从C语言来理解文件系统
文章目录
-
- 一、文件、文件系统
- 二、C语言文件操作详解
- C语言中的文件是什么?
-
-
- 文件流
-
- C语言fopen函数的用法,C语言打开文件详解
- fopen() 函数的返回值
-
-
- 判断文件是否打开成功
-
- fopen() 函数的打开方式
- 关闭文件
- 实例演示
- 文本文件和二进制文件到底有什么区别?
-
- 文本文件和二进制文件的区别
- fopen() 中的文本方式和二进制方式
- C语言fgetc和fputc函数用法详解(以字符形式读写文件)
-
- 字符读取函数 fgetc
-
-
- 对 EOF 的说明
-
- 字符写入函数 fputc
-
-
- 两点说明
-
- C语言fgets和fputs函数的用法详解(以字符串的形式读写文件)
-
- 读字符串函数 fgets
- 写字符串函数 fputs
- C语言fread和fwrite的用法详解(以数据块的形式读写文件)
- C语言fscanf和fprintf函数的用法详解(格式化读写文件)
- C语言rewind和fseek函数的用法详解(随机读写文件)
-
- 文件定位函数rewind和fseek
- 文件的随机读写
- C语言实现文件复制功能(包括文本文件和二进制文件)
- C语言FILE结构体以及缓冲区深入探讨
- C语言获取文件大小(长度)
-
- ftell()函数
- C语言插入、删除、更改文件内容
-
- 文件复制函数
- 文件内容插入函数
- 文件内容删除函数
- 三、C++文件操作
- 计算机文件到底是什么(通俗易懂)?
- C++文件类(文件流类)及用法详解
- C++ open 打开文件(含打开模式一览表)
-
- 使用 open 函数打开文件
- 使用流类的构造函数打开文件
- 文本打开方式和二进制打开方式的区别是什么?
-
- 文本文件和二进制文件的区别
- 两种打开方式的区别
- C++ close()关闭文件方法详解
- C++打开的文件一定要用close()方法关闭!
-
-
-
- C++ flush()刷新缓冲区
-
-
- C++文本文件读写操作详解
-
- C++ >>和<<读写文本文件
- C++ ostream::write()方法写文件
- C++ istream::read()方法读文件
- C++ get()和put()读写文件详解
-
- C++ ostream::put()成员方法
- C++ istream::get()成员方法
- C++ getline():从文件中读取一行字符串
- C++移动和获取文件读写指针(seekp、seekg、tellg、tellp)
之前写过一篇有关文件的一篇文章: 【C/C++服务器开发】文件,文件描述符,I/O多路复用,select / poll / epoll 详解.
可以和这篇一起补充阅读。
一、文件、文件系统
可以看下面这几篇文章:
文件系统
一口气搞懂「文件系统」,就靠这 25 张图了
简直不要太硬了!一文带你彻底理解文件系统
文件系统是什么?介绍几种计算机文件系统及其运行原理
转载于:http://c.biancheng.net/view/vip_2079.html,http://c.biancheng.net/view/309.html
二、C语言文件操作详解
C语言具有操作文件的能力,比如打开文件、读取和追加数据、插入和删除数据、关闭文件、删除文件等。
与其他编程语言相比,C语言文件操作的接口相当简单和易学。在C语言中,为了统一对各种硬件的操作,简化接口,不同的硬件设备也都被看成一个文件。对这些文件的操作,等同于对磁盘上普通文件的操作。
C语言中的文件是什么?
我们对文件的概念已经非常熟悉了,比如常见的 Word 文档、txt 文件、源文件等。文件是数据源的一种,最主要的作用是保存数据。
在操作系统中,为了统一对各种硬件的操作,简化接口,不同的硬件设备也都被看成一个文件。对这些文件的操作,等同于对磁盘上普通文件的操作。例如:
- 通常把显示器称为标准输出文件,printf 就是向这个文件输出数据;
- 通常把键盘称为标准输入文件,scanf 就是从这个文件读取数据。
| 文件 | 硬件设备 |
|---|---|
| stdin | 标准输入文件,一般指键盘;scanf()、getchar() 等函数默认从 stdin 获取输入。 |
| stdout | 标准输出文件,一般指显示器;printf()、putchar() 等函数默认向 stdout 输出数据。 |
| stderr | 标准错误文件,一般指显示器;perror() 等函数默认向 stderr 输出数据(后续会讲到)。 |
| stdprn | 标准打印文件,一般指打印机。 |
我们不去探讨硬件设备是如何被映射成文件的,大家只需要记住,在C语言中硬件设备可以看成文件,有些输入输出函数不需要你指明到底读写哪个文件,系统已经为它们设置了默认的文件,当然你也可以更改,例如让 printf 向磁盘上的文件输出数据。
操作文件的正确流程为:打开文件 --> 读写文件 --> 关闭文件。文件在进行读写操作之前要先打开,使用完毕要关闭。
所谓打开文件,就是获取文件的有关信息,例如文件名、文件状态、当前读写位置等,这些信息会被保存到一个 FILE 类型的结构体变量中。关闭文件就是断开与文件之间的联系,释放结构体变量,同时禁止再对该文件进行操作。
在C语言中,文件有多种读写方式,可以一个字符一个字符地读取,也可以读取一整行,还可以读取若干个字节。文件的读写位置也非常灵活,可以从文件开头读取,也可以从中间位置读取。
文件流
在《载入内存,让程序运行起来》一文中提到,所有的文件(保存在磁盘)都要载入内存才能处理,所有的数据必须写入文件(磁盘)才不会丢失。数据在文件和内存之间传递的过程叫做文件流,类似水从一个地方流动到另一个地方。数据从文件复制到内存的过程叫做输入流,从内存保存到文件的过程叫做输出流。
文件是数据源的一种,除了文件,还有数据库、网络、键盘等;数据传递到内存也就是保存到C语言的变量(例如整数、字符串、数组、缓冲区等)。我们把数据在数据源和程序(内存)之间传递的过程叫做数据流(Data Stream)。相应的,数据从数据源到程序(内存)的过程叫做输入流(Input Stream),从程序(内存)到数据源的过程叫做输出流(Output Stream)。
输入输出(Input output,IO)是指程序(内存)与外部设备(键盘、显示器、磁盘、其他计算机等)进行交互的操作。几乎所有的程序都有输入与输出操作,如从键盘上读取数据,从本地或网络上的文件读取数据或写入数据等。通过输入和输出操作可以从外界接收信息,或者是把信息传递给外界。
我们可以说,打开文件就是打开了一个流。
C语言fopen函数的用法,C语言打开文件详解
在C语言中,操作文件之前必须先打开文件;所谓“打开文件”,就是让程序和文件建立连接的过程。
打开文件之后,程序可以得到文件的相关信息,例如大小、类型、权限、创建者、更新时间等。在后续读写文件的过程中,程序还可以记录当前读写到了哪个位置,下次可以在此基础上继续操作。
标准输入文件 stdin(表示键盘)、标准输出文件 stdout(表示显示器)、标准错误文件 stderr(表示显示器)是由系统打开的,可直接使用。
使用
FILE *fopen(char *filename, char *mode);
filename为文件名(包括文件路径),mode为打开方式,它们都是字符串。
fopen() 函数的返回值
fopen() 会获取文件信息,包括文件名、文件状态、当前读写位置等,并将这些信息保存到一个 FILE 类型的结构体变量中,然后将该变量的地址返回。
FILE 是
如果希望接收 fopen() 的返回值,就需要定义一个 FILE 类型的指针。例如:
FILE *fp = fopen("demo.txt", "r");
表示以“只读”方式打开当前目录下的 demo.txt 文件,并使 fp 指向该文件,这样就可以通过 fp 来操作 demo.txt 了。fp 通常被称为文件指针。
再来看一个例子:
FILE *fp = fopen("D:\\demo.txt","rb+");
表示以二进制方式打开 D 盘下的 demo.txt 文件,允许读和写。
判断文件是否打开成功
打开文件出错时,fopen() 将返回一个空指针,也就是 NULL,我们可以利用这一点来判断文件是否打开成功,请看下面的代码:
FILE *fp;
if( (fp=fopen("D:\\demo.txt","rb")) == NULL ){
printf("Fail to open file!\n");
exit(0); //退出程序(结束程序)
}
我们通过判断 fopen() 的返回值是否和 NULL 相等来判断是否打开失败:如果 fopen() 的返回值为 NULL,那么 fp 的值也为 NULL,此时 if 的判断条件成立,表示文件打开失败。
以上代码是文件操作的规范写法,读者在打开文件时一定要判断文件是否打开成功,因为一旦打开失败,后续操作就都没法进行了,往往以“结束程序”告终。
fopen() 函数的打开方式
不同的操作需要不同的文件权限。例如,只想读取文件中的数据的话,“只读”权限就够了;既想读取又想写入数据的话,“读写”权限就是必须的了。
另外,文件也有不同的类型,按照数据的存储方式可以分为二进制文件和文本文件,它们的操作细节是不同的。
在调用 fopen() 函数时,这些信息都必须提供,称为“文件打开方式”。最基本的文件打开方式有以下几种:
| 控制读写权限的字符串(必须指明) | |
|---|---|
| 打开方式 | 说明 |
| “r” | 以“只读”方式打开文件。只允许读取,不允许写入。文件必须存在,否则打开失败。 |
| “w” | 以“写入”方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。 |
| “a” | 以“追加”方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。 |
| “r+” | 以“读写”方式打开文件。既可以读取也可以写入,也就是随意更新文件。文件必须存在,否则打开失败。 |
| “w+” | 以“写入/更新”方式打开文件,相当于w和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。 |
| “a+” | 以“追加/更新”方式打开文件,相当于a和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。 |
| 控制读写方式的字符串(可以不写) | |
| 打开方式 | 说明 |
| “t” | 文本文件。如果不写,默认为"t"。 |
| “b” | 二进制文件。 |
调用 fopen() 函数时必须指明读写权限,但是可以不指明读写方式(此时默认为"t")。
读写权限和读写方式可以组合使用,但是必须将读写方式放在读写权限的中间或者尾部(换句话说,不能将读写方式放在读写权限的开头)。例如:
- 将读写方式放在读写权限的末尾:“rb”、“wt”、“ab”、“r+b”、“w+t”、“a+t”
- 将读写方式放在读写权限的中间:“rb+”、“wt+”、“ab+”
整体来说,文件打开方式由 r、w、a、t、b、+ 六个字符拼成,各字符的含义是:
- r(read):读
- w(write):写
- a(append):追加
- t(text):文本文件
- b(binary):二进制文件
- +:读和写
关闭文件
文件一旦使用完毕,应该用 fclose() 函数把文件关闭,以释放相关资源,避免数据丢失。fclose() 的用法为:
int fclose(FILE *fp);
fp 为文件指针。例如:
fclose(fp);
文件正常关闭时,fclose() 的返回值为0,如果返回非零值则表示有错误发生。
实例演示
最后,我们通过一段完整的代码来演示 fopen 函数的用法,这个例子会一行一行地读取文本文件的所有内容:
#include 读者只需要关心文件打开部分的代码,暂时不用关心文件读取部分的代码,后续我们会逐一讲解。
文本文件和二进制文件到底有什么区别?
