计算机是如何进行工作的+进程和线程
一)计算机是如何工作的?







指令是如何执行的?CPU基本工作过程?
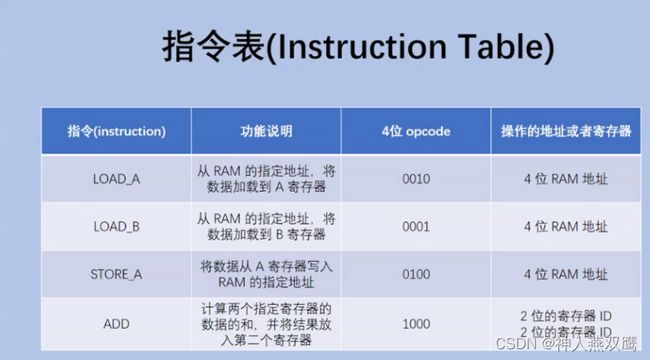
假设上面有一些指令表,假设CPU上面有两个寄存器A的编号是00,B的编号是01
1)第一个指令0010 1010,这个指令的意思就是说把1010地址上面的数据给他读取到A寄存器里面
2)第二个指令0001 1111,这个指令的意思是说把1111内存地址上面的数据给他读到寄存器B里面
3)第三个指令0100,1000,这个指令的意思是把A寄存器里面的内容值写到并保存到内存地址1000的地方上面
4)1000 0100这个操作的意思就是将00寄存器和01寄存器的数值进行相加,结果放到00寄存器里面
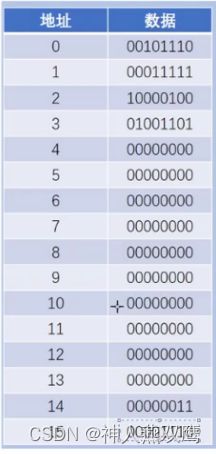
接下来我们来进行查看一下,这些指令是怎么进行工作的: 我们的上面的每一个地址的数据就是8bit,一个字节
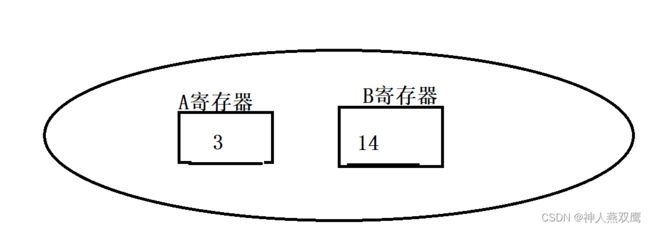
1)假设从0号地址的位置开始进行执行,首先CPU中的CU就会从0号地址读取内存中的指令,来进行解析,发现指令是00101110,根据上面的指令表可以看出我们此时执行的指令就是00101110,我们就会把14号地址的数据加载到寄存器A里面,发现14号地址上面的数据就是00000011,此时数据就是3,此时我们就在CPU中有一个寄存器A来存放3的值
2)加下来我们从1号地址位置的地址处开始进行执行,00011111,我们的意思就是说,执行loadB操作,把内存地址是15上面的数据加载到寄存器B里面,内存地址是15的数据,去查发现数据是14,但是我们的计算机在1s内可以执行15条这样的指令
3)第三条指令就是:10000100,就是将01和00寄存器中的数据取出来进行相加,放到00这个寄存器里面,在上面说了01就是B,00就是A,加起来就是17,放到A里面
4)01001101,这个命令就是说把A寄存器的这个数据写到1101这个内存地址上面,1101翻译成10进制就是13,所以说我们就把A寄存器上面的这个17写到了13这个内存地址上面,17的二进制就是00010001这个数据写到了内存地址是13的地方(内存地址是13的地方原来是00000000)
CPU的工作流程:
1)从内存中读取指令
2)解析指令
3)执行指令
1)上面这个过程都是通过CU这一个控制单元来进行实现的,这就是说在CPU在执行代码的时候的关键所在,咱们最终要进行编写的程序,最终都会被编译器给翻译成CPU所能识别的机器语言指令,在运行程序的时候,操作系统就会把这样的可执行程序加载到内存里面,CPU就依靠CU这个控制单元来进行读取,解析和执行
2)如果说我们最终要是在配上条件跳转,我们就可以实现条件语句和循环语句,所以我们这一套完整的逻辑就可以通过二进制指令来进行表述出来,以上这就是所谓编程的本质
3)所以说我们写下来的每一行代码,写下来的每一个类,每一个方法,每一个变量最终都会被编译器翻译成CPU所执行的指令的 ,所以接下来通过CPU执行这些指令,就会完成整个程序的工作过程
4)咱们自己电脑上面的idea还有QQ音乐都是依靠上面的工作过程来进行执行的
咱们CPU执行的是工作指令,不同的CPU上面执行的是不同的工作指令
1)外挂是一个单独的程序, 对于一个游戏来说,源代码是不会被公开的,虽然没有源码,但是具有可执行程序,可执行程序其实本质上来说就是二进制的机器指令,这里面就包含了一些程序运行的时候涉及到的一些逻辑,我们就可以通过研究这里面的机器指令来进行找到其中的一些关键逻辑
2)比如说找到一些,子弹扣血的关键逻辑,本质上就是说是一些机器指令,算术逻辑加上一些逻辑判断,我们就可以把这里面的条件给改了,或者把篡改的血量换成0
二)操作系统:操作系统是一个搞管理的软件,就是一个软件
操作系统是一个软件,是计算机上面最复杂,最重要的软件之一,比如说linux系统,windows,mac系统,安卓,IOS系统,操作系统相当于是给硬件设备和软件系统相互之间架起了一座桥,软件和硬件更好的进行交互,更好地进行相互配合
1)先进行描述一个进程(明确指出一个进程上面的相关属性),结构体(PCB)
2)再进行组织若干个进程,使用一些数据结构,把很多描述进程的信息都放到一起,方便进行增删改查,实现一个双向链表把每一个进程的PCB来进行串起来


三)进程:叫做任务,process,运行的exe文件;
进程:把这些运行起来的可执行文件,就被称之为进程,CMD上面的输入任务管理器,进程就是跑起来的应用程序,咱们电脑上面的exe就是被称为可执行文件(QQ.exe,CCtalk.exe),这些可执行文件,都是文件,都是静静的躺在硬盘上面的,在你双击之前,这些文件都不会对你的系统产生任何影响,但是当双击执行这些exe文件的时候,操作系统就会将这些exe文件给加载到内存里面,并开始执行exe内部的一些指令,这个可执行程序就变成了进程
这个进程此时就和内存空间绑定在了一起,让CPU开始执行一些exe内部的指令,exe里面就存放了很多和这个程序相关的二进制指令,编译器生成的,还有一些重要的数据,CPU可以识别的机器语言,点击exe文件,就可以运行起来的,exe里面有啥,那么内存里面就有啥
这个时候就已经把exe文件给执行起来了,它就不再是躺平的咸鱼了,而是开始进行执行一些具体的工作,就从静态过程成为了动态过程
进程管理:因为进程被描述和组织:



四)线程的相关知识
创建线程注意的事项:
创建线程的方式:以下创建线程的方式,本质上都是相同的,都要借助Thread类,在内核中创建出新的PCB,加入到内核中的双向链表中,只不过是描述任务的主体不一样;
可以通过Thread类创建线程,最简单的方法就是说创建一个类继承于Thread类,并且重写里面的run方法,本质上是在创建继承于Thread类的这样的一个实例
1.1)注意:Thread类是在Java.lang包底下的,而我们的TimeUnit是在juc包底下的,咱们的jconsole是JAVA中自带的一个调试工具
1.2)jconsole可以列举出你系统上面的JAVA进程,但是其他进程不行,但是他是JDK的调试工具
前两个进程表示的是JConsole进程,下来一个是Main进程,下来是Idea进程
java进程一但进行启动,那么不仅仅是你自己代码中的线程,还有一些其他的线程
咱们的Java进程一旦进行启动,不仅仅有一些自己代码中的线程,还有一些其他的线程(有的进行网络连接,有的进行垃圾回收,有的进行日志打印)

1)run方法里面描述了这个线程内部要执行那些代码,每一个线程都是并发执行的,每一个线程都有每一个线程的代码,是一个完全并发的关系,就需要告诉线程你要执行的代码是什么,run方法的逻辑就是在新创建的线程中,要执行的代码
2)在这里并不是定义这个Thread类的子类,一重写run方法,线程就被创建出来了,相当于是老板把活安排好了,工人们还没有开始干呢
3)需要进行创建Thread子类的实例并且调用start方法,才真正的进行开始执行上面的run方法,所以说在进行调用start方法之前,系统中是没有进行创建出线程的
4)因为两个进程之间是不会相互干扰的,所以我们通过Thread类创建的线程,都是在同一个JAVA进程里面的
