【kafka】Java客户端代码demo:自动异步提交、手动同步提交及提交颗粒度、动态负载均衡
一,代码及配置项介绍
kafka版本为3.6,部署在3台linux上。
maven依赖如下:
org.apache.kafka
kafka_2.13
3.6.0
生产者、消费者和topic代码如下:
String topic = "items-01";
@Test
public void producer() throws ExecutionException, InterruptedException {
Properties p = new Properties();
p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.129:9092,192.168.184.130:9092,192.168.184.131:9092");
p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
KafkaProducer producer = new KafkaProducer(p);
while(true){
for (int i = 0; i < 3; i++) {
for (int j = 0; j <3; j++) {
ProducerRecord record = new ProducerRecord<>(topic, "item"+j,"val" + i);
Future send = producer
.send(record);
RecordMetadata rm = send.get();
int partition = rm.partition();
long offset = rm.offset();
System.out.println("key: "+ record.key()+" val: "+record.value()+" partition: "+partition + " offset: "+offset);
}
}
}
}
@Test
public void consumer(){
//基础配置
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.129:9092,192.168.184.130:9092,192.168.184.131:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//消费的细节
String group = "user-center";
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,group);
//KAKFA IS MQ IS STORAGE
/**
* "What to do when there is no initial offset in Kafka or if the current offset
* does not exist any more on the server
* (e.g. because that data has been deleted):
*
* - earliest: automatically reset the offset to the earliest offset
*
- latest: automatically reset the offset to the latest offset
* - none: throw exception to the consumer if no previous offset is found for the consumer's group
- anything else: throw exception to the consumer.
*
";
*/
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");//第一次启动,米有offset
//自动提交时异步提交,丢数据&&重复数据
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
// p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");
// p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"10");
KafkaConsumer consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(topic));
while(true){
ConsumerRecords records = consumer.poll(Duration.ofMillis(0));
if (!records.isEmpty()){
System.out.println();
System.out.println("-----------------" + records.count() + "------------------------------");
Iterator> iterator = records.iterator();
while (iterator.hasNext()){
ConsumerRecord record = iterator.next();
int partition = record.partition();
long offset = record.offset();
System.out.println("key: " + record.key() + " val: " + record.value() + " partition: " + partition + " offset: " + offset);
}
}
}
}
这里先简单解释一下,kafka的topic只是一个逻辑上的概念,实际上的物理存储是依赖分布在broker中的分区partition来完成的。kafka依赖的zk中有一个__consumer_offsets[1]话题,存储了所有consumer和group消费的进度,包括当前消费到的进度current-offset、kafka写入磁盘的日志中记录的消息的末尾log-end-offset。
kafka根据消息的key进行哈希取模的结果来将消息分配到不同的partition,partition才是consumer拉取的对象。每次consumer拉取,都是从一个partition中拉取。(这一点,大家可以自己去验证一下)

下面代码,是描述的当consumer第一次启动时,在kafka中还没有消费的记录,此时current-offset为"-"时,consumer应如何拉取数据的行为。有3个值可选,latest、earliest、none。
当设置如下配置为latest,没有current-offset时,只拉取consumer启动后的新消息。
earliest,没有current-offset时,从头开始拉取消息消费。
node,没有current-offset时,抛异常。
它们的共同点就是current-offset有值时,自然都会按照current-offset拉取消息。
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
下面代码,true表示设置的异步自动提交,false为手动提交。
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
下面代码,设置的是自动提交时,要过多少秒去异步自动提交。
properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");
下面代码,是设置kafka批量拉取多少数据,默认的应该是最大500,小于500。 kafka可以批量的拉取数据,这样可以节省网卡资源。
properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"10");
二、异步自动提交
部分设置项如下:
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");//自动提交时异步提交,丢数据&&重复数据
properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");
properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"10");
开启生产者,生产出一些消息,可以看到之前拉取完数据的group又有了新的数据。

开启消费者,可以看到消息被消费掉。

因为提交是异步的,我们需要需要为了业务代码留出处理时间。所以需要设置异步提交时间。