在学习了 fopen() 函数后,我们知道它的第二个参数是一个字符串,用来表示文件打开方式。如果字符串中出现b,则表示以二进制方式打开文件;如果字符串中出现t,或者两者都不出现,则表示以文本方式打开文件。
文本文件和二进制文件的区别
根据我们以往的经验,文本文件通常用来保存肉眼可见的字符,比如.txt文件、.c文件、.dat文件等,用文本编辑器打开这些文件,我们能够顺利看懂文件的内容。
二进制文件通常用来保存视频、图片、程序等不可阅读的内容,用文本编辑器打开这些文件,会看到一堆乱码,根本看不懂。
但是从物理上讲,二进制文件和字符文件并没有什么区别,它们都是以二进制的形式保存在磁盘上的数据。
我们之所以能看懂文本文件的内容,是因为文本文件中采用的是 ASCII、UTF-8、GBK 等字符编码,文本编辑器可以识别出这些编码格式,并将编码值转换成字符展示出来。
而二进制文件使用的是 mp4、gif、exe 等特殊编码格式,文本编辑器并不认识这些编码格式,只能按照字符编码格式胡乱解析,所以就成了一堆乱七八糟的字符,有的甚至都没见过。
如果我们新建一个 mp4 文件,给它写入一串字符,然后再用文本编辑器打开,你一样可以读得懂,有兴趣的读者可以自己试试。
总起来说,不同类型的文件有不同的编码格式,必须使用对应的程序(软件)才能正确解析,否则就是一堆乱码,或者无法使用。
fopen() 中的文本方式和二进制方式
在C语言中,二进制方式很简单,读取文件时,会原封不动的读出文件的全部內容,写入数据时,也是把缓冲区中的內容原封不动的写到文件中。
文本方式和二进制方式并没有本质上的区别,只是对于换行符的处理不同。
C语言程序将\n作为换行符,类 UNIX/Linux 系统在处理文本文件时也将\n作为换行符,所以程序中的数据会原封不动地写入文本文件中,反之亦然。
但是 Windows 系统却不同,它将\r\n作为文本文件的换行符。
在 Windows 系统中,如果以文本方式打开文件,当读取文件时,程序会将文件中所有的\r\n转换成一个字符\n。也就是说,如果文本文件中有连续的两个字符是\r\n,则程序会丢弃前面的\r,只读入\n。
当写入文件时,程序会将\n转换成\r\n写入。也就是说,如果要写入的内容中有字符\n,则在写入该字符前,程序会自动先写入一个\r。
因此,如果用文本方式打开二进制文件进行读写,读写的内容就可能和文件的内容有出入。
总起来说,对于 Windows 平台,为了保险起见,我们最好用"t"来打开文本文件,用"b"来打开二进制文件。对于 Linux 平台,使用"r"还是"b"都无所谓,既然默认是"r",那我们什么都不写就行了。
C语言fgetc和fputc函数用法详解(以字符形式读写文件)
在C语言中,读写文件比较灵活,既可以每次读写一个字符,也可以读写一个字符串,甚至是任意字节的数据(数据块)。本节介绍以字符形式读写文件。
以字符形式读写文件时,每次可以从文件中读取一个字符,或者向文件中写入一个字符。主要使用两个函数,分别是 fgetc() 和 fputc()。
字符读取函数 fgetc
fgetc 是 file get char 的缩写,意思是从指定的文件中读取一个字符。fgetc() 的用法为:
int fgetc (FILE *fp);
fp 为文件指针。fgetc() 读取成功时返回读取到的字符,读取到文件末尾或读取失败时返回EOF。
EOF 是 end of file 的缩写,表示文件末尾,是在 stdio.h 中定义的宏,它的值是一个负数,往往是 -1。fgetc() 的返回值类型之所以为 int,就是为了容纳这个负数(char不能是负数)。
EOF 不绝对是 -1,也可以是其他负数,这要看编译器的实现。
fgetc() 的用法举例:
char ch;
FILE *fp = fopen("D:\\demo.txt", "r+");
ch = fgetc(fp);
表示从D:\\demo.txt文件中读取一个字符,并保存到变量 ch 中。
在文件内部有一个位置指针,用来指向当前读写到的位置,也就是读写到第几个字节。在文件打开时,该指针总是指向文件的第一个字节。使用 fgetc() 函数后,该指针会向后移动一个字节,所以可以连续多次使用 fgetc() 读取多个字符。
注意:这个文件内部的位置指针与C语言中的指针不是一回事。位置指针仅仅是一个标志,表示文件读写到的位置,也就是读写到第几个字节,它不表示地址。文件每读写一次,位置指针就会移动一次,它不需要你在程序中定义和赋值,而是由系统自动设置,对用户是隐藏的。
【示例】在屏幕上显示 D:\demo.txt 文件的内容。
#include在D盘下创建 demo.txt 文件,输入任意内容并保存,运行程序,就会看到刚才输入的内容全部都显示在屏幕上。
该程序的功能是从文件中逐个读取字符,在屏幕上显示,直到读取完毕。
程序第 13 行是关键,while 循环的条件为(ch=fgetc(fp)) != EOF。fget() 每次从位置指针所在的位置读取一个字符,并保存到变量 ch,位置指针向后移动一个字节。当文件指针移动到文件末尾时,fget() 就无法读取字符了,于是返回 EOF,表示文件读取结束了。
对 EOF 的说明
EOF 本来表示文件末尾,意味着读取结束,但是很多函数在读取出错时也返回 EOF,那么当返回 EOF 时,到底是文件读取完毕了还是读取出错了?我们可以借助 stdio.h 中的两个函数来判断,分别是 feof() 和 ferror()。
feof() 函数用来判断文件内部指针是否指向了文件末尾,它的原型是:
int feof ( FILE * fp );
当指向文件末尾时返回非零值,否则返回零值。
ferror() 函数用来判断文件操作是否出错,它的原型是:
int ferror ( FILE *fp );
出错时返回非零值,否则返回零值。
需要说明的是,文件出错是非常少见的情况,上面的示例基本能够保证将文件内的数据读取完毕。如果追求完美,也可以加上判断并给出提示:
#include这样,不管是出错还是正常读取,都能够做到心中有数。
字符写入函数 fputc
fputc 是 file output char 的所以,意思是向指定的文件中写入一个字符。fputc() 的用法为:
int fputc ( int ch, FILE *fp );
ch 为要写入的字符,fp 为文件指针。fputc() 写入成功时返回写入的字符,失败时返回 EOF,返回值类型为 int 也是为了容纳这个负数。例如:
fputc('a', fp);
或者:
char ch = 'a';
fputc(ch, fp);
表示把字符 ‘a’ 写入fp所指向的文件中。
两点说明
-
被写入的文件可以用写、读写、追加方式打开,用写或读写方式打开一个已存在的文件时将清除原有的文件内容,并将写入的字符放在文件开头。如需保留原有文件内容,并把写入的字符放在文件末尾,就必须以追加方式打开文件。不管以何种方式打开,被写入的文件若不存在时则创建该文件。
-
每写入一个字符,文件内部位置指针向后移动一个字节。
【示例】从键盘输入一行字符,写入文件。
#include运行程序,输入一行字符并按回车键结束,打开D盘下的 demo.txt 文件,就可以看到刚才输入的内容。
程序每次从键盘读取一个字符并写入文件,直到按下回车键,while 条件不成立,结束读取。
C语言fgets和fputs函数的用法详解(以字符串的形式读写文件)
fgetc() 和 fputc() 函数每次只能读写一个字符,速度较慢;实际开发中往往是每次读写一个字符串或者一个数据块,这样能明显提高效率。
读字符串函数 fgets
fgets() 函数用来从指定的文件中读取一个字符串,并保存到字符数组中,它的用法为:
char *fgets ( char *str, int n, FILE *fp );
str 为字符数组,n 为要读取的字符数目,fp 为文件指针。
返回值:读取成功时返回字符数组首地址,也即 str;读取失败时返回 NULL;如果开始读取时文件内部指针已经指向了文件末尾,那么将读取不到任何字符,也返回 NULL。
注意,读取到的字符串会在末尾自动添加 ‘\0’,n 个字符也包括 ‘\0’。也就是说,实际只读取到了 n-1 个字符,如果希望读取 100 个字符,n 的值应该为 101。例如:
#define N 101
char str[N];
FILE *fp = fopen("D:\\demo.txt", "r");
fgets(str, N, fp);
表示从 D:\demo.txt 中读取 100 个字符,并保存到字符数组 str 中。
需要重点说明的是,在读取到 n-1 个字符之前如果出现了换行,或者读到了文件末尾,则读取结束。这就意味着,不管 n 的值多大,fgets() 最多只能读取一行数据,不能跨行。在C语言中,没有按行读取文件的函数,我们可以借助 fgets(),将 n 的值设置地足够大,每次就可以读取到一行数据。
【示例】一行一行地读取文件。
#include 将下面的内容复制到 D:\demo.txt:
C语言中文网
http://c.biancheng.net
一个学习编程的好网站!
