EasyExcel使用详解与源码解读
EasyExcel使用详解
- 1、EasyExcel简单介绍
-
- 64M内存20秒读取75M(46W行25列)的Excel(3.0.2+版本)
- 2、EasyExcel和POI数据处理能力对比
- 3、使用EasyExcel读写Excel、web上传/下载
-
- 3.1、写EXCEL
- 3.2、读EXCEL
- 3.3、web上传、下载
- 4、EasyExcel源码解读
- 5、总结
1、EasyExcel简单介绍
官方介绍:Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
普及一个知识点:读写速度 cpu>内存>磁盘
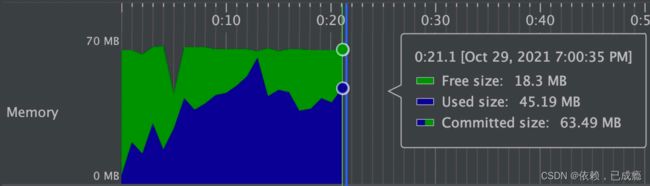
64M内存20秒读取75M(46W行25列)的Excel(3.0.2+版本)
当然还有极速模式能更快,但是内存占用会在100M多一点 img
2、EasyExcel和POI数据处理能力对比
poi
| 结构 | 支持Excel版本 | 读写行数 | 读写速度 | 格式 | 内存占用 |
|---|---|---|---|---|---|
| HSSF | excel 2003 版本 | <=65536行 | 快 | 高 | |
| XSSF | excel 2007 版本 | >=65536行 | 慢 | Microsoft Excel OOXML | 高 |
| SXSSF | excel 2007 版本 | >=65536行 | 介于HSSF 和XSSF | Microsoft Excel OOXML | 比较高 |
阿里easyExcel
| easyExcel | 内存占用 | 读写速度 | 读写行数 |
|---|---|---|---|
| 2.0.0以上版本 | 比较低(重写POI对07Excel的解析) | 非常快 | >65536(无限制,单sheet最大支持1048576行) |
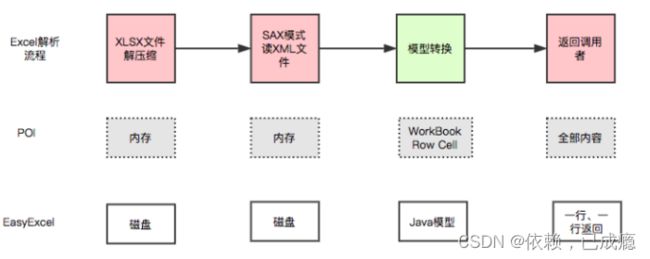
下面是poi和easyexcel解析excel的过程
3、使用EasyExcel读写Excel、web上传/下载
3.1、写EXCEL
/**
* 最简单的写
* 1. 创建excel对应的实体对象 参照{@link com.alibaba.easyexcel.test.demo.write.DemoData}
*
2. 直接写即可
*/
@Test
public void simpleWrite() {
//时间
long begin = System.currentTimeMillis();
// 注意 simpleWrite在数据量不大的情况下可以使用(5000以内,具体也要看实际情况),数据量大参照 重复多次写入
// 写法1 JDK8+
// since: 3.0.0-beta1
String fileName = PATH + "simpleWrite" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个class去写,然后写到第一个sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用03 则 传入excelType参数即可
EasyExcel.write(fileName, DemoData.class)
.sheet("模板")
.doWrite(() -> {
// 分页查询数据
return data();
});
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-begin));
}

优点:数量无限制(单sheet最大支持1048576行),速度比POI的SXSSF方式快
多种写法
@Test
public void simpleWrite() {
// 注意 simpleWrite在数据量不大的情况下可以使用(5000以内,具体也要看实际情况),数据量大参照 重复多次写入
// 写法1 JDK8+
// since: 3.0.0-beta1
String fileName = TestFileUtil.getPath() + "simpleWrite" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个class去写,然后写到第一个sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用03 则 传入excelType参数即可
EasyExcel.write(fileName, DemoData.class)
.sheet("模板")
.doWrite(() -> {
// 分页查询数据
return data();
});
// 写法2
fileName = TestFileUtil.getPath() + "simpleWrite" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个class去写,然后写到第一个sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用03 则 传入excelType参数即可
EasyExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
// 写法3
fileName = TestFileUtil.getPath() + "simpleWrite" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个class去写
try (ExcelWriter excelWriter = EasyExcel.write(fileName, DemoData.class).build()) {
WriteSheet writeSheet = EasyExcel.writerSheet("模板").build();
excelWriter.write(data(), writeSheet);
}
}
3.2、读EXCEL
多种读法
/**
* 最简单的读
*
* 1. 创建excel对应的实体对象 参照{@link DemoData}
*
* 2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link DemoDataListener}
*
* 3. 直接读即可
*/
@Test
public void simpleRead() {
// 写法1:JDK8+ ,不用额外写一个DemoDataListener
// since: 3.0.0-beta1
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
// 这里每次会读取100条数据 然后返回过来 直接调用使用数据就行
EasyExcel.read(fileName, DemoData.class, new PageReadListener<DemoData>(dataList -> {
for (DemoData demoData : dataList) {
log.info("读取到一条数据{}", JSON.toJSONString(demoData));
}
})).sheet().doRead();
