s = "3456"且a = 5,则执行此操作后s变成"3951"。 - 轮转:将
s向右轮转b位。例如,s = "3456"且b = 1,则执行此操作后s变成"6345"。
请你返回在 s 上执行上述操作任意次后可以得到的 字典序最小 的字符串。
如果两个字符串长度相同,那么字符串 a 字典序比字符串 b 小可以这样定义:在 a 和 b 出现不同的第一个位置上,字符串 a 中的字符出现在字母表中的时间早于 b 中的对应字符。例如,"0158” 字典序比 "0190" 小,因为不同的第一个位置是在第三个字符,显然 '5' 出现在 '9' 之前。
示例 1:
输入:s = "5525", a = 9, b = 2
输出:"2050"
解释:执行操作如下:
初态:"5525"
轮转:"2555"
累加:"2454"
累加:"2353"
轮转:"5323"
累加:"5222"
累加:"5121"
轮转:"2151"
累加:"2050"
无法获得字典序小于 "2050" 的字符串。
import math
class Solution(object):
def findLexSmallestString(self, s, a, b):
"""
:type s: str
:type a: int
:type b: int
:rtype: str
"""
# q = deque([s]) # 双向队列
# vis = {s} # 记录操作后得到的值,避免重复
# ans = s
# while q:
# s = q.popleft() # s取q队列的最左个值,并将该值从队列移除
# if ans > s: # 记录最小值
# ans = s
# t1 = ''.join([str((int(c) + a) % 10) if i & 1 else c for i, c in enumerate(s)]) # 操作a
# t2 = s[-b:] + s[:-b] # 操作b
# for t in (t1, t2): # 判断a操作和b操作得到的2个值是否出现过,出现过则不管他,未出现过则加入队列q和列表vis
# if t not in vis:
# vis.add(t)
# q.append(t)
# return ans
# lens, lst = len(s), set(''.join(str((int(c) + j * a) % 10) if i & 1 else str((int(c) + k * a) % 10) for i, c in enumerate(s)) for j in range(10) for k in range(10)) if b & 1 else set(''.join(str((int(c) + j * a) % 10) if i & 1 else c for i, c in enumerate(s)) for j in range(10))
# return min(l[i % lens : ] + l[ : i % lens] for i in range(0, lens * b // gcd(lens, b), b) for l in lst)
def gcd(a, b): # 求最大公约数
if a < b:
a, b = b, a
while b != 0:
temp = a % b
a = b
b = temp
return a
lst = set()
lens = len(s)
ans_list = []
if b & 1: # 判断是否为奇数,b为奇数,则a=1/3/7/9有10*10种,a=2/4/6有5*5种,a=5有2*2种
if a == 5:
for k in range(2):
for j in range(2):
ll = []
for i, c in enumerate(s):
if i & 1:
ll.append(str((int(c) + j * a) % 10))
else:
ll.append(str((int(c) + k * a) % 10))
lst.add(''.join(ll))
elif a % 2 == 0:
for k in range(5):
for j in range(5):
ll = []
for i, c in enumerate(s):
if i & 1:
ll.append(str((int(c) + j * a) % 10))
else:
ll.append(str((int(c) + k * a) % 10))
lst.add(''.join(ll))
else:
for k in range(10):
for j in range(10):
ll = []
for i, c in enumerate(s):
if i & 1:
ll.append(str((int(c) + j * a) % 10))
else:
ll.append(str((int(c) + k * a) % 10))
lst.add(''.join(ll))
else: # b是偶数的时候,只有奇数位进行加a操作,最多10次
for j in range(10):
ll = []
for i, c in enumerate(s):
if i & 1:
ll.append(str((int(c) + j * a) % 10))
else:
ll.append(c)
lst.add(''.join(ll))
# 对第一步累加得到的lst的每种情况进行轮转,每种情况的轮转次数为:len(s) // gcd(len(s), b)
for l in lst:
for i in range(0, lens * b // gcd(lens, b), b):
ans_list.append(l[i % lens : ] + l[ : i % lens])
return min(ans_list)
704.二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
class Solution(object):
def search(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: int
"""
l, r = 0, len(nums)-1
while l <= r:
p = l + (r - l) // 2 # 避免r + l溢出
if nums[p] < target:
l = p + 1
elif nums[p] > target:
r = p - 1
else:
return p
return -1
面试题 05.02. 二进制数转字符串
二进制数转字符串。给定一个介于0和1之间的实数(如0.72),类型为double,打印它的二进制表达式。如果该数字无法精确地用32位以内的二进制表示,则打印“ERROR”。
示例1:
输入:0.625
输出:"0.101"
示例2:
输入:0.1
输出:"ERROR"
提示:0.1无法被二进制准确表示
class Solution(object):
def printBin(self, num):
"""
:type num: float
:rtype: str
"""
ans = '0.'