package com; class MyThread extends Thread{ public void run(){ System.out.println("执行run方法"); } } public class Solution{ public static void main(String[] args) { MyThread thread=new MyThread(); thread.start(); } }Thread t1=new Thread(){ @Override public void run() { System.out.println(1); } }; t1.start();import java.sql.Time; import java.util.concurrent.TimeUnit; class MyThread extends Thread{ public void run(){ try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("我是线程1里面的方法"); } } class TestThread extends Thread{ public void run(){ try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("我是线程2里面的方法"); } } public class Solution{ public static void main(String[] args) { MyThread t1=new MyThread(); t1.start(); TestThread t2=new TestThread(); t2.start(); } }1)如果说在循环中不加任何限制,那么循环就会转得非常快,就导致我们打印的东西太多了,根本看不过来
2)所以可以加上一个sleep操作,让这个线程强行进行休眠一段时间,这个休眠操作就是让线程强制进入到阻塞状态,单位是ms,意思就是说在指定的毫秒之内,这个线程不会到CPU上面执行
3)InterruptedException就是说线程被打断的异常
4)在一个进程里面,至少会有一个线程,在一个JAVA进程里面,也是说会至少会有一个调用main方法的线程,这个线程不是你自己写的,而是你的系统自动搞出来的,自己创建的线程和main线程就是在并发执行的,宏观上面看起来同时执行,这里面的并发就是指并发+并行,在宏观上面是无法进行区分并发和并行,这完全取决于操作系统的调度执行
4)在的上述代码中,现在有两个线程,都是打印个一条,那么就直接休眠1s,但是当1s时间到了以后,会先执行谁呢?结论就是不知道,这个顺序并不能完全进行确定,所以说操作系统内部对于线程之间的调度顺序,在宏观上面可以认为是随机的,把这个线程以内的随机调度,称之为抢占式执行,线程之间在抢,就存在了太多的不确定因素
1)通过显示创建一个类,实现Runnable接口,然后再把这个继承runnable的实例化对象关联到Thread的实例上;也可以通过匿名内部类的方式来进行创建;
static class myrunnable implements Runnable { public void run() { System.out.println("我是线程"); } } public static void main(String[] args) throws InterruptedException{ Thread t1=new Thread(new myrunnable()); t1.start(); }
2)通过runnable匿名内部类的方式创建一个线程,重写run方法,在直接把这个Runnable类创建的对象关联到Thread里面,这种写法和单独创建一个类,再继承Thread没有任何区别;
直接通过Runnable来进行描述一个线程执行的具体任务,进一步的在把描述好的任务交给Thread实例
1)Runnable myrunnable=new Runnable(){ public void run() { System.out.println("我是一个线程"); } }; Thread t1=new Thread(myrunnable); t1.start(); }} 在这里面主要是说new出来的Runnable接口,创建继承于runnable接口的类的实例 同时将new出来的Runnable实例传给Thread类的构造方法 2)Thread thread =new Thread(new Runnable() { @Override public void run() { System.out.println("我是一个线程"); } }); thread.start();3)通过lamda的表达式的方式创建一个线程,类似于通过匿名内部类的方式来进行创建,只是通过lamda表达式来代替Runnable接口
new Comparator(){ @Override public int compare(Integer o1, Integer o2) { return o1-o2; } }; public class Hello { public static void main(String[] args) throws InterruptedException{ Thread t1=new Thread(()->{System.out.println("我是一个线程");}); t1.start(); 函数式接口 }}
1)咱们的匿名内部类,其中的Comparable接口,Comparator接口,都是可以写成匿名内部类的方式
2)咱们上面的这个匿名内部类的写法就是说进行创建了一个匿名内部类,实现了Comparator接口或者继承于Thread类,同时我们进行重写了run方法,同时还new出了这个匿名内部类的实例
3)Runnable这一种写法要更好一些,因为可以让线程和线程执行的任务可以更好地进行解耦,所以说在写代码的时候,要高内聚,低耦合,同类的功能的代码放在一起,不同的功能模块之间尽量不要有太多的关联关系,Runable只是单纯的描述了一个任务,至于这段代码是有一个线程来进行执行,进程,线程池,协程来进行执行,Runnable本身并不关心,Runnable本身的代码也不会进行关心,以后的代码改动更小,所以说这种写法要更好一些
class Hello{ public static void main(String[] args) throws InterruptedException{ long beg1=System.currentTimeMillis(); Thread t1=new Thread(){ public void run(){ long a=0; for(long i=0;i<1000000000;i++) { a++; } } }; Thread t2=new Thread(){ public void run(){ long b=0; for(long j=0;j<1000000000;j++) { b++; } } }; t1.start(); t2.start(); t1.join(); t2.join(); long beg2=System.currentTimeMillis(); System.out.println("执行时间为"); System.out.println(beg2-beg1); 1)此时我们记录时间是在main线程里面来进行记录的,也是在主线程里面执行的,main线程和t1线程和t2线程是一种并发执行的关系,我们此处就认为t1和t2还没有执行完成呢,main线程就进行记录时间,这显然是不准确的 2)此时我们的正确做法应该是让我们的main线程等待t1线程和t2线程全部执行完成了,再来进行执行我们的main线程 } }public static void main(String[] args){ long beg1=System.currentTimeMillis(); int a=0; for(long i=0;i<1000000000;i++) { a++; } int b=0; for(int j=0;j<1000000000;j++) { b++; } long beg2=System.currentTimeMillis(); System.out.println("执行时间为"); System.out.println(beg2-beg1); } }
