Docker实现资源隔离和资源限制的方法
Docker 容器是一个开源的应用容器引擎,让开发者可以以统一的方式打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何安装了docker引擎的服务器上(包括流行的Linux机器、windows机器),也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app)。几乎没有性能开销,可以很容易地在机器和数据中心中运行。最重要的是,他们不依赖于任何语言、框架包括系统。Docker中文社区

Docker资源划分图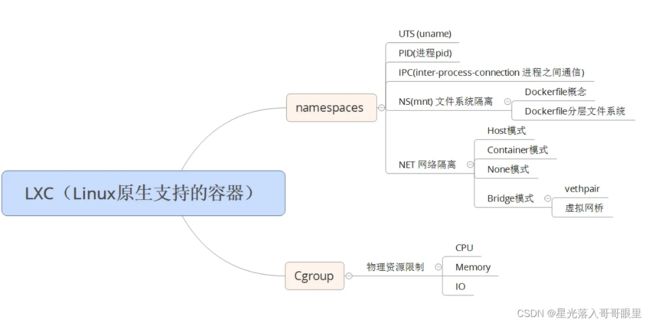
NameSpace资源隔离
Linux Namespaces机制提供一种资源隔离方案。PID,IPC,Network等系统资源不再是全局性的,而是属于某个特定的Namespace。这是一种轻量级的虚拟化形式,用来隔离各个容器!
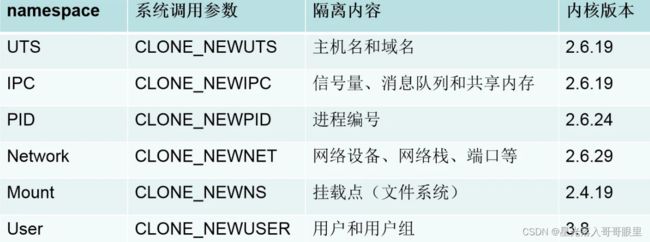
pid namepaces:不同用户的进程是通过namepaces隔离开的,且不同的namepaces中可以有相同的pid。
net namepaces:网络隔离是通过net namepaces实现的,每个net namepaces都有独立的network。
ipc namepaces:Containter中进程交互是采用linux常见的进程交互方法。
mnt namepaces:本身允许不同namepaces的进程看到的文件结构不同,使用mnt namepaces中的进程所看到的文件目录就被隔离开了。
uts namepaces:允许每个container拥有独立的hostname和domain name,使其在网络上可以被作视一个独立的节点而非host上的一个进程。
user namepaces:每个container可以有不同的user和group id,也就是说可以在container内部用container内部的用户执行程序而非host上的用户。
[root@localhost ~]# ss -anput | grep httpd
tcp LISTEN 0 128 :::80 :::* users:(("httpd",pid=7384,fd=4),("httpd",pid=7383,fd=4),("httpd",pid=7382,fd=4),("httpd",pid=7381,fd=4),("httpd",pid=7380,fd=4),("httpd",pid=7379,fd=4))
[root@localhost ~]# cd /proc/7382/
[root@localhost 7382]# cd ns/
[root@localhost ns]# ll
总用量 0
lrwxrwxrwx. 1 root root 0 10月 19 15:08 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 10月 19 15:08 mnt -> mnt:[4026532624]
lrwxrwxrwx. 1 root root 0 10月 19 15:08 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 10月 19 15:08 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 10月 19 15:08 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 10月 19 15:08 uts -> uts:[4026531838]
[root@localhost ns]# ll ../../2/ns 进程2目录中内容基本相同,只不过7382目录里多个lrwxrwxrwx··· exe -> /usr/sbin/httpd
···(数值相等表示在同一个空间内就有可能资源冲突,但是mnt数值不同表示不在同一个空间内)
[root@localhost ns]# cd
准备脚本
使用C语言脚本来实现验证:
[root@localhost ~]# vim test.c //此脚本中包含4个隔离项,所以下面的只是换了下名字而已(本来是分开的,我却合在一起了)
#define _GNU_SOURCE
#include 验证
(1)UTS主机名
[root@localhost ~]# gcc -Wall test.c -o ust.o
-Wa,<选项> 将逗号分隔的 <选项> 传递给汇编器
-Wp,<选项> 将逗号分隔的 <选项> 传递给预处理器
-Wl,<选项> 将逗号分隔的 <选项> 传递给链接器
[root@localhost ~]# ./ust.o
程序开始:
在子进程中!