while len(ans) <= 32 and num != 0:
num *= 2
digit = int(num)
ans += str(digit)
num -= digit
return ans if len(ans) <= 32 else 'ERROR'
2. 两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:

输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
递归-此方法分3种情况
- l1 节点为空返回 l2,l2 节点为空返回 l1 (没什么好说的)
- l1 + l2 小于 10,则再调用此方法另下节点相加
- l1 + l2 大于 10,则创建一个新节点并令其与 l1 下节点相加,然后 l1 节点取余,再让 l1 + l2
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def addTwoNumbers(self, l1, l2):
"""
:type l1: ListNode
:type l2: ListNode
:rtype: ListNode
"""
if not l1:
return l2
if not l2:
return l1
l1.val += l2.val # 将两数相加,赋值给 l1 节点
if l1.val >= 10: # 结果大于10 进行递归 l1值去10
l1.next = self.addTwoNumbers(ListNode(l1.val // 10), l1.next)
l1.val %= 10
l1.next = self.addTwoNumbers(l1.next, l2.next)
return l1
283.移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
输入: nums = [0,1,0,3,12]
输出: [1,3,12,0,0]
示例 2:
输入: nums = [0]
输出: [0]
这里参考了快速排序的思想,快速排序首先要确定一个待分割的元素做中间点 x,然后把所有小于等于 x 的元素放到 x 的左边,大于x的元素放到其右边。
这里我们可以用 0 当做这个中间点,把不等于 0(注意题目没说不能有负数)的放到中间点的左边,等于 0 的放到其右边。 这的中间点就是 0 本身,所以实现起来比快速排序简单很多,我们使用两个指针 i 和 j,只要 nums[i]!=0,我们就交换nums[i]和 nums[j]
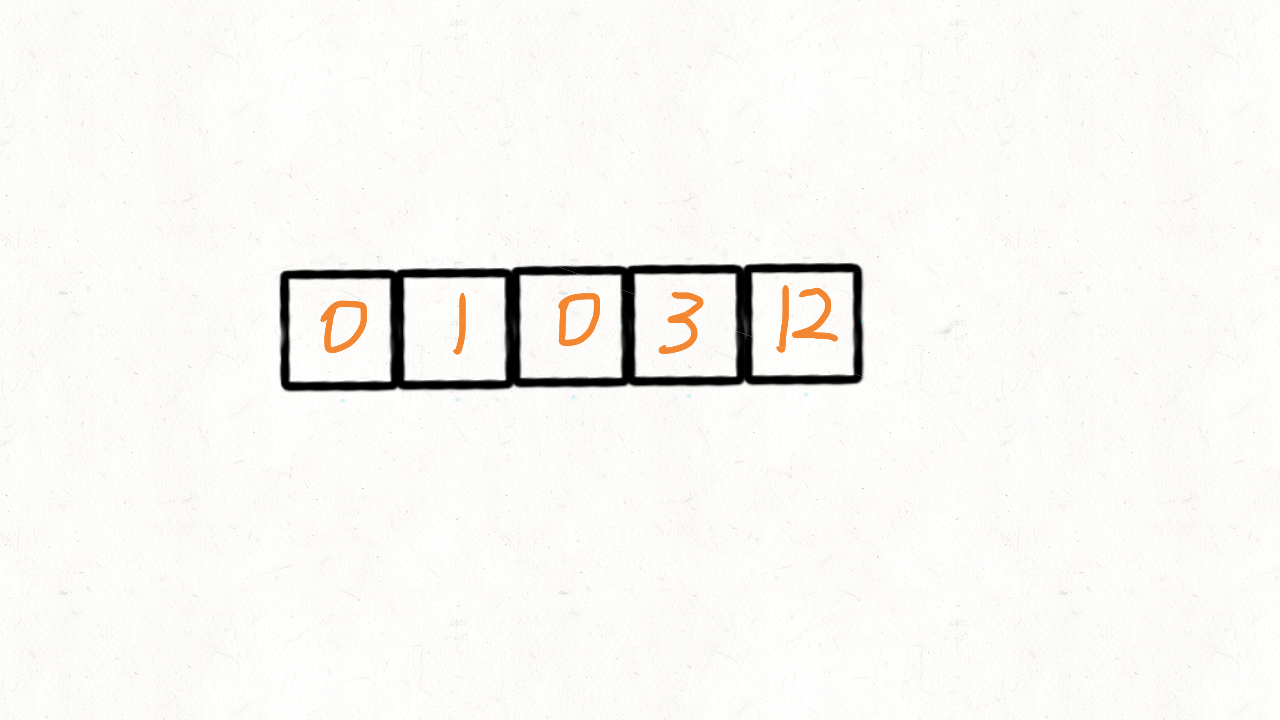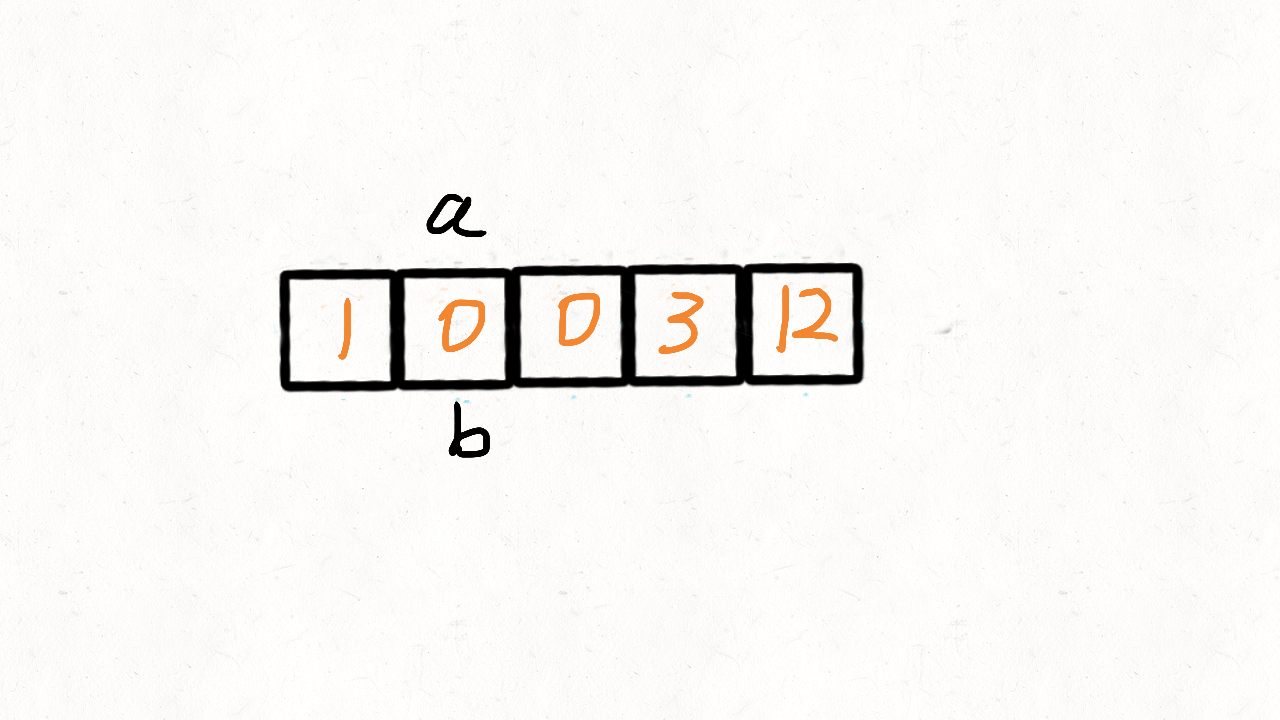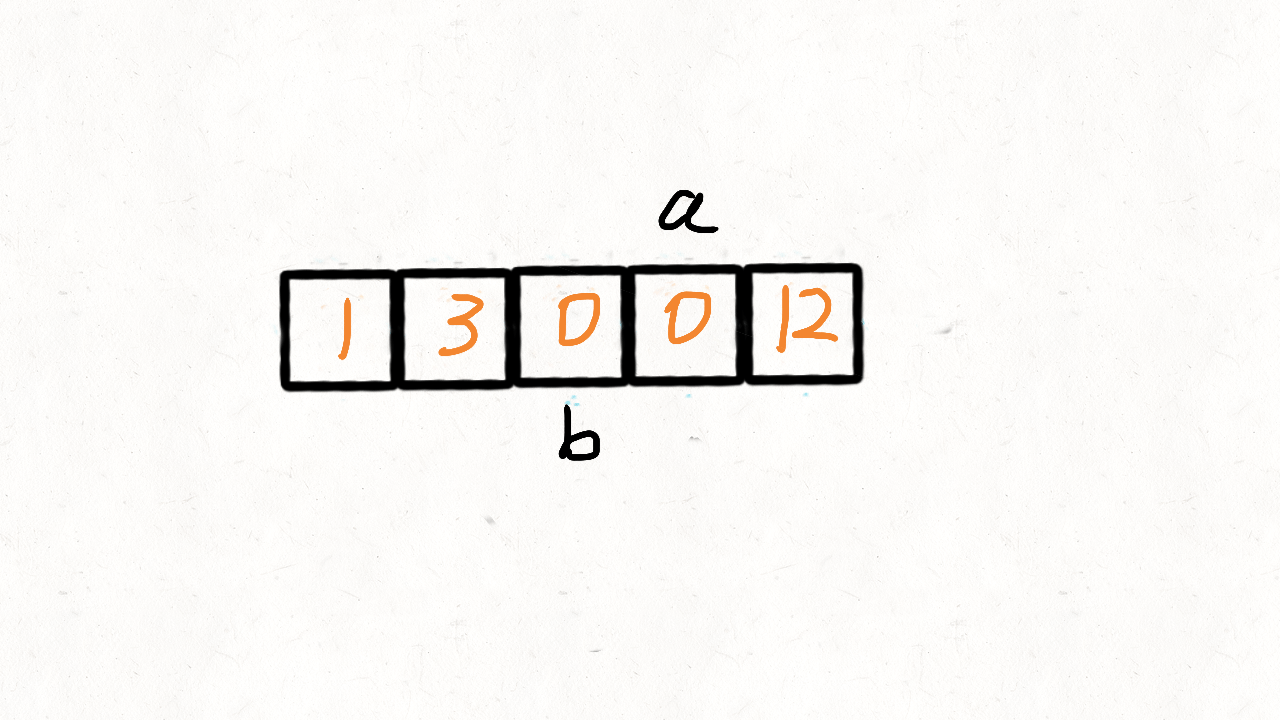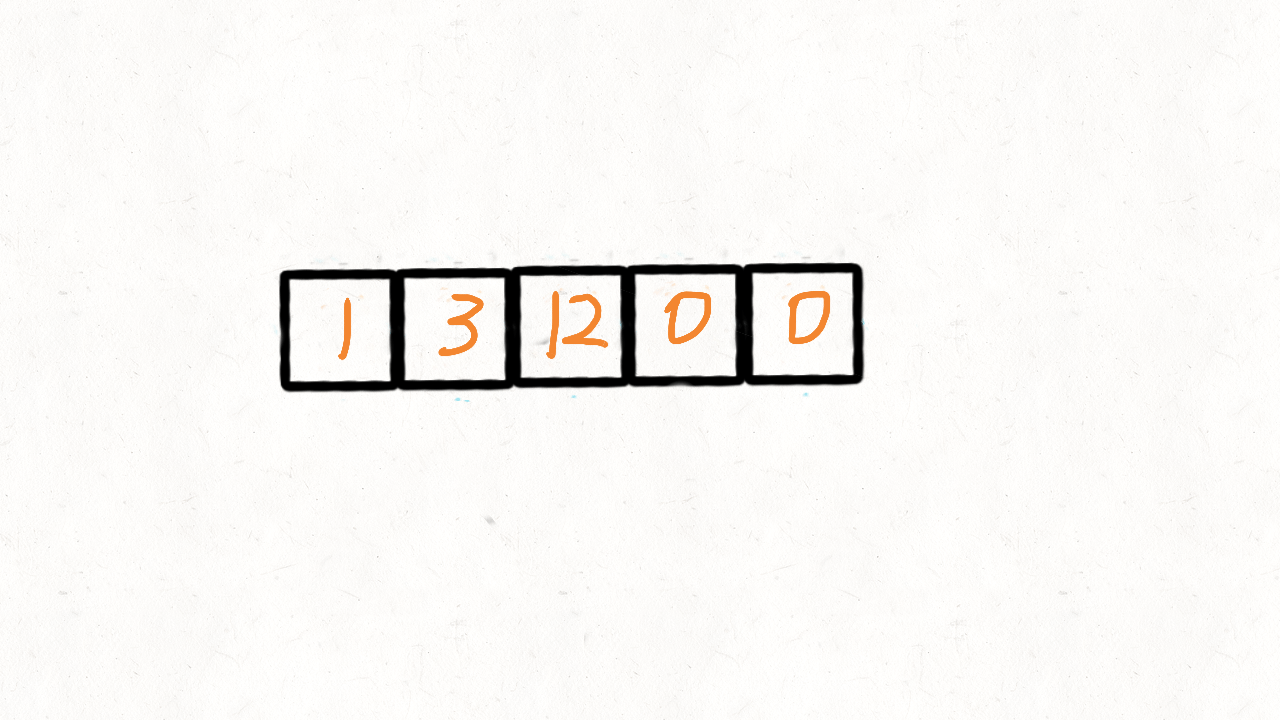
时间复杂度:O(n)
空间复杂度:O(1)
class Solution(object):
def moveZeroes(self, nums):
"""
:type nums: List[int]
:rtype: None Do not return anything, modify nums in-place instead.