上面的join效果就是t1线程和t2线程执行完成之后,再来执行main线程
1)咱们的join的效果就是等待对应线程结束:t1.join就是让main线程等待t1线程结束,t2.join()就是说让main线程等待t2线程结束,上述的这两个线程在我们的底层到底是在并行执行还是在并发执行,这是不确定的,只有真正的两个线程在并行执行的时候,效率才会有显著的提升,但是肯定要比单线程执行的更快
2)如果说进行计算的count值太小,那么此时你创建线程本身也是有开销的呀,你的主要的时间就花在创建线程上面了,光你创建两个线程就用了50ms,但是你计算值的过程就使用了10ms,此时肯定是得不偿失的,只有你的任务量太大的时候,多线程才有优势,只有说进行创建的任务量的总时间大于线程创建的时间,才说多线程可以提高效率
1)主线程还是一直向下走,但是新线程会执行run方法,对于新线程来说,run方法执行完了,新线程就结束了,对于主线程来说,main方法执行完,主线程就结束了
2)线程之间,是并发执行的关系,谁先执行,谁后执行,谁执行到哪里让出CPU,都是不确定的,作为程序员是无法感知的,全权有操作系统的内核负责,例如当创建一个新线程的时候,接下来是主线程先执行,还是新线程,是不好保证的;
3)执行join方法的时候,该线程会一直阻塞,一直阻塞到对应线程结束后,才会继续执行,本质上来说是为了控制线程执行的先后顺序,而对于sleep来说,谁调用谁就会阻塞;
4)主线程把任务分成几份,每个线程计算自己的一份任务,当所有的任务被计算完毕后,主线程再来汇总(就必须保证主线程是最后执行完的线程)
5)获得当前对象的引用 Thread.currentThread()
6)如果线程正在运行,执行计算其逻辑,此时就在就绪队列排序呢,调度器就会在就绪队列找出合适的PCB让他在CPU执行,如果某个线程调用Sleep就会让对应的PCB进入阻塞队列,无法上CPU;
7 对于sleep让其进入阻塞队列的时间是有限制的,时间到了之后,就会被系统把PCB那回到原来的就绪队列中了;
t1.start(); t1.join(); t2.start(); t2.join(); 在这种情况下:t1,t2是串行执行的8)join被恢复的条件是对应的线程结束
1)Thread类中的常见用法,Thread类是用于管理线程的一个类,换句话来说,每一个线程都有唯一的Thread类进行关联
2)Thread的常见构造方法:
Thread() 创建线程对象 Thread(Runnable target) 借助Runnable对象创建线程对象 Thread(String name),创建线程对象,并命名; Thread(Runnable target,String name)通过runnable来进行创建线程对象,并且进行命名 有名字的构造方法就是为了方便调试3)给线程起一个名字,本质上是为了方便程序员来进行调试,我们起一个啥样的名字是不会影响线程本身的执行的,仅仅只是影响程序员来进行调试,我们可以在工具中看到每一个线程以及名字,这样就很容易在调试中对线程进行区分,只是程序调试的小功能,并不会对代码本身的功能造成影响
4)我们在C:\Program Files\Java\jdk1.8.0_301\bin中的jconsole.exe就可以罗列出我们系统上面的Java进程,jconsole.exe就是一个方便与程序员进行调试的工具
import java.util.concurrent.TimeUnit; class MyRunnableT1 implements Runnable{ public void run(){ while(true){ try { TimeUnit.SECONDS.sleep(1000); System.out.println("我是一个任务"); } catch (InterruptedException e) { e.printStackTrace(); } } } } class MyRunnableT2 implements Runnable { public void run() { try { TimeUnit.SECONDS.sleep(1000); System.out.println("我也是一个任务"); } catch (InterruptedException e) { e.printStackTrace(); } } } public class Main { public static void main(String[] args) { Thread t1=new Thread(new MyRunnableT1(),"ThreadT1"); Thread t2=new Thread(new MyRunnableT2(),"ThreadT2"); t1.start(); t2.start(); } }



线程中断:让一个线程停下来,线程停下来的关键,是让先成对应的Run方法执行完,在这里面有一种特殊的情况,是对于这个main线程,对于main线程来说,main方法执行完成,整个线程才会执行完成
1)先把当前任务执行完,再来结束线程
2)任务还在执行,被强制结束
1)通过自己手动的来进行设置一个标志位,这就是自己创建的变量,来进行控制线程是否要结束,搞一个boolean类型的变量或者是int类型的变量,咱们就可以通过标志位,在其他代码中控制这个标志位的值,来进行决定当前线程是否要结束
static private boolean flag=true; public static void main(String[] args)throws InterruptedException { Thread t1 =new Thread(){ public void run() { while(flag==true) { System.out.println("正在发财"); try{ Thread.sleep(500); }catch(InterruptedException e) { e.printStackTrace(); break; } } System.out.println("发财结束"); } }; t1.start(); Thread.sleep(5000); System.out.println("有内鬼"); flag=false; //我们要是将这个flag改成false,那么此时这个循环就退出了,进一步的,run方法就执行完毕了,再进一步就是线程结束了 } }此处因为多个线程在共同用同一块虚拟地址空间,因此main线程修改的flag变量和线程判定的flag变量是同一个值,是同一块内存空间,适合我们最终的线程的特点来进行修改这个代码的,但是在不同的虚拟地址空间里面,这样的代码就有可能会失效