[root@Change Names ~]# hostname
Change Names
[root@Change Names ~]# exit
(2)IPC消息队列
[root@localhost ~]# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
[root@localhost ~]# ipcs
···
[root@localhost ~]# gcc -Wall test.c -o ipc.o
[root@localhost ~]# ./ipc.o
程序开始:
在子进程中!
[root@Change Names ~]# ipcs
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
------------ 共享内存段 --------------
键 shmid 拥有者 权限 字节 nattch 状态
--------- 信号量数组 -----------
键 semid 拥有者 权限 nsems
[root@Change Names ~]# ipcmk -Q //创建消息队列
消息队列 id:0
[root@Change Names ~]# ipcs -q //显示活动的消息队列信息
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
0xe419cda4 0 root 644 0 0
[root@Change Names ~]# exit
exit
已退出
[root@localhost ~]# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
(3)PID进程号
每个企业版7中的第一个进程都要等于1,特殊权限,负责开启所有进程
[root@localhost ~]# pstree -p //发现进程systemd(1)
[root@localhost ~]# gcc -Wall test.c -o pid.o
[root@localhost ~]# ./pid.o
[root@Change Names ~]# echo $$
1
[root@Change Names ~]# ls /proc/
1 2 272 2877 2963 3041 396 ···
[root@Change Names ~]# exit
[root@localhost ~]# echo $$
7279
(4)mount隔离
pid编号被改变,但是/proc/目录没有改变,需要两边变成私有挂载
四种挂载方式:
主从挂载:master影响salve,salve不影响master
共享挂载:互相影响
私密挂载:private互不影响
不可绑定的挂载:unbindable
[root@localhost ~]# man mount "内容在下面"
[root@localhost ~]# ps aux | head -2
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.1 0.5 46080 5152 ? Ss 19:12 0:02 /usr/lib/systemd/systemd --system ···
[root@localhost ~]# ls /proc/ //查看主机中proc伪进程文件夹中的内容
1 2 272 2877 2963 3041 396 ···
[root@localhost ~]# gcc -Wall test.c -o ns.o
[root@localhost ~]# ./ns.o
程序开始:
在子进程中!
[root@Change Names ~]# ls /proc/
1 2 272 2877 2963 3041 396 ···
[root@Change Names ~]# mount --make-private -t proc proc /proc/ //私有挂载
[root@Change Names ~]# mount | tail -1
proc on /proc type proc (rw,relatime)
[root@Change Names ~]# ls /proc/
1 cmdline driver ioports kpagecount modules sched_debug swaps uptime
[root@Change Names ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 116756 3436 pts/1 S 19:34 0:00 /bin/bash
root 44 0.0 0.1 151056 1812 pts/1 R+ 19:35 0:00 ps aux
[root@Change Names ~]# pstree
bash───pstree
[root@Change Names ~]# exit
[root@localhost ~]# ls /proc/
[root@localhost ~]# pstree
/proc 是空的 (未挂载?)