"""
# nums[:] = [i for i in nums if i != 0] + [0] * nums.count(0)
if not nums:
return 0
j = 0
for i in range(len(nums)):
if nums[i]:
if i > j:
nums[j], nums[i] = nums[i], nums[j]
j += 1
167.两数之和 II - 输入有序数组
给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 <= index1 < index2 <= numbers.length 。
以长度为 2 的整数数组 [index1, index2] 的形式返回这两个整数的下标 index1 和 index2。
你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。
你所设计的解决方案必须只使用常量级的额外空间。
示例 1:
输入:numbers = [2,7,11,15], target = 9
输出:[1,2]
解释:2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。返回 [1, 2] 。
示例 2:
输入:numbers = [2,3,4], target = 6
输出:[1,3]
解释:2 与 4 之和等于目标数 6 。因此 index1 = 1, index2 = 3 。返回 [1, 3] 。
示例 3:
输入:numbers = [-1,0], target = -1
输出:[1,2]
解释:-1 与 0 之和等于目标数 -1 。因此 index1 = 1, index2 = 2 。返回 [1, 2] 。
解题思路详细
class Solution(object):
def twoSum(self, numbers, target):
"""
:type numbers: List[int]
:type target: int
:rtype: List[int]
"""
# 暴力解法
# for i in range(len(numbers)):
# delta = target - numbers[i]
# if delta in numbers[i + 1:]:
# return[i + 1, numbers[i + 1:].index(delta) + i + 2]
# 双指针法,缩减搜索空间
i = 0
j = len(numbers) - 1
while i < j:
sum = numbers[i] + numbers[j]
if sum > target:
j -= 1
elif sum < target:
i += 1
else:
return [i + 1, j + 1]
1626. 无矛盾的最佳球队
假设你是球队的经理。对于即将到来的锦标赛,你想组合一支总体得分最高的球队。球队的得分是球队中所有球员的分数 总和 。
然而,球队中的矛盾会限制球员的发挥,所以必须选出一支 没有矛盾 的球队。如果一名年龄较小球员的分数 严格大于 一名年龄较大的球员,则存在矛盾。同龄球员之间不会发生矛盾。
给你两个列表 scores 和 ages,其中每组 scores[i] 和 ages[i] 表示第 i 名球员的分数和年龄。请你返回 所有可能的无矛盾球队中得分最高那支的分数 。
示例 1:
输入:scores = [1,3,5,10,15], ages = [1,2,3,4,5]
输出:34
解释:你可以选中所有球员。
示例 2:
输入:scores = [4,5,6,5], ages = [2,1,2,1]
输出:16
解释:最佳的选择是后 3 名球员。注意,你可以选中多个同龄球员。
示例 3:
输入:scores = [1,2,3,5], ages = [8,9,10,1]
输出:6
解释:最佳的选择是前 3 名球员。
解题思路
本题的数据范围显然不可能支持我们进行所有子集的枚举。我们希望找到一种顺序,使得我们在进行选择时,总是不会发生冲突。
我们可以将所有队员按照年龄升序进行排序,年龄相同时,则按照分数升序进行排序。排序之后,我们可以进行动态规划。令 dp[i]表示最后一个队员是第i个队员时的最大分数(这里的i 是重新排序后的编号)。我们只需要在 [0,i−1] 的范围内枚举上一个队员即可。这里,如果上一个队员的分数不超过当前队员的分数,就可以进行转移。
为什么这样的枚举一定是合法的呢?因为我们的最大分数总是在最后一个队员处取得(对于相同年龄的,我们是按照分数升序排序的,所以分数较高的一定在更后面),同时第 iii 个队员的年龄不小于之前任意队员的年龄,所以只要第i个队员的分数大于等于之前的分组中最后一个队员的分数,就一定可以将第i个队员加入到组里,从而得到一个以第i个队员为最后一名队员的新的组。
class Solution(object):
def bestTeamScore(self, scores, ages):
"""
:type scores: List[int]
:type ages: List[int]
:rtype: int
"""
tup = [(age, score) for age, score in zip(ages, scores)]
tup.sort()
dp = [0] * (1+len(scores))
for idx, (age, score) in enumerate(tup):
tmp = 0
for j in range(idx):
if tup[j][1] <= score:
tmp = max(tmp, dp[j])
dp[idx] = tmp + score
return max(dp)
leetcode官方题解,俩种方法
567.字符串的排列
给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列。如果是,返回 true ;否则,返回 false 。
换句话说,s1 的排列之一是 s2 的 子串 。
示例 1:
输入:s1 = "ab" s2 = "eidbaooo"
输出:true
解释:s2 包含 s1 的排列之一 ("ba").
示例 2:
输入:s1= "ab" s2 = "eidboaoo"
输出:false
解题思路:
滑动窗口 + 字典
分析一: 题目要求 s1 的排列之一是 s2 的一个子串。而子串必须是连续的,所以要求的 s2 子串的长度跟 s1 长度必须相等。
分析二: 那么我们有必要把 s1 的每个排列都求出来吗?当然不用。如果字符串 a 是 b 的一个排列,那么当且仅当它们两者中的每个字符的个数都必须完全相等。
所以,根据上面两点分析,我们已经能确定这个题目可以使用 滑动窗口 + 字典 来解决。
我们使用一个长度和 s1 长度相等的固定窗口大小的滑动窗口,在 s2 上面从左向右滑动,判断 s2 在滑动窗口内的每个字符出现的个数是否跟 s1 每个字符出现次数完全相等。
我们定义 counter1 是对 s1 内字符出现的个数的统计,定义 counter2 是对 s2 内字符出现的个数的统计。在窗口每次右移的时候,需要把右边新加入窗口的字符个数在 counter2 中加 1,把左边移出窗口的字符的个数减 1。如果 counter1 == counter2 ,那么说明窗口内的子串是 s1 的一个排列,返回 True;如果窗口已经把 s2 遍历完了仍然没有找到满足条件的排列,返回 False。
对于题目给的示例一:s1 = “ab” s2 = “eidbaooo”,我制作了滑动窗口过程的动画帮助理解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sS10Pxnz-1680883355230)(https://pic.leetcode-cn.com/1612923521-rTbkNV-567.gif)]
详细讲解
官解两种方法(滑动窗口/双指针)
class Solution(object):
def checkInclusion(self, s1, s2):
"""
:type s1: str
:type s2: str
:rtype: bool
"""
# 统计 s1 中每个字符出现的次数
counter1 = collections.Counter(s1)
N = len(s2)
# 定义滑动窗口的范围是 [left, right],闭区间,长度与s1相等
left = 0
right = len(s1) - 1
# 统计窗口s2[left, right - 1]内的元素出现的次数
counter2 = collections.Counter(s2[0:right])
while right < N:
# 把 right 位置的元素放到 counter2 中
counter2[s2[right]] += 1
# 如果滑动窗口内各个元素出现的次数跟 s1 的元素出现次数完全一致,返回 True
if counter1 == counter2:
return True
# 窗口向右移动前,把当前 left 位置的元素出现次数 - 1
counter2[s2[left]] -= 1
# 如果当前 left 位置的元素出现次数为 0, 需要从字典中删除,否则这个出现次数为 0 的元素会影响两 counter 之间的比较
if counter2[s2[left]] == 0:
del counter2[s2[left]]
# 窗口向右移动
left += 1
right += 1
return False
1574.删除最短的子数组使剩余数组有序
给你一个整数数组 arr ,请你删除一个子数组(可以为空),使得 arr 中剩下的元素是 非递减 的。
一个子数组指的是原数组中连续的一个子序列。
请你返回满足题目要求的最短子数组的长度。
示例 1:
输入:arr = [1,2,3,10,4,2,3,5]
输出:3
解释:我们需要删除的最短子数组是 [10,4,2] ,长度为 3 。剩余元素形成非递减数组 [1,2,3,3,5] 。
另一个正确的解为删除子数组 [3,10,4] 。
示例 2:
输入:arr = [5,4,3,2,1]
输出:4
解释:由于数组是严格递减的,我们只能保留一个元素。所以我们需要删除长度为 4 的子数组,要么删除 [5,4,3,2],要么删除 [4,3,2,1]。
示例 3:
输入:arr = [1,2,3]
输出:0
解释:数组已经是非递减的了,我们不需要删除任何元素。
示例 4:
输入:arr = [1]
输出:0
解题思路:
注意删除的是数组,因此要么删开头一段,要么删中间一段,要么删结尾一段。
假设删除的是 arr[i+1]∼arr[j−1]\textit{arr}[i + 1] \sim \textit{arr}[j - 1]arr[i+1]∼arr[j−1] 之间的元素,我们需要保证:
arr[0]∼arr[i]非递减arr[j]∼arr[n−1]非递减arr[i]≤arr[j]
如果我们枚举i 和 j,然后再用 O(n)的时间判断是否满足上述条件,那么总复杂度是 O(n^3)。但如果我们在从小到大枚举i的过程中也从大到小枚举 j,那么我们可以将条件1 和条件2 的判定结合到枚举过程中(每移动 i或者 j一次,就判断条件 1 和条件2 是否仍然满足),总复杂度将会降低至 O(n^2)。
更进一步思考,假设对于当前的 i来说,j_1 是最优的,那么这意味着这个 j_1是最小的满足条件 2 和条件 3 的下标。最小是因为我们要使得被删除数组 arr[i+1]∼arr[j−1] 最短。此时我们将i加 1,如果满足条件 1,即 arr[i+1]≥arr[i],那么i+1所匹配的 j_2满足 j_2≥j_1 。
因此,我们需要两个指针来维护这样的i和 j。起初 j 指向数组尾部,然后不断往前移动,直到前面的元素小于当前所指元素。然后初始化答案为j前面的元素个数。
然后我们让i从0开始,直到n−1。对于每个i,我们让j不断地向后移动,直到 arr[j]≥arr[i]或者 j=n,此时j−i−1就是我们要删除的元素个数,用它来更新答案。然后令i等于i+1,并保证 arr[i+1]≥arr[i],如果不满足则直接跳出循环,如果满足则继续下一轮枚举。
class Solution:
def findLengthOfShortestSubarray(self, arr):
n = len(arr)
j = n - 1
while j > 0 and arr[j - 1] <= arr[j]:
j -= 1
if j == 0:
return 0
res = j
for i in range(n):
while j < n and arr[j] < arr[i]:
j += 1
res = min(res, j - i - 1)
if i + 1 < n and arr[i] > arr[i + 1]:
break
return res
# class Solution:
# def findLengthOfShortestSubarray(self, arr):
# n = len(arr)
# i, j = 0, n - 1
# while i + 1 < n and arr[i] <= arr[i + 1]:
# i += 1
# while j - 1 >= 0 and arr[j - 1] <= arr[j]:
# j -= 1
# if i >= j:
# return 0
# ans = min(n - i - 1, j)
# r = j
# for l in range(i + 1):
# while r < n and arr[r] < arr[l]:
# r += 1
# ans = min(ans, r - l - 1)
# return ans
733.图像渲染
有一幅以 m x n 的二维整数数组表示的图画 image ,其中 image[i][j] 表示该图画的像素值大小。
你也被给予三个整数 sr , sc 和 newColor 。你应该从像素 image[sr][sc] 开始对图像进行 上色填充 。
为了完成 上色工作 ,从初始像素开始,记录初始坐标的 上下左右四个方向上 像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应 四个方向上 像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为 newColor 。
最后返回 经过上色渲染后的图像 。
示例 1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-teFqa0KC-1680883363658)(null)]
输入: image = [[1,1,1],[1,1,0],[1,0,1]],sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析: 在图像的正中间,(坐标(sr,sc)=(1,1)),在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,因为它不是在上下左右四个方向上与初始点相连的像素点。
示例 2:
输入: image = [[0,0,0],[0,0,0]], sr = 0, sc = 0, newColor = 2
输出: [[2,2,2],[2,2,2]]
解题思路:
BFS广度优先搜索
DFS深度优先搜索
DFS 与 BFS 两种方法 三种实现 超精简代码 趣味详解
官解(广度、深度)无python
#from queue import Queue
class Solution(object):
def floodFill(self, image, sr, sc, color):
"""
:type image: List[List[int]]
:type sr: int
:type sc: int
:type color: int
:rtype: List[List[int]]
"""
# BFS queue
# # 起始颜色和目标颜色相同,则直接返回原图
# if color == image[sr][sc]:
# return image
# # 设置四个方向偏移量,一种常见的省事儿技巧
# directions = {(1, 0), (-1, 0), (0, 1), (0, -1)}
# # 构造一个队列,先把起始点放进去
# que = Queue()
# que.put((sr, sc))
# # 记录初始颜色
# originalcolor = image[sr][sc]
# # 当队列不为空
# while not que.empty():
# # 取出队列的点并染色
# point = que.get()
# image[point[0]][point[1]] = newColor
# # 遍历四个方向
# for direction in directions:
# # 新点是(new_i,new_j)
# new_i = point[0] + direction[0]
# new_j = point[1] + direction[1]
# # 如果这个点在定义域内并且它和原来的颜色相同
# if 0 <= new_i < len(image) and 0 <= new_j < len(image[0]) and image[new_i][new_j] == originalcolor:
# que.put((new_i, new_j))
# return image
# BFS list
# if color == image[sr][sc]:return image
# que, old, = [(sr, sc)], image[sr][sc]
# while que:
# point = que.pop()
# image[point[0]][point[1]] = color
# for new_i, new_j in zip((point[0], point[0], point[0] + 1, point[0] - 1), (point[1] + 1, point[1] - 1, point[1], point[1])):
# if 0 <= new_i < len(image) and 0 <= new_j < len(image[0]) and image[new_i][new_j] == old:
# que.insert(0,(new_i,new_j))
# return image
# DFS 栈
# if color == image[sr][sc]: return image
# stack, old = [(sr, sc)], image[sr][sc]
# while stack:
# point = stack.pop()
# image[point[0]][point[1]] = color
# for new_i, new_j in zip((point[0], point[0], point[0] + 1, point[0] - 1), (point[1] + 1, point[1] - 1, point[1], point[1])):
# if 0 <= new_i < len(image) and 0 <= new_j < len(image[0]) and image[new_i][new_j] == old:
# stack.append((new_i, new_j))
# return image
# DFS 递归
if image[sr][sc] != color:
old, image[sr][sc] = image[sr][sc], color