那么运行结果为:
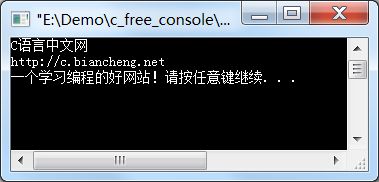
fgets() 遇到换行时,会将换行符一并读取到当前字符串。该示例的输出结果之所以和 demo.txt 保持一致,该换行的地方换行,就是因为 fgets() 能够读取到换行符。而 gets() 不一样,它会忽略换行符。
写字符串函数 fputs
fputs() 函数用来向指定的文件写入一个字符串,它的用法为:
int fputs( char *str, FILE *fp );
str 为要写入的字符串,fp 为文件指针。写入成功返回非负数,失败返回 EOF。例如:
char *str = "http://c.biancheng.net";
FILE *fp = fopen("D:\\demo.txt", "at+");
fputs(str, fp);
表示把把字符串 str 写入到 D:\demo.txt 文件中。
【示例】向上例中建立的 d:\demo.txt 文件中追加一个字符串。
#include运行程序,输入C C++ Java Linux Shell,打开 D:\demo.txt,文件内容为:
C语言中文网
http://c.biancheng.net
一个学习编程的好网站!
C C++ Java Linux Shell
C语言fread和fwrite的用法详解(以数据块的形式读写文件)
fgets() 有局限性,每次最多只能从文件中读取一行内容,因为 fgets() 遇到换行符就结束读取。如果希望读取多行内容,需要使用 fread() 函数;相应地写入函数为 fwrite()。
对于 Windows 系统,使用 fread() 和 fwrite() 时应该以二进制的形式打开文件,具体原因我们已在《文本文件和二进制文件到底有什么区别》一文中进行了说明。
fread() 函数用来从指定文件中读取块数据。所谓块数据,也就是若干个字节的数据,可以是一个字符,可以是一个字符串,可以是多行数据,并没有什么限制。fread() 的原型为:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );
fwrite() 函数用来向文件中写入块数据,它的原型为:
size_t fwrite ( void * ptr, size_t size, size_t count, FILE *fp );
对参数的说明:
- ptr 为内存区块的指针,它可以是数组、变量、结构体等。fread() 中的 ptr 用来存放读取到的数据,fwrite() 中的 ptr 用来存放要写入的数据。
- size:表示每个数据块的字节数。
- count:表示要读写的数据块的块数。
- fp:表示文件指针。
- 理论上,每次读写 size*count 个字节的数据。
size_t 是在 stdio.h 和 stdlib.h 头文件中使用 typedef 定义的数据类型,表示无符号整数,也即非负数,常用来表示数量。
返回值:返回成功读写的块数,也即 count。如果返回值小于 count:
- 对于 fwrite() 来说,肯定发生了写入错误,可以用 ferror() 函数检测。
- 对于 fread() 来说,可能读到了文件末尾,可能发生了错误,可以用 ferror() 或 feof() 检测。
【示例】从键盘输入一个数组,将数组写入文件再读取出来。
#include运行结果:
23 409 500 100 222↙
23 409 500 100 222
打开 D:\demo.txt,发现文件内容根本无法阅读。这是因为我们使用"rb+"方式打开文件,数组会原封不动地以二进制形式写入文件,一般无法阅读。
数据写入完毕后,位置指针在文件的末尾,要想读取数据,必须将文件指针移动到文件开头,这就是rewind(fp);的作用。更多关于rewind函数的内容请点击:C语言rewind函数。
文件的后缀不一定是 .txt,它可以是任意的,你可以自己命名,例如 demo.ddd、demo.doc、demo.diy 等。
【示例】从键盘输入两个学生数据,写入一个文件中,再读出这两个学生的数据显示在屏幕上。
#include运行结果:
Input data:
Tom 2 15 90.5↙
Hua 1 14 99↙
Tom 2 15 90.500000
Hua 1 14 99.000000
C语言fscanf和fprintf函数的用法详解(格式化读写文件)
fscanf() 和 fprintf() 函数与前面使用的 scanf() 和 printf() 功能相似,都是格式化读写函数,两者的区别在于 fscanf() 和 fprintf() 的读写对象不是键盘和显示器,而是磁盘文件。
这两个函数的原型为:
int fscanf ( FILE *fp, char * format, ... );
int fprintf ( FILE *fp, char * format, ... );
fp 为文件指针,format 为格式控制字符串,… 表示参数列表。与 scanf() 和 printf() 相比,它们仅仅多了一个 fp 参数。例如:
FILE *fp;
int i, j;
char *str, ch;
fscanf(fp, "%d %s", &i, str);
fprintf(fp,"%d %c", j, ch);
fprintf() 返回成功写入的字符的个数,失败则返回负数。fscanf() 返回参数列表中被成功赋值的参数个数。
【示例】用 fscanf 和 fprintf 函数来完成对学生信息的读写。
#include运行结果:
Input data:
Tom 2 15 90.5↙
Hua 1 14 99↙
Tom 2 15 90.500000
Hua 1 14 99.000000
打开 D:\demo.txt,发现文件的内容是可以阅读的,格式非常清晰。用 fprintf() 和 fscanf() 函数读写配置文件、日志文件会非常方便,不但程序能够识别,用户也可以看懂,可以手动修改。
如果将 fp 设置为 stdin,那么 fscanf() 函数将会从键盘读取数据,与 scanf 的作用相同;设置为 stdout,那么 fprintf() 函数将会向显示器输出内容,与 printf 的作用相同。例如:
#include运行结果:
Input two numbers: 10 20↙
sum=30
C语言rewind和fseek函数的用法详解(随机读写文件)
前面介绍的文件读写函数都是顺序读写,即读写文件只能从头开始,依次读写各个数据。但在实际开发中经常需要读写文件的中间部分,要解决这个问题,就得先移动文件内部的位置指针,再进行读写。这种读写方式称为随机读写,也就是说从文件的任意位置开始读写。
实现随机读写的关键是要按要求移动位置指针,这称为文件的定位。
文件定位函数rewind和fseek
移动文件内部位置指针的函数主要有两个,即 rewind() 和 fseek()。
rewind() 用来将位置指针移动到文件开头,前面已经多次使用过,它的原型为:
void rewind ( FILE *fp );
fseek() 用来将位置指针移动到任意位置,它的原型为:
int fseek ( FILE *fp, long offset, int origin );
参数说明:
-
fp 为文件指针,也就是被移动的文件。
-
offset 为偏移量,也就是要移动的字节数。之所以为 long 类型,是希望移动的范围更大,能处理的文件更大。offset 为正时,向后移动;offset 为负时,向前移动。
-
origin 为起始位置,也就是从何处开始计算偏移量。C语言规定的起始位置有三种,分别为文件开头、当前位置和文件末尾,每个位置都用对应的常量来表示:
| 起始点 | 常量名 | 常量值 |
|---|---|---|
| 文件开头 | SEEK_SET | 0 |
| 当前位置 | SEEK_CUR | 1 |
| 文件末尾 | SEEK_END | 2 |
例如,把位置指针移动到离文件开头100个字节处:
fseek(fp, 100, 0);
值得说明的是,fseek() 一般用于二进制文件,在文本文件中由于要进行转换,计算的位置有时会出错。
文件的随机读写
在移动位置指针之后,就可以用前面介绍的任何一种读写函数进行读写了。由于是二进制文件,因此常用 fread() 和 fwrite() 读写。
【示例】从键盘输入三组学生信息,保存到文件中,然后读取第二个学生的信息。
#include运行结果:
Input data:
Tom 2 15 90.5↙
Hua 1 14 99↙
Zhao 10 16 95.5↙
Hua 1 14 99.000000
C语言实现文件复制功能(包括文本文件和二进制文件)
文件的复制是常用的功能,要求写一段代码,让用户输入要复制的文件以及新建的文件,然后对文件进行复制。能够复制的文件包括文本文件和二进制文件,你可以复制1G的电影,也可以复制1Byte的txt文档。
实现文件复制的主要思路是:开辟一个缓冲区,不断从原文件中读取内容到缓冲区,每读取完一次就将缓冲区中的内容写入到新建的文件,直到把原文件的内容读取完。
这里有两个关键的问题需要解决:
-
开辟多大的缓冲区合适?缓冲区过小会造成读写次数的增加,过大也不能明显提高效率。目前大部分磁盘的扇区都是4K对齐的,如果读写的数据不是4K的整数倍,就会跨扇区读取,降低效率,所以我们开辟4K的缓冲区。
-
缓冲区中的数据是没有结束标志的,如果缓冲区填充不满,如何确定写入的字节数?最好的办法就是每次读取都能返回读取到的字节数。
fread() 的原型为:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );
它返回成功读写的块数,该值小于等于 count。如果我们让参数 size 等于1,那么返回的就是读取的字节数。
注意:fopen()一定要以二进制的形式打开文件,不能以文本形式打开,否则系统会对文件进行一些处理,如果是文本文件,像.txt等,可能没有问题,但如果是其他格式的文件,像.mp4, .rmvb, .jpg等,复制后就会出错,无法读取。
代码实现:
#include 运行结果:
要复制的文件:d://1.mp4
将文件复制到:d://2.mp4
恭喜你,文件复制成功!