使用标准库中的内置的标记
一)获取线程中内置的标记位:
通过:Thread.interrupted(),这个是一个静态的方法
或者是:Thread.currentThread().isInterrupted(),这个是一个实例方法,其中可以通过Thread.currentThread()来进行获取到当前线程的实例
二:修改线程中内置的标记位:
线程名字.interrupt()来进行执行中断
1)public void interrupted() 中断对象关联的线程,如果线程正在阻塞,那么以异常的方式来进行通知,否则设计标志位
2)Thread.currentThread().IsInterrupted()这个方法的判定的标志位是Thread的普通成员,每一个实例都有自己的标志位;
关于线程的实例.interrupted()方法的时候,可能会导致两种效果:
1)如果说当前这个线程处于就绪状态,那么会设置线程的标记位设置成是true;
2)如果当前这个线程处于阻塞状态(sleep休眠),那么就会触发一个InterruptedException异常,让我们当前的线程从阻塞状态被唤醒;
3)如果说处于sleep状态,调用Interrupt方法,一旦触发了异常之后,就进行了catch语句块,在catch中就单纯打了个日志,可是咱们的标志位并没有真正的进行修改,然后线程就继续在循环里面运行了,不能起到线程终止的作用
4)如果代码中没有任何sleep或者其他阻塞操作,只是做一个循环判定就够了,直接就可以中断线程,如果说我们当前的run方法有阻塞操作(sleep),那么当我们的程序执行了Interrupt方法,并不会真正的修改标志位,只会发生一个异常,就需要在catch语句块里面做出进一步的处理,才可以使我们的线程进行终止;
当使用Thread.currentThread().IsInterrupted()当作循环标志位的时候:
现象:刚一开始程序里面会不断地打印出Hello Thread这样的代码日志,但是当的主线程调用interrupt方法的时候,由于当前线程处于休眠状态,当前线程就会出现InterruptedException异常,不会修改标志位,但是当try代码语句出现异常的时候,就会立即进入到catch语句块里面,打印对应的异常调用栈
1)但是这个代码绝大部分情况下是在休眠的状态下阻塞,所以在代码中直接改成break就可以了,就可以起到中断线程的作用
2)此处的中断,希望是可以立即起到最终的效果,但是如果线程是本身处于阻塞状态下,此时我们本身进行设置标志位就不可以起到及时唤醒的效果
3)此处我们当前的线程处于休眠状态,那么当我们调用这个interrupted方法的时候,就会使这个sleep触发一个异常,那么这就会导致当前线程从阻塞状态被唤醒,咱们的sleep状态被唤醒之后出现异常只是在catch中打印了一个日志就没有了,直接就进入到下一次循环了printStackTrace只是打印当前代码中出现异常位置的调用栈,直接就继续运行了,这个情况是并不科学的
public static void main(String[] args) throws InterruptedException { Thread t1=new Thread(()->{ while(!Thread.currentThread().isInterrupted()){ System.out.println("Hello Thread"); try { Thread.sleep(1000); } catch (InterruptedException e) { //我们应该在这个代码中写上一句,当我们的程序中出现InterruptedException之后,虽然线程从阻塞状态到运行状态之后,我们的线程应该终止运行 e.printStackTrace(); } } }); //在我们的主线程中,我们调用interrupt方法,来进行中断线程,t.interrupt的意思就是让t线程被中断 t1.start(); Thread.sleep(5000); t1.interrupt(); }
4)比如说我正在打游戏,我的妈妈让我去下楼买一瓶酱油,我的处理方式就是如下:
4.1)答应一下,好嘞,然后接着打
4.2)答应一下,好嘞,立即放下游戏就去
4.3)答应一下,好嘞,打完这一局就去
第一种情况就是说处于休眠状态,但是经过打断之后回到就绪状态之后,还是继续执行程序
第二种情况就是说处于休眠状态,但是经过打断之后回到就绪状态之后,直接break了
第三种情况就是说处于休眠状态,但是经过打断之后回到就绪状态之后,要做一些收尾工作,最好要再finallly语句块中执行一段逻辑,再去打酱油或者是说咱们上述那一种使用标志位的方式来进行线程的中断,虽然标志位在线程外边被修改了,但是我们还是要等到当前循环中的逻辑结束之后再来退出循环,结束run方法
中断标记想象成是一个boolean值,初始情况为false,如果外部方法调用interrupt方法,就会把这个终端标记设成true;
但是Thread.currentThread.isInterrupted()方法是属于Thread实例的方法,每一个线程都有一个标志位,还是说自己判断自己是否结束当然还是比较好的;对于Thread.currentThread().interrupted()来说,经过一次打断后,会彻底的改成true;
public class Main{ public static void main(String[] args) throws InterruptedException { Thread t1=new Thread(()->{ while(!Thread.interrupted()){ System.out.println("线程1正在执行"); } System.out.println("线程1终止执行"); }); Thread t2=new Thread(()->{ while(!Thread.interrupted()){ System.out.println("线程2正在执行"); } System.out.println("线程2终止执行"); }); t1.start(); t2.start(); Thread.sleep(2000); t1.interrupt(); } }
线程等待:因为线程与线程之间,调度顺序是完全不确定,它取决于操作系统本身调度器的一个实现,但是有时候我们希望这个顺序是可控的,此时的线程等待,就是一种方法,用来控制线程结束的先后顺序;
1)线程之间,调度顺序是不确定的,线程之间的执行是按照调度器来进行安排执行的,这个过程是无序,随机的,有些时候,但是这样不太好,要控制线程之间的执行顺序,先进行执行线程1,再来执行线程2,再来执行线程3;
2)线程等待就是其中一种控制线程执行的先后顺序的一种手段,此处我们所说的线程等待,就是我们说的控制线程结束的先后顺序
3)当我们进行调用join的时候,哪个线程调用的join,那个线程就会阻塞等待,直到对应的线程执行完毕,也就是对应线程run方法执行完之后,