[root@localhost ~]# mount --make-private -t proc proc /proc
[root@localhost ~]# mount |tail -2
proc on /proc type proc (rw,relatime)
proc on /proc type proc (rw,relatime)
[root@localhost ~]# pstree | head -2
systemd-+-ModemManager---2*[{ModemManager}]
|-NetworkManager---2*[{NetworkManager}]
[root@localhost ~]# ./ns.o
···每次进入都需要重新挂载才能解决
共享子树 “当使用--make-*指令时并不会读取 fstab,挂载所必须的参数都必须在命令行给出”
mount 命令 [-t 文件系统] [-L 卷标名] [-o 特殊选项] 设备文件名 挂载点
可以为一个挂载点(可以包含子挂载点)设置传播类型标记(shared, private, slave, unbindable)。
shared 表示允许创建镜像,一个镜像内的挂载和卸载操作会被自动传播到所有其他镜像中。
slave 表示自动继承主挂载点中挂载和卸载操作,但是自身的挂载和卸载操作不会反向传播到主挂载点中。
private 表示既不继承主挂载点中挂载和卸载操作,自身的挂载和卸载操作也不会反向传播到主挂载点中。
unbindable 表示禁止对该挂载点进行任何绑定(--bind|--rbind)操作。
详见 Documentation/filesystems/sharedsubtree.txt 文档。
支持的操作:
mount --make-shared mountpoint
mount --make-slave mountpoint
mount --make-private mountpoint
mount --make-unbindable mountpoint
NamespacePID被隔离后产生哪些问题(是什么原因导致的进程无法使用(1号进程无法使用))?
Namespace隔离时把PID隔离,namespace中的PID编号会重新统计,但是/proc设备中的内容没有发生改变,使用mount --make-private解决/proc设备的隔离问题发现/proc设备中的目录被改变,此时1号进程已经是非systemd\init。导致无法启动systemd管理程序(容器内1号进程此时为/bin/bash没有systemd特殊权限)
(5)提权操作
yum安装的程序无法启动,因为/bin/bash没有权限启动; 不安全,提权操作会把虚拟机变成root并把宿主机锁住
docker run -itd --name httpd centos:7
docker exec -it httpd /bin/bash
yum -y install httpd
[root@537ce4827db8 /]# systemctl restart httpd
Failed to get D-Bus connection: Operation not permitted
解决方法:
[root@localhost ~]# ll /sbin/init init应用于Centos6,systemd应用于Centos7
lrwxrwxrwx. 1 root root 22 4月 17 2020 /sbin/init -> ../lib/systemd/systemd
[root@localhost ~]# docker run --restart always -d --name new --privileged centos:7 /sbin/init【强制1号进程为init】
docker exec -it new /bin/bash
yum -y install httpd &>/dev/null
systemctl start httpd
[root@localhost ~]# docker rm -f new
解释:
通过--restart选项,可以设置容器的重启策略,以决定在容器退出时Docker守护进程是否重启刚刚退出的容器。
Docker容器的重启都是由Docker守护进程完成的,因此与守护进程息息相关。
Docker容器的重启策略如下:
no 默认策略,在容器退出时不重启容器
on-failure 在容器非正常退出时(退出状态非0),才会重启容器
on-failure:3 在容器非正常退出时重启容器,最多重启3次
always 在容器退出时总是重启容器
unless-stopped 在容器退出时总是重启容器,但是不考虑在Docker守护进程启动时就已经停止了的容器
通过--privileged选项,决定是否让docker应用容器 获取宿主机root权限(特殊权限-),否则container内的root只是外部的一个普通用户权限。
(6)网络隔离
将物理机和容器连在一起
实验目的:实现不同网段的虚拟空间进行通信[跨网段通信需要网关]
1.创建两个虚拟空间
[root@localhost ~]# ip netns add ns1 #ns1是第一个虚拟空间
