CCF ChinaSoft 2023 论坛巡礼|大模型与软件测试论坛
✦ +
+
论坛巡礼
论坛名称:大模型与软件测试论坛
时间:2023年12月01日14:00-17:40
地点:上海国际会议中心,5H会议厅
论坛简介:
人工智能预训练大模型在近两年成为了海内外科技前沿的热点话题,其自身的计算推理能力及在各行业领域内的应用层出不穷。一方面,研究人员利用大模型的理解能力,将其用于软件研发和软件测试等任务,取得了超前的效果;另一方面,大模型的安全性、可靠性等问题也受到越来越多的关注,如何对大模型进行测试也是重要的研究问题。
本论坛分为“面向大模型的测试(Testing for LLM)”和“基于大模型的测试(Testing with LLM)”两个半场,邀请了国内学术界和企业界知名专家学者进行报告和讨论。期待各位来宾共聚一堂,就软件测试结合大模型方向来一场头脑风暴,共同推进相关领域的技术发展。
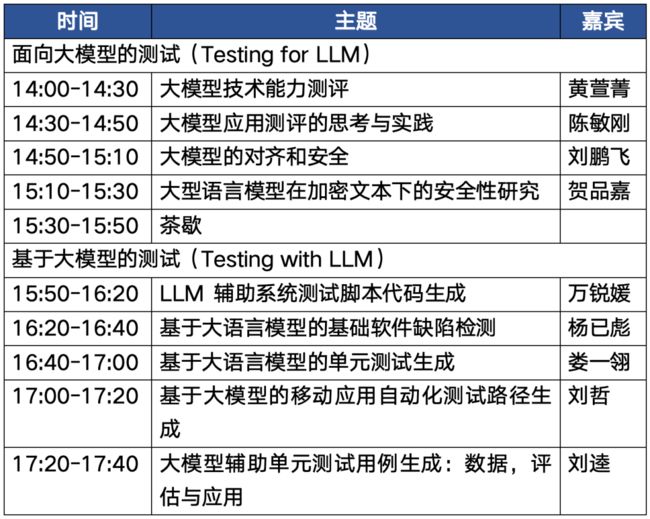
日程安排
Schedule
论坛主席
Forum Chair

蔡立志(上海计算机软件技术开发中心)
博士、研究员。上海计算软件技术开发中心主任、上海市技术带头人、上海市软件行业标兵、上海市第十届青联委员,上海市软件行业协会副会长。兼任上海计算机学会软件工程专业委员会主任、CCF软件工程委员会委员、上海软件质量管理和过程改进委员会副主任、华东理工大学兼职硕士生导师、全国信息技术标准化委员会委员、国际标准化组织ISO/IEC JTC1/SC7 中国专家代表等职务。长期从事软件质量、网络安全及人工智能应用测评的研究和技术服务。承担科技部现代服务业项目等项目或者课题10余项,获得发明专利授权10项,出版《软件测试导论》专著9本,审定和编撰《英汉云计算、物联网、大数据辞典》等4本,发表论文135篇,编制国际、国家、军工行业等各类标准118项,其中国际标准5项。

王俊杰(中国科学院软件研究所)
中国科学院软件研究所研究员,博士生导师,中国科学院特聘研究岗位,软件所杰出青年,主要从事智能化软件工程、软件质量等方面的研究,近年来主要关注移动应用测试、智能软件测试、众包测试等。在国际著名学术期刊/会议发表50余篇高水平学术论文,四次荣获ACM/IEEE杰出论文奖。主持和参与了多项国家自然科学基金项目、科技部重点研发计划、CCF-华为胡杨林基金等。担任CCF A类期刊TSE的副主编(Associate Editor),FSE、ICST、ICSE demo等的PC member,TSE、TOSEM、EMSE、AUSE等期刊的审稿人。

冯洋(南京大学)
研究方向为软件质量保障,具体研究课题包括复杂软件系统的质量保障技术,基于程序设计语言的软件质量保障等。近年来已发表相关论文40余篇,其中包括ICSE、FSE、ASE、ISSTA、TSE、TOSEM等CCF-A类期刊与会议发表学术论文20余篇,并于2022年ASE、2023年Internetware获杰出论文奖。申请发明专利多项,部分专利成果已经在百度、阿里、华为等知名软件公司转化;担任多个期刊审稿人及国际会议程序委员会成员。
论坛嘉宾
Forum Guests