4)在调用join之后,对应线程就会进入阻塞状态,暂时这个线程无法在CPU上面执行,就暂时停下了,不会再继续向下执行了,就是让main线程暂时放弃CPU,暂时不往CPU上面调度,往往会等待到时机成熟
5)Sleep等待的时机是时间结束,而我们的join等待的时机是当我们的(t.join),t线程中的run方法执行完了,main方法才会继续执行
public class Main{ public static void main(String[] args) throws InterruptedException { Thread t1=new Thread(()->{ for(int i=0;i<5;i++){ System.out.println("hello Thread"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); t1.start(); //我们在主线程中就可以使用一个等待操作来进行等待t线程执行结束 try{ t1.join(); }catch(InterruptedException e){ e.printStackTrace(); } } }join执行到这一行,就暂时停下了,不会继续向下执行,当前的join方法是main方法调用的,针对这个t线程对象进行调用的,此时就是让main等待t,我们这是阻塞状态,调用join之后,main方法就会暂时进入阻塞状态(暂时无法在CPU上执行);
join默认情况下是死等,只要对应的线程不结束,那么我们就进行死等,里面可以传入一个参数,指定时间,最长可以等待多久,等不到,咱们就撤
Thread.currentThread()表示获取当前对象的实例
相当于在Thread实例中run方法中直接使用this
操作系统管理线程: 1)描述 2)组织:双向链表 就绪队列:队列中的PCB有可能随时被操作系统调度上CPU执行1)当前这几个状态,都是Thread类的状态和操作系统中的内部的PCB的状态并不是一致的;
2)然后我们从当前join位置啥时候才可以向下执行呢?也就是说恢复成就绪状态呢?就是我们需要等待到当前t线程执行完毕,也就是说t的run方法执行完成了,通过线程等待,我们就可以让t先结束,main后结束,一定程度上干预了这两个线程的执行顺序
3)我们此时还是需要注意,优先级是咱们系统内部,进行线程调度使用的参考量,咱们在用户代码层面上是控制不了的,这是属于操作系统内核的内部行为,但是我们的join是控制线程代码结束之后的先后顺序
4)就是说带有参数的join方法的时候,就会产生阻塞,但是这个阻塞不会一直执行下去,如果说10s之内,t线程结束了,此时的join会直接进行返回,但是假设我们此时的10S之后,t线程仍然不结束,那么join也直接返回,这就是超时时间
五)线程安全问题:
1)咱们说的就绪状态和阻塞状态,其实是针对系统级别的状态(PCB)
2)线程不安全:由于多线程并发执行,导致代码中出现了BUG,因为操作系统在进行调度线程的时候是随机的,正是因为这样的随机性,才会导致程序的执行会出现BUG
3)如果因为这样的随机性引入了BUG,那么就认为代码是线程不安全的,如果因为这样的调度随机性,没有引入BUG,那么就说明代码是线程安全的,安全不安全,我们在这里面指的是是否出现了BUG
使用两个线程,对同一个整型变量,进行自增操作,每一个线程自增5w次,看看最终的结果
class Counter{ //这个变量就是连各个线程进行自增的变量 public int count; public void increase(){ count++; } } public class Solution { private static Counter counter=new Counter(); public static void main(String[] args) throws InterruptedException { Thread t1=new Thread(()->{ for(int i=0;i<5000;i++) { counter.increase(); } }); Thread t2=new Thread(()->{ for(int i=0;i<5000;i++) { counter.increase(); } }); t1.start(); t2.start(); t1.join(); t2.join(); //让我们的main线程最后执行完,由于我们的线程调度是随机的,咱们也不知道是t1先结束,还是t2先进行结束 System.out.println(counter.count); } }
上面的两个join操作,是一定要进行注意的,这两个Join谁在前,谁在后面无所谓,但是也可以这么说由于我们的线程调度是随机的,我们也是不知道是t1先结束还是t2先结束
1)假设我们的t1先进行结束,那么就先进行执行t1.join,然后进行等待t1结束,t1结束了,那么开始调用t2.join(),等待t2结束,t2结束了,我们t2.join()执行完毕,
2)假设此时的t2线程先进行结束,因为我们是先进行执行t1.join(),等到t1结束,t2结束了,t1没有结束,那么我们此时的main线程仍然阻塞在t1.join()里面,在过了一会,t1结束了,我们此时再次执行t2.join(),因为之前说过,t2已经结束了,t2.join()就会立即返回
3)两个线程,操作的是同一个变量,变量是什么类型没有什么关系,和静态不静态没有什么关系,只要两个线程操作的是同一个变量,就没有什么关系
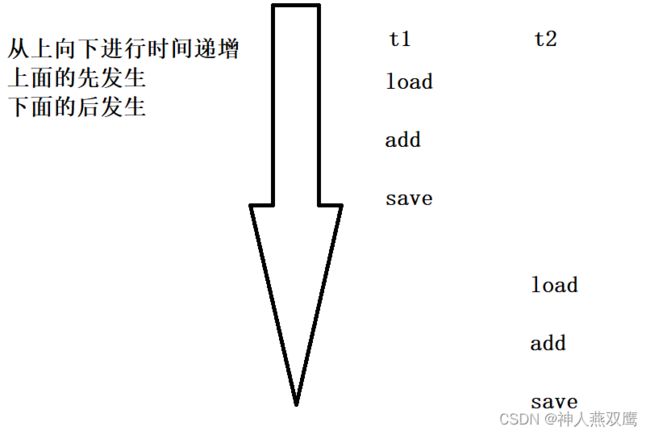
自增的内容分成三步,咱们的变量都是在内存里面,一个++操作,就分成了三个指令
假设两次自增操作数据在不同的CPU上执行
1)把内存中的count数据读取加载到CPU寄存器里面;load
2)在CPU中的寄存器中把数据加1(比其他两个操作快1000倍);add
3)再把计算结果也就是CPU寄存器的值,结果写回到内存中;save
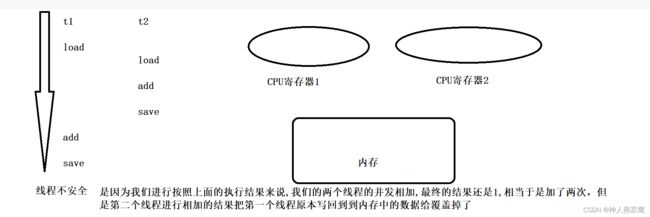
当CPU执行到上面三个步骤的任何一个步骤的时候,都随时可能会被调度器抢走,让给其他线程执行,正是因为咱们前面说的抢占式执行,这就导致两个线程同时执行这三条指令的时候,顺序上面就充满了随机性,每一种情况都有可能发生
上面这两种情况是不会产生线程安全问题的
虽然我们执行了两次相加,但是内存的数据仍然少加了一个1,只有两次的三条指令,是完全串行执行的时候就不会出现问题,如果说这两种线程的指令出现相互交错,那么最终的结果就会出现问题,就会少进行相加一次
一:一个线程修改一个变量,线程安全;
二:多个线程同时读取一个变量,线程安全:读,只是把内存中的数据放到CPU中,不管怎么读,内存中的数据是始终不会进行改变的
三:多个线程修改不同的变量,线程安全(自己修改自己的),两个线程去自增自己的两个变量,就不会影响到结果

一)为什么多次运行结果不是10000?这就涉及到线程安全问题,只要两个线程同时操作的是一个变量,就会出现问题
1)因为在5w对并发相加过程中,有时候操作可能是串行执行的,那么此时就加上2,有的时候可能是交错的,如果说两个操作时进行交错的,那么结果就+1
2)在极端情况下,如果说所有的操作都是串行执行的,那么此时结果就是10W