[root@localhost ~]# ip netns add ns2 #ns2是第二个虚拟空间
[root@localhost ~]# ip netns exec ns1 ip a #在指定的网络命名空间中执行命令
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1(因为处于down状态)
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@localhost ~]# ip netns exec ns1 ping 127.0.0.1
connect: 网络不可达
2.开启两个虚拟空间的回环地址
[root@localhost ~]# ip netns exec ns1 ip link set dev lo up
[root@localhost ~]# ip netns exec ns2 ip link set dev lo up
[root@localhost ~]# ip netns exec ns1 ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.066 ms
3.创建第一个虚拟空间并指定虚拟空间网卡(本地网卡+虚拟空间网卡)veth-pair是一对的虚拟网络设备接口,成对出现,所以它常常充当着一个桥梁
[root@localhost ~]# ip link add v1 type veth peer name v2 #本地网卡为v1,虚拟空间网卡为v2(此时物理机会多出两块网卡)
[root@localhost ~]# ip link set v2 netns ns1 #为虚拟空间指定虚拟空间网卡
netns NETNSNAME|PID:将设备移至与名称NETNSNAME关联的网络名称空间或处理PID
[root@localhost ~]# ip link show #显示网络接口信息(会看不到v2网卡,因为它已经加入到ns1中了)
[root@localhost ~]# ip netns exec ns1 ip a
6: v2@if7: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 92:76:1b:58:2e:2f brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@localhost ~]# ip a
7: v1@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 9e:54:fd:34:07:4c brd ff:ff:ff:ff:ff:ff link-netnsid 0
Linux 提供了 veth pair。可以把veth pair当做是双向的 pipe(管道),从一个方向发送的网络数据,可以直接被另外一端接收到;或者也可以想象成两个 namespace 直接通过一个特殊的虚拟网卡连接起来,可以直接通信。
4.为第一个虚拟空间网卡配置IP/本地ip/网关
[root@localhost ~]# ip netns exec ns1 ifconfig v2 10.1.1.2/24 up #虚拟空间网卡ip
[root@localhost ~]# ifconfig v1 10.1.1.1/24 up #虚拟空间本地网卡ip
[root@localhost ~]# ip netns exec ns1 route add default gw 10.1.1.1 #虚拟空间网卡网关
5.创建第二个虚拟空间并指定虚拟空间网卡(本地IP,虚拟空间的ip)
[root@localhost ~]# ip link add v3 type veth peer name v4 #本地网卡为v3,虚拟空间网卡为v4
[root@localhost ~]# ip link set v4 netns ns2 #为虚拟空间指定虚拟空间网卡
6.为第二个虚拟空间网卡配置IP/本地ip/网关
[root@localhost ~]# ip netns exec ns2 ifconfig v4 20.1.1.2/24 up
[root@localhost ~]# ifconfig v3 20.1.1.1/24
[root@localhost ~]# ip netns exec ns2 route add default gw 20.1.1.1
7.开启本地路由转发功能
[root@localhost ~]# sysctl -p
net.ipv4.ip_forward = 1
8.验证"命名空间中的网络隔离是把防火墙iptables和路由表彻底隔离"
[root@localhost ~]# ip netns list //列出网络命名空间。此命令显示的是 “/var/run/netns” 中的所有网络命名空间。
ns2 (id: 1)
ns1 (id: 0)
》用第一个虚拟空间去ping第二个虚拟空间
[root@localhost ~]# ip netns exec ns1 ping 20.1.1.2
PING 20.1.1.2 (20.1.1.2) 56(84) bytes of data.
