【Linux】进程地址空间
文章目录
- 一、内存布局引入
- 二、程序地址空间
-
- 1.现象解释
- 2.什么是地址空间
- 3.为什么要有程序地址空间?
- 再谈页表
-
- 浅谈缺页中断
- 重新理解进程概念
- 总结
一、内存布局引入
以前学习c语言的时候知道,内存的大致布局如下:
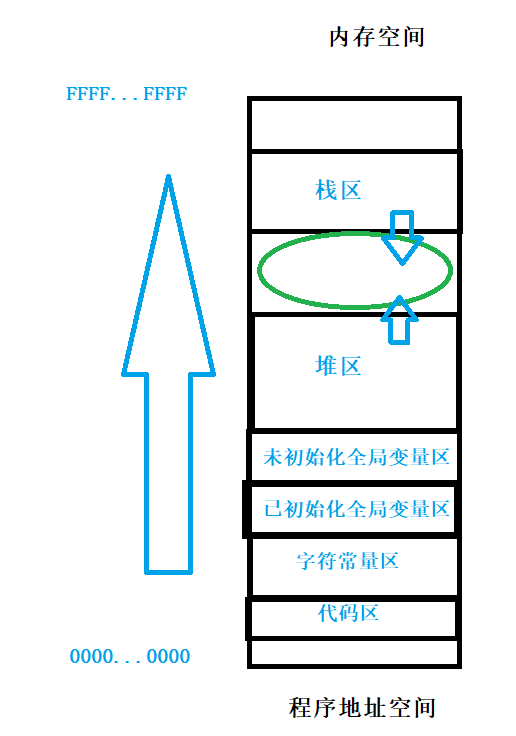
从前这段区域是叫做内存空间,实际上这段空间是程序地址空间。
下面来一段代码验证一下这段空间的地址的分布:
37 int g_val_1;
38 int g_val_2 = 100;
39
40 int main()
41 {
42 printf("code addr:%p\n",main);
43
44 const char* str = "hello linux";
45 printf("read only string addr:%p\n",str);
46 printf("init global value addr:%p\n",&g_val_2);
47 printf("uninit global value addr:%p\n",&g_val_1);
48 char *mem = (char*)malloc(sizeof(char)*100);
49 char *mem1 = (char*)malloc(sizeof(char)*100);
50 char *mem2 = (char*)malloc(sizeof(char)*100);
51 printf("heap addr:%p\n",mem);
52 printf("heap addr:%p\n",mem1);
53 printf("heap addr:%p\n",mem2);
54
55 printf("stack addr:%p\n",&str);
56 printf("stack addr:%p\n",&mem);
57 static int a;
58 int b,c;
59 printf("a = stack addr:%p\n",&a);
60 printf("stack addr:%p\n",&b);
61 printf("stack addr:%p\n",&c);
62 return 0;
63
64 }

可以看到栈区是向下生长的,堆区是向上生长的。
对于变量a来说,它被设置成了静态变量,在编译时就已经确定地址在全局变量区了。
不过在其他系统中,并不是一定按照上述的布局情况分布的。
上面的布局分布系统以linux为例。
下面还有一段代码,作为本文章的引入点:
5 int main()
6 {
7 pid_t id = fork();
8 int g_val = 100;
9 if(id == 0)
10 {
11 //子进程
12 int cnt = 5;
13 while(1)
14 {
15 printf("子进程:pid:%d, ppid:%d, g_val:%d ,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);
16 sleep(1);
17 if(cnt == 0)
18 {
19 g_val = 200;
20 printf("子进程: g_val = 200:pid:%d, ppid:%d, g_val:%d ,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);
21 }
22 cnt--;
23
24 }
25 }
26 else
27 {
28 while(1)
29 {
30 printf("父进程:pid:%d, ppid:%d, g_val:%d ,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);
31 sleep(1);
32 }
33 }
34 return 0;
35 }
前五秒可以理解,父子进程具有独立性,且fork之后父子进程代码共享。
第六秒开始,子进程修改了g_val = 200也能理解,子进程在修改父进程数据时会发生写时拷贝,子进程有一份独立的g_val数据。
可重点是:为什么父子进程各自私有一份g_val数据,可是打印出它们的地址是相同的呢???