如果说所有的操作都是进行交错执行的,那么此时的结果就是5W,也是可能出现的,但是是小概率事件,串行多少次和进行交替多少次,我们不知道,这都是操作系统进行调度执行产生的效果,因此我们就无法预知最终结果是多少,只不过是有多少次串行执行,这才是最终会影响结果
二)编译器的优化问题:编译器不会到内存里面读
众所周知,编译器从内存里面读数据和把CPU操作过的数据放回到内存里面,这个过程会比在CPU中操作数据要慢的很多,于是编译器就把这个过程给优化了,直接不断地在CPU里面进行操作,这样就会导致线程安全问题;如果说在单线程环境下,这样的操作绝对没有问题,但是在单线程环境下,就出大问题了;
两个线程要是去分别自增两个变量,就最终不会影响到结果
要是没有多个线程进行操作同一个资源就不会产生线程安全问题
//1.在方法前面加上synchronized关键字,进入到方法就会自动加锁,离开方法就会自动解锁 public synchronized void increase(){ count++; } //2.当我们给一个线程加锁成功的时候,其他线程尝试进行加锁,此时就会触发阻塞等待,此时对应的线程就处于Blocked状态 //3.阻塞会一直持续到占用锁的线程把锁释放位置
1)操作系统抢占式执行,线程调度随机,这是万恶之源,无能为力;
2)多个线程同时修改同一个变量,适当调整代码结构,避免这种情况;
3)针对的变量操作不是原子的,count++本质上是三个指令:load,add,save;
4)内存可见性:一个线程读,一个线程写,直接读寄存器,不读内存,这也是一种优化;
5)指令重排序:编译器优化,CPU自身的执行;

线程安全问题产生的原因:
1)线程是抢占式执行,这是线程不安全的根本原因,解决方法:没有,假设线程之间不是抢占式执行的,而是其他的调度方式,那么就可能没有线程不安全问题了,也有协商式执行的,虽然这是根本原因,但是我们拿他无可奈何,毕竟这是操作系统自身的机制,咱们也改变不了,它天然就是充满随机性的,因为操作系统的调度完全由内核负责,线程之间的调度不可预期,线程的调度充满随机性,线程谁先执行谁后执行,谁后执行,到哪里从CPU上下来
都是不确定的;导致两个线程里面执行的操作顺序无法确定,随机性是导致线程安全问题的根本所在;
2)多个线程针对同一个变量进行修改操作,多个线程同时批量执行一些不是原子性的操作
2.1)多个线程同时修改同一个变量会发生线程问题;多个线程针对不同的变量进行修改不会发生线程安全问题,多个线程针对同一个变量读,不会发生线程安全问题
2.2)针对变量的操作不是原子性,但是赋值这样的操作就认为是一个原子性的操作,(读取变量的值,只是对应着一条机器操作指令,这样的操作本身就可以视为是原子性的操作
2.3)通过加锁操作,也是把好几个指令打包成一个原子性的操作了
2.4)自增或者自减操作,本身就不是一个原子性的操作
2.5)什么是原子性的操作?不进行拆分,一步就到位的那一种操作,就是原子性的操作
2.6)由于不是原子性的操作,那么就会更容易的在多线程调度中出现问题,原子性的操作直接一步到位,所以说多个线程读,就没有什么问题);
2.7)可以通过调整代码结构,使不同的线程操作不同的变量,只要不是多个线程同时操作同一个变量,那么就不会有太大的问题
2.8)自增操作不是原子的 ,上面的++操作,本质上分成三个步骤,是一个非原子的操作;
2.9)在这里面的加锁操作,就是将若干个非原子性的操作,打包成原子性的操作
3)内存可见性:最终内存可见性操作,都是由咱们的JAVA编译器进行代码优化的效果,一个线程在不断地进行读,一个线程针对这个变量进行修改
3.1)原因就是说咱们的JAVA编译器是不会相信程序员的,编译器就会假设程序员就是一个XXXX,写的代码就是一坨XXX,编译器就会对程序员写的一些代码做出一些调整,保证在原有逻辑不变的情况下,程序的执行效率可以大大提高,这就叫做编译器优化
3.2)在我们保证原有逻辑不变的情况下,大部分情况下,都是可以保证的,但是在多线程的环境下,是可能翻车的,因为多线程执行代码的不确定性,导致在整个编译器编译阶段,就很难预知执行行为的,进行的优化就有可能会发生误判,因为优化的误判就有可能会发生线程不安全的问题;
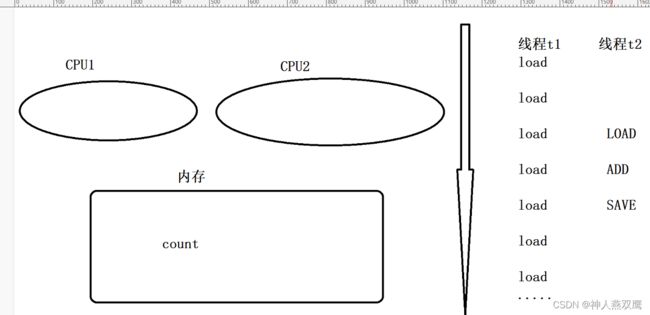
基本定义:线程A针对这个变量进行读操作,线程B针对这个变量进行修改操作,注意A和B都是对应的是操作同一个变量,一个线程进行读操作这是我们进行循环很多次,我们的一个线程进行修改操作,在合适的时候执行一次;
1)一个线程修改了共享变量的值,其他线程来不及看到最新修改的值 ,和原子性类似,与编译器优化相关;
2)如果有多个线程,针对同一个变量,一个线程t1进行读操作(循环进行很多次),一个线程t2修改数据(合适的时候执行一次),可能会导致线程不安全;
3)咱们线程在循环读取内存操作,是一个非常低效的事情,如果说t1线程在频繁的读取这里面的内存里面的值,就会非常低效,如果说t2线程迟迟不修改,t1线程读到的值有始终是一个值,因此t1就会产生一个大胆的想法,直接从CPU的寄存器里面读,不从内存里面读
此时如果说等了很久,t2线程修改了count值,那么t1线程就感知不到了
private static int flag=0; public static void main(String[] args) { Thread t1=new Thread(){ public void run() { while (flag == 0) { //加上sleep操作,就不会进行优化,可能加上了sleep操作之后 //就是说可能不会频繁的读取内存的数据加载到CPU里面了 //t1线程不断地从快速的从CPU的寄存器里面进行读取数据 } System.out.println("当前循环结束,当前线程结束,t1线程退出"); } }; t1.start(); Scanner scanner=new Scanner(System.in); System.out.println("请输入你要修改的flag的值"); flag=scanner.nextInt(); System.out.println("当前的main线程已经执行完毕"); } } 上面的这个操作就是类似于第一个线程在不断地进行读操作,第二个线程进行针对这同一个变量进行修改操作;

解决方法线程安全问题:
1)使用synchronized关键字,synchronized不光可以保证原子性的指令,还可以保证内存可见性,指令重排序,被synchronized包裹起来的的代码,编译器不敢轻易的做出上面的假设,于是手动的禁止了对编译器的优化,所以说我们使用synchronized的时候禁止编译器进行优化操作,会使我们的程序的效率会大大降低
2)使用volatile关键字,是和原子性无关,禁止编译器优化,每一次在循环条件里面判定是否相等,都会强制刷新内存中的内容到我们的CPU寄存器里面,能够保证内存可见性
指令重排序:
Java的编译器在编译代码时,也会针对指令进行优化,调整指令的先后顺序,保证原来指令逻辑不变的情况下,提高程序运行效率;
synchronized不光可以保证原子性,同时还可以保证内存可见性,还可以禁止指令重排序
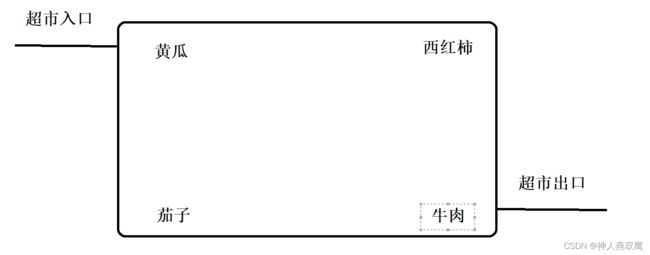
1)比如说我妈妈让我买牛肉,黄瓜,茄子,还有西红柿,如果我们按照这种顺序从进入超市之后一个一个找,从进入超市门口之后,先去到超市出口买牛肉,再去超市入口卖黄瓜.....