如果文件不存在,会给出提示,并终止程序:
要复制的文件:d://123.mp4
将文件复制到:d://333.mp4
d://cyuyan.txt: No such file or directory
第46行是文件复制的核心代码。通过fread()函数,每次从 fileRead 文件中读取 bufferLen 个字节,放到缓冲区,再通过fwrite()函数将缓冲区的内容写入fileWrite文件。
正常情况下,每次会读取bufferLen个字节,即readCount=bufferLen;如果文件大小不足bufferLen个字节,或者读取到文件末尾,实际读取到的字节就会小于bufferLen,即readCount 在C语言中,用一个指针变量指向一个文件,这个指针称为文件指针。通过文件指针就可对它所指的文件进行各种操作。 定义文件指针的一般形式为: 这里的FILE,实际上是在stdio.h中定义的一个结构体,该结构体中含有文件名、文件状态和文件当前位置等信息,fopen 返回的就是FILE类型的指针。 注意:FILE是文件缓冲区的结构,fp也是指向文件缓冲区的指针。 不同编译器 stdio.h 头文件中对 FILE 的定义略有差异,这里以标准C举例说明: 下面说一下如果控制缓冲区。 我们知道,当我们从键盘输入数据的时候,数据并不是直接被我们得到,而是放在了缓冲区中,然后我们从缓冲区中得到我们想要的数据 。如果我们通过setbuf()或setvbuf()函数将缓冲区设置10个字节的大小,而我们从键盘输入了20个字节大小的数据,这样我们输入的前10个数据会放在缓冲区中,因为我们设置的缓冲区的大小只能够装下10个字节大小的数据,装不下20个字节大小的数据。那么剩下的那10个字节大小的数据怎么办呢?暂时放在了输入流中。请看下图: 上面的箭头表示的区域就相当是一个输入流,红色的地方相当于一个开关,这个开关可以控制往深绿色区域(标注的是缓冲区)里放进去的数据,输入20个字节的数据只往缓冲区中放进去了10个字节,剩下的10个字节的数据就被停留在了输入流里!等待下去往缓冲区中放入!接下来系统是如何来控制这个缓冲区呢? 再说一下 FILE 结构体中几个相关成员的含义: 在上面我们向缓冲区中放入了10个字节大小的数据,FILE结构体中的 cnt 变为了10 ,说明此时缓冲区中有10个字节大小的数据可以读,同时我们假设缓冲区的基地址也就是 base 是0x00428e60 ,它是不变的 ,而此时 ptr 的值也为0x00428e60 ,表示从0x00428e60这个位置开始读取数据,当我们从缓冲区中读取5个数据的时候,cnt 变为了5 ,表示缓冲区还有5个数据可以读,ptr 则变为了0x0042e865表示下次应该从这个位置开始读取缓冲区中的数据 ,如果接下来我们再读取5个数据的时候,cnt 则变为了0 ,表示缓冲区中已经没有任何数据了,ptr 变为了0x0042869表示下次应该从这个位置开始从缓冲区中读取数据,但是此时缓冲区中已经没有任何数据了,所以要将输入流中的剩下的那10个数据放进来,这样缓冲区中又有了10个数据,此时 cnt 变为了10 ,注意了刚才我们讲到 ptr 的值是0x00428e69 ,而当缓冲区中重新放进来数据的时候这个 ptr 的值变为了0x00428e60 ,这是因为当缓冲区中没有任何数据的时候要将 ptr 这个值进行一下刷新,使其指向缓冲区的基地址也就是0x0042e860这个值!因为下次要从这个位置开始读取数据! 在这里有点需要说明:当我们从键盘输入字符串的时候需要敲一下回车键才能够将这个字符串送入到缓冲区中,那么敲入的这个回车键(\r)会被转换为一个换行符\n,这个换行符\n也会被存储在缓冲区中并且被当成一个字符来计算!比如我们在键盘上敲下了123456这个字符串,然后敲一下回车键(\r)将这个字符串送入了缓冲区中,那么此时缓冲区中的字节个数是7 ,而不是6。 缓冲区的刷新就是将指针 ptr 变为缓冲区的基地址 ,同时 cnt 的值变为0 ,因为缓冲区刷新后里面是没有数据的! 实际开发中,有时候需要先获取文件大小再进行下一步操作。C语言没有提供获取文件大小的函数,要想实现该功能,必须自己编写函数。 ftell() 函数用来获取文件内部指针(位置指针)距离文件开头的字节数,它的原型为: 注意:fp 要以二进制方式打开,如果以文本方式打开,函数的返回值可能没有意义。 先使用 fseek() 将文件内部指针定位到文件末尾,再使用 ftell() 返回内部指针距离文件开头的字节数,这个返回值就等于文件的大小。请看下面的代码: 这段代码并不健壮,它移动了文件内部指针,可能会导致接下来的文件操作错误。例如: fread() 函数将永远读取不到内容。 所以,获取到文件大小后还需要恢复文件内部指针,请看下面的代码: fpos_t 是在 stdio.h 中定义的结构体,用来保存文件的内部指针。fgetpos() 用来获取文件内部指针,fsetpos() 用来设置文件内部指针。 完整的示例: 我们平时所见的文件,例如 txt、doc、mp4 等,文件内容是按照从头到尾的顺序依次存储在磁盘上的,就像排起一条长长的队伍,称为顺序文件。 除了顺序文件,还有索引文件、散列文件等,一般用于特殊领域,例如数据库、高效文件系统等。 顺序文件的存储结构决定了它能够高效读取内容,但不能够随意插入、删除和修改内容。例如在文件开头插入100个字节的数据,那么原来文件的所有内容都要向后移动100个字节,这不仅是非常低效的操作,而且还可能覆盖其他文件。因此C语言没有提供插入、删除、修改文件内容的函数,要想实现这些功能,只能自己编写函数。 以插入数据为例,假设原来文件的大小为 1000 字节,现在要求在500字节处插入用户输入的字符串,那么可以这样来实现: 删除数据时,也是类似的思路。假设原来文件大小为1000字节,名称为 demo.mp4,现在要求在500字节处往后删除100字节的数据,那么可以这样来实现: 修改数据时,如果新数据和旧数据长度相同,那么设置好内部指针,直接写入即可;如果新数据比旧数据长,相当于增加新内容,思路和插入数据类似;如果新数据比旧数据短,相当于减少内容,思路和删除数据类似。实际开发中,我们往往会保持新旧数据长度一致,以减少编程的工作量,所以我们不再讨论新旧数据长度不同的情况。 总起来说,本节重点讨论数据的插入和删除。 在数据的插入删除过程中,需要多次复制文件内容,我们有必要将该功能实现为一个函数,如下所示: 该函数可以将原文件任意位置的任意长度的内容复制到目标文件的任意位置,非常灵活。如果希望实现《C语言实现文件复制功能(包括文本文件和二进制文件)》一节中的功能,那么可以像这面这样调用: 请先看代码: 代码说明: fsize() 是在《C语言获取文件大小(长度)》自定义的函数,用来获取文件大小(以字节计)。 第17行判断数据的插入位置,如果是在文件末尾,就非常简单了,直接用 fwrite() 写入即可。 如果从文件开头或中间插入,就得创建临时文件。 tmpfile() 函数用来创建一个临时的二进制文件,可以读取和写入数据,相当于 fopen() 函数以"wb+"方式打开文件。该临时文件不会和当前已存在的任何文件重名,并且会在调用 fclose() 后或程序结束后自动删除。 请看下面的代码: 文件第5~7行用来判断传入的参数是否合法。freopen() 以"w+"方式打开文件时,如果有同名的文件存在,那么先将文件内容删除,作为一个新文件对待。 C++文件操作主要分为 2 类,即读文件和写文件,本章将介绍常见的C++文件操作,包括(但不限于)打开文件、读取和追加数据、插入和删除数据、关闭文件、删除文件等。 为了方便用户实现文件操作,C++提供了 3 个文件流类,分别是 ofstream(实现写文件)、ifstream(实现读文件)以及 fstream(实现读写文件),它们统称为“文件流类”。 关于文件操作,虽然在 C++ 程序中可以继续沿用 C 语言的那套文件操作方式,但更推荐使用适当的文件流类来读写文件。 内存中存放的数据在计算机关机后就会消失。要长久保存数据,就要使用硬盘、光盘、U 盘等设备。为了便于数据的管理和检索,引入了“文件”的概念。 一篇文章、一段视频、一个可执行程序,都可以被保存为一个文件,并赋予一个文件名。操作系统以文件为单位管理磁盘中的数据。 成千上万个文件如果不加分类放在一起,用户使用起来显然非常不便,因此又引入了树形目录(目录也叫文件夹)的机制,可以把文件放在不同的文件夹中,文件夹中还可以嵌套文件夹,这就便于用户对文件进行管理和使用,正如 Windows 的资源管理器呈现的那样。 一般来说,文件可分为文本文件、视频文件、音频文件、图像文件、可执行文件等多种类别,这是从文件的功能进行分类的。从数据存储的角度来说,所有的文件本质上都是一样的,都是由一个个字节组成的,归根到底都是 0、1 比特串。不同的文件呈现出不同的形态(有的是文本,有的是视频等等),这主要是文件的创建者和解释者(使用文件的软件)约定好了文件格式。 所谓“格式”,就是关于文件中每一部分的内容代表什么含义的一种约定。例如,常见的纯文本文件(也叫文本文件,扩展名通常是“.txt”),指的是能够在 Windows 的“记事本”程序中打开,并且能看出是一段有意义的文字的文件。文本文件的格式可以用一句话来描述:文件中的每个字节都是一个可见字符的 ASCII 码。 除了纯文本文件外,图像、视频、可执行文件等一般被称作“二进制文件”。二进制文件如果用“记事本”程序打开,看到的是一片乱码。 所谓“文本文件”和“二进制文件”,只是约定俗成的、从计算机用户角度出发进行的分类,并不是计算机科学的分类。因为从计算机科学的角度来看,所有的文件都是由二进制位组成的,都是二进制文件。文本文件和其他二进制文件只是格式不同而已。 实际上,只要规定好格式,而且不怕浪费空间,用文本文件一样可以表示图像、声音、视频甚至可执行程序。简单地说,如果约定用字符 ‘1’、‘2’、…、‘7’ 表示七个音符,那么由这些字符组成的文本文件就可以被遵从该约定的音乐软件演奏成一首曲子。 下面再看一个用文本文件表示一幅图像的例子:一幅图像实际上就是一个由点构成的矩阵,每个点可以有不同的颜色,称为像素。有的图像是 256 色的,有的是 32 位真彩色(即一 个像素的颜色用一个 32 位的整数表示)的。 以 256 色图像为例,可以用 0~255 这 256 个数代表 256 种颜色,那么每个像素就可以用一个数来表示。再约定文件开始的两个数代表图像的宽度和高度(以像素为单位),则以下文本文件就可以表示一幅宽度为 6 像素、高度为 4 像素的 256 色图像: 6 4 这个“文本图像”文件的格式可以描述为:第一行的两个数分别代表水平方向的像素数目和垂直方向的像素数目,此后每行代表图像的一行像素,一行中的每个数对应于一个像素,表示其颜色。