for i, j in zip((sr, sr+1, sr, sr-1), (sc+1, sc, sc-1, sc)):
if 0 <= i < len(image) and 0 <= j < len(image[0]) and image[i][j] == old:
self.floodFill(image, i, j, color)
return image
695.岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例 1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PnDaKmIF-1680883363583)(null)]
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]]
输出:6
解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
示例 2:
输入:grid = [[0,0,0,0,0,0,0,0]]
输出:0
官解(深度、广度)
class Solution(object):
# 深度优先
# def dfs(self, grid, cur_i, cur_j):
# if cur_i < 0 or cur_j < 0 or cur_i == len(grid) or cur_j == len(grid[0]) or grid[cur_i][cur_j] != 1:
# return 0
# grid[cur_i][cur_j] = 0
# ans = 1
# for di, dj in [[0, 1], [0, -1], [1, 0], [-1, 0]]:
# next_i, next_j = cur_i + di, cur_j + dj
# ans += self.dfs(grid, next_i, next_j)
# return ans
# def maxAreaOfIsland(self, grid):
# ans = 0
# for i, l in enumerate(grid):
# for j, n in enumerate(l):
# ans = max(self.dfs(grid, i, j), ans)
# return ans
# 深度优先 栈
# def maxAreaOfIsland(self, grid):
# ans = 0
# for i, l in enumerate(grid):
# for j, n in enumerate(l):
# cur = 0
# stack = [(i, j)]
# while stack:
# cur_i, cur_j = stack.pop()
# if cur_i < 0 or cur_j < 0 or cur_i == len(grid) or cur_j == len(grid[0]) or grid[cur_i][cur_j] != 1:
# continue
# cur += 1
# grid[cur_i][cur_j] = 0
# for di, dj in [[0, 1], [0, -1], [1, 0], [-1, 0]]:
# next_i, next_j = cur_i + di, cur_j + dj
# stack.append((next_i, next_j))
# ans = max(ans, cur)
# return ans
# 广度优先 队列
def maxAreaOfIsland(self, grid):
ans = 0
for i, l in enumerate(grid):
for j, n in enumerate(l):
cur = 0
q = collections.deque([(i, j)])
while q:
cur_i, cur_j = q.popleft()
if cur_i < 0 or cur_j < 0 or cur_i == len(grid) or cur_j == len(grid[0]) or grid[cur_i][cur_j] != 1:
continue
cur += 1
grid[cur_i][cur_j] = 0
for di, dj in [[0, 1], [0, -1], [1, 0], [-1, 0]]:
next_i, next_j = cur_i + di, cur_j + dj
q.append((next_i, next_j))
ans = max(ans, cur)
return ans
1638. 统计只差一个字符的子串数目
给你两个字符串 s 和 t ,请你找出 s 中的非空子串的数目,这些子串满足替换 一个不同字符 以后,是 t 串的子串。换言之,请你找到 s 和 t 串中 恰好 只有一个字符不同的子字符串对的数目。
比方说, "computer" and "computation" 只有一个字符不同: 'e'/'a' ,所以这一对子字符串会给答案加 1 。
请你返回满足上述条件的不同子字符串对数目。
一个 子字符串 是一个字符串中连续的字符。
示例 1:
输入:s = "aba", t = "baba"
输出:6
解释:以下为只相差 1 个字符的 s 和 t 串的子字符串对:
("aba", "baba")
("aba", "baba")
("aba", "baba")
("aba", "baba")
("aba", "baba")
("aba", "baba")
加粗部分分别表示 s 和 t 串选出来的子字符串。
示例 2:
输入:s = "ab", t = "bb"
输出:3
解释:以下为只相差 1 个字符的 s 和 t 串的子字符串对:
("ab", "bb")
("ab", "bb")
("ab", "bb")
加粗部分分别表示 s 和 t 串选出来的子字符串。
示例 3:
输入:s = "a", t = "a"
输出:0
示例 4:
输入:s = "abe", t = "bbc"
输出:10
解题思路:
官解,枚举(Python)/动态规划(无)
动态规划python
非暴力解法(靠思路)
class Solution(object):
def countSubstrings(self, s, t):
"""
:type s: str
:type t: str
:rtype: int
"""
# 枚举
# 从s的i个值和t的j个值同时开始向右扩展,计数两个字符串不同的次数,
# 等于1则ans+1,大于1则跳出循环,继续i,j循环知道s,t遍历完成
ans = 0
for i in range(len(s)):
for j in range(len(t)):
diff = 0
k = 0
while i + k < len(s) and j + k < len(t):
if s[i + k] != t[j + k]:
diff += 1
if diff == 1:
ans += 1
elif diff > 1:
break
k += 1
return ans
# 动态规划
# f[i][j][0]表示s第i个值和t第j个值,其前及其字符串相同的长度
# f[i][j][1]表示s第i个值和t第j个值,其前及其字符串仅一个不同的长度
# 当s[i-1]不等于t[j-1]时,得到f[i - 1][j - 1][0]的值n,表示s[i-1]和t[j-1]字符前有n个字符对应相同,因此令f[i][j][1] = f[i - 1][j - 1][0] + 1 = n + 1,即其可构成n+1个子串,满足条件
# 当s[i-1]等于t[j-1]时,得到f[i - 1][j - 1][0]的值n,令f[i][j][0] = f[i - 1][j - 1][0] + 1 = n + 1,即s[i-1]和t[j-1]字符及其前有n + 1个字符对应相同;同时得到f[i - 1][j - 1][1],表示s[i-1]和t[j-1]字符前有长度为n的字符串恰好对应只差一个,令f[i][j][1] = f[i - 1][j - 1][1],表示s[i-1]和t[j-1]字符及其前有长度为n的字符串恰好对应只差一个(PS:无需加1,因为s[i-1]和t[j-1]字符相等,相较于f[i - 1][j - 1][1]所对应的s[i-2]和t[i-2]字符所构成的满足条件字符串,f[i][j][1]所构成满足条件字符串仅比其后面多加了一个字符s[i-1]或t[j-1],因为s[i-1]和t[j-1]字符相等所以在子串变化时仍满足字符串相差为1的条件)
m, n = len(s), len(t)
f = [[[0] * 2 for i in range(n + 1)] for i in range(m + 1)]
i = 1
ans = 0
while i <= m:
j = 1
while j <= n:
if s[i - 1] == t[j - 1]:
f[i][j][0] = f[i - 1][j - 1][0] + 1
f[i][j][1] = f[i - 1][j - 1][1]
else:
f[i][j][1] = f[i - 1][j - 1][0] + 1
ans += f[i][j][1]
j += 1
i += 1
return ans
# 其他非暴力解法
# s和t以i,j为结束下标,k为开始下标,符合要求的k在一个区间内
# 即(当第一个s[k0]不等于t[k0]时的k0,下一个s[k1]不等于s[k1]的k1],即满足要求的有k1-k0个
# 此时假设i = j的情况,需要考虑i不等于j的情况,即用差值d,j=i-d。
ans, n, m = 0, len(s), len(t)
for d in range(1 - m, n): # d=i-j, j=i-d
i = max(d, 0)