二、程序地址空间
1.现象解释
在进程创建时,描述该进程属性的PCB数据结构先被操作系统创建出来,在该PCB数据结构中,能找到进程对应的唯一程序地址空间,(注意每个进程都有唯一的一份程序地址空间)通过PCB内的指针变量就能找到程序地址空间,且进程也有对应的唯一一张叫做页表的东西。

页表的作用是一个桥梁,将程序地址空间和真正的物理内存链接起来。
如上图:
经过fork()创建子进程后,子进程会将父进程的程序地址空间和页表拷贝一份下来。
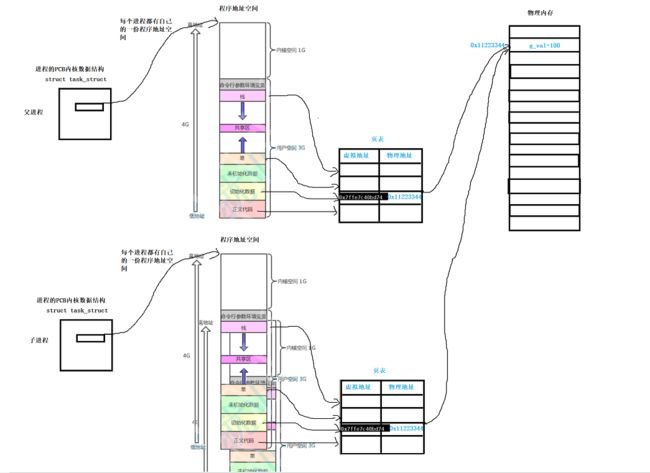
由于程序地址空间一样,页表也是一样的,所以子进程的页表也同样映射到物理空间中的同一个位置。
然后在子进程内部对g_val变量进行修改时,会发生写时拷贝,这个过程是操作系统自动做的,我们无需关心。
子进程会在物理空间中找一块未被使用的空间,然后将自己的页表中g_val变量映射的物理地址进行修改,如下:

结果就是子进程和父进程对应的虚拟地址空间在页表中的映射是相同的,然而在父子进程不同的页表中,映射的物理地址却不同,所以打印出不同的g_val的值,却看到打印的地址是相同的结果。
在这个过程中,虚拟地址是零感知的,压根不会影响到它!!!
所以,打印的地址一定不是真实的物理地址,而是虚拟地址!!
2.什么是地址空间
在硬件级别,有32根地址总线,每一根地址总线都只代表0/1,CPU和内存实际上是有32根地址总线连接起来的。
地址排列组合有2^32种地址。
而每种地址对应CPU读取一个字节的话,就得出了内存有4GB的结论。
如何理解地址空间上的区域划分?
举一个简单的例子,上小学时,可能是两人同桌,假如小胖和小美做同桌,而小胖又比较喜欢动手动脚,所以给小花造成了困扰,小花一怒之下暴打小胖,并跟他说:我要划一条三八线,你以后不准越界!!

自此,区域划分就出来了!!
所以,我们可以建立一个描述该区域的结构体:
struct area
{
int start;
int end;
struct area xiaopang;
struct area xiaohua;
};
struct area a;
a.start = 0,a.end = 100;
自此一块区域就创建出来了!
而小胖和小美怎么知道自己的三八线呢?
a.xiaopang.begin = 0,a.xiaopang.end = 30;
a.xiaohua.begin = 31,a.xiaohua.end = 100;
至此,两块空间的区域划分不就出来了吗?
所以,所谓的地址空间,本质上就是一个描述进程可视范围的大小!(可视范围就是进程所能看到的空间范围)
地址空间一定是一个线性区域,只要对各个区域进行划分,就能达到所谓的常量区,数据区,代码段等等各个不同的空间!!!
地址空间的本质也是内核的数据结构对象,类似进程的PCB一样,地址空间也需要被操作系统管理起来,那就一定要先描述,再组织!!
所以地址空间的本质也就是一个数据结构对象,如下:
struct mm_struct
{
long code_begin;
long code_begin;
long read_only_begin;
long read_only_end;
long init_begin;
long init_end;
long uninit_begin;
long uninit_end;
long heap_start;
long heap_end;
long stack_start;
long stack_end;
};
对象中使用变量存储空间的起始地址和结束地址,就能达到对各个空间进行划分的效果!
注意:程序地址空间是一个进程可视化的概念,实际上一定不止有那么点空间,还有上面小胖和小花的例子中之外的其他空间!
3.为什么要有程序地址空间?