理解这一格式的图像处理软件就可以把上述文本文件呈现为一幅图像。视频是由每秒 24 幅图像组成的,因此用文本文件也可以表示视频。 上面用文本文件表示图像的方法是非常低效的,浪费了太多的空间。文件中大量的空格是一种浪费。另外,常常要用 2 个甚至 3 个字符来表示一个像素,也造成大量浪费,因为用一个字节就足以表示 0~255 这 256 个数。因此,可以约定一个更节省空间的格式来表示一个 256 色的图像,此种文件格式的描述如下:文件中的第 0 和第 1 个字节是整数 n,代表图像的宽度(2 字节的 n 的取值范围是 0~65 535,说明图像最多只能是 65 535 个像素宽),第 2 和第 3 个字节代表图像的高度。接下来,每 n 个字节表示图像的一行像素,其中每个字节对应于一个像素的颜色。 用这种格式存储 256 色图像,比用上面的文本格式存储图像能够大大节省空间。在“记事本”程序中打开它,看到的就会是乱码,这个图像文件也就是所谓的“二进制文件”。 真正的图像文件、音频文件、视频文件的格式都比较复杂,有的还经过了压缩,但只要文件的制作软件和解读软件(如图像查看软件,音频、视频播放软件)遵循相同的格式约定,用户就可以在文件解读软件中看到文件的内容。 《C++输入输出流》一章中讲过,重定向后的 cin 和 cout 可分别用于读取文件中的数据和向文件中写入数据。除此之外,C++ 标准库中还专门提供了 3 个类用于实现文件操作,它们统称为文件流类,这 3 个类分别为: 值得一提的是,这 3 个文件流类都位于 头文件中,因此在使用它们之前,程序中应先引入此头文件。 这 3 个文件流类的继承关系,如图 1 所示。 可以看到,ifstream 类和 fstream 类是从 istream 类派生而来的,因此 ifstream 类拥有 istream 类的全部成员方法。同样地,ofstream 和 fstream 类也拥有 ostream 类的全部成员方法。这也就意味着,istream 和 ostream 类提供的供 cin 和 cout 调用的成员方法,也同样适用于文件流。并且这 3 个类中有些成员方法是相同的,比如 operator <<()、operator >>()、peek()、ignore()、getline()、get() 等。 值得一提的是,和 头文件中定义有 ostream 和 istream 类的对象 cin 和 cout 不同, 头文件中并没有定义可直接使用的 fstream、ifstream 和 ofstream 类对象。因此,如果我们想使用该类操作文件,需要自己创建相应类的对象。 为什么 C++ 标准库不提供现成的类似 fin 或者 fout 的对象呢?其实很简单,文件输入流和输出流的输入输出设备是硬盘中的文件,硬盘上有很多文件,到底应该使用哪一个呢?所以,C++ 标准库就把创建文件流对象的任务交给用户了。 fstream 类拥有 ifstream 和 ofstream 类中所有的成员方法,表 2 罗列了 fstream 类一些常用的成员方法。 表 2 中仅列举的了部分常用的成员方法,更详细的介绍,读者可查看 C++标准库手册。 这里就以 fstream 类举例,简单演示一下如何使用表 2 中的一些成员方法操作文件: 执行程序,该程序同目录下会生成一个 test.txt 文件,该文件的内容为: http://c.biancheng.net/cplus/ 注意,初学者只需借助注释看懂程序执行流程即可,具体的代码实现不必深究,后续章节会做详细讲解。 值得一提的是,无论是读取文件中的数据,还是向文件中写入数据,最先要做的就是调用 open() 成员方法打开文件。同时在操作文件结束后,还必须要调用 close() 成员方法关闭文件。关于如何使用 open() 函数打开一个文件,下一节会做详细介绍。 在对文件进行读写操作之前,先要打开文件。打开文件有以下两个目的: 打开文件可以通过以下两种方式进行: 先看第一种文件打开方式。以 ifstream 类为例,该类有一个 open 成员函数,其他两个文件流类也有同样的 open 成员函数: void open(const char* szFileName, int mode) 第一个参数是指向文件名的指针,第二个参数是文件的打开模式标记。 文件的打开模式标记代表了文件的使用方式,这些标记可以单独使用,也可以组合使用。表 1 列出了各种模式标记单独使用时的作用,以及常见的两种模式标记组合的作用。 ios::binary 可以和其他模式标记组合使用,例如: 文本方式与二进制方式打开文件的区别其实非常微小,我会在《文件的文本打开方式和二进制打开方式的区别》一节中专门解释。一般来说,如果处理的是文本文件,那么用文本方式打开会方便一些。但其实任何文件都可以以二进制方式打开来读写。 在流对象上执行 open 成员函数,给出文件名和打开模式,就可以打开文件。判断文件打开是否成功,可以看“对象名”这个表达式的值是否为 true,如果为 true,则表示文件打开成功。 下面的程序演示了如何打开文件: 调用 open 成员函数时,给出的文件名可以是全路径的,如第 7 行的 第 18 行的 定义流对象时,在构造函数中给出文件名和打开模式也可以打开文件。以 ifstream 类为例,它有如下构造函数: ifstream::ifstream (const char* szFileName, int mode = ios::in, int); 第一个参数是指向文件名的指针;第二个参数是打开文件的模式标记,默认值为 在定义流对象时打开文件的示例程序如下(用流类的构造函数打开文件): 注意,当不再对打开的文件进行任何操作时,应及时调用 close() 成员方法关闭文件。有关该方法的用法,后续会做详细讲解。 在学习了 C++ 文件流对象使用 open() 打开文件后,我们知道它的第二个参数是一个字符串,用来表示文件打开方式,即如果使用 ios::binary,则表示以二进制方式打开文件;反之,则以文本文件的方式打开文件。 根据我们以往的经验,文本文件通常用来保存肉眼可见的字符,比如 .txt文件、.c文件、.dat文件等,用文本编辑器打开这些文件,我们能够顺利看懂文件的内容。 二进制文件通常用来保存视频、图片、程序等不可阅读的内容,用文本编辑器打开这些文件,会看到一堆乱码,根本看不懂。 但是从物理上讲,二进制文件和字符文件并没有什么区别,它们都是以二进制的形式保存在磁盘上的数据。 我们之所以能看懂文本文件的内容,是因为文本文件中采用的是 ASCII、UTF-8、GBK 等字符编码,文本编辑器可以识别出这些编码格式,并将编码值转换成字符展示出来。 而二进制文件使用的是 mp4、gif、exe 等特殊编码格式,文本编辑器并不认识这些编码格式,只能按照字符编码格式胡乱解析,所以就成了一堆乱七八糟的字符,有的甚至都没见过。 如果我们新建一个 mp4 文件,给它写入一串字符,然后再用文本编辑器打开,你一样可以读得懂,有兴趣的读者可以自己试试。 总的来说,不同类型的文件有不同的编码格式,必须使用对应的程序(软件)才能正确解析,否则就是一堆乱码,或者无法使用。 文本方式和二进制方式并没有本质上的区别,只是对于换行符的处理不同。 在 UNIX/Linux 平台中,用文本方式或二进制方式打开文件没有任何区别,因为文本文件以 \n(ASCII 码为 0x0a)作为换行符号。 但在 Windows 平台上,文本文件以连在一起的 \r\n 作为换行符号。如果以文本方式打开文件,当读取文件时,程序会将文件中所有的 \r\n 转换成一个字符 \n。也就是说,如果文本文件中有连续的两个字符是 \r\n,则程序会丢弃前面的 \r,只读入 \n。 同样当写入文件时,程序会将 \n 转换成 \r\n 写入。也就是说,如果要写入的内容中有字符 \n,则在写入该字符前,程序会自动先写入一个 \r。 因此在 Windows 平台上,如果用文本方式打开二进制文件进行读写,读写的内容就可能和文件的内容有出入。 总的来说,Linux 平台使用哪种打开方式都行;Windows 平台上最好用 “ios::in | ios::out” 等打开文本文件,用 “ios::binary” 打开二进制文件。但无论哪种平台,用二进制方式打开文件总是最保险的。 《C++ open打开文件》一节中,详细介绍了文件流对象如何调用 open() 成员方法打开指定文件。相对应地,文件流对象还可以主动关闭先前打开的文件,即调用 close() 成员方法。 我们知道,调用 open() 方法打开文件,是文件流对象和文件之间建立关联的过程。那么,调用 close() 方法关闭已打开的文件,就可以理解为是切断文件流对象和文件之间的关联。注意,close() 方法的功能仅是切断文件流与文件之间的关联,该文件流并会被销毁,其后续还可用于关联其它的文件。 close() 方法的用法很简单,其语法格式如下: void close( ) 可以看到,该方法既不需要传递任何参数,也没有返回值。 举个例子: 运行程序,在该程序同目录下会生成一个 url.txt 文件,其内部存储的数据为: http://c.biancheng.net/cplus/ 有些读者可能发现,即便上面程序中不调用 close() 方法,也能成功向 url.txt 文件中写入 url 字符串。这是因为,当文件流对象的生命周期结束时,会自行调用其析构函数,该函数内部在销毁对象之前,会先调用 close() 方法切断它与任何文件的关联,最后才销毁它。 强烈建议读者,使用 open() 方法打开的文件,一定要手动调用 close() 方法关闭,这样可以避免程序发生一些奇葩的错误! 值得一提的是,《C++处理输入输出错误》一节中介绍了 4 种流状态,它们也同样适用于文件流。当文件流对象未关联任何文件时,调用 close() 方法会失败,其会为文件流设置 failbit 状态标志,该标志可以被 fail() 成员方法捕获。例如: 程序执行结果为: 文件操作过程发生了错误! 通过前面的学习我们知道,C++ 使用 open() 方法打开文件,使用 close() 方法关闭文件。例如(程序一): 执行该程序,会生成一个 out.txt 文件,内部存有如下内容: http://c.biancheng.net/cplus/ 前面提到,在某些情况下(例如上面程序中),即便不显式调用 close() 方法,文件的读写操作也能成功执行。因为当文件流对象的生命周期结束时,会自行调用析构函数,此函数内部会先调用 close() 方法切断文件流对象与任何文件的关联,最后才销毁它。 那么,既然文件流对象自行销毁时会隐式调用 close() 方法,是不是就不用显式调用 close() 方法了呢? 