64 bytes from 20.1.1.2: icmp_seq=1 ttl=63 time=0.048 ms
》用第二个虚拟空间去ping第一个虚拟空间的IP
[root@localhost ~]# ip netns exec ns2 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=63 time=0.139 ms
》用宿主机可以去ping通20.1.1.2与10.1.1.2都是可以通信的(Netns虚拟网络空间的网络通讯依赖于物理接口)
[root@localhost ~]# ip netns exec ns1 ip a
8: v2@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether fa:4b:a0:2b:3d:c3 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.1.1.2/24 brd 10.1.1.255 scope global v2
valid_lft forever preferred_lft forever
···
[root@localhost ~]# ip netns exec ns2 ip a
[root@localhost ~]# route //可以看到网段所对应的网卡Iface
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
20.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 v3
[root@localhost ~]# ip route //网关隔离
···
10.1.1.0/24 dev v1 proto kernel scope link src 10.1.1.1
20.1.1.0/24 dev v3 proto kernel scope link src 20.1.1.1
169.254.0.0/16 dev ens33 scope link metric 1002
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
[root@localhost ~]# ip netns exec ns1 route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default gateway 0.0.0.0 UG 0 0 0 v2
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 v2
netns是在linux中提供网络虚拟化的一个项目,使用netns网络空间虚拟化能够在本地虚拟化出多个网络环境,目前netns在容器中被用来为容器提供网络。linux使用netns建立的网络空间独立于当前系统的网络空间,其中的网络设备以及iptables规则等都是独立的,就好像进入了另一个网络一样。
SSH远程
在使用Docker运行容器的时候避免不了要使用systemd程序。 容器中的服务配置文件统一存放在:/usr/lib/systemd/system目录下
1.启动容器并安装相应的依赖工具
docker run -itd --name sshd centos:7
docker exec -it sshd /bin/bash
yum -y install passwd iproute openssh-server openssh-clients net-tools vim
echo 123.com | passwd root --stdin //给容器中root设置密码
[root@1599722ca9aa /]# cat /usr/lib/systemd/system/sshd.service
9 EnvironmentFile=/etc/sysconfig/sshd //变量文件
10 ExecStart=/usr/sbin/sshd -D $OPTIONS //启动文件
[root@1599722ca9aa /]# /usr/sbin/sshd -D //发现启动sshd服务需要主机密钥; -D以非后台守护进程方式运行服务器
Could not load host key: //elp
Could not load host key: /etc/ssh/ssh_host_rsa_key
Could not load host key: /etc/ssh/ssh_host_ecdsa_key
Could not load host key: /etc/ssh/ssh_host_ed25519_key
sshd: no hostkeys available -- exiting.
2.生成秘钥值
-q:静默显示 -b:指定密钥长度 -f:指定用来保存密钥的文件名 -N:指定生成密钥公钥对的密码
[root@1599722ca9aa /]# cat /etc/sysconfig/sshd
[root@1599722ca9aa /]# ssh-keygen -q -t rsa -b 2048 -f /etc/ssh/ssh_host_rsa_key -N ''
[root@1599722ca9aa /]# ssh-keygen -q -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N ''
[root@1599722ca9aa /]# ssh-keygen -q -t ed25519 -f /etc/ssh/ssh_host_ed25519_key -N ''
[root@1599722ca9aa /]# ls /etc/ssh/
moduli ssh_host_ecdsa_key ssh_host_ed25519_key ssh_host_rsa_key sshd_config
ssh_config ssh_host_ecdsa_key.pub ssh_host_ed25519_key.pub ssh_host_rsa_key.pub
[root@1599722ca9aa /]# cat /etc/ssh/ssh_host_rsa_key
···
3.编辑主配置文件
[root@1599722ca9aa /]# vim /etc/ssh/ssh_config
96 #UsePAM yes //是否通过PAM验证 PAM:热插拔安全模块【默认本地计算机走的所有认证都是PAM认证】
109 UsePrivilegeSeparation no//是否让 sshd 通过创建非特权子进程处理接入请求的方法来进行权限分离。默认值是"yes"。认证成功后,将以该认证用户的身份创建另一个子进程。这样做的目的是为了防止通过有缺陷的子进程提升权限,从而使系统更加安全。
38 PermitRootLogin yes //是否允许root用户远程登录[限制的比较粗略,without-password在yes的基础上,禁止了root用户使用密码登陆]
[root@1599722ca9aa /]# /usr/sbin/sshd
[root@1599722ca9aa /]# ss -anput | grep sshd
tcp LISTEN 0 128 *:22 *:* users:(("sshd",pid=141,fd=3))
tcp LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=141,fd=4))
[root@1599722ca9aa /]# ip a
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
[root@1599722ca9aa /]# exit
exit
4.验证
[root@localhost ~]# ssh [email protected]
yum -y install httpd &>/dev/null
httpd
echo 1 >/var/www/html/index.html
[root@1599722ca9aa ~]# curl 172.17.0.2
1
Cgroup资源限制
Cgroup的内核通过hook钩子来实现管理进程资源,提供了一个统一的接口,从单个进程的资源控制到操作系统层面的虚拟卡的过渡!