讲一个小故事帮助理解:
有一个大富翁拥有10亿美金,同时他有四个私生子。这四个私生子意味着他们并不知道对方之间的存在,都认为自己是唯一一个私生子。
这个大富翁非常会画大饼,他跟私生子1说:等我死了,我的10亿美金就是你的了。
同时,他跟私生子2,3,4都说了同样的话。
有一天,私生子1说:老爸,给我5万美金,我要去环游世界。
他老爸觉得行,反正钱多得是,就给了5万私生子1。
第二天,私生子2说,老爸,我要创业,需要50万启动资金,老爸认为可以,是干正事,也就给了。
此时私生子1还觉得,我才用了5万美金,还有9亿多在老爸那里呢,这些钱迟早是我的。
这个过程就像是:这个大富翁老爸就像是操作系统,操作系统比较富裕,有很多内存空间。
而这四个私生子就分别代表4个进程,进程1向操作系统申请了500字节的空间,进程2向操作系统申请5000字节的空间。
在申请完后,所有进程都认为操作系统还有很多很多空间,大家都觉得如果我想继续申请,一定能申请到!
以上的故事产生的第一个结论是:
每一个进程都认为,我一定能使用操作系统的空间!!!
即,为了给进程统一的视角去看待内存空间!!!
下面讲第二个故事:
今年过年的时候,小胖收获了1000块钱的压岁钱,可是小胖还小,并不知道1000块钱是什么概念,此时妈妈走过来了,说:“小胖,妈妈帮你保管你的压岁钱哈!你看,你不知道这些压岁钱有多少钱,也不知道该怎么花,要是弄丢了怎么办呐!”
小胖想了想也是,就把这些钱交给了妈妈保管。
第二天,小胖说:“妈妈,我想买一个文具盒,要20块钱!”
妈妈想了想,买文具是正事,可以,那就让他买吧!随机给了小胖20块钱买文具盒。
过了几天,小胖屁颠屁颠跑过来问妈妈:“妈妈,我想买一个游戏机,要50块钱!”
妈妈听完瞪了小胖一眼:“买什么游戏机!现在不还在读书呢吗!玩什么游戏!”
妈妈头也不回地走了,小胖没能拿到钱买游戏机,灰溜溜地走了。
上述这个过程,小胖相当于一个进程,而那些钱就相当于操作系统内管理的内存空间,妈妈相当于页表。
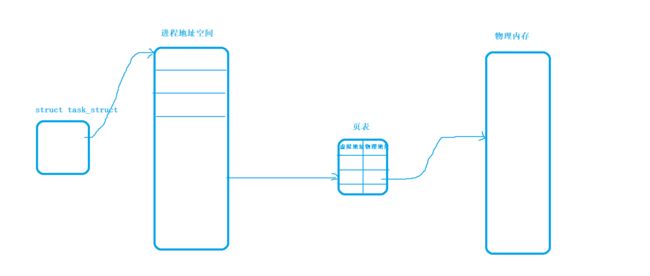
当一个进程向内存申请空间时,如果没有虚拟地址空间和页表这一层中介,进程可以直接访问到内存空间的话。
就特别危险,就比如说:
如果小胖没把钱交给妈妈,而是自己拿着一千块钱去买东西,可能会碰到无良商家欺骗小胖。
如果进程直接向物理内存访问空间,甚至修改空间的话,会发生非常危险的行为。
有了虚拟地址和页表作为中介,如果进程想要空间,或者进程想要向物理内存中修改数据,就必须经过页表的映射关系,将虚拟地址和物理地址连接起来,操作系统直接对其进行判断,如果是进程想要修改别人的数据,那就一定是非法的,从而有效阻止进程的非法操作!
再谈页表
通过上述的理解,可以知道页表起到一个举足轻重的作用。
那么,一个页表如何知道进程的申请是合法的还是非法的呢?!
其实,页表还有一个权限管理的功能。
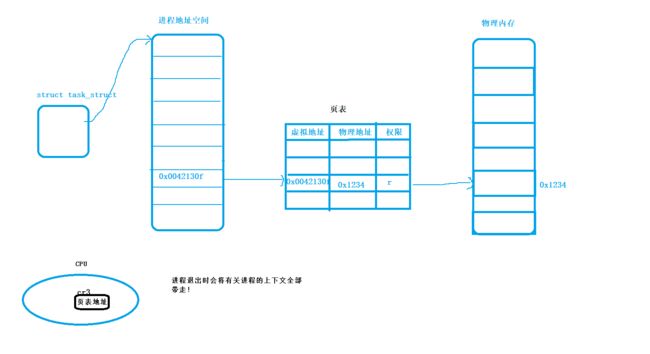
页表中存储着进程的虚拟地址和真实的物理内存直接的联系,还存在着该物理内存是否能被读/写的权限!

如果进程想要申请在对应的0x0042130f虚拟地址中进行修改数据,页表接收到申请后,会先将虚拟地址对应物理内存的权限进行检查,一旦检查结果不符合,页表会立刻将结果返回给操作系统,然后操作系统会立刻将该进程杀死!
那么,页表如何进行存储的呢?
在CPU中存在着一个cr3的寄存器,来存储页表地址的!