当然不是。在实际进行文件操作的过程中,对于打开的文件,要及时调用 close() 方法将其关闭,否则很可能会导致读写文件失败。 举个例子(程序二): 通过对比不难发现,此程序和程序一唯一的区别在于,第 17 行添加了抛出异常的语句。由于程序中没有对抛出的异常进行处理,因此当程序执行到此行时会崩溃。 更重要的是,第 17 行会导致文件写入操作失败。执行此程序,同样会生成 out.txt 文件,但 “http:c.biancheng.net/cplus/” 字符串并没有成功被写入。 也就是说,对于已经打开的文件,如果不及时关闭,一旦程序出现异常,则很可能会导致之前读写文件的所有操作失效。在程序二的基础上,如果将第 17 行代码和第 19 行代码互换,再次执行程序会发现,虽然程序执行仍会崩溃,但 “http:c.biancheng.net/cplus/” 字符串可以被成功写入到 out.txt 文件中。 在很多实际场景中,即便已经对文件执行了写操作,但后续还可能会执行其他的写操作。对于这种情况,我们可能并不想频繁地打开/关闭文件,可以使用 flush() 方法及时刷新输出流缓冲区,也能起到防止写入文件失败的作用。 程序二之所以写入文件失败,是因为 << 写入运算符会先将 url 字符串写入到输出流缓冲区中,待缓冲区满或者关闭文件时,数据才会由缓冲区写入到文件中。但直到程序崩溃,close() 方法也没有得到执行,且 destFile 对象也没有正常销毁,所以 url 字符串一直存储在缓冲区中,没有写入到文件中。 比如,修改程序二的代码: 可以看到,在程序二的基础上,在第 17 行调用了 flush() 方法。再次执行程序,虽然仍执行崩溃,但 “http://c.baincheng.net/cplus/” 字符串成功写入到了 out.txt 文件中。 总之,C++ 中使用 open() 打开的文件,在读写操作执行完毕后,应及时调用 close() 方法关闭文件,或者对文件执行写操作后及时调用 flush() 方法刷新输出流缓冲区。 前面章节中,已经给大家介绍了文件流对象如何调用 open() 方法打开文件,并且在读写(又称 I/O )文件操作结束后,应调用 close() 方法关闭先前打开的文件。那么,如何实现对文件内容的读写呢?接下来就对此问题做详细的讲解。 在讲解具体读写文件的方法之前,读者首先要搞清楚的是,对文件的读/写操作又可以细分为 2 类,分别是以文本形式读写文件和以二进制形式读写文件。 我们知道,文件中存储的数据并没有类型上的分别,统统都是字符。所谓以文本形式读/写文件,就是直白地将文件中存储的字符(或字符串)读取出来,以及将目标字符(或字符串)存储在文件中。 而以二进制形式读/写文件,操作的对象不再是打开文件就能看到的字符,而是文件底层存储的二进制数据。更详细地讲,当以该形式读取文件时,读取的是该文件底层存储的二进制数据;同样,当将某数据以二进制形式写入到文件中时,写入的也是其对应的二进制数据。 举个例子,假设我们以文本形式将浮点数 19.625 写入文件,则该文件会直接将 “19.625” 这个字符串存储起来。当我们双击打开此文件,也可以看到 19.625。值得一提的是,由非字符串数据(比如这里的浮点数 19.625)转换为对应字符串(转化为 “19.625”)的过程,C++ 标准库已经实现好了,不需要我们操心。 但如果以二进制形式将浮点数 19.625 写入文件,则该文件存储的不再是 “19.625” 这个字符串,而是 19.625 浮点数对应的二进制数据。以 float 类型的 19.625 来说,文件最终存储的数据如下所示: 0100 0001 1001 1101 0000 0000 0000 0000 至于如何得出 float 类型的 19.625 对应的二进制,感兴趣的读者可阅读《小数在内存中是如何存储的》一节。 显然,如果直接将以上二进制数据转换为 float 类型,仍可以得到浮点数 19.625。但对于文件来说,它只会将存储的二进制数据根据既定的编码格式(如 utf-8、gbk 等)转换为一个个字符。这也就意味着,如果我们直接打开此文件,看到的并不会是 19.625,往往是一堆乱码。 C++ 标准库中,提供了 2 套读写文件的方法组合,分别是: 本节先讲解如何用 >> 和 << 实现以文本形式读写文件,至于如何实现以二进制形式读写文件,下一节会做详细介绍。 通过《C++文件流类》一节的学习我们知道,fstream 或者 ifstream 类负责实现对文件的读取,它们内部都对 >> 输出流运算符做了重载;同样,fstream 和 ofstream 类负责实现对文件的写入,它们的内部也都对 << 输出流运算符做了重载。 所以,当 fstream 或者 ifstream 类对象打开文件(通常以 ios::in 作为打开模式)之后,就可以直接借助 >> 输入流运算符,读取文件中存储的字符(或字符串);当 fstream 或者 ofstream 类对象打开文件(通常以 ios::out 作为打开模式)后,可以直接借助 << 输出流运算符向文件中写入字符(或字符串)。 举个例子: 注意,此程序中分别采用 ios::in 和 ios::out 打开文件,即以文本模式而非二进制模式打开文件。感兴趣的读者可在其基础上添加 ios::binary,即以二进制模式打开文件,程序依旧会正常执行。这是因为,以文本模式打开文件和以二进制模式打开文件,并没有很大的区别(后续章节会做详细讲解)。 执行此程序之前,必须在和该程序源文件同目录中手动创建一个 in.txt 文件,假设其内部存储的字符串为: 10 20 30 40 50 建立之后,执行程序,其执行结果为: sum:150 同时在 in.txt 文件同目录下,会生成一个 out.txt 文件,其内部存储的字符和 in.txt 文件完全一样,读者可自行打开文件查看。 通过分析程序的执行结果不难理解,对于 in.txt 文件中的 “10 20 30 40 50” 字符串,srcFile 对象会依次将 “10”、“20”、“30”、“40”、“50” 读取出来,将它们解析成 int 类型的整数 10、20、30、40、50 并赋值给 x,同时完成和 sum 的加和操作。 同样,对于每次从 in.txt 文件读取并解析出的整形 x,destFile 对象都会原封不动地将其再解析成对应的字符串(如整数 10 解析成字符串 “10”),然后和 " " 空格符一起写入 out.txt 文件。 通过《C++文本文件读写操作》一节的学习,读者了解了以文本形式读写文件和以二进制形式读写文件的区别,并掌握了用重载的 >> 和 << 运算符实现以文本形式读写文件。在此基础上,本节继续讲解如何以二进制形式读写文件。 不过介绍具体的实现方法前,先给读者介绍一下相比以文本形式读写文件,以二进制形式读写文件有哪些好处? 举个例子,现在要做一个学籍管理程序,其中一个重要的工作就是记录学生的学号、姓名、年龄等信息。这意味着,我们需要用一个类来表示学生,如下所示: 前面章节中,我们学会了如何以文本形式读写文件,如果使用此方式存储学生的信息,则最终的文件中存储的学生信息可能是这个样子: Micheal Jackson 110923412 17 要知道,这种存储学生信息的方式不但浪费空间,而且后期不利于查找指定学生的信息(查找效率低下),因为每个学生的信息所占用的字节数不同。 这种情况下,以二进制形式将学生信息存储到文件中,是非常不错的选择,因为以此形式存储学生信息,可以直接把 CStudent 对象写入文件中,这意味着每个学生的信息都只占用 sizeof(CStudent) 个字节。 值得一提的是,要实现以二进制形式读写文件,<< 和 >> 将不再适用,需要使用 C++ 标准库专门提供的 read() 和 write() 成员方法。其中,read() 方法用于以二进制形式从文件中读取数据;write() 方法用于以二进制形式将数据写入文件。 ofstream 和 fstream 的 write() 成员方法实际上继承自 ostream 类,其功能是将内存中 buffer 指向的 count 个字节的内容写入文件,基本格式如下: ostream & write(char* buffer, int count); 其中,buffer 用于指定要写入文件的二进制数据的起始位置;count 用于指定写入字节的个数。 也就是说,该方法可以被 ostream 类的 cout 对象调用,常用于向屏幕上输出字符串。同时,它还可以被 ofstream 或者 fstream 对象调用,用于将指定个数的二进制数据写入文件。 同时,该方法会返回一个作用于该函数的引用形式的对象。举个例子,obj.write() 方法的返回值就是对 obj 对象的引用。 需要注意的一点是,write() 成员方法向文件中写入若干字节,可是调用 write() 函数时并没有指定这些字节写入文件中的具体位置。事实上,write() 方法会从文件写指针指向的位置将二进制数据写入。所谓文件写指针,是是 ofstream 或 fstream 对象内部维护的一个变量,文件刚打开时,文件写指针指向的是文件的开头(如果以 ios::app 方式打开,则指向文件末尾),用 write() 方法写入 n 个字节,写指针指向的位置就向后移动 n 个字节。 下面的程序演示了如何将学生信息以二进制形式写入文件: 输入: Tom 60↙ 其中, 执行程序后,会自动生成一个 students.dat 文件,其内部存有 72 字节的数据,如果用“记事本”打开此文件,可能看到如下乱码: Tom 烫烫烫烫烫烫烫烫< Jack 烫烫烫烫烫烫烫蘌 Jane 烫烫烫烫烫烫烫? 值得一提的是,程序中第 13 行指定文件的打开模式为 ios::out | ios::binary,即以二进制写模式打开。在 Windows平台中,以二进制模式打开文件是非常有必要的,否则可能出错,原因会在《文件的文本打开方式和二进制打开方式的区别》一节中介绍。 另外,第 15 行将 s 对象写入文件。s 的地址就是要写入文件的内存缓冲区的地址,但是 &s 不是 char * 类型,因此要进行强制类型转换;第 16 行,文件使用完毕一定要关闭,否则程序结束后文件的内容可能不完整。 ifstream 和 fstream 的 read() 方法实际上继承自 istream 类,其功能正好和 write() 方法相反,即从文件中读取 count 个字节的数据。该方法的语法格式如下: istream & read(char* buffer, int count); 其中,buffer 用于指定读取字节的起始位置,count 指定读取字节的个数。