这种效率就非常低
2)可以针对买的顺序的一个指令进行优化,先买黄瓜,再买西红柿,这样我们的走的路程就会少了很多,整个路程也会更短
3)在我们的上面的那一个买菜的例子中,我们如果说要是可以能够调整一下代码执行的先后顺序,最终的执行结果不变,但是我们的程序执行效率就大大的提高了
4)咱们以前写的很多代码,彼此的顺序,谁在前面,谁在后面都是无所谓的,在这里面我们的编译器就会智能地进行调整代码执行的前后顺序,从而提高程序的效率,总而言之,保证逻辑不面的条件下来进行优化的
1)也就是说编译器会自动的调整指令的顺序,以便达到提高执行效率的结果,但是调整的前提是,保证指令的最终结果是不变的;
2)编译器优化,是一个非常智能的东西,如果当前的判断逻辑只是在单线程下执行编译器根据顺序来判断结果,还是比较容易的;但是如果在多线程情况下,编译器也可能会进行误判,编译器判定顺序是否会影响结果,就不一定了;使用synchronized不光可以保证原子性,还可以保证内存可见性,保证指令重排序
synchronized关键字的作用:
1)互斥使用
2)避免内存可见性,指令重排序
3)可重入锁
咱们的synchronized的使用是要付出代价的,代价就是一旦使用synchronized很容易会导致线程阻塞,一旦线程阻塞(放弃CPU),下一次我们这个线程再次回到CPU就会变得很困难,这个时间是不可控的,如果调度不回来,可能是沧海桑田,自然对应的任务执行时间也就被拖慢了,一旦代码使用synchronized,就会基本和高性能无缘,volaitile不会导致线程阻塞
1)进入increase之后加了一次锁,进入代码块之后又加了一锁,在这里面synchronized在这里进行了特殊处理;
2)如果是其他语言的锁操作,就有可能造成死锁;
第一次加锁,加锁成功
第二次在尝试对这个对象头加锁的时候,此时对象头的锁标记已经是true,按照之前的理解,线程就要进行阻塞等待,等待这个所标记被改成false,才重新竞争这个锁,但是此时是在方法内部,肯定是无法释放第一次所加的锁的,就出现死锁了;


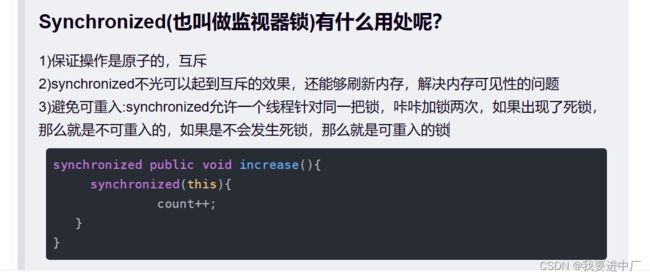

synchronized public void increase() { count++; } synchronized public void increase2() { increase(); }synchronized public static void run() { synchronized (Student.class) { System.out.println("我叫做run方法"); } }3)在可重入锁内部,会记录当前的锁是被哪一个线程占用的,同时也会记录一个加锁次数;当我们的线程A对这个锁进行第一次加锁的时候,显然是能加锁成功的,锁内部就会进行记录,当前占用着的线程是A,同时加锁次数是1,后续我们再次针对这个线程A进行加锁的时候,此时就不会真的加锁,而只是单纯的把引用计数给自增,加锁次数是2,后续我们进行解锁的时候,再把引用计数减1,当我们进行把引用计数减到0的时候,就真的进行解锁,所以说后续的加锁操作对这个线程持有这把锁是没有本质影响的;
3.2)咱们的可重入锁的意义就是为了降低程序员的负担,降低使用成本,提高了开发效率,但是也带来了代价,程序中需要有额外的开销,因为我们要维护锁属于哪一个线程,并且进行加减计数,这个变量还占用空间,降低了运行效率,开发效率最重要
3.3)如果说我们使用的是不可重入锁,此时我们的开发效率就降低了,如果我们一不小心,代码中就出现死锁了,线上程序出BUG了,就需要修BUG了,如果BUG严重了,年终奖可能会泡汤
4)解决指令重排序,避免乱序执行
当synchronized修饰方法的时候有以下需要进行注意:
1)synchronized关键字不可以被继承:虽然可以使用synchronized来进行修饰方法,但是synchronized并不属于方法中的一部分,因此synchronized关键字不可以被继承,如果说你在父类中的某一个方法中使用了synchronized关键字,在子类中重写了这个方法,在子类中的某一个方法并不是同步的,必须显示的在子类中加上synchronized关键字才可以
2)定义接口方法中不能使用synchronized关键字
3)在构造方法中不能使用synchronized关键字,但是可以使用synchronized同步代码快来进行同步
总结:synchronized修饰普通方法和同步代码快指定this表示给当前对象进行加锁,就是当不同线程尝试访问一个对象中的synchronized(this)同步代码快的时候,其他访问该对象的线程将会被阻塞
class RunnableTask implements Runnable{ public void GetCount(){ System.out.println("生命在于运动"); } public void run() { synchronized (this){ try { TimeUnit.SECONDS.sleep(10); System.out.println("我是中国人"); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Solution { public static void main(String[] args) { RunnableTask task=new RunnableTask(); Thread t1=new Thread(task); Thread t2=new Thread(task); t1.start(); t2.start(); //上面这种情况就会发生阻塞 //但是下面这种情况就不会发生阻塞,不会产生锁的竞争 RunnableTask task1=new RunnableTask(); RunnableTask task2=new RunnableTask(); Thread t3=new Thread(task1); Thread t4=new Thread(task2); t3.start(); t4.start(); } }
1)当我们的两个并发线程t1和t2在进行访问同一个对象的synchronized(this)修饰的同步代码快的时候,同一时刻只能有一个线程被执行,一个线程被阻塞,必须等待一个线程执行玩这个同步代码快之后另一个线程才可以执行这个代码块
2)t1和t2是互斥的,因为在我们执行synchronized代码块的时候会进行锁定当前的对象,只有执行完该同步代码快的才能释放该对象的锁,下一个线程才能执行并且锁定该对象
3)但是被注释掉的那一片代码,t3和t4在同时进行执行,因为他们是访问两个对象中的被synchronized修饰的方法或者是同步代码快,这是因为synchronized只锁定对象,每一个对象只有一把锁与之相关联
4)当一个线程访问一个对象的synchronized的同步代码快的时候,另一个线程仍然可以访问该对象的非同步代码快
1)synchronized给静态方法加锁是全局的,也就是说在整个程序运行期间,所有调用这个静态方法的对象都是互斥的,而普通方法是对象级别的,不同的对象对应着不同的锁
2)当我们修饰静态代码块的时候,需要指定一个加锁对象,可以给this来进行加锁,表示给当前的对象加锁,不同的对象对应着不同的锁,但是我们给.class进行加锁的时候,表示给某个类对象进行加锁
volatile:禁止编译器进行优化,保证内存可见性,是因为计算机的硬件结构决定的
JMM内存模型就描述了,CPU指令内存之间的交互过程和硬件结构用AVA这里面的术语重新进行了封装
在这里面,涉及到一个重要的知识点,JMM(Java memory model内存模型)
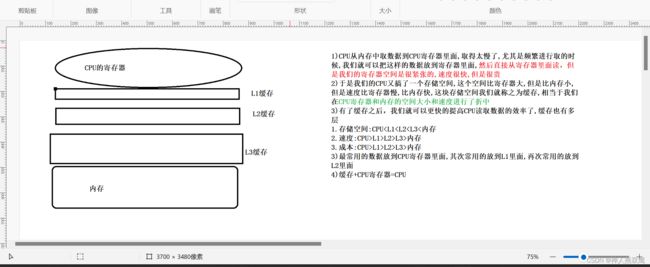
1)正常情况下,是想要把内存中的数据读到CPU里面进行操作,但是实际上在CPU和内存中还会存在这一些缓存,为了提高CPU和内存之间的读写效率;