黄萱菁(复旦大学)
复旦大学教授、国家级领军人才。主要从事人工智能、自然语言处理和信息检索研究。兼任中国中文信息学会理事、中国计算机学会自然语言处理专委会副主任、中国人工智能学会女科技工作者委员会副主任、计算语言学学会亚太分会副主席、亚太信息检索学会指导委员会委员。近年来承担了国家重点研发计划课题、国家自然科学基金等多个项目,在国际重要学术刊物和会议发表论文180余篇。获钱伟长中文信息处理科学技术奖、上海市优秀学术带头人、上海市育才奖、人工智能全球女性学者、福布斯中国科技女性等多项荣誉。
报告题目
大模型技术能力测评
摘要
随着ChatGPT的发布,国内外掀起了大模型研发的热潮,涌现了上百种开源和闭源的大模型。这些大模型在人们日常工作生活中发挥着越来越重要的作用,因此其技术能力测评变得越来越关键。不同于此前仅能完成单个任务的自然语言处理算法,大模型是一种单一模型可以执行多种复杂自然语言处理任务的技术。因此,此前针对单个任务进行评价的自然语言处理算法评估方法不能很好地适用于大模型测评。该报告将首先介绍大模型的基本技术与能力,之后以LLMEval为例,从评估体系、评估方法以及评测数据集构建等方面分享大模型的评测实践,并探讨大模型鲁棒性、幻觉现象、人格、多模态能力的测评思路。

陈敏刚(上海计算机软件技术开发中心)
上海计算机软件技术开发中心研究员、上海市计算机软件评测重点实验室副主任。主要从事人工智能应用技术及测评技术研究,担任ISO/IEC JTC1 SC42 国际人工智能标准工作组专家、上海市科技发展重点领域技术预见专家组专家、上海市人工智能地方标准委员会委员。三次荣获上海市科技进步奖,其中2020年度荣获上海市科技进步奖特等奖。在Pattern(Cell子刊)、ACM Multimedia、ECCV等重要期刊及会议上发表论文60余篇。获上海市五一劳动奖章、上海市科技系统工匠、上海市闵行区领军人才(上海领军人才“后备队”)、上海市闵行区春申金字塔杰出人才等多项誉。
报告题目
大模型应用测评的思考与实践
摘要
随着大模型技术的持续迭代演进,大模型的应用从通用聊天机器人拓展到医疗、金融、法律、政务等各应用领域。业界开始探索基于API与提示或基于LangChain框架的大模型应用开发方法。本报告将介绍基于大模型的AI应用测评方法,包括测试用例集生成、测试通过准则设计、自动化测试执行及回归测试等,并展示场景化大语言模型测评工具箱相关的研发与实践。

刘鹏飞(上海交通大学)
上海交通大学长聘教轨副教授,博士生导师。生成式人工智能研究组负责人,上海市领军人才 (海外青年);在自然语言处理和人工智能领域发表学术论文 70 余篇。谷歌学术引用 8900余次。ACL会议史上首次实现连续两年获得System & Demo Paper Award;提示工程(Prompt Engineering)概念最早提出者之一。曾获得中国人工智能学会优秀博士论文、上海市计算机学会优秀博士论文,百度奖学金,微软学者等。代表作包括:高数学推理大模型“阿贝尔”、LIMA等。曾与CMU教授教授联合创立AI模型评估与诊断公司。
报告题目
大模型的对齐和安全
摘要
随着生成式人工智能技术的快速发展,确保大模型与人类价值(意图)对齐(Alignment)已经成为行业的重要挑战。本报告将分享大模型价值对齐的必要性、基本方法和挑战,以及我们最新的一些研究进展。

贺品嘉(香港中文大学)
香港中文大学(深圳)助理教授,校长青年学者。博士毕业于香港中文大学,在苏黎世联邦理工学院任职博士后三年。研究方向为软件可靠性、软件测试、智能运维等。近年来在ICSE, FSE, CSUR等顶级会议期刊发表学术论文40余篇。获得ISSRE最有影响力论文奖,IEEE开源软件服务奖。谷歌学术引用超3700次。主导的自动化日志分析开源项目LogPAI在GitHub上被star 4000余次,并被450多个学界业界组织下载5万余次。他是期刊TOSEM的副主编,也在ICSE、FSE等会议担任程序委员会成员。
报告题目
大型语言模型在加密文本下的安全性研究
摘要
安全性是大型语言模型研究的核心课题之一。大模型在保留人性特征和个性化偏好的同时,已有广泛的研究尝试通过数据过滤、有监督的微调、从人类反馈中强化学习等方法,使其与人类的行为模式一致。本次报告将探讨一个有趣的发现:“加密对话”可以突破大模型的安全防护机制,触发有危害性的回复。基于此发现,我们将介绍一个全新的框架CipherChat,以测试大模型在非自然语言环境下的表现。使用CipherChat,用户可以利用加密的提示和角色说明与模型展开对话。我们研究了CipherChat在ChatGPT和GPT-4等前沿模型上的效果,涵盖了英文和中文下的11个安全领域。实验结果表明,特定的加密方式在绝大多数安全领域中都百分之百地突破了GPT-4的安全防护。此外,我们发现大模型“自带”一种加密方式SelfCipher。相比现有的加密方式,使用SelfCipher与大模型对话能更好地绕过其安全防护机制。