同样,该方法也会返回一个调用该方法的对象的引用。 和 write() 方法类似,read() 方法从文件读指针指向的位置开始读取若干字节。所谓文件读指针,可以理解为是 ifstream 或 fstream 对象内部维护的一个变量。文件刚打开时,文件读指针指向文件的开头(如果以 ios::app 方式打开,则指向文件末尾),用 read() 方法读取 n 个字节,读指针指向的位置就向后移动 n 个字节。因此,打开一个文件后连续调用 read() 方法,就能将整个文件的内容读取出来。 通过执行 write() 方法的示例程序,我们将 3 个学生的信息存储到了 students.dat 文件中,下面程序演示了如何使用 read() 方法将它们读取出来: 程序的输出结果是: Tom 60 注意,程序中第 18 行直接将 read() 方法作为 while 循环的判断条件,这意味着,read() 方法会一直读取到文件的末尾,将所有字节全部读取完毕,while 循环才会终止。 另外,在使用 read() 方法的同时,如果想知道一共成功读取了多少个字节(读到文件尾时,未必能读取 count 个字节),可以在 read() 方法执行后立即调用文件流对象的 gcount() 成员方法,其返回值就是最近一次 read() 方法成功读取的字节数。感兴趣的读者可自行尝试,这里不再做具体演示。 在某些特殊的场景中,我们可能需要逐个读取文件中存储的字符,或者逐个将字符存储到文件中。这种情况下,就可以调用 get() 和 put() 成员方法实现。 通过《C++ cout.put()》一节的学习,读者掌握了如何通过执行 cout.put() 方法向屏幕输出单个字符。我们知道,fstream 和 ofstream 类继承自 ostream 类,因此 fstream 和 ofstream 类对象都可以调用 put() 方法。 当 fstream 和 ofstream 文件流对象调用 put() 方法时,该方法的功能就变成了向指定文件中写入单个字符。put() 方法的语法格式如下: ostream& put (char c); 其中,c 用于指定要写入文件的字符。该方法会返回一个调用该方法的对象的引用形式。例如,obj.put() 方法会返回 obj 这个对象的引用。 举个例子: 执行程序,输入: http://c.biancheng.net/cplus/↙ 其中, 由此,程序中通过执行 while 循环,会将 “http://c.biancheng.net/cplus/” 字符串的字符逐个复制给变量 c,并逐个写入到 out.txt 文件。 注意,由于文件存放在硬盘中,硬盘的访问速度远远低于内存。如果每次写一个字节都要访问硬盘,那么文件的读写速度就会慢得不可忍受。因此,操作系统在接收到 put() 方法写文件的请求时,会先将指定字符存储在一块指定的内存空间中(称为文件流输出缓冲区),等刷新该缓冲区(缓冲区满、关闭文件、手动调用 flush() 方法等,都会导致缓冲区刷新)时,才会将缓冲区中存储的所有字符“一股脑儿”全写入文件。 和 put() 成员方法的功能相对的是 get() 方法,其定义在 istream 类中,借助 cin.get() 可以读取用户输入的字符。在此基础上,fstream 和 ifstream 类继承自 istream 类,因此 fstream 和 ifstream 类的对象也能调用 get() 方法。 当 fstream 和 ifstream 文件流对象调用 get() 方法时,其功能就变成了从指定文件中读取单个字符(还可以读取指定长度的字符串)。值得一提的是,get() 方法的语法格式有很多(请猛击这里了解详情),这里仅介绍最常用的 2 种: int get(); 其中,第一种语法格式的返回值就是读取到的字符,只不过返回的是它的 ASCII 码,如果碰到输入的末尾,则返回值为 EOF。第二种语法格式需要传递一个字符变量,get() 方法会自行将读取到的字符赋值给这个变量。 本节前面在讲解 put() 方法时,生成了一个 out.txt 文件,下面的样例演示了如何通过 get() 方法逐个读取 out.txt 文件中的字符: 程序执行结果为: http://c.biancheng.net/cplus/ 注意,和 put() 方法一样,操作系统在接收到 get() 方法的请求后,哪怕只读取一个字符,也会一次性从文件中将很多数据(通常至少是 512 个字节,因为硬盘的一个扇区是 512 B)读到一块内存空间中(可称为文件流输入缓冲区),这样当读取下一个字符时,就不需要再访问硬盘中的文件,直接从该缓冲区中读取即可。 《cin.getline()》一节中,详细介绍了如何使用 getline() 方法从 cin 输入流缓冲区中读取一行字符串。在此基础上,getline() 方法还适用于读取指定文件中的一行数据,本节就给大家做详细的讲解。 我们知道,getline() 方法定义在 istream 类中,而 fstream 和 ifstream 类继承自 istream 类,因此 fstream 和 ifstream 的类对象可以调用 getline() 成员方法。 当文件流对象调用 getline() 方法时,该方法的功能就变成了从指定文件中读取一行字符串。该方法有以下 2 种语法格式: istream & getline(char* buf, int bufSize); 其中,第一种语法格式用于从文件输入流缓冲区中读取 bufSize-1 个字符到 buf,或遇到 \n 为止(哪个条件先满足就按哪个执行),该方法会自动在 buf 中读入数据的结尾添加 ‘\0’。 第二种语法格式和第一种的区别在于,第一个版本是读到 \n 为止,第二个版本是读到 delim 字符为止。\n 或 delim 都不会被读入 buf,但会被从文件输入流缓冲区中取走。 以上 2 种格式中,getline() 方法都会返回一个当前所作用对象的引用。比如,obj.getline() 会返回 obj 的引用。 注意,如果文件输入流中 \n 或 delim 之前的字符个数达到或超过 bufSize,就会导致读取失败。 举个例子: 假设 in.txt 文件中存有如下字符串: http://c.biancheng.net/cplus/ 则程序执行结果为: http://c.biancheng.net/cplus/ 当然,我们也可以使用 getline() 方法的第二种语法格式。例如,更改上面程序中第 15 行代码为: 这意味着,一旦遇到字符 ‘c’,getline() 方法就会停止读取。 再次运行程序,其输出结果为: http:// 另外,如果想读取文件中的多行数据,可以这样做: 假设 in.txt 文件中存有如下数据: http://c.biancheng.net/cplus/ 则程序执行结果为: http://c.biancheng.net/cplus/ 在读写文件时,有时希望直接跳到文件中的某处开始读写,这就需要先将文件的读写指针指向该处,然后再进行读写。 所谓“位置”,就是指距离文件开头有多少个字节。文件开头的位置是 0。 这两个函数的原型如下: ostream & seekp (int offset, int mode); mode 代表文件读写指针的设置模式,有以下三种选项: 此外,我们还可以得到当前读写指针的具体位置: 这两个成员函数的原型如下: int tellg(); 要获取文件长度,可以用 seekg 函数将文件读指针定位到文件尾部,再用 tellg 函数获取文件读指针的位置,此位置即为文件长度。 例题:假设学生记录文件 students.dat 是按照姓名排好序的,编写程序,在 students.dat 文件中用折半查找的方法找到姓名为 Jack 的学生记录,并将其年龄改为 20(假设文件很大,无法全部读入内存)。程序如下:C语言FILE结构体以及缓冲区深入探讨
FILE *fp;
typedef struct _iobuf {
int cnt; // 剩余的字符,如果是输入缓冲区,那么就表示缓冲区中还有多少个字符未被读取
char *ptr; // 下一个要被读取的字符的地址
char *base; // 缓冲区基地址
int flag; // 读写状态标志位
int fd; // 文件描述符
// 其他成员
} FILE;

cnt // 剩余的字符,如果是输入缓冲区,那么就表示缓冲区中还有多少个字符未被读取
ptr // 下一个要被读取的字符的地址
base // 缓冲区基地址C语言获取文件大小(长度)
ftell()函数
long int ftell ( FILE * fp );
long fsize(FILE *fp){
fseek(fp, 0, SEEK_END);
return ftell(fp);
}
long size = fsize(fp);
fread(buffer, 1, 1, fp);
long fsize(FILE *fp){
long n;
fpos_t fpos; //当前位置
fgetpos(fp, &fpos); //获取当前位置
fseek(fp, 0, SEEK_END);
n = ftell(fp);
fsetpos(fp,&fpos); //恢复之前的位置
return n;
}
#includeC语言插入、删除、更改文件内容
文件复制函数
/**
* 文件复制函数
* @param fSource 要复制的原文件
* @param offsetSource 原文件的位置偏移(相对文件开头),也就是从哪里开始复制
* @param len 要复制的内容长度,小于0表示复制offsetSource后边的所有内容
* @param fTarget 目标文件,也就是将文件复制到哪里
* @param offsetTarget 目标文件的位置偏移,也就是复制到目标文件的什么位置
* @return 成功复制的字节数
**/
long fcopy(FILE *fSource, long offsetSource, long len, FILE *fTarget, long offsetTarget){
int bufferLen = 1024*4; // 缓冲区长度
char *buffer = (char*)malloc(bufferLen); // 开辟缓存
int readCount; // 每次调用fread()读取的字节数
long nBytes = 0; //总共复制了多少个字节
int n = 0; //需要调用多少次fread()函数
int i; //循环控制变量
fseek(fSource, offsetSource, SEEK_SET);
fseek(fTarget, offsetTarget, SEEK_SET);
