LINUX入门篇【5】----程序的翻译过程解析
前言:
在C语言阶段我们已经讲过程序的翻译过程,我们知道程序是由预处理,编译,汇编,链接四部分组成的,但是,当时受到C语言编译器的限制,我们没法去深刻体会这个过程,所以,本次我们利用LINUX再一次更为详细的展现一下程序的翻译。
1.编译器:
不同的语言需要由不同的编译器来进行编译,我们一般使用gcc来编译C语言,g++来编译C++语言,且这个对应是不能混淆的,否则编译是无法通过的。
在这里补充一下C++文件的几种格式:.cpp,.cc,.cxx等,我们不能仅仅认识cpp后缀的叫C++文件,要知道C++后缀的文件不只一种
在LINUX中gcc是自带的,想要编译C++语言,需要我们下载一个g++编译器,在这里我们可以使用:
yum install gcc-c++,也就是利用我们上节课讲的yum软件搜索系统来下载
但是,说到这里,你或许会问,LINUX不是不看后缀么?
这个之前我是说过的,LINUX的确是不看后缀的,但是编译工具是看后缀的,所以我们规范文件名和代码还是很有必要的
2.程序的翻译过程详解:
先让我们复习一下程序的翻译的过程:预处理,编译,汇编,链接,**每经过一个阶段,我们所写的程序就被处理为一个不同的形式,但它的趋势是逐渐处理为我们看不懂而计算机硬件能看懂的过程。**这句话很关键,但为什么要这样去一步一步的去翻译呢?难道直接一步到位让计算机看懂不行么?
这就要谈一谈我们程序的发展过程了:
首先我们明白,计算机的本质是一堆硬件,只能处理二进制信息,不管是多么强大和先进的计算机,它都只能识别二进制的数据,因此,早期的科学家们使用打孔的方式打印计算机信息,后来经过发展,人们发明了一套编码负责专门处理这种二进制信息,这便是汇编语言,但是,就像我说过的,计算机只能看懂二进制信息,因此,需要专门把汇编语言翻译成二进制信息给计算机看,由此,便诞生了最早的编译器,汇编语言编译器,负责将汇编代码翻译成二进制语言交给计算机去理解。但是,即使是汇编语言依旧晦涩难懂,大部分人没法快速掌握语法和功能,由此,科学家们又以汇编语言为底层,开发出了更高级的语言—C语言!同时,C语言的编译器也应运而生,但和汇编编译器不同,C语言的编译器负责去将C语言的代码翻译成汇编语言,然后汇编语言再经过编译器变成二进制代码。从这之后,C++诞生了,但是其本质都不无承接C语言的做法,将其翻译成汇编语言。C/C++之后,又出现了一大批以C/C++为底层的解释性语言,JAVA python php他们的本质是解释代码的意思而不是编译,但是你可以理解为他们是将其代码解释成汇编代码,因此他们使用解释器而不是编译器。通过这个过程,我i们发现,语言的发展是一层接着一层去承接的,下一层把上一层当作底层来进行翻译,这个过程便是语言/编译器的自举过程。

这也就解释了为什么我们的计算机程序翻译是一步一步进行的而不是跨越,因为每一步都有对应的编译器,你总不能重新构建一个由C语言直接翻译为二进制代码的编译器吧,那样需要消耗大量的成本和时间,而且毫无意义,这样一层一层的编译,提高了效率也节省了成本。
由此,我们便先解开了为什么我们的计算机程序要一步一步去翻译的问题,下面就让我们一步一步去看:
1.预处理:
在预处理阶段,由C语言那篇文章我们知道,主要进行的是4个过程:
1.头文件展开
2.去掉注释
3.条件编译
4.宏替换
经过这4个过程,我们的程序代码就更加纯粹和简洁,我们以LINUX我写的这个代码为例子,来讲一讲。

这是一个很简单的C语言程序,在这里包括条件编译,宏,条件编译,注释,让我们看看经过预处理阶段后程序会变成什么样子呢?
我们wq退出程序,然后我们输入指令gcc -E 文件名 -o 新的文件名
这条指令的意思就是:从现在开始进行程序的翻译,到预处理完就停下来,并将预处理完的结果放入我们后面的文件中,如下:

我将文件放入到code.i文件中,现在让我们打开文件:
是的,你会发现宏被替换后消失了,同时条件编译直接保留条件编译要执行的程序部分,其他部分全部剪切掉,同时注释被取消,这样,我们的代码就变得更加简洁。
条件编译为我们提供了一个很好的思路:
通过条件编译,我们是可以实现代码的动态裁剪的,比如,就如同我们玩的游戏有时会有不同的版本切换,不同的版本或许只是几个数值上的改变,游戏的机制和操作方式没有任何区别,这种不同版本的维护,对应的源代码其实都是一份,而通过条件编译,就可以实现利用一份源代码去维护两个或者多个版本
2.编译:
下一个过程就是编译,即是将代码经过编译器编译成汇编语言,为下一步汇编进一步翻译成二进制码做准备,我们的指令为:
gcc -S code.i -o code.s
文件如下:

在这里便是汇编代码的内容,为下一步做准备
3.汇编:
指令如下:
gcc -c code.s -o code.o

到这里,已经变成能由计算机看懂的二进制代码了。
4.链接:
所谓的链接,其实本质上讲是我们的.o文件完成后,同系统库链接,从而最终形成可执行程序的过程。
链接还是很好理解的,不过在这里我们谈到了库,由此便让我们先讲一讲何为库:
1.动态库,静态库概念和理解:
我们现在所写的代码,包括一些可以直接使用的函数,都是前人写好的,我们都是直接拿来用。
那么,这些函数存储他们的库在哪里呢?我们可以用下面的指令来查看:
ldd +可执行程序文件如下:

我们的ldd指令就可以查看我们所写的可执行程序都链接了哪些库,在这里你会看见三个,由此我们先引入库的分类:
1.库的分类:
库主要分为两种:
1.动态库:
.库类别为.so的即为动态库,这是在LINUX,在windows中为xxxx.dll
2.静态库:
库类别为.a的即为静态库,这是在LINUX,在windows中为xxx.lib
而在我们的LINUX系统中,是基本不会默认安装静态库的,而是动态库居多,至于这是为什么,我们先把这条结论记住,之后等我们分析优缺点的时候,不用我说,你自然就知道原因了。
2.库命名:
一个常见的库的命名如下:

一个库的真正名字实际上就是去掉lib,类别,版本号剩下的,在这里就是C即为它的名字。
3.动静态链接的理解:
我们应该怎样理解链接呢?我用这样一张图去体现链接的过程,图片如下:
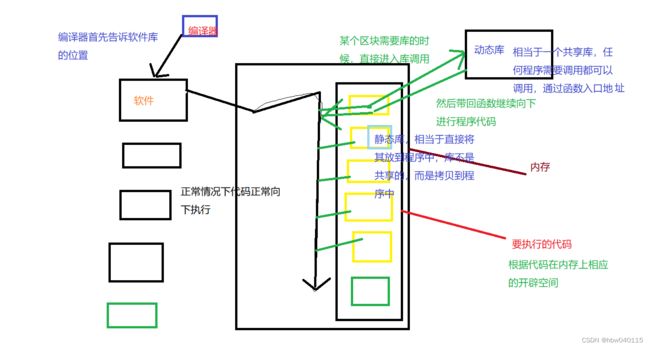
我们前面知道,LINUX系统中默认的库都是动态库,所以如果你删除了动态库,LINUX系统相当于直接用不了了,要重新装。
根据上面的图,我们来明确一下动静态库,动静态链接的概念:
动态库:是C/C++或者其他第三方提供的所有方法的集合,被所有程序以链接的方式关联起来。
动态链接:库中的所有函数,都有其对应的入口地址,所谓的动态链接,其实就是把链接的库中的函数的入口地址拷贝到我们的可执行程序的特定位置,方便程序执行时可以到对应地址的位置调用函数.(注意,由于程序没有实际执行,也就是说,程序没有实际上在内存空间中占用位置,故在这里我们的入口地址都是逻辑地址而非物理上的地址)
静态库:是C/C++或者其他第三方提供的所有方法的集合,被所有程序以拷贝的方式,将需要的代码拷贝到自己的可执行程序中。
静态链接:以拷贝的形式,直接把所需要的函数代码拷贝到程序当中
在这里,我们就很清楚动静态链接的差别所在了:动态链接是拷贝地址,而静态链接是拷贝代码,就像我上面的图所示的,静态相当于直接把代码放到自己的身边,而动态的代码依旧在原来的位置
4.动静态链接的优缺点:
动态链接:
优点:形成的可执行程序体积比较小,比较节省资源
缺点:由于涉及到根据地址调用的过程,因此要慢一些,并且强依赖动态库,一旦动态库没了,所有依赖这个库的程序都没法执行了
静态链接:
优点:即使库被销毁,由于程序代码已经被拷贝到程序中,因此可以独立运行
缺点:体积太大,浪费资源
由此,让我们想想我之前问大家的那个问题?为什么LINUX支持的都是默认的动态文件,而不是静态的呢?
这正是因为静态库占用了过大的空间,浪费了更多的资源,我们可以拿这样一个例子来说明:
我们在gcc指令后面加上-static,就代表静态链接的意思,如下我们产生了这样的情况:
![]()
![]()
你会发现,861288是静态链接的可执行程序的大小,而8360是动态链接的,即使是一个很小的程序,就有这样的大小差距,现在我想,默认动态库不是没有道理的吧。
补充,有时我们-static没法执行:这个时候需要我们安装C的静态:
sudo yum install glibc-static
如果你需要C++的静态编译器,你可以安装:
sudo yum install -y libstdc+±static
5.引发思考,一款合格开发环境应该为我们做什么:
在这里我必须重新提一下VS,它确实称得上是一款十分优秀的开发平台,随着我自己配置编译器的过程,我逐渐意识到vs的强大之处,我们在VS可以直接调用库,可以调试,可以重新编译和卸载上一次的编译结果,可以查看汇编代码。
那在我看来,一个优秀的开发环境应该具备:
1.配置好了各种开发需要的库环境,例如lib 等
2.设置了合适的查找路径,方便调用
3.规定好我们形成的可执行程序的链接方式
总结:
本篇,我们进一步查看了程序是如何被翻译出来的,以及库的链接是如何进行的,同时我们也清楚的知道,我们所写的程序是多种库组合出来的结果,没有这些库,我们的函数就需要自己去构造,很麻烦,库进一步帮助我们提高了开发效率,同时,也让我们对开发环境的配置要求有了一个初步大概的认识。之后,我们将进一步配置完善我们的代码编写vim工具,并且可以在LINUX上实现我们的第一个有趣的程序。