而一旦该进程退出,不论是由于时间片到了还是正常执行结束,寄存器的数据就会被进程带走!
所以,cr3寄存器存储的页表地址,本质属于进程的硬件上下文!!!
谈一谈一个共识:操作系统不会做任何浪费时间和浪费空间的事。
如果我们要下载一个游戏,这个游戏要下载100个G。
那么,这个游戏下载到本地磁盘时,是需要将这100个G完全加载到内存中才运行得起来吗?
根据生活经验,很显然不是。
如果一个100G的大文件要加载到内存中,可实际上需要使用的只有5GB,如果操作系统全部加载下来,本质上就是一个浪费空间的操作。
所以,操作系统采用惰性加载的方式,将文件加载到内存中,即用多少,加载多少
为什么操作系统会采用这样的方式?
浅谈缺页中断
在页表中还有一个这样的东西:标志位
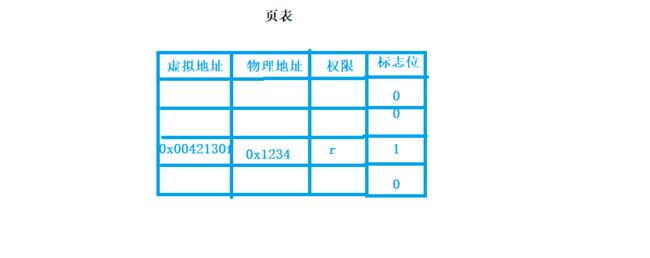
标志位的含义是:对应的代码和数据是否已经被加载到内存中,如果已经加载,标志位设置为1,如果未被加载,标志位设置为0。
操作系统想要访问进程的代码和数据时,操作系统会找到对应进程的页表,通过页表获取到物理地址,但是如果该进程的代码和数据没有写入到物理内存中,对应内存的地址也就不会写入到页表,就会触发缺页中断!!!
缺页中断的意思就是页表中没有找到对应的物理地址!
一旦操作系统发现页表中的对应物理内存的标志位为0,操作系统就会去找进程对应的代码和数据,将其加载到内存中;加载完成后再将标志位设置成1,将物理地址填到页表中。
这样就实现了,当我操作系统向访问数据时,我再去页表中找,如果没找到,就会触发缺页中断然后将数据加载到内存中再填充页表即可。
写时拷贝的发生就是由于缺页中断的!
所以,到底是先创建进程的内核数据结构,还是先加载对应的可执行程序呢?
答案是:
先创建进程的内核数据结构
通过创建进程的内核数据结构,就能在数据结构中找到该进程对应的程序地址空间,将其加载进来,然后通过保存的上下文数据,将页表地址加载到CPU的寄存器,进而将页表也加载进来,然后再通过页表等对内存进行管理,而进程本身并不关心内存管理的过程!!!
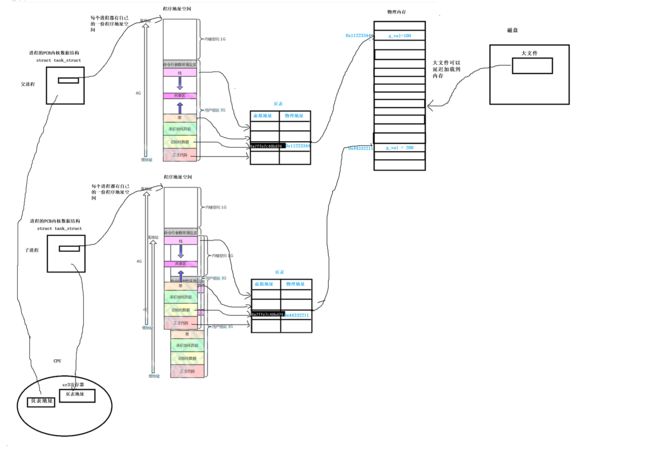
这整套下来,进程做自己的事情,内存做自己的事情,达到了解耦合的成效!!!
结论:
- 1.为了给进程以统一的视角看待内存空间。
- 2.防止进程对物理内存进行非法操作。
- 3.进程地址空间和页表的存在,让进程管理不再需要关心内存是怎样申请释放的。
-
- 也就是让进程管理和内存管理之间相互独立,实现解耦!!
重新理解进程概念
上面一套流程下来,进程的属性就更详细了:
进程=内核数据结构(struct task_struct + struct mm_struct + 页表)+程序的代码和数据
总结
进程地址空间也是一个比较抽象的概念,不过这也是一个初级工程师和高级工程师之间的分水岭,通过进程地址空间,把进程管理和内存管理独立开来,更好地让操作系统管理。