if(len<0){ //复制所有内容
while( (readCount=fread(buffer, 1, bufferLen, fSource)) > 0 ){
nBytes += readCount;
fwrite(buffer, readCount, 1, fTarget);
}
}else{ //复制len个字节的内容
n = (int)ceil((double)((double)len/bufferLen));
for(i=1; i<=n; i++){
if(len-nBytes < bufferLen){ bufferLen = len-nBytes; }
readCount = fread(buffer, 1, bufferLen, fSource);
fwrite(buffer, readCount, 1, fTarget);
nBytes += readCount;
}
}
fflush(fTarget);
free(buffer);
return nBytes;
}
fcopy(fSource, 0, -1, fTarget, 0);
文件内容插入函数
/**
* 向文件中插入内容
* @param fp 要插入内容的文件
* @param buffer 缓冲区,也就是要插入的内容
* @param offset 偏移量(相对文件开头),也就是从哪里开始插入
* @param len 要插入的内容长度
* @return 成功插入的字节数
**/
int finsert(FILE *fp, long offset, void *buffer, int len){
long fileSize = fsize(fp);
FILE *fpTemp; //临时文件
if(offset>fileSize || offset<0 || len<0){ //插入错误
return -1;
}
if(offset == fileSize){ //在文件末尾插入
fseek(fp, offset, SEEK_SET);
if(!fwrite(buffer, len, 1, fp)){
return -1;
}
}
if(offset < fileSize){ //从开头或者中间位置插入
fpTemp = tmpfile();
fcopy(fp, 0, offset, fpTemp, 0);
fwrite(buffer, len, 1, fpTemp);
fcopy(fp, offset, -1, fpTemp, offset+len);
freopen(FILENAME, "wb+", fp );
fcopy(fpTemp, 0, -1, fp, 0);
fclose(fpTemp);
}
return 0;
}
文件内容删除函数
int fdelete(FILE *fp, long offset, int len){
long fileSize = getFileSize(fp);
FILE *fpTemp;
if(offset>fileSize || offset<0 || len<0){ //错误
return -1;
}
fpTemp = tmpfile();
fcopy(fp, 0, offset, fpTemp, 0); //将前offset字节的数据复制到临时文件
fcopy(fp, offset+len, -1, fpTemp, offset); //将offset+len之后的所有内容都复制到临时文件
freopen(FILENAME, "wb+", fp ); //重新打开文件
fcopy(fpTemp, 0, -1, fp, 0);
fclose(fpTemp);
return 0;
}
三、C++文件操作
计算机文件到底是什么(通俗易懂)?
24 0 38 129 4 154
12 73 227 40 0 0
12 173 127 20 0 0
21 73 87 230 1 0C++文件类(文件流类)及用法详解

图1:C++类库中的流类
成员方法名
适用类对象
功 能
open()
fstream ifstream ofstream
打开指定文件,使其与文件流对象相关联。
is_open()
检查指定文件是否已打开。
close()
关闭文件,切断和文件流对象的关联。
swap()
交换 2 个文件流对象。
operator>>
fstream ifstream
重载 >> 运算符,用于从指定文件中读取数据。
gcount()
返回上次从文件流提取出的字符个数。该函数常和 get()、getline()、ignore()、peek()、read()、readsome()、putback() 和 unget() 联用。
get()
从文件流中读取一个字符,同时该字符会从输入流中消失。
getline(str,n,ch)
从文件流中接收 n-1 个字符给 str 变量,当遇到指定 ch 字符时会停止读取,默认情况下 ch 为 ‘\0’。
ignore(n,ch)
从文件流中逐个提取字符,但提取出的字符被忽略,不被使用,直至提取出 n 个字符,或者当前读取的字符为 ch。
peek()
返回文件流中的第一个字符,但并不是提取该字符。
putback©
将字符 c 置入文件流(缓冲区)。
operator<<
fstream ofstream
重载 << 运算符,用于向文件中写入指定数据。
put()
向指定文件流中写入单个字符。
write()
向指定文件中写入字符串。
tellp()
用于获取当前文件输出流指针的位置。
seekp()
设置输出文件输出流指针的位置。
flush()
刷新文件输出流缓冲区。
good()
fstream ofstream ifstream
操作成功,没有发生任何错误。
eof()
到达输入末尾或文件尾。
#include
C++ open 打开文件(含打开模式一览表)
使用 open 函数打开文件
模式标记
适用对象
作用
ios::in
ifstream fstream
打开文件用于读取数据。如果文件不存在,则打开出错。
ios::out
ofstream fstream
打开文件用于写入数据。如果文件不存在,则新建该文件;如果文件原来就存在,则打开时清除原来的内容。
ios::app
ofstream fstream
打开文件,用于在其尾部添加数据。如果文件不存在,则新建该文件。
ios::ate
ifstream
打开一个已有的文件,并将文件读指针指向文件末尾(读写指 的概念后面解释)。如果文件不存在,则打开出错。
ios:: trunc
ofstream
打开文件时会清空内部存储的所有数据,单独使用时与 ios::out 相同。
ios::binary
ifstream ofstream fstream
以二进制方式打开文件。若不指定此模式,则以文本模式打开。
ios::in | ios::out
fstream
打开已存在的文件,既可读取其内容,也可向其写入数据。文件刚打开时,原有内容保持不变。如果文件不存在,则打开出错。
ios::in | ios::out
ofstream
打开已存在的文件,可以向其写入数据。文件刚打开时,原有内容保持不变。如果文件不存在,则打开出错。
ios::in | ios::out | ios::trunc
fstream
打开文件,既可读取其内容,也可向其写入数据。如果文件本来就存在,则打开时清除原来的内容;如果文件不存在,则新建该文件。
ios::in | ios::binary表示用二进制模式,以读取的方式打开文件。ios::out | ios::binary表示用二进制模式,以写入的方式打开文件。#include c:\\tmp\\test.txt, 指明文件在 c 盘的 tmp 文件夹中;也可以只给出文件名,如第 13 行的test1.txt,这种情况下程序会在当前文件夹(也就是可执行程序所在的文件夹)中寻找要打开的文件。tmp\\test2.txt给出的是相对路径,说明 test2.txt 位于当前文件夹的 tmp 子文件夹中。第 24 行的..\\test3.txt也是相对路径,代表上一层文件夹,此时要到当前文件夹的上一层文件夹中查找 test3.txt。此外,..\\..\\test4.txt、..\\tmp\\test4.txt等都是合法的带相对路径的文件名。使用流类的构造函数打开文件
ios::in; 第三个参数是整型的,也有默认值,一般极少使用。#include
文本打开方式和二进制打开方式的区别是什么?
文本文件和二进制文件的区别
两种打开方式的区别
C++ close()关闭文件方法详解
#include
#include C++打开的文件一定要用close()方法关闭!
#include #include C++ flush()刷新缓冲区
#include C++文本文件读写操作详解
C++ >>和<<读写文本文件
#include
class CStudent
{
char szName[20]; //假设学生姓名不超过19个字符,以 '\0' 结尾
char szId[l0]; //假设学号为9位,以 '\0' 结尾
int age; //年龄
};
Tom Hanks 110923413 18
…C++ ostream::write()方法写文件
#include
Jack 80↙
Jane 40↙
^Z↙↙表示输出换行符,^Z 表示输入Ctrl+Z组合键结束输入。C++ istream::read()方法读文件
#include
Jack 80
Jane 40
C++ get()和put()读写文件详解
C++ ostream::put()成员方法
#include
^Z↙
↙表示输入换行符;^Z是 Ctrl+Z 的组合键,表示输入结束。
C++ istream::get()成员方法
istream& get (char& c);#include C++ getline():从文件中读取一行字符串
istream & getline(char* buf, int bufSize, char delim);
#include inFile.getline(c,40,'c');
#include
http://c.biancheng.net/python/
http://c.biancheng.net/java/
http://c.biancheng.net/python/
http://c.biancheng.net/java/C++移动和获取文件读写指针(seekp、seekg、tellg、tellp)
istream & seekg (int offset, int mode);
int tellp();#include