2)当我们在代码中读取变量的时候,不一定是在真的读内存,可能这个数据已经在CPU或者cathe中缓存着了;
3)这个时候就可能会绕过内存,直接从CPU寄存器里面或者cathe中取数据,咱们的JMM针对计算机的硬件结构,又进行了一层抽象,主要是因为Java是要跨平台,要能够支持不同的计算,有的计算机可能没有catche2内存,可能也会有catche3内存,当这个变量进行修改的时候,此时读的这个线程没有从内存里面读,而是从catche里面读,或者CPU中的寄存器里面读,就会出现内存可见性的问题;4)JMM就会把CPU中的寄存器,L1,L2,L3catche,统称为工作内存,把真正的内存称为主内存,工作内存一般不是真的内存,每一个线程都会有自己的工作内存,每个线程都有独立的上下文,独立的上下文就是各自的一组寄存器,catche中的内容
5)CPU和内存进行交互时,经常会把主内存中的内容,拷贝到工作内存,然后再进行工作,写会到主内存中,这就可能会出现数据不一致的情况,这种情况是在编译器进行优化的时候特别严重


关键字volitaile和synchronized就可以强制保证接下来的操作是在操作内存,在生成的java字节码中强制插入一些内存屏障的指令,这些指令的效果,就是强制刷新内存,同步更新主内存和工作内存中的内容,在牺牲效率的时候,保证了准确性
这就类似于我现在要出远门,要带行李
内存:就是我们家
CPU寄存器:就是我的手
揣个口袋:相当于是catche1缓存,这里面存放了我最常用的数据,比如说身份证,钱财
背了个背包:相当于是catch2缓存,这里面存放了我不太常用的数据,比如说水杯,牙刷
带了个行李包:相当于是catche2缓存,里面存放了一些最不常用的东西,比如说衣服
1)咱们如果说出门忘带东西了,那么就赶紧回到内存中,同步更新工作内存的内容
从内存取东西,从家里面取东西,效率最低,但是直接从缓存中拿数据,最好是直接从口袋中拿数据
2)之前我们进行循环进行读取内存,就是类似于你出外面办事情,发现用到什么东西就会到家里面取,这样的开销实在是太大了
3)工作内存:CPU寄存器+缓存
1)计算机想要执行一些计算,就需要把内存中的数据写入到CPU的寄存器里面,然后再在寄存器中进行计算,再写回到内存里面,直接读寄存器,CPU访问寄存器的速度是要比访问内存的速度要快的多,当CPU连续多次访问内存,发现结果都一样,就不会从内存里面读了,就直接会从CPU的寄存器里面读就可以了;
2)在Java中,要先把数据从主内存加载到工作内存里面,工作内存计算完毕之后在写回到主内存里面
六)单例模式:
1)单例模式是什么:单例模式是一种常用的软件设计模式,其定义是单例对象的类只能允许一个实例存在,设计模式就是根据常见场景给出的一些经典解决方案;
2)饿汉模式:在类加载的过程中就把实例创建出来
3)懒汉模式:通过getInstance方法来获取到首例首次调用该方法,用了才创建,不用就不创建
4)最大的区别就是说对于我们代码中的唯一实例实例化的初始时机是不一样的
这就类似于吃完饭洗碗:
1)中午这一顿饭,使用了四个碗,吃完之后,就立即把这四个完给洗了,这就是所说的饿汉模式,就是很着急
2)中午这顿饭,使用了四个碗,吃完之后,先不洗,因为晚上这一顿只需要两个碗,然后直接就洗两个碗就可以了;就是懒汉模式,我们认为这是一个更加高效的操作
我们的饿汉的单例模式是很着急的创建实例的
我们的懒汉的单例模式是不算太着急的创建实例的,只是在用的时候创建实例
1)饿汉模式
一)使用static创建一个实例并且立即进行实例化,这个instance实例就是该类的唯一实例
二)为了防止在其他地方程序员不小心在其他地方new了一个Singleton,就可以把这个构造方法设置成私有的,你如果想要new只能在类的内部new;
三)提供一个公开的static静态方法,让类外可以直接拿到这一个唯一实例;
//我们通过Singleton这个类来进行创建单例模式,来进行保证Singleton只有一个唯一的实例 static class Singleton{ private Singleton(){}; //把构造方法设成私有的,防止在类外调用构造方法,也就禁止了调用者在其他地方创建实例的机会 private static Singleton instance=new Singleton(); public static Singleton getInstance() { return instance; } } public static void main(String[] args) { Singleton s1=Singleton.getInstance(); Singleton s2=Singleton.getInstance(); System.out.println(s1==s2); } //针对这个唯一实例的初始化比较着急,类加载阶段阶段,我们就会直接创建实例 //程序中使用到了这个类,就会立即进行加载
1)这里的打印结果是true;
2)要创建这个类的实例只能提供一个静态公共方法,此处的getInstance是获取该类实例的唯一方式,不应该有其他方式来获取该实例;
3)static修饰的成员准确的来说应该是类成员,也叫做类属性或者类方法,不加static修饰的成员,就叫做实例成员,也称之为实例属性,或者是实例方法
4)JAVA程序,一个类对象是指只存在一份的,这是JVM来进行保证的,进一步也就保证了说咱们的类的static成员也是只有一份的,总结这个类的实例和获取这个类的实例方法都是static的,主要是不想依赖对象的实例来进行调用,类对象只有一个,但是实例确实有很多个
5)对于饿汉模式来说,类加载只有一次,就是在类创建的时候,当我们调用getInstance的时候,getInstance只做了一件事,那就是读取instance实例的地址,这就相当于多个线程同时读取同一个变量,不涉及到修改
6)多个线程调用getinstance就是相当于是多个线程同时来读引用里面的值,返回引用里面的值,是不会有线程安全问题的,只是把的内存里面的值加载到我们的CPU的寄存器里面
2)懒汉模式(效率更高),不太着急创建实例
1)当没有使用到这个实例的时候,就算我们需要用到这个类的时候,但是也并不会进行真正的初始化,只有说什么时候真正的调用到这个方法的时候,我们才真正的进行初始化操作
2)也就是说只有我们真正的用到这个实例的时候,我们才会真正的创建这个实例
3)线程是否安全指的是具体是在多线程环境下,并发的调用GetInstance方法,看看是否可能会创建出多个实例,也就出现了BUG
static class Singleton{ private Singleton(){}; private static Singleton instance=null; //防止其他程序员在外边new这个实例,就可以让构造方法是private public static Singleton getInstance() //只有调用到getInstance的时候才会创建实例 { if(instance==null) { instance=new Singleton(); } return instance; } } public static void main(String[] args) { Singleton s1=Singleton.getInstance(); Singleton s2=Singleton.getInstance(); System.out.println(s1==s2); }1)在一个Java成员里面,一个类对象只存在一份,进一步就保证了类的static成员也是只有一份的,static修饰的成员,叫做类成员,类对象,就是.class文件,被JVM加载到内存中的摸样,类对象里面就有有关于.class文件的一切属性,只有基于类对象,我们才能完成反射;
2)一开始的时候,instance指向的内容为null,在main函数里面,s1的时候创建了一个对象,instance就指向了一个对象,当