[root@localhost ~]# yum -y install libcgroup-tools
[root@localhost ~]# lscgroup #列出当前计算机当中有效的cgroup有哪些
[root@localhost ~]# lssubsys #列出包含指定子系统的层次结构
[root@localhost ~]# lssubsys -m #所在目录具体内容[-m:显示挂载点]
[root@localhost ~]# cd /sys/fs/cgroup/
[root@localhost cgroup]# ls [subsystem的控制选项如下]
blkio cpuacct cpuset freezer memory net_cls,net_prio perf_event systemd
cpu cpu,cpuacct devices hugetlb net_cls net_prio pids
解释:
blkio: 可以为块设备设置输入和输出限制(能存储数据的外界设备,比如光盘,u盘,硬盘)
CPU: 控制程序对cpu的使用
cpuacct:生成cpu使用情况报告
cpuset: 可以为cgroup中的task独立分配CPU
freezer:挂起和恢复task
memory: 内存用量进行限制,并且生成报告
perf_event:统一的性能测试
devices:开启关闭对设备的访问(设备不仅仅包括块设备,所有的设备都算)
hugetlb:暂时和启用
net_cls,net_prio:没有直接被使用,给网络数据打标签
net_cls:标记网络
net_prio 网络跟踪
pids: 暂时没有使用,限制单一的PID运行
systemd:系统资源(进程)
CPU的优先级意义和作用
root@localhost ~]# docker run -itd centos:7 /bin/bash
de901cc5d5277a3158c3d8de993c85bc727d3d412bda898a2f7cd615ead89bdc
[root@localhost ~]# cd /sys/fs/cgroup/cpu/docker/
[root@localhost docker]# ls
de901cc5d5277a3158c3d8de993c85bc727d3d412bda898a2f7cd615ead89bdc ···
[root@localhost docker]# cd de901cc5d5277a3158c3d8de993c85bc727d3d412bda898a2f7cd615ead89bdc/
[root@localhost de901cc5d5277a3158c3d8de993c85bc727d3d412bda898a2f7cd615ead89bdc]# cat cpu.shares
1024
[root@localhost de901cc5d5277a3158c3d8de993c85bc727d3d412bda898a2f7cd615ead89bdc]# echo 512 >cpu.shares
[root@localhost de901cc5d5277a3158c3d8de993c85bc727d3d412bda898a2f7cd615ead89bdc]# cd
[root@localhost ~]# docker run --name testA -itd -c 1024 centos:7 /bin/bash
45da53a9e23cdcfa3390e7ab027dc7d4d58d71be35ca88191f0c1d033e5f9e26
[root@localhost ~]# docker run --name testB -itd -c 512 centos:7 /bin/bash
0dca272ef6aafb89f5211d49c4478fc78f083a2dce4616a248d2e7ad0c739548
[root@localhost ~]# cd /sys/fs/cgroup/cpu/docker/45da53a9e23cdcfa3390e7ab027dc7d4d58d71be35ca88191f0c1d033e5f9e26/
[root@localhost 45da53a9e23cdcfa3390e7ab027dc7d4d58d71be35ca88191f0c1d033e5f9e26]# cat cpu.shares >修改文件立即生效
1024
[root@localhost ~]# docker search stress
[root@localhost ~]# docker pull progrium/stress 下载完后关机,把虚拟机改为单核单线程
[root@localhost ~]# docker run -itd --name aa --cpu-shares 512 progrium/stress --cpu 1 //按权重比例设定CPU的分配
另开终端:
[root@localhost ~]# docker run -itd --name bb --cpu-shares 1024 progrium/stress --cpu 1
在打开终端:
[root@localhost ~]# top //cpu就会出现一个是另一个一倍的情况,停止一个终端,另一个就会占领
top - 17:48:32 up 24 min, 4 users, load average: 2.17, 0.95, 0.68
Tasks: 182 total, 3 running, 179 sleeping, 0 stopped, 0 zombie
%Cpu(s): 99.7 us, 0.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 999936 total, 80216 free, 495376 used, 424344 buff/cache
KiB Swap: 2097148 total, 1839204 free, 257944 used. 252552 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7633 root 20 0 7308 100 0 R 64.3 0.0 0:23.76 stress
7558 root 20 0 7308 100 0 R 32.0 0.0 0:39.91 stress
[root@localhost ~]# docker ps -a
[root@localhost ~]# docker rm -f $(docker ps -qa)
cgroup控制项
SubSystem的控制选项
cpuset 为cgroup中的task分配独立cpu和内存
cpu 调度程序控制task对CPU的使用
cpuacct 自动生成CPU资源使用情况报告
memory 对内存用量的使用限制,同时可以生成硬件报告
devices 开启/关闭cgroup中task对设备的访问
freezer 挂起/恢复cgroup中的task
net_cls,net_prio 没有被直接使用。通过等级识别符号(classid)标记网络数据,从而控制流量
blkio 为块设备设定输入或输出的限制
perf-event 统一的性能测试。
hugetlb 没有被启用。
pids 单独对某个pid进行限制。
docker命令行限制内容
-c/--cpu-shares 限制优先级,默认值是1024。设置容器使用CPU共享权值(相对权重)
--cpu 用来设置工作线程的数量
-m/--memory 限制内存的使用额度
--memory-swap 限制内存+swap的大小(默认这两个值为-1,表示没有限制)
--blkio-weight 权重限制
Bps 每秒读取的数据量
Iops 每秒读写数据次数
--device-read-bps 限制此设备上的读速度(bytes per second)
--device-write-bps 限制此设备上的写速度(bytes per second)
--device-read-iops 通过每秒读IO次数来限制指定设备的读速度。
--device-write-iops 通过每秒写IO次数来限制指定设备的写速度。
-blkio-weight 容器默认磁盘IO的加权值,有效值范围为10-100
-blkio-weight-device 针对特定设备的IO加权控制。其格式为DEVICE_NAME:WEIGHT
内存限制
[root@localhost ~]# docker run -itd --name qq -m 200M --memory-swap=300M centos:7 /bin/bash
设置物理内存200M swap100M
-m :限制内存使用额度
--memory-swap:内存+swap使用额度(如果不设置swap大小则大小等于内存大小)
[root@localhost ~]# free -m
[root@localhost ~]# docker rm -f qq
如何超出300就直接kill掉:
[root@localhost ~]# docker run -it -m 200M --memory-swap=300M progrium/stress --vm 1 --vm-bytes 280M
--vm 1:启动 1 个内存工作线程
--vm-bytes 280M:每个线程分配 280M 内存
stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: dbug: [1] using backoff sleep of 3000us
stress: dbug: [1] --> hogvm worker 1 [7] forked
stress: dbug: [7] allocating 293601280 bytes ...
stress: dbug: [7] touching bytes in strides of 4096 bytes ...
stress: dbug: [7] freed 293601280 bytes
stress: dbug: [7] allocating 293601280 bytes ...
stress: dbug: [7] touching bytes in strides of 4096 bytes ...