// 写法2:
// 匿名内部类 不用额外写一个DemoDataListener
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new ReadListener<DemoData>() {
/**
* 单次缓存的数据量
*/
public static final int BATCH_COUNT = 100;
/**
*临时存储
*/
private List<DemoData> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
@Override
public void invoke(DemoData data, AnalysisContext context) {
cachedDataList.add(data);
if (cachedDataList.size() >= BATCH_COUNT) {
saveData();
// 存储完成清理 list
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData();
}
/**
* 加上存储数据库
*/
private void saveData() {
log.info("{}条数据,开始存储数据库!", cachedDataList.size());
log.info("存储数据库成功!");
}
}).sheet().doRead();
// 有个很重要的点 DemoDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去
// 写法3:
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
// 写法4
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 一个文件一个reader
try (ExcelReader excelReader = EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).build()) {
// 构建一个sheet 这里可以指定名字或者no
ReadSheet readSheet = EasyExcel.readSheet(0).build();
// 读取一个sheet
excelReader.read(readSheet);
}
}
3.3、web上传、下载
/**
* 文件下载(失败了会返回一个有部分数据的Excel)
*
* 1. 创建excel对应的实体对象 参照{@link DownloadData}
*
* 2. 设置返回的 参数
*
* 3. 直接写,这里注意,finish的时候会自动关闭OutputStream,当然你外面再关闭流问题不大
*/
@GetMapping("download")
public void download(HttpServletResponse response) throws IOException {
// 这里注意 有同学反应使用swagger 会导致各种问题,请直接用浏览器或者用postman
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止中文乱码 当然和easyexcel没有关系
String fileName = URLEncoder.encode("测试", "UTF-8").replaceAll("\\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName + ".xlsx");
EasyExcel.write(response.getOutputStream(), DownloadData.class).sheet("模板").doWrite(data());
}
/**
* 文件上传
* 1. 创建excel对应的实体对象 参照{@link UploadData}
*
2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link UploadDataListener}
*
3. 直接读即可
*/
@PostMapping("upload")
@ResponseBody
public String upload(MultipartFile file) throws IOException {
EasyExcel.read(file.getInputStream(), UploadData.class, new UploadDataListener(uploadDAO)).sheet().doRead();
return "success";
}
4、EasyExcel源码解读
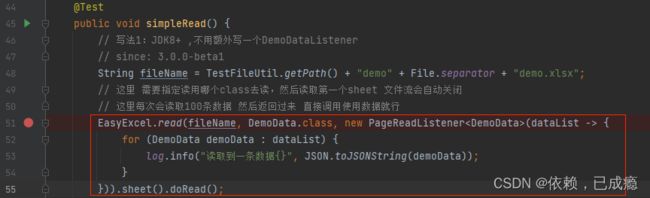
1、入口(有不同写法,这里只看这一种)
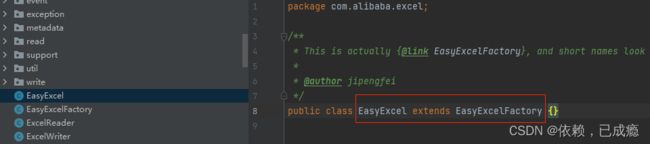
2、进入EasyExcel类,发现它是继承了EasyExcelFactory类,EasyExcel自动拥有EasyExcelFactory父类的所有方法。
3、进入.read方法,需要传入三个参数(文件路径,表头映射类,read监听器)
首先调用new ExcelReaderBuilder()方法,初始化ReadWorkbook对象
设置完readWorkbook属性后调,返回excelReaderBuilder对象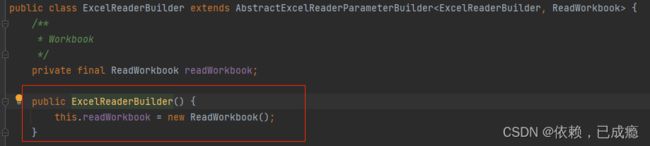
4、这里又个传入的参数是read监听器,进入其内部看一下,我们自定义了PageReadListener实现了ReadListener,我们来看一下ReadListener接口源码
public interface ReadListener<T> extends Listener {
/**
* All listeners receive this method when any one Listener does an error report. If an exception is thrown here, the
* entire read will terminate.
* 当任何一个侦听器执行错误报告时,所有侦听器都会收到此方法。如果在此处引发异常
*
* @param exception
* @param context
* @throws Exception
*/
default void onException(Exception exception, AnalysisContext context) throws Exception {
throw exception;
}
/**
* When analysis one head row trigger invoke function.
* 分析时 第一行表头触发器调用函数。
*
* @param headMap
* @param context
*/
default void invokeHead(Map<Integer, ReadCellData<?>> headMap, AnalysisContext context) {}
/**
* When analysis one row trigger invoke function.
* 分析时,一行触发器调用函数。
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context analysis context
*/
void invoke(T data, AnalysisContext context);
/**
* The current method is called when extra information is returned
* 返回额外信息时调用当前方法
*
* @param extra extra information
* @param context analysis context
*/
default void extra(CellExtra extra, AnalysisContext context) {}
/**
* if have something to do after all analysis
* 如果分析后有什么事要做
*
* @param context
*/
void doAfterAllAnalysed(AnalysisContext context);
/**
* Verify that there is another piece of data.You can stop the read by returning false
* 验证是否存在另一条数据。您可以通过返回false来停止读取
*
* @param context
* @return
*/
default boolean hasNext(AnalysisContext context) {
return true;
}
}
我们在PageReadListener中使用到了Consumer
public class PageReadListener<T> implements ReadListener<T> {
/**
* Single handle the amount of data
*/
public static int BATCH_COUNT = 100;
/**
* Temporary storage of data
*/
private List<T> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
/**
* consumer
*/
private final Consumer<List<T>> consumer;
public PageReadListener(Consumer<List<T>> consumer) {
this.consumer = consumer;
}
@Override
public void invoke(T data, AnalysisContext context) {
// 每一行数据添加进缓存list中
cachedDataList.add(data);
if (cachedDataList.size() >= BATCH_COUNT) {
// 当超过某个阈值,把它消费掉(此处可存入数据库)
consumer.accept(cachedDataList);
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
/**
* 确保easyexcel分析完数据被全部消费
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
if (CollectionUtils.isNotEmpty(cachedDataList)) {
consumer.accept(cachedDataList);
}
}
}
5、接下来调用的是.sheet()方法,我们进入里面看一下

这里我们会传入sheetNo、sheetName参数,调用build()方法创建ExcelReader对象,传入ExcelReaderSheetBuilder构造方法中,最终创建ExcelReaderSheetBuilder对象
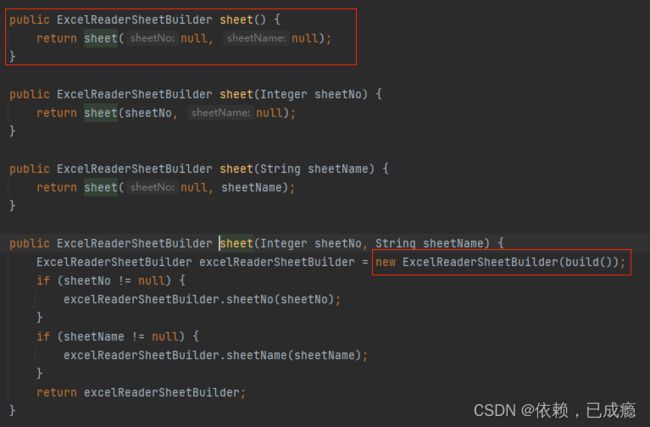
6、我们进入build()方法看一下里面到底创建了什么
6.1、生成ExcelReader对象

6.2、初始化ExcelAnalyser

6.3、实例化ExcelAnalyser
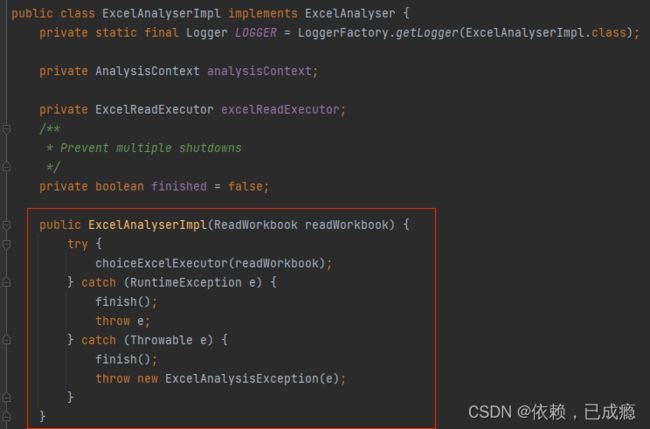
7、我们进入choiceExcelExecutor方法看一下,方法通过excel格式,使用不同的执行器
我们看XLSX中,初始化了XlsxReadContext上下文对象,给到analysisContext
又初始化了XlsxSaxAnalyser解析器对象,
private void choiceExcelExecutor(ReadWorkbook readWorkbook) throws Exception {
ExcelTypeEnum excelType = ExcelTypeEnum.valueOf(readWorkbook);
switch (excelType) {
case XLS:
POIFSFileSystem poifsFileSystem;
if (readWorkbook.getFile() != null) {
poifsFileSystem = new POIFSFileSystem(readWorkbook.getFile());
} else {
poifsFileSystem = new POIFSFileSystem(readWorkbook.getInputStream());
}
// So in encrypted excel, it looks like XLS but it's actually XLSX
if (poifsFileSystem.getRoot().hasEntry(Decryptor.DEFAULT_POIFS_ENTRY)) {
InputStream decryptedStream = null;
try {
decryptedStream = DocumentFactoryHelper
.getDecryptedStream(poifsFileSystem.getRoot().getFileSystem(), readWorkbook.getPassword());
XlsxReadContext xlsxReadContext = new DefaultXlsxReadContext(readWorkbook, ExcelTypeEnum.XLSX);
analysisContext = xlsxReadContext;
excelReadExecutor = new XlsxSaxAnalyser(xlsxReadContext, decryptedStream);
return;
} finally {
IOUtils.closeQuietly(decryptedStream);
// as we processed the full stream already, we can close the filesystem here
// otherwise file handles are leaked
poifsFileSystem.close();
}
}
if (readWorkbook.getPassword() != null) {
Biff8EncryptionKey.setCurrentUserPassword(readWorkbook.getPassword());
}
XlsReadContext xlsReadContext = new DefaultXlsReadContext(readWorkbook, ExcelTypeEnum.XLS);
xlsReadContext.xlsReadWorkbookHolder().setPoifsFileSystem(poifsFileSystem);
analysisContext = xlsReadContext;
excelReadExecutor = new XlsSaxAnalyser(xlsReadContext);
break;
case XLSX:
XlsxReadContext xlsxReadContext = new DefaultXlsxReadContext(readWorkbook, ExcelTypeEnum.XLSX);
analysisContext = xlsxReadContext;
excelReadExecutor = new XlsxSaxAnalyser(xlsxReadContext, null);
break;
case CSV:
CsvReadContext csvReadContext = new DefaultCsvReadContext(readWorkbook, ExcelTypeEnum.CSV);
analysisContext = csvReadContext;
excelReadExecutor = new CsvExcelReadExecutor(csvReadContext);
break;
default:
break;
}
}
7.1、我们进入new XlsxSaxAnalyser(xlsxReadContext, null)方法看一下,这里使用到SAX模式模式解析excel
public XlsxSaxAnalyser(XlsxReadContext xlsxReadContext, InputStream decryptedStream) throws Exception {
this.xlsxReadContext = xlsxReadContext;
// 初始化缓存
XlsxReadWorkbookHolder xlsxReadWorkbookHolder = xlsxReadContext.xlsxReadWorkbookHolder();
OPCPackage pkg = readOpcPackage(xlsxReadWorkbookHolder, decryptedStream);
xlsxReadWorkbookHolder.setOpcPackage(pkg);
// Read the Shared information Strings
PackagePart sharedStringsTablePackagePart = pkg.getPart(SHARED_STRINGS_PART_NAME);
if (sharedStringsTablePackagePart != null) {
// 指定默认缓存
defaultReadCache(xlsxReadWorkbookHolder, sharedStringsTablePackagePart);
// 分析sharedStringsTable.xml,解析excel所有数据到readCache
analysisSharedStringsTable(sharedStringsTablePackagePart.getInputStream(), xlsxReadWorkbookHolder);
}
XSSFReader xssfReader = new XSSFReader(pkg);
analysisUse1904WindowDate(xssfReader, xlsxReadWorkbookHolder);
// 设置样式
setStylesTable(xlsxReadWorkbookHolder, xssfReader);
sheetList = new ArrayList<>();
sheetMap = new HashMap<>();
commentsTableMap = new HashMap<>();
Map<Integer, PackageRelationshipCollection> packageRelationshipCollectionMap = MapUtils.newHashMap();
xlsxReadWorkbookHolder.setPackageRelationshipCollectionMap(packageRelationshipCollectionMap);
// 获取所有sheet页
XSSFReader.SheetIterator ite = (XSSFReader.SheetIterator)xssfReader.getSheetsData();
int index = 0;
if (!ite.hasNext()) {
throw new ExcelAnalysisException("Can not find any sheet!");
}
// 遍历所有sheet页
while (ite.hasNext()) {
InputStream inputStream = ite.next();
// 保存所有sheet页
sheetList.add(new ReadSheet(index, ite.getSheetName()));
// 保存每个sheet页的输入流
sheetMap.put(index, inputStream);
if (xlsxReadContext.readWorkbookHolder().getExtraReadSet().contains(CellExtraTypeEnum.COMMENT)) {
CommentsTable commentsTable = ite.getSheetComments();
if (null != commentsTable) {
commentsTableMap.put(index, commentsTable);
}
}
if (xlsxReadContext.readWorkbookHolder().getExtraReadSet().contains(CellExtraTypeEnum.HYPERLINK)) {
PackageRelationshipCollection packageRelationshipCollection = Optional.ofNullable(ite.getSheetPart())
.map(packagePart -> {
try {
return packagePart.getRelationships();
} catch (InvalidFormatException e) {
log.warn("Reading the Relationship failed", e);
return null;
}
}).orElse(null);
if (packageRelationshipCollection != null) {
packageRelationshipCollectionMap.put(index, packageRelationshipCollection);
}
}
index++;
}
}
7.2、我们进入analysisSharedStringsTable方法,可以看到创建了一个SharedStringsTableHandler处理器
private void analysisSharedStringsTable(InputStream sharedStringsTableInputStream,
XlsxReadWorkbookHolder xlsxReadWorkbookHolder) throws Exception {
ContentHandler handler = new SharedStringsTableHandler(xlsxReadWorkbookHolder.getReadCache());
parseXmlSource(sharedStringsTableInputStream, handler);
xlsxReadWorkbookHolder.getReadCache().putFinished();
}
7.3、再进入parseXmlSource看到xmlReader.setContentHandler(handler)这一行代码,设置了SharedStringsTableHandler处理器
private void parseXmlSource(InputStream inputStream, ContentHandler handler) {
InputSource inputSource = new InputSource(inputStream);
try {
SAXParserFactory saxFactory;
String xlsxSAXParserFactoryName = xlsxReadContext.xlsxReadWorkbookHolder().getSaxParserFactoryName();
if (StringUtils.isEmpty(xlsxSAXParserFactoryName)) {
saxFactory = SAXParserFactory.newInstance();
} else {
saxFactory = SAXParserFactory.newInstance(xlsxSAXParserFactoryName, null);
}
try {
saxFactory.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
} catch (Throwable ignore) {}
try {
saxFactory.setFeature("http://xml.org/sax/features/external-general-entities", false);
} catch (Throwable ignore) {}
try {
saxFactory.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
} catch (Throwable ignore) {}
SAXParser saxParser = saxFactory.newSAXParser();
XMLReader xmlReader = saxParser.getXMLReader();
xmlReader.setContentHandler(handler);
xmlReader.parse(inputSource);
inputStream.close();
} catch (IOException | ParserConfigurationException | SAXException e) {
throw new ExcelAnalysisException(e);
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
throw new ExcelAnalysisException("Can not close 'inputStream'!");
}
}
}
}
7.4、我们将端点打在,发现下一步进入到这里面了

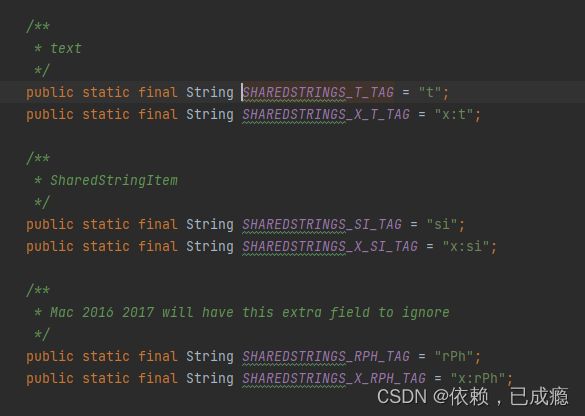
7.5、excel所有数据读取到readcache中
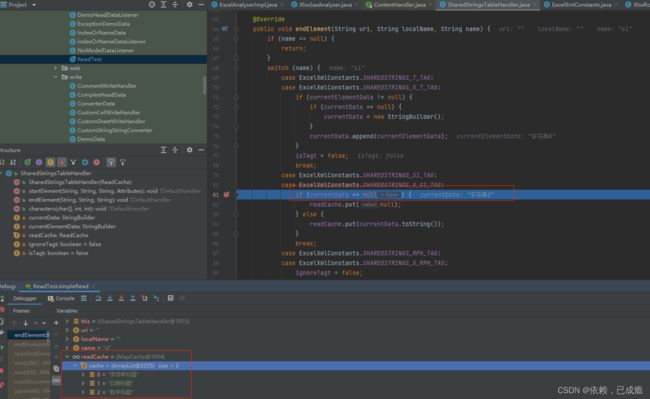

8、调用.doRead()方法,开始SAX解析
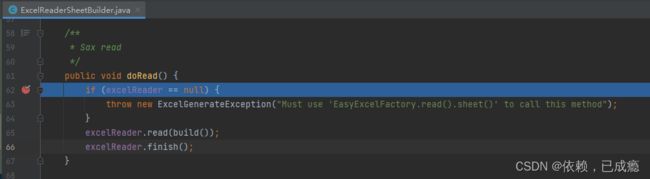
8.1、build()方法

8.2、进入read()方法
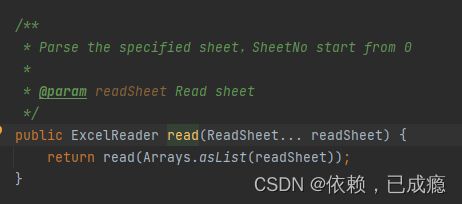
8.3、继续进入

9、设置sheetList,并调用执行器开始执行解析
@Override
public void analysis(List<ReadSheet> readSheetList, Boolean readAll) {
try {
if (!readAll && CollectionUtils.isEmpty(readSheetList)) {
throw new IllegalArgumentException("Specify at least one read sheet.");
}
analysisContext.readWorkbookHolder().setParameterSheetDataList(readSheetList);
analysisContext.readWorkbookHolder().setReadAll(readAll);
try {
excelReadExecutor.execute();
} catch (ExcelAnalysisStopException e) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Custom stop!");
}
}
} catch (RuntimeException e) {
finish();
throw e;
} catch (Throwable e) {
finish();
throw new ExcelAnalysisException(e);
}
}
9.1、我们调用的XlsxSaxAnalyser解析器
@Override
public void execute() {
for (ReadSheet readSheet : sheetList) {
readSheet = SheetUtils.match(readSheet, xlsxReadContext);
if (readSheet != null) {
xlsxReadContext.currentSheet(readSheet);
// 解析输入流
parseXmlSource(sheetMap.get(readSheet.getSheetNo()), new XlsxRowHandler(xlsxReadContext));
// 读取comment
readComments(readSheet);
// 读取最后一个sheet
xlsxReadContext.analysisEventProcessor().endSheet(xlsxReadContext);
}
}
}
10、进入parseXmlSource()方法,发现和之前的sax差不多,还是看一下传入的ContentHandler参数具体实现,进入XlsxRowHandler 内部
public class XlsxRowHandler extends DefaultHandler {
private final XlsxReadContext xlsxReadContext;
private static final Map<String, XlsxTagHandler> XLSX_CELL_HANDLER_MAP = new HashMap<String, XlsxTagHandler>(32);
static {
CellFormulaTagHandler cellFormulaTagHandler = new CellFormulaTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.CELL_FORMULA_TAG, cellFormulaTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_CELL_FORMULA_TAG, cellFormulaTagHandler);
CellInlineStringValueTagHandler cellInlineStringValueTagHandler = new CellInlineStringValueTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.CELL_INLINE_STRING_VALUE_TAG, cellInlineStringValueTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_CELL_INLINE_STRING_VALUE_TAG, cellInlineStringValueTagHandler);
CellTagHandler cellTagHandler = new CellTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.CELL_TAG, cellTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_CELL_TAG, cellTagHandler);
CellValueTagHandler cellValueTagHandler = new CellValueTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.CELL_VALUE_TAG, cellValueTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_CELL_VALUE_TAG, cellValueTagHandler);
CountTagHandler countTagHandler = new CountTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.DIMENSION_TAG, countTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_DIMENSION_TAG, countTagHandler);
HyperlinkTagHandler hyperlinkTagHandler = new HyperlinkTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.HYPERLINK_TAG, hyperlinkTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_HYPERLINK_TAG, hyperlinkTagHandler);
MergeCellTagHandler mergeCellTagHandler = new MergeCellTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.MERGE_CELL_TAG, mergeCellTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_MERGE_CELL_TAG, mergeCellTagHandler);
RowTagHandler rowTagHandler = new RowTagHandler();
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.ROW_TAG, rowTagHandler);
XLSX_CELL_HANDLER_MAP.put(ExcelXmlConstants.X_ROW_TAG, rowTagHandler);
}
public XlsxRowHandler(XlsxReadContext xlsxReadContext) {
this.xlsxReadContext = xlsxReadContext;
}
@Override
public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException {
XlsxTagHandler handler = XLSX_CELL_HANDLER_MAP.get(name);
if (handler == null || !handler.support(xlsxReadContext)) {
return;
}
// 队列保存当前tag
xlsxReadContext.xlsxReadSheetHolder().getTagDeque().push(name);
// 调用具体的startElement实现方法
handler.startElement(xlsxReadContext, name, attributes);
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String currentTag = xlsxReadContext.xlsxReadSheetHolder().getTagDeque().peek();
if (currentTag == null) {
return;
}
XlsxTagHandler handler = XLSX_CELL_HANDLER_MAP.get(currentTag);
if (handler == null || !handler.support(xlsxReadContext)) {
return;
}
handler.characters(xlsxReadContext, ch, start, length);
}
@Override
public void endElement(String uri, String localName, String name) throws SAXException {
XlsxTagHandler handler = XLSX_CELL_HANDLER_MAP.get(name);
if (handler == null || !handler.support(xlsxReadContext)) {
return;
}
// 调用具体的endElement实现方法
handler.endElement(xlsxReadContext, name);
// 出队
xlsxReadContext.xlsxReadSheetHolder().getTagDeque().pop();
}
}
10.1、多种startElement实现

10.2、多种endElement实现
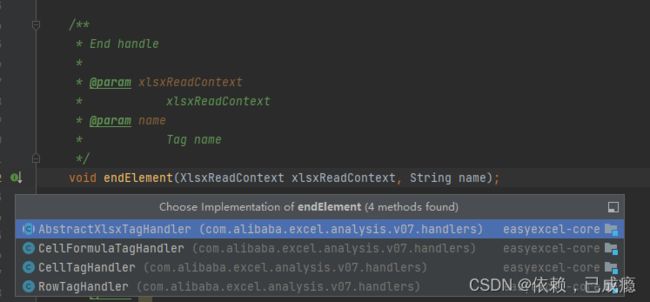
11、进入用到的重要的几个类CellTagHandler、RowTagHandler
CellTagHandler
读取cell的值,并放入tempCellData
public class CellTagHandler extends AbstractXlsxTagHandler {
private static final int DEFAULT_FORMAT_INDEX = 0;
@Override
public void startElement(XlsxReadContext xlsxReadContext, String name, Attributes attributes) {
XlsxReadSheetHolder xlsxReadSheetHolder = xlsxReadContext.xlsxReadSheetHolder();
xlsxReadSheetHolder.setColumnIndex(PositionUtils.getCol(attributes.getValue(ExcelXmlConstants.ATTRIBUTE_R),
xlsxReadSheetHolder.getColumnIndex()));
// t="s" ,it means String
// t="str" ,it means String,but does not need to be read in the 'sharedStrings.xml'
// t="inlineStr" ,it means String,but does not need to be read in the 'sharedStrings.xml'
// t="b" ,it means Boolean
// t="e" ,it means Error
// t="n" ,it means Number
// t is null ,it means Empty or Number
CellDataTypeEnum type = CellDataTypeEnum.buildFromCellType(attributes.getValue(ExcelXmlConstants.ATTRIBUTE_T));
xlsxReadSheetHolder.setTempCellData(new ReadCellData<>(type));
xlsxReadSheetHolder.setTempData(new StringBuilder());
// Put in data transformation information
String dateFormatIndex = attributes.getValue(ExcelXmlConstants.ATTRIBUTE_S);
int dateFormatIndexInteger;
if (StringUtils.isEmpty(dateFormatIndex)) {
dateFormatIndexInteger = DEFAULT_FORMAT_INDEX;
} else {
dateFormatIndexInteger = Integer.parseInt(dateFormatIndex);
}
xlsxReadSheetHolder.getTempCellData().setDataFormatData(
xlsxReadContext.xlsxReadWorkbookHolder().dataFormatData(dateFormatIndexInteger));
}
@Override
public void endElement(XlsxReadContext xlsxReadContext, String name) {
XlsxReadSheetHolder xlsxReadSheetHolder = xlsxReadContext.xlsxReadSheetHolder();
ReadCellData<?> tempCellData = xlsxReadSheetHolder.getTempCellData();
StringBuilder tempData = xlsxReadSheetHolder.getTempData();
String tempDataString = tempData.toString();
CellDataTypeEnum oldType = tempCellData.getType();
switch (oldType) {
case STRING:
// In some cases, although cell type is a string, it may be an empty tag
if (StringUtils.isEmpty(tempDataString)) {
break;
}
String stringValue = xlsxReadContext.readWorkbookHolder().getReadCache().get(
Integer.valueOf(tempDataString));
tempCellData.setStringValue(stringValue);
break;
case DIRECT_STRING:
case ERROR:
tempCellData.setStringValue(tempDataString);
tempCellData.setType(CellDataTypeEnum.STRING);
break;
case BOOLEAN:
if (StringUtils.isEmpty(tempDataString)) {
tempCellData.setType(CellDataTypeEnum.EMPTY);
break;
}
tempCellData.setBooleanValue(BooleanUtils.valueOf(tempData.toString()));
break;
case NUMBER:
case EMPTY:
if (StringUtils.isEmpty(tempDataString)) {
tempCellData.setType(CellDataTypeEnum.EMPTY);
break;
}
tempCellData.setType(CellDataTypeEnum.NUMBER);
tempCellData.setNumberValue(BigDecimal.valueOf(Double.parseDouble(tempDataString)));
break;
default:
throw new IllegalStateException("Cannot set values now");
}
if (tempCellData.getStringValue() != null
&& xlsxReadContext.currentReadHolder().globalConfiguration().getAutoTrim()) {
tempCellData.setStringValue(tempCellData.getStringValue().trim());
}
tempCellData.checkEmpty();
tempCellData.setRowIndex(xlsxReadSheetHolder.getRowIndex());
tempCellData.setColumnIndex(xlsxReadSheetHolder.getColumnIndex());
xlsxReadSheetHolder.getCellMap().put(xlsxReadSheetHolder.getColumnIndex(), tempCellData);
}
}
RowTagHandler
当一行读取完毕后,调用分析事件处理器,处理一行数据
xlsxReadContext.analysisEventProcessor().endRow(xlsxReadContext);
public class RowTagHandler extends AbstractXlsxTagHandler {
@Override
public void startElement(XlsxReadContext xlsxReadContext, String name, Attributes attributes) {
XlsxReadSheetHolder xlsxReadSheetHolder = xlsxReadContext.xlsxReadSheetHolder();
int rowIndex = PositionUtils.getRowByRowTagt(attributes.getValue(ExcelXmlConstants.ATTRIBUTE_R),
xlsxReadSheetHolder.getRowIndex());
Integer lastRowIndex = xlsxReadContext.readSheetHolder().getRowIndex();
while (lastRowIndex + 1 < rowIndex) {
xlsxReadContext.readRowHolder(new ReadRowHolder(lastRowIndex + 1, RowTypeEnum.EMPTY,
xlsxReadSheetHolder.getGlobalConfiguration(), new LinkedHashMap<Integer, Cell>()));
xlsxReadContext.analysisEventProcessor().endRow(xlsxReadContext);
xlsxReadSheetHolder.setColumnIndex(null);
xlsxReadSheetHolder.setCellMap(new LinkedHashMap<Integer, Cell>());
lastRowIndex++;
}
xlsxReadSheetHolder.setRowIndex(rowIndex);
}
@Override
public void endElement(XlsxReadContext xlsxReadContext, String name) {
XlsxReadSheetHolder xlsxReadSheetHolder = xlsxReadContext.xlsxReadSheetHolder();
RowTypeEnum rowType = MapUtils.isEmpty(xlsxReadSheetHolder.getCellMap()) ? RowTypeEnum.EMPTY : RowTypeEnum.DATA;
// It's possible that all of the cells in the row are empty
if (rowType == RowTypeEnum.DATA) {
boolean hasData = false;
for (Cell cell : xlsxReadSheetHolder.getCellMap().values()) {
if (!(cell instanceof ReadCellData)) {
hasData = true;
break;
}
ReadCellData<?> readCellData = (ReadCellData<?>)cell;
if (readCellData.getType() != CellDataTypeEnum.EMPTY) {
hasData = true;
break;
}
}
if (!hasData) {
rowType = RowTypeEnum.EMPTY;
}
}
xlsxReadContext.readRowHolder(new ReadRowHolder(xlsxReadSheetHolder.getRowIndex(), rowType,
xlsxReadSheetHolder.getGlobalConfiguration(), xlsxReadSheetHolder.getCellMap()));
xlsxReadContext.analysisEventProcessor().endRow(xlsxReadContext);
xlsxReadSheetHolder.setColumnIndex(null);
xlsxReadSheetHolder.setCellMap(new LinkedHashMap<>());
}
}
12、进入xlsxReadContext.analysisEventProcessor().endRow(xlsxReadContext)/endRow()方法
public void endRow(AnalysisContext analysisContext) {
if (RowTypeEnum.EMPTY.equals(analysisContext.readRowHolder().getRowType())) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Empty row!");
}
if (analysisContext.readWorkbookHolder().getIgnoreEmptyRow()) {
return;
}
}
dealData(analysisContext);
}
13、继续进入dealData方法
private void dealData(AnalysisContext analysisContext) {
ReadRowHolder readRowHolder = analysisContext.readRowHolder();
Map<Integer, ReadCellData<?>> cellDataMap = (Map)readRowHolder.getCellMap();
readRowHolder.setCurrentRowAnalysisResult(cellDataMap);
int rowIndex = readRowHolder.getRowIndex();
int currentHeadRowNumber = analysisContext.readSheetHolder().getHeadRowNumber();
boolean isData = rowIndex >= currentHeadRowNumber;
// Last head column 保存表头数据
if (!isData && currentHeadRowNumber == rowIndex + 1) {
buildHead(analysisContext, cellDataMap);
}
// Now is data 调用一开传入的监听器,处理一行数据
for (ReadListener readListener : analysisContext.currentReadHolder().readListenerList()) {
try {
if (isData) {
// 处理数据
readListener.invoke(readRowHolder.getCurrentRowAnalysisResult(), analysisContext);
} else {
// 处理表头
readListener.invokeHead(cellDataMap, analysisContext);
}
} catch (Exception e) {
onException(analysisContext, e);
break;
}
if (!readListener.hasNext(analysisContext)) {
throw new ExcelAnalysisStopException();
}
}
}
14、进入readComments()方法,读取额外信息(批注、超链接、合并单元格信息读取)
private void readComments(ReadSheet readSheet) {
if (!xlsxReadContext.readWorkbookHolder().getExtraReadSet().contains(CellExtraTypeEnum.COMMENT)) {
return;
}
CommentsTable commentsTable = commentsTableMap.get(readSheet.getSheetNo());
if (commentsTable == null) {
return;
}
Iterator<CellAddress> cellAddresses = commentsTable.getCellAddresses();
while (cellAddresses.hasNext()) {
CellAddress cellAddress = cellAddresses.next();
XSSFComment cellComment = commentsTable.findCellComment(cellAddress);
CellExtra cellExtra = new CellExtra(CellExtraTypeEnum.COMMENT, cellComment.getString().toString(),
cellAddress.getRow(), cellAddress.getColumn());
xlsxReadContext.readSheetHolder().setCellExtra(cellExtra);
xlsxReadContext.analysisEventProcessor().extra(xlsxReadContext);
}
}
15、最后进入.endSheet(xlsxReadContext)方法
@Override
public void endSheet(AnalysisContext analysisContext) {
// 这里会调用所有监听器中的doAfterAllAnalysed方法,执行最后的操作
for (ReadListener readListener : analysisContext.currentReadHolder().readListenerList()) {
readListener.doAfterAllAnalysed(analysisContext);
}
}
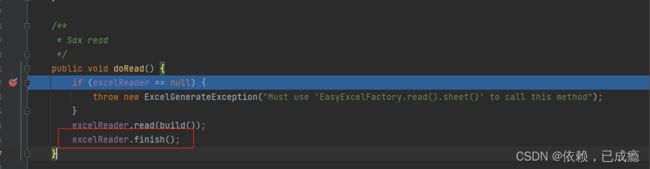
16、在读取完毕之后,执行finish()方法,关闭所有流
5、总结
从上面使用和源码可以看得出阿里,poi能做的easyExcel也能做,而且做的更加优秀(防止内存溢出、性能),更加的方便(使用),所以阿里的EasyExcel做的那么优秀,还是有很多地方值得我们学习的,并且是开源的就非常棒!