假设在间隔时间(AUTO_COMMIT_INTERVAL_MS_CONFIG,自动提交间隔毫秒数配置)内,还没有提交的时候,消费过数据假设数据,consumer挂了。那么consumer再次启动时,从kafka拉取数据,就会因为还没有提交offset,而重新拉取消费过的数据,导致重复消费。
假设现在已经过了延间隔时间,提交成功了,但是业务还没有完成,并且在提交后失败了。那么这个消费失败的消息也不会被重新消费了,导致丢失消息。
为了解决上述的问题,可以使用手动同步提交。
三、手动同步提交
假设我们现在是按照批量拉取,下面介绍2种提交粒度的demo,粒度由小到大,分别是按条提交,按partition提交 && 按批次提交。
3.1 按条提交
public void test1(){
//基础配置
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.129:9092,192.168.184.130:9092,192.168.184.131:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//消费的细节
String group = "user-center";
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,group);
//KAKFA IS MQ IS STORAGE
/**
* "What to do when there is no initial offset in Kafka or if the current offset
* does not exist any more on the server
* (e.g. because that data has been deleted):
*
* - earliest: automatically reset the offset to the earliest offset
*
- latest: automatically reset the offset to the latest offset
* - none: throw exception to the consumer if no previous offset is found for the consumer's group
- anything else: throw exception to the consumer.
*
";
*/
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");//第一次启动,米有offset
//自动提交时异步提交,丢数据&&重复数据
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
// p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");
// p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"10");
KafkaConsumer consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(topic));
while(true){
ConsumerRecords records = consumer.poll(Duration.ofMillis(0));
if (!records.isEmpty()){
System.out.println();
System.out.println("-----------------" + records.count() + "------------------------------");
Iterator> iterator = records.iterator();
while (iterator.hasNext()){
ConsumerRecord next = iterator.next();
int p = next.partition();
long offset = next.offset();
String key = next.key();
String value = next.value();
System.out.println("key: " + key + " val: " + value + " partition: " + p + " offset: " + offset);
TopicPartition sp = new TopicPartition(topic,p);
OffsetAndMetadata om = new OffsetAndMetadata(offset);
HashMap map = new HashMap<>();
map.put(sp,om);
consumer.commitSync(map);
}
}
}
}
3.2 按partition提交 && 按批次提交
由于消费者每一次拉取都是从一个partition中拉取,所以其实按partition拉取和按批次拉取,是一回事。整体成功
@Test
public void test2(){
//基础配置
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.129:9092,192.168.184.130:9092,192.168.184.131:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//消费的细节
String group = "user-center";
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,group);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
//自动提交时异步提交,丢数据&&重复数据
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
// p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");
// p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"10");
KafkaConsumer consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(topic));
while(true){
ConsumerRecords records = consumer.poll(Duration.ofMillis(0));
if (!records.isEmpty()){
System.out.println();
System.out.println("-----------------" + records.count() + "------------------------------");
Set partitions = records.partitions();
for (TopicPartition partition : partitions){
List> pRecords = records.records(partition);
Iterator> pIterator = pRecords.iterator();
while (pIterator.hasNext()){
ConsumerRecord next = pIterator.next();
int p = next.partition();
long offset = next.offset();
String key = next.key();
String value = next.value();
System.out.println("key: " + key + " val: " + value + " partition: " + p + " offset: " + offset);
}
//按partition提交
long offset = pRecords.get(pRecords.size() - 1).offset();
OffsetAndMetadata om = new OffsetAndMetadata(offset);
HashMap map = new HashMap<>();
map.put(partition,om);
consumer.commitSync(map);
}
//按批次提交
// consumer.commitSync();
}
}
}
四,动态负载均衡
我们知道,对于一个topic,一个group中,为了保证消息的顺序性,默认只能有一个consumer来消费。假设我们有3台消费者,那么此时,另外2台消费者就会闲着不干活。有没有可能能够既保证消费消息的顺序性,又能够提升性能呢?
答案就是kafka的动态负载均衡。
前面提到了,producer会根据消息的key的哈希取模的结果来把消息分配到某个partition,也就是说同一个key的消息,只存在于一个partition中。而且消费者拉取消息,一个批次,只从一个partition中拉取消息。
假设我们现在有一个topic,有2个partition。那么我们可不可以在组内3台消费者中,挑2台出来,各自对应这个topic的2个partition,这样消费者和partition一一对应。既能保证消息的顺序性,又能够提升性能。这就是kafka的动态负载均衡。
代码如下:
//动态负载均衡
@Test
public void test3(){
//基础配置
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.129:9092,192.168.184.130:9092,192.168.184.131:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//消费的细节
String group = "user-center";
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,group);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
//自动提交时异步提交,丢数据&&重复数据
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");
properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"10");
KafkaConsumer consumer = new KafkaConsumer<>(properties);
//kafka 的consumer会动态负载均衡
consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener() {
//Revoked,取消的回调函数
@Override
public void onPartitionsRevoked(Collection partitions) {
System.out.println("---onPartitionsRevoked:");
Iterator iter = partitions.iterator();
while(iter.hasNext()){
System.out.println(iter.next().partition());
}
System.out.println();
}
//Assigned 指定的回调函数
@Override
public void onPartitionsAssigned(Collection partitions) {
System.out.println("---onPartitionsAssigned:");
Iterator iter = partitions.iterator();
while(iter.hasNext()){
System.out.println(iter.next().partition());
}
System.out.println();
}
});
while(true){
ConsumerRecords records = consumer.poll(Duration.ofMillis(0));
if (!records.isEmpty()){