[root@localhost ~]# docker run -it -m 200M --memory-swap=300M progrium/stress --vm 1 --vm-bytes 380M #超过300会运行失败
···
stress: FAIL: [1] (416) <-- worker 7 got signal 9
stress: WARN: [1] (418) now reaping child worker processes
stress: FAIL: [1] (422) kill error: No such process
stress: FAIL: [1] (452) failed run completed in 1s
硬盘的限制
目前对硬盘不能彻底的限制,只能对硬盘读/写,每秒输入/输出进行限制。
[root@localhost ~]# docker run -it --name qq centos:7 /bin/bash
[root@7e70970506d4 /]# time dd if=/dev/zero of=test.out bs=1M count=800 oflag=direct
838860800 bytes (839 MB) copied, 2.17112 s, 386 MB/s
限制30M/S,然后测试读写速度:
[root@localhost ~]# docker run -it --rm --device-write-bps /dev/sda:30MB centos:7
[root@e601fe928148 /]# time dd if=/dev/zero of=test.out bs=1M count=800 oflag=direct
800+0 records in
800+0 records out
838860800 bytes (839 MB) copied, 27.0136 s, 31.1 MB/s
real 0m27.073s
user 0m0.002s
sys 0m1.236s
解释:
time 追踪一条命令的执行时间
bs=1M 每次读1M,一个block块的大小是1M
if(input file) 输入文件zero是特殊空文件
count 次数为800次
oflag 输入不走内存,直接读写硬盘(绕过磁盘页面缓存)
四大规则
task:系统进程PID subsystem:资源调度控制器 hierarchy:层级树,是通过cgroup排列而成的,加入subsystem从而实现限制,逻辑上把cg分类
规则一:同一个hierarchy可以附加一个或者多个subsystem
规则二:一个已经附加在某个hierarchy上的subsystem不能附加到其他含有别的subsystem的hierarchy
规则三:一个task不能属于同一个hierarchy的不同cgroup(以Cgroup为单位进行控制)
规则四:刚fork出来的子进程在初始状态与其父进程处于同一个Cgroup中
Docker新特性
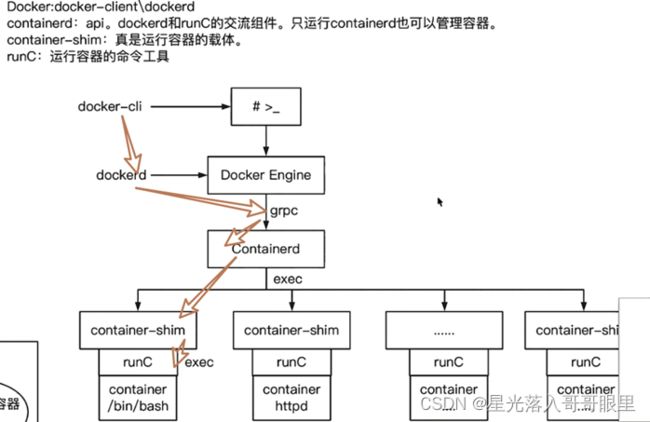
✔ dockerd 属于对容器相关操作的API接口的上层封装,直接面向用户(docker-client发送信息到docker engine)
✔ containerd dockerd实际调用的是ContainedAPI接口,调用方式为rpc。是dockerd和runC之间交流的组件,理论上不需要运行dockerd程序
✔ container-shim 真正运行容器的载体,每启动一个容器都会启动一个shim进程,通过三个参数容器ID,bind目录,runC指令来对引擎进行独立升级
✔ runC 是一套符合OCI标准的容器引擎;其是一个非常独立,真正创建容器的组件,runC可以独立于dockerd创建、操作容器,其功能和LXC等容器化工具类似;使用runC主要功能:创建、并启动标准化容器。
✔ RPC (Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务
✔ GRPC 是一个高性能、通用的开源RPC框架,基于HTTP/2协议标准和Protobuf序列化协议开发,支持众多的开发语言。
一个容器可以有多个container-shim进程; container-shim进程由containerd进程拉起,并持续存在到容器实例进程退出为止(两者是调用关系)
Success comes from frustration, satisfaction comes from love of work!