损失函数总结(十四):RMSELoss、LogCosh Loss
损失函数总结(十四):RMSELoss、LogCosh Loss
- 1 引言
- 2 损失函数
-
- 2.1 RMSELoss
- 2.2 LogCosh Loss
- 3 总结
1 引言
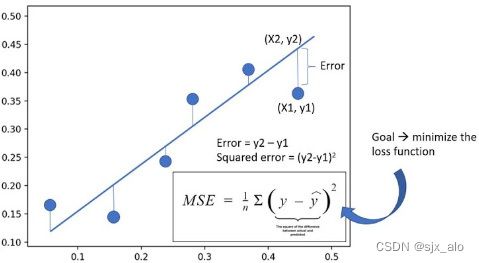
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss、BCELoss、CrossEntropyLoss、NLLLoss、CTCLoss、PoissonNLLLoss、GaussianNLLLoss、KLDivLoss、BCEWithLogitsLoss、MarginRankingLoss、HingeEmbeddingLoss、MultiMarginLoss、MultiLabelMarginLoss、SoftMarginLoss、MultiLabelSoftMarginLoss、TripletMarginLoss、TripletMarginWithDistanceLoss、Huber Loss、SmoothL1Loss、MBELoss、RAELoss、RSELoss、MAPELoss)。在这篇文章中,会接着上文提到的众多损失函数继续进行介绍,给大家带来更多不常见的损失函数的介绍。这里放一张损失函数的机理图:
2 损失函数
2.1 RMSELoss
Root Mean Squared Error (RMSE) 是 MSELoss 的平方根。它考虑了实际值的变化并测量误差的平均幅度。RMSE 可以应用于各种特征,因为它有助于确定特征是否增强模型预测。当非常不希望出现巨大错误时,RMSE 最有用。RMSELoss 的数学表达式如下:
L RMSE ( Y , Y ′ ) = 1 n ∑ i = 1 n ( y i − y i ′ ) 2 L_{\text{RMSE}}(Y, Y') = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - y_i')^2} LRMSE(Y,Y′)=n1i=1∑n(yi−yi′)2
代码实现(Pytorch):
import torch
import math
# 创建模型的预测值和真实观测值
predicted = torch.tensor([2.0, 4.0, 6.0, 8.0, 10.0], dtype=torch.float32)
observed = torch.tensor([1.5, 4.2, 5.8, 7.9, 9.8], dtype=torch.float32)
# 计算 RMSE
squared_error = (predicted - observed)**2
mse = torch.mean(squared_error)
rmse = math.sqrt(mse)
# 打印 RMSE
print("Root Mean Squared Error (RMSE):", rmse)
RMSELoss 更关注于较大错误,因此只有当只关注模型较大错误时才使用该损失函数,否则还是使用 MSELoss 较好。。。。
2.2 LogCosh Loss
LogCosh Loss 是比 L2 更光滑的损失函数,是误差值的双曲余弦的对数。它的功能类似于 MSELoss,但不受重大预测误差的影响。LogCosh Loss 的数学表达式如下:
L ( Y , Y ′ ) = ∑ i = 1 n log ( cosh ( y i − y i ′ ) ) L(Y, Y') = \sum_{i=1}^{n} \log(\cosh(y_i - y_i')) L(Y,Y′)=i=1∑nlog(cosh(yi−yi′))
代码实现(Pytorch):
import torch
import torch.nn as nn
# 创建模型的预测值和真实观测值
predicted = torch.tensor([2.0, 4.0, 6.0, 8.0, 10.0], dtype=torch.float32)
observed = torch.tensor([1.5, 4.2, 5.8, 7.9, 9.8], dtype=torch.float32)
# 创建 LogCoshLoss
logcosh_loss = torch.log(torch.cosh(observed - predicted)) # SmoothL1Loss 实现了 LogCosh Loss
# 计算 LogCosh Loss
loss = toch.sum(logcosh_loss)
# 打印 LogCosh Loss
print("LogCosh Loss:", loss.item())
LogCosh Loss 因求导比较复杂,计算量较大,在深度学习中使用不多,但是在机器学习领域由于其处处二阶可微的特性有所使用。。。
3 总结
到此,使用 损失函数总结(十四) 已经介绍完毕了!!! 如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。如果存在没有提及的损失函数也可以在评论区提出,后续会对其进行添加!!!!
如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦。