AbutionGraph是图特摩斯自研的时序图数据库,它可以满足永不掉线的实时知识图谱指标计算任务以及历史数据分析,静态图+动态图+时序图同时存储。在面向大规模在线场景时,使用Flink技术做ETL的同时,保证数据接入更稳定且无丢失。 目录: 1. 测试目的 2. 业务场景 3. 测试过程 4. AbutionGraph v.s Hbase
1. 测试目的
测试AbutionGraph单节点实时读写TPS的极值,确定AbutionGraph实时读写性能。 测试 AbutionGraph在低核数低内存环境下持续运行的稳定性 。
2. 测试环境
2.1 硬件信息
| 机器 |
小米笔记本Pro |
| CPU |
8核 Intel® Core™ i7-8550U CPU @ 1.80GHz |
| RAM |
8G(除去使用谷歌浏览器、IDEA代码编辑器、文件浏览器、文本编辑器所占内存剩余) |
2.2 软件信息
| 计算机系统 |
Linux Ubuntu18.04 |
| JDK |
1.8u211 |
| AbutionGraph |
1.0.2 |
| Flink |
1.9.1 |
| RocketMQ |
4.5.2 |
| Hadoop |
3.2.1 |
2.3 软件配置信息 Hadoop:单节点伪分布式部署 Flink:单节点嵌入式,程序使用单线程 RocketMQ:单节点同时部署 mqnamesrv 和mqbroker,各占用1G内存 AbutionGraph:单节点同时部署集群监控、资源监控、数据计算、RestAPI等服务
3. 模拟场景
一个在线交易系统,人与人的转账交易数据实时计算并存储。这是一种静态图+动态图的多维度图存储方式。
 图结构信息:
图结构信息: 实体“人”具有1个静态维度和1个动态维度数据: 1. 静态维度 BasicEntityPerson 具有
jymc (交易名称) 属性; 2. 动态维度SuperEntityPerson具有
zzPeople (转账过的人集合) 和
zzCount (转账过的人数) 属性,代表所有历史数据的实时汇总更新; 关系“交易”具有1个静态维度和1个时序维度数据: 1. 静态维度BasicEdgeJiaoYi保存交易的基本信息
jysj (交易时间) 和
jyje (交易金额) 2. 动态维度SuperEdgeJiaoYi具有
day (存储“年月日”为时序数据分区) 和
zje (两个人之间每天的历史交易金额实时汇总计算并存储) 属性。
实时数据样本: 
数据字段:行标,(汇款人,汇款人名称,被汇款人,被汇款人名称,汇款日期,汇款金额)
4. 测试过程
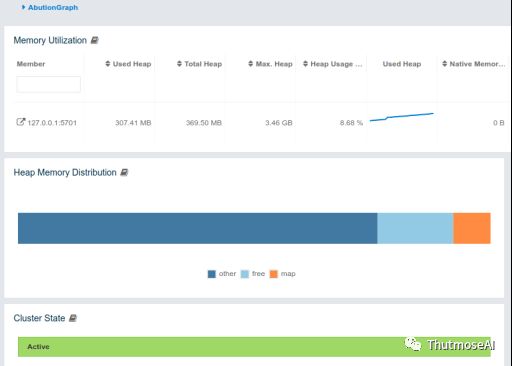
24小时不间断: 数据生产(RocketMQ)-->数据消费(Flink)-->数据入库(Flink)-->AbutionGraph-->数据查询 所有的大数据技术软件都启动在笔记本上,AbutionGMS资源监控系统与Linux系统自带监控(剩余内存一致)附图:

4.1 数据生产
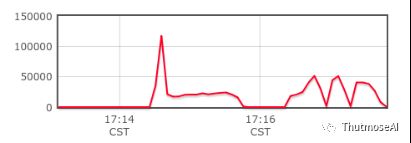
单线程中每秒生产200~6w条数据并不定时写入 AbutionGraph 。数据生产程序将在IDEA中持续运行。
RocketMQ数据生成核心代码:
DefaultMQProducer producer = new DefaultMQProducer("p004");producer.setNamesrvAddr("localhost:9876");try { producer.start();} catch (MQClientException e) { e.printStackTrace();}for (int i = 0; i < 200000000; i++) { Random random = new Random(); DecimalFormat b20 = new DecimalFormat("00"); DecimalFormat b50 = new DecimalFormat("00000"); String num1 = b50.format(random.nextInt(99999)); String num2 = b50.format(random.nextInt(99999)); String data = num1+",ID_"+num1+ "," +num2+",ID_"+num2 + ",2020-"+b20.format(random.nextInt(11)+1)+"-"+b20.format(random.nextInt(30)+1)+" " + b20.format(random.nextInt(24))+":"+b20.format(random.nextInt(59))+":"+b20.format(random.nextInt(59))+"," + random.nextInt(100)+".0"; Message msg = new Message("flink-source", "", "id_" + i, data.getBytes()); try { producer.send(msg); } catch (Exception e) { e.printStackTrace(); } System.out.println("["+i+"]: "+ data); try { Thread.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }}
4.2 数据消费
数据采用不定时长间隔消费,以制造真实环境中的突然大流量峰值。我们使用大数据技术Flink实时接入数据(AbutionGraph接口)并做一定数据处理,将接收到的每一条数据拆分为 3个实体(源点/终点/实时统计的源点)2条关系(静态数据边/实时统计的动态边) ,即将1条原始数据扩展为5条图数据同时入库,并对原始数据中的字段处理成指定的数据类型,如将字符串日期处理成Date格式并存储到AbutionGraph。
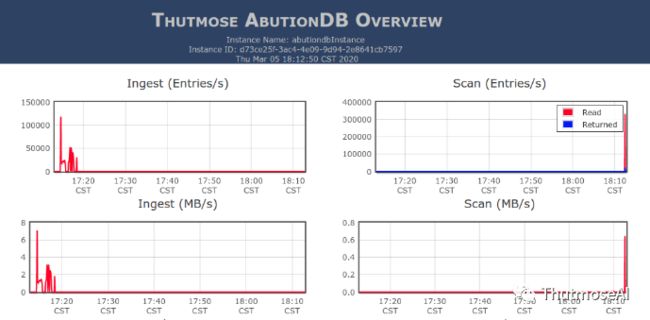
4.3 数据入库
数据入库的分别对 3个静态维度+1个时序维度的图(即常见的数据图谱+1个时序属性) 和 2个静态维度+2个动态维度的图(即常见的数据图谱+1个动态维度和1个时序维度图属性随数据流入而实时计算并更新) 进行性能测试。
静态+时序测试图:
(2个静态实体维度、1个静态关系维度、1个时序关系维度) 高峰入库过程,使用RocketMQ每秒生成1k数据,使用Flink不定间隔时长消费RocketMQ中的数据并导入AbutionGraph。图内已存在数据量>9千万,且持续入库,系统健康运行>3天(同时开网页优酷看电影)。
实时入库峰值:17w/s 
静态+动态+时序测试图:
(1个静态实体维度、1个动态实体维度、1个静态关系维度、一个时序关系维度) 高峰入库过程,使用RocketMQ每秒不定间隔生成1k或1w数据,使用Flink不定间隔时长导入数据到AbutionGraph。图内已存在数据量>5千万,且持续入库。
实时入库峰值:17w/s 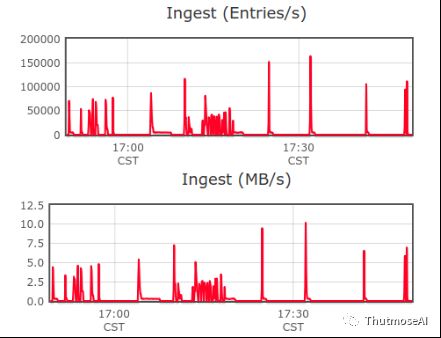
当数据过亿之后:
实时入库峰值:15w/s 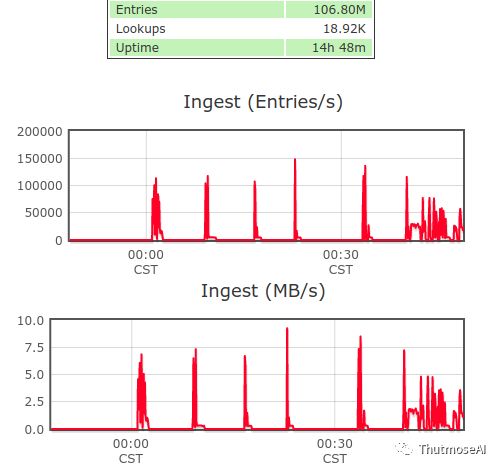 总结:
总结: 动态指标维度需要根据历史数据进行实时计算并取库,随着动态维度的增加,不会因此降低写入速率,两个测试图写入速率基本保持一致,最高峰值都达到了惊人的17w/s。
4.3 数据查询
使用1.3亿数据图,因为笔记本剩余空间是3.5G,可用内存只有不到1G,所以在此不做大量查询。
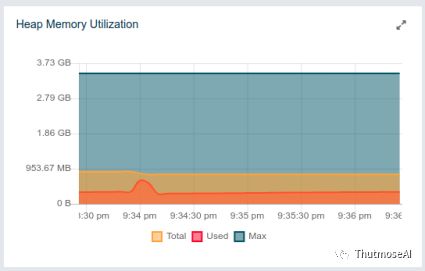
1跳查询(查询实体 "62016" ):多毫秒内返回252条数据 2跳查询(查询实体 "62016" ):1s/并返回可视化数据502条 3跳查询(查询实体 "62016" ):1.4s/并返回可视化数据9638条(下图最短的蓝柱状) 6跳查询(查询实体 "62016" ):22s/并返回可视化数据38991条(下图最长的后2根蓝柱状)
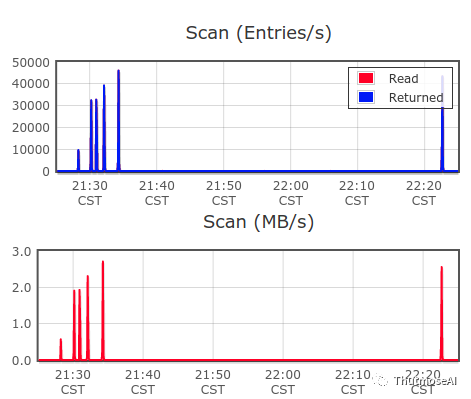
Ps:一般的图库在亿级数据已经很难完成6跳的查询了,因为多跳数据查询不涉及属性的过滤操作,所以不需要大规模的数据扫描操作即可快速定位到数据。 我们来看看扫描全部数据,过滤出每天交易金额大于100元的边(由于可用内存原因做了条数限制):
 扫描速率:20w/s
扫描速率:20w/s 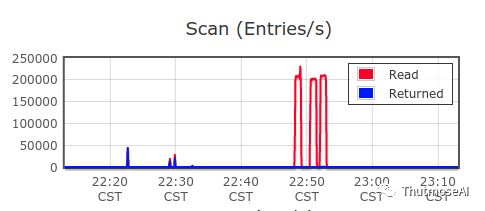
5. AbutionGraph v.s Hbase
为了体现对比权威性,我们使用Hbase技术社区发布的测试报告,且为目前Hbase最高的2.2版本。该Hbase测试结果也为全网的最高水平,网络查找到的一些测试报告可能因为版本和配置不同要远低于此水平。
| 指标\技术 |
AbutionGraph |
Hbase |
| CPU |
8核 |
112核 |
| RAM |
8G(可用4G) |
312G |
| 网络 |
公用WIFI |
网易内网 |
| 操作系统 |
Ubuntu |
Debian |
| 实例数 |
1个 |
4个 |
| 单节点稳定吞吐 |
13w/s |
3.5w/s(集群14w/s) |
| 单节点最高峰值 |
17w/s |
3.5w/s(集群14w/s) |
| 测试时间 |
2020.03 |
2020.01 |
对比文章: HBase 2.2随机读写性能测试: https://thutmose.blog.csdn.net/article/details/104554739 Cassandra3.11读写性能测试(6台集群6w/s): https://thutmose.blog.csdn.net/article/details/104670119
6. 总结
本测试可能是有史以来配置最低的大数据技术性能测试了,结果比较令人欣喜,期间查看日志信息可以看到好几次警告内存过低,但整套大数据生态系统都还能稳定的运行下去,性价比很高。在此测试中使用的Flink并没有启动,而是使用AbutionGraph接口中嵌入式的方式运行,集群模式下性能更佳。业务合作与技术人才投递 邮箱:
[email protected]