System.out.println();
System.out.println("-----------------" + records.count() + "------------------------------");
Iterator> iterator = records.iterator();
while (iterator.hasNext()){
ConsumerRecord next = iterator.next();
int p = next.partition();
long offset = next.offset();
String key = next.key();
String value = next.value();
System.out.println("key: " + key + " val: " + value + " partition: " + p + " offset: " + offset);
TopicPartition sp = new TopicPartition(topic,p);
OffsetAndMetadata om = new OffsetAndMetadata(offset);
HashMap map = new HashMap<>();
map.put(sp,om);
consumer.commitSync(map);
}
}
}
}
上述代码在订阅时,加了一个ConsumerRebalanceListener监听器,实现了2个回调函数onPartitionsRevoked和onPartitionsAssigned,分别是取消组内消费者负载均衡时触发的回调函数,和指定组内消费者加入负载均衡时触发的回调函数。
在使用动态负载均衡时,需要注意的是,在提交时不要批量提交,否则会报错如下,暂时还没有研究问题原因,有了结果会回来更新的。
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
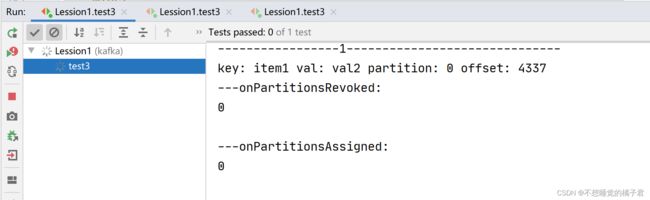
先打开一个消费者A,触发了回调函数onPartitionsAssigned,可以看到partition0 和 partition1都被分配到了A上。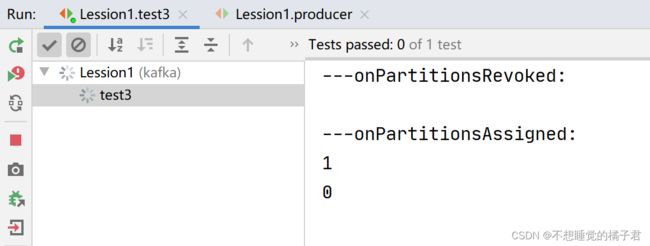
此时打开生产者,可以看到partition0和1的消息都发送到了A上。
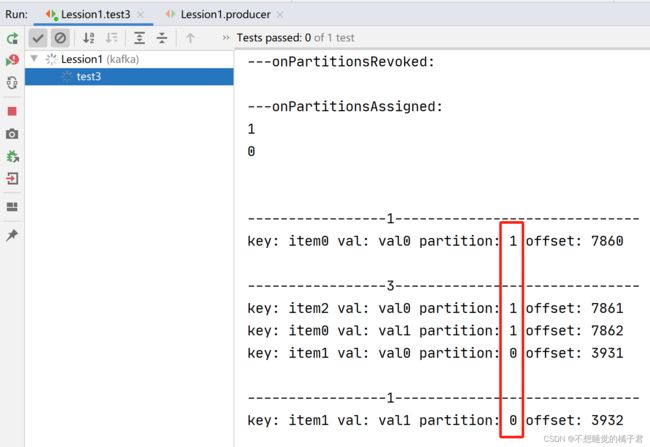
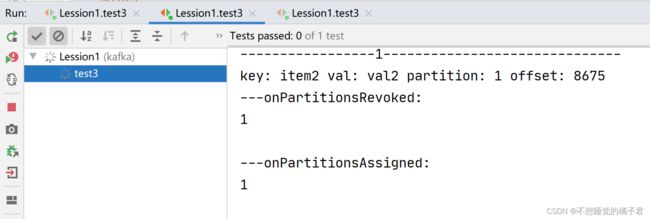
我们再打开一个同一个组内的消费者B。
可以看到A取消了partition0和1的分配,被指定了partition0。消费者B则被指定了partition1.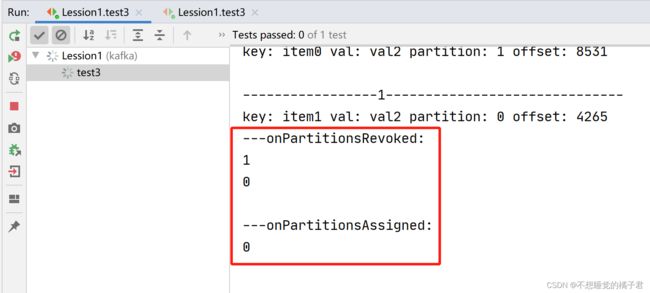

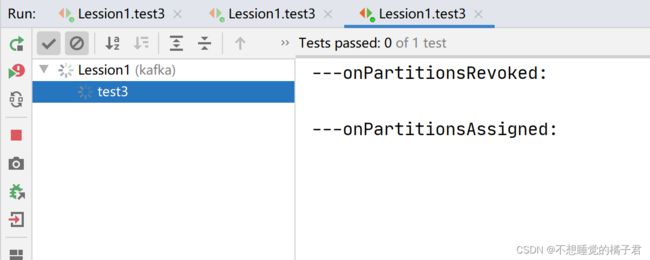
再次打开生产者去生产消息,这次A只消费partition 0的消息,B只消费partition1的消息。

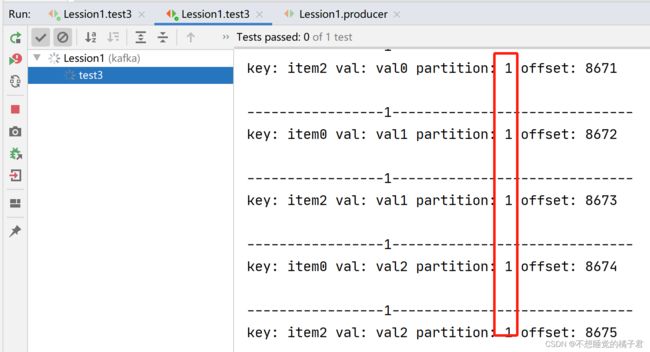
如果我们再启动组内第3台消费者,那么组内消费者会再次负载均衡。由于这个topic只有2个partition,所以即使启动3台组内的消费者,也最多只有2个消费者被分配给某个partition,剩余1个消费者不参与负载均衡。
参考文章:
[1],【kafka】记一次kafka基于linux的原生命令的使用