k0 = k1 = i - 1
while i < n and i - d < m:
if s[i] != t[i - d]:
k0 = k1 # 上上一个不同
k1 = i # 上一个不同
ans += k1 - k0
i += 1
return ans
77.组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
解题思路:
前面用过的,后面不会再选到,用递归
回溯算法
python:
class Solution(object):
def combine(self, n, k):
"""
:type n: int
:type k: int
:rtype: List[List[int]]
"""
# python 内置函数
return list(itertools.combinations(range(1,n+1),k))
# 递归 从头开始
ans = []
path = []
def dps(i):
p = []
if n-i+1 < k - len(path):
return
if len(path) == k:
p.extend(path)
ans.append(p)#ans.append(path[:])
return
for j in range(i,n+1):
path.append(j)
dps(j+1)
path.pop()
return
dps(1)
return ans
#递归 从尾部开始
ans = []
path = []
def dps(i):
p = []
d = k - len(path)
if len(path) == k:
p.extend(path)
ans.append(p)
return
for j in range(i, d-1, -1):
path.append(j)
dps(j-1)
path.pop()
return
dps(n)
return ans
python3:
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
ans = []
path = []
def dfs(i: int) -> None:
d = k - len(path) # 还要选 d 个数
if d == 0:
ans.append(path.copy())
return
# 不选 i
if i > d: dfs(i - 1)
# 选 i
path.append(i)
dfs(i - 1)
path.pop()
dfs(n)
return ans
**PS:list.copy() python2里木有,只有python3里有,python2要用path[:]**的方式,不然path变化append进去的值也会变化
784.字母大小写全排列
给定一个字符串 s ,通过将字符串 s 中的每个字母转变大小写,我们可以获得一个新的字符串。
返回 所有可能得到的字符串集合 。以 任意顺序 返回输出。
示例 1:
输入:s = "a1b2"
输出:["a1b2", "a1B2", "A1b2", "A1B2"]
示例 2:
输入: s = "3z4"
输出: ["3z4","3Z4"]
官解(广度、回溯)
【回溯算法套路①子集型回溯【基础算法精讲 14】
ASCII 表,A 到 Z,Z 完了以后没有直接到 a,中间隔了 6 个字符。
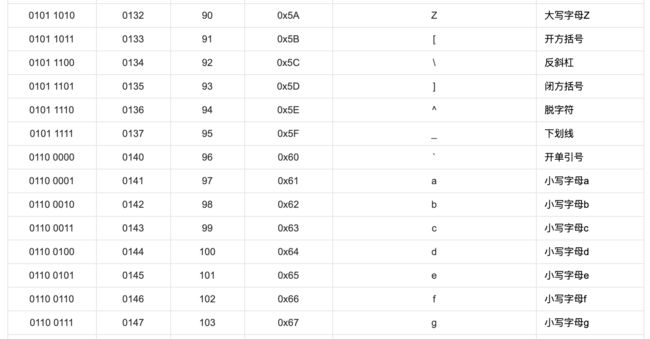
大写字符与其对应的小写字符的 ASCII 的差为 32,32 这个值如果敏感的话,它是 2^5,在编程语言中,可以表示为 1 << 5。
class Solution(object):
def letterCasePermutation(self, s):
"""
:type s: str
:rtype: List[str]
"""
# 广度优先搜索
ans = []
q = deque([''])
while q:
cur = q[0]
pos = len(cur)
if pos == len(s):
ans.append(cur)
q.popleft()
else:
if s[pos].isalpha():
q.append(cur + s[pos].swapcase())
q[0] += s[pos]
return ans
# 回溯
ans = []
def dfs(s, pos):
while pos < len(s) and s[pos].isdigit():
pos += 1
if pos == len(s):
ans.append(''.join(s))
return
dfs(s, pos + 1)
s[pos] = s[pos].swapcase()
dfs(s, pos + 1)
s[pos] = s[pos].swapcase()
dfs(list(s), 0)
return ans
# 用位掩码 bits 唯一地表示一个字符串
# 大小写二进制只有第5位不同,其余都相同,
# 因此只需要与 1 << 5(也就是32)进行异或运算,就可以实现大小写转换了
ans = []
m = sum(c.isalpha() for c in s)
for mask in range(1 << m): # 即2^m
t, k = [], 0
for c in s:
if c.isalpha():
t.append(c.upper() if mask >> k & 1 else c.lower())
k += 1
else:
t.append(c)
ans.append(''.join(t))
return ans
231.2的幂
给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。
如果存在一个整数 x 使得 n == 2x ,则认为 n 是 2 的幂次方。
示例 1:
输入:n = 1
输出:true
解释:20 = 1
解题思路:
方法一:
若 n=2^x,且 x为自然数(即 n为 2 的幂),则一定满足以下条件:
恒有 n & (n - 1) == 0,这是因为:n 二进制最高位为 1,其余所有位为0;
n−1二进制最高位为 0,其余所有位为 1;
一定满足 n > 0。
因此,通过 n > 0 且 n & (n - 1) == 0 即可判定是否满足n=2^x 。
| 2^x | n | n - 1 | n & (n - 1) |
|---|---|---|---|
| 2^0 | 0001 | 0000 | (0001) & (0000) == 0 |
| 2^1 | 0010 | 0001 | (0010) & (0001) == 0 |
| 2^2 | 0100 | 0011 | (0100) & (0011) == 0 |
| 2^3 | 1000 | 0111 | (1000) & (0111) == 0 |
| … | … | … | … |
class Solution(object):
def isPowerOfTwo(self, n):
"""
:type n: int
:rtype: bool
"""
return n > 0 and (n & (n - 1)) == 0
方法二:
由于负数是按照补码规则在计算机中存储的,−n 的二进制表示为 n的二进制表示的每一位取反再加上 1,因此,如果 n是正整数并且 n & (-n) = n,那么 n 就是 2的幂。
class Solution:
def isPowerOfTwo(self, n):
"""
:type n: int
:rtype: bool
"""
return n > 0 and (n & -n) == n
191.位1的个数
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。
示例 1:
输入:n = 00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
示例 2:
输入:n = 00000000000000000000000010000000
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。
示例 3:
输入:n = 11111111111111111111111111111101
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。
解题思路:
官解
class Solution(object):
def hammingWeight(self, n):
"""
:type n: int
:rtype: int
"""
# 转字符串计数字符1出现次数
return bin(n).count("1")
# 循环检查给定整数n的二进制位的每一位是否为1,
# 让n与2^i进行与运算,当且仅当n的第i位为1时,运算结果不0。
ret = sum(1 for i in range(32) if n & (1 << i))
return ret
# n & (n−1)的运算结果恰为把n的二进制位中的最低位的1变为0
# 不断让当前的n与n−1做与运算,直到n变为0即可,运算次数即为n中1的个数
ret = 0
while n:
n &= n - 1
ret += 1
return ret
190. 颠倒二进制位
颠倒给定的 32 位无符号整数的二进制位。
示例 1:
输入:n = 00000010100101000001111010011100
输出:964176192 (00111001011110000010100101000000)
解释:输入的二进制串 00000010100101000001111010011100 表示无符号整数 43261596,
因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。