万锐媛(华为)
华为公司智能化测试C-TMG主任,研发工具测试技术专家。12年获清华大学EE博士学位,曾赴UC Berkeley EECS访问学者。16年加入华为至今,从事智能辅助测试技术探索、工程工具落地规划、设计,带领团队聚焦LLM&ML智能辅助测试设计、系统测试代码生成、 API接口全场景自主测试,多目标精准回归,测试失败智能定界&RCA等方向,成功孵化多项智能测试服务并规模落地应用,获得华为2012实验室总裁个人奖、金牌团队、光产品线总裁奖、数字能源总裁奖、研发工具领域总裁奖、软件工程能力提升总体组优秀个人等,多次获得华为海盗派重大测试技术突破奖。申请专利8项,已获5项,在ICSE、FSE等国际会议发表论文,担任ICST、ISSRE、QECon、TiD、NJSD等会议演讲嘉宾,AiDD测试生成与优化专题出品人。
报告题目
LLM辅助系统测试脚本代码生成
摘要
本课题主要介绍LLM辅助系统集成测试脚本代码生成华为实践之路,包括总体方案、AI工程、经验总结等。本课题应是业界首个针对ICT领域大型复杂嵌入式系统集成测试代码生成为应用背景的AIGC训练、调优、推理及落地各领域产品线实际测试系统开发项目应用的全面系统的探索实践。

杨已彪(南京大学)
博士,现任南京大学计算机系特任副研究员。他的主要研究兴趣包括软件测试与分析、缺陷检测与定位等软件自动化技术。他于2016年9月在南京大学计算机系获得博士学位,并获得江苏省和南京大学优秀博士学位论文奖。他的研究成果主要发表在国际重要会议和期刊如ICSE、FSE、ASE、TOSEM、TSE等,曾主持包括国家自然科学基金面上基金和青年基金、江苏省自然科学面上基金和青年基金、CCF-华为胡杨林基金、中国博士后科学基金特别资助等在内的多项科研项目。
报告题目
基于大语言模型的基础软件缺陷检测
摘要
近年来,大语言模型技术取得了显著进展,并在多个领域展示出卓越的能力,引起了广泛关注。本报告旨在汇报我们最近基于大语言模型进行基础软件缺陷检测方面的研究实践。我们主要探讨如何通过有针对性的重新训练和调优,充分利用大语言模型的生成能力,生成多样性高和具备更强缺陷检测能力的测试用例,以进行大规模基础软件模糊测试,从而提高基础软件的可靠性和质量。

娄一翎(复旦大学)
复旦大学计算机科学技术学院青年副研究员,2016年毕业于北京大学信息科学技术学院,获理学学士学位,2021年毕业于北京大学信息科学技术学院,获理学博士学位,博士毕业后在美国普渡大学计算机系任博后研究员。主要研究方向包括软件工程、软件测试与分析、智能化软件开发等。目前已在ICSE、FSE、ASE、ISSTA、TSE等软件工程国际高水平会议和期刊上发表论文二十余篇,获ACM SIGSOFT Distinguished Paper Award、IEEE TCSE Distinguished Paper Award,并担任ICSE、FSE、ASE、ISSTA等国际会议程序委员会委员。
报告题目
基于大语言模型的单元测试生成
摘要
人工编写单元测试费时费力。传统方法所生成的单元测试代码往往不符合开发者的编码风格,对单元测试的编写效率提升有限。大语言模型(LLMs)在大规模代码语料上进行预训练,往往能够生成更接近开发者风格的、更有意义的代码,因此在单元测试生成方面具有巨大潜力。本报告将分享ChatGPT等代表性大模型在单元测试生成上的能力评估,包括其所生成单元测试代码的正确性、充分性、可读性和可用性等;进而提出基于大模型的高质量单元测试生成方法,并探索该方法在开源和商用大模型上的效果。

刘哲(中国科学院软件研究所)
中国科学院软件研究所特别研究助理,主要从事智能化软件工程、人机交互等方面的研究 ,近年来主要关注移动应用测试、人机协同测试等。在软件工程和人机交互领域国际著名学术期刊 /会议ICSE、CHI、TSE、ASE等发表 15篇CCF-A类学术论文。博士期间荣获ACM Student Research Competition研究生组全球总冠军,也是中国大陆博士生首次获得该荣誉,同时也获得中国科学院院长优秀奖等荣誉,参与了多项国家自然科学基金项目、科技部重点研发计划。
报告题目
基于大模型的移动应用自动化测试路径生成
摘要
随着软件测试研究的不断深入,一些更具挑战性的问题阻碍了软件测试的有效性和覆盖率的进一步提高。前沿研究正在积极探索一些新兴技术来解决这些问题,而大型语言模型(LLMs)被视为最具潜力的技术之一,具备前所未有的自然语言理解和生成能力,并广泛用于各种自然语言处理任务。本报告将分享大语言模型在自动化测试路径生成和异常输入生成方向的研究成果,包括功能驱动的测试记忆技术和基于正确文本的测试突变技术,来更好的提升自动化测试的充分性和覆盖性。