解题思路:
方法一:
用bin函数转成str然后反转字符串即可,记得去’0b’并在前面加0
方法二:
将n循环右移并将最后一个值,通过对res进行左移和或运算的方式,不断接到res上
方法三:
分治法思想是分而治之,把数字分为两半,然后交换这两半的顺序;然后把前后两个半段都再分成两半,交换内部顺序……直至最后交换顺序的时候,交换的数字只有 1 位。
以一个 8 位的二进制数字为例:

二进制的1111 1111 1111 1111 1111 1111 1111 1111相当于十六进制的ffff ffff
ffff ffff右移16位,变成 0000 ffff
ffff ffff左移16位,变成 ffff 0000
它们俩相或,就可以完成低16位与高16位的交换
之后的每次分治,都要先与上一个掩码,再进行交换
class Solution:
# @param n, an integer
# @return an integer
def reverseBits(self, n):
s = bin(n)[2:][::-1]
s += "0"*(32-len(s))
return int(s, 2)
res = 0
for i in range(32):
res = (res << 1) | (n & 1)
# res << 1:res左移一位即后边多了个0,n & 1:n判断最后一位是否是1
# n 最后一位是1的话res最后一位就由0变1,不然不变
# PS:res初始值为0,0左移还是0不变
n >>= 1
# n右移一位,相当于把最右边那个值pop出去了
return res
n = (n >> 16) | (n << 16)
# 低16位与高16位交换
n = ((n & 0xff00ff00) >> 8) | ((n & 0x00ff00ff) << 8)
# 每16位中低8位和高8位交换; 1111是f
n = ((n & 0xf0f0f0f0) >> 4) | ((n & 0x0f0f0f0f) << 4)
# 每8位中低4位和高4位交换;
n = ((n & 0xcccccccc) >> 2) | ((n & 0x33333333) << 2)
# 每4位中低2位和高2位交换; 1100是c,0011是3
n = ((n & 0xaaaaaaaa) >> 1) | ((n & 0x55555555) << 1)
# 每2位中低1位和高1位交换; 1010是a,0101是5
return n
136. 只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :
输入:nums = [2,2,1]
输出:1
示例 2 :
输入:nums = [4,1,2,1,2]
输出:4
解题思路:
方法一:
排序,因为大小相同,所以2个2个找
方法二:
异或,在二进制上相同的位取0不同取1,即当两个相同的数进行异或得到结果为0,因此全部异或一遍,最后得到的结果就是唯一不重复的那个值
class Solution(object):
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
# ^按位异或 ,二进制位数不同结果位为1
return reduce(lambda x, y: x ^ y, nums)
nums.sort()
for i in range(0,len(nums)-1,2):
if nums[i] != nums[i+1]:
return nums[i]
return nums[-1]
70. 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
解题思路:
其实就是一个斐波那契数列,即这个值是上两个值之和
单纯的暴力递推会超时,因此需要将前期计算过的数值存起来,避免重复计算。
即动态规划(递归DP)
class Solution(object):
def climbStairs(self, n):
"""
:type n: int
:rtype: int
"""
f = [0] * (n+1)
if n == 1:
return 1
if n == 2:
return 2
f[1] = 1
f[2] = 2
for i in range(3,n + 1):
f[i] = f[i - 1] + f[i - 2]
return f[n]
120. 三角形最小路径和
给定一个三角形 triangle ,找出自顶向下的最小路径和。
每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
示例 1:
输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]]
输出:11
解释:如下面简图所示:
2
3 4
6 5 7
4 1 8 3
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
解题思路:
动态规划:
转态转移方程:
f [ i ] [ j ] = { f [ i − 1 ] [ 0 ] + c [ i ] [ 0 ] j = 0 f [ i − 1 ] [ i − 1 ] + c [ i ] [ i ] j = i m i n ( f [ i − 1 ] [ j − 1 ] , f [ i − 1 ] [ j ] ) + c [ i ] [ j ] otherwise f[i][j]=\begin{cases} f[i-1][0]+c[i][0] &\text{} j=0 \\ f[i-1][i-1]+c[i][i] &\text{} j=i \\ min(f[i-1][j-1],f[i-1][j])+c[i][j]&\text{otherwise} \end{cases} f[i][j]=⎩ ⎨ ⎧f[i−1][0]+c[i][0]f[i−1][i−1]+c[i][i]min(f[i−1][j−1],f[i−1][j])+c[i][j]j=0j=iotherwise
class Solution(object):
def minimumTotal(self, triangle):
"""
:type triangle: List[List[int]]
:rtype: int
"""
# 从底部往上
m=len(triangle)
dp=[0]*(len(triangle[m-1])+1)
for i in range(m-1,-1,-1):
for j in range(len(triangle[i])):
dp[j]=min(dp[j],dp[j+1])+triangle[i][j]
return dp[0]
# 动态规划
n = len(triangle)
f = [[0] * n for _ in range(n)]
f[0][0] = triangle[0][0]
for i in range(1, n):
f[i][0] = f[i - 1][0] + triangle[i][0]
for j in range(1, i):
f[i][j] = min(f[i - 1][j - 1], f[i - 1][j]) + triangle[i][j]
f[i][i] = f[i - 1][i - 1] + triangle[i][i]
return min(f[n - 1])
# 动态规划空间优化后
n = len(triangle)
f = [0] * n
f[0] = triangle[0][0]
for i in range(1, n):
f[i] = f[i - 1] + triangle[i][i]
for j in range(i - 1, 0, -1):
f[j] = min(f[j - 1], f[j]) + triangle[i][j]
f[0] += triangle[i][0]
return min(f)
198.打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1]
输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入:[2,7,9,3,1]
输出:12
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
解题思路:
经典动态规划
动态规划解题四步骤
- 定义子问题
- 写出子问题的递推关系
- 确定 DP 数组的计算顺序
- 空间优化(可选)
class Solution(object):
def rob(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
# 动态规划
# 子问题:f[k]偷前k个房子最高偷窃金额
# 初始值:f[0]=0 f[1]=nums[0]
# 转态转移: f[k]=max(f[k-1],f[k-2]+num[k-1])
n = len(nums)
f = [0] * (n + 1)
f[1] = nums[0]
for i in range(2,n + 1):
f[i] = max(f[i - 1], f[i - 2] + nums[i - 1])
return f[n]
# 动态规划空间优化
# 由于计算只用到了f[i - 1], f[i - 2],因此只保存改两个值即可
prev = 0
curr = 0
# 每次循环,计算“偷到当前房子为止的最大金额”
for i in nums:
# 循环开始时,curr 表示 dp[k-1],prev 表示 dp[k-2]
# dp[k] = max{ dp[k-1], dp[k-2] + i }
prev, curr = curr, max(curr, prev + i)
# 循环结束时,curr 表示 dp[k],prev 表示 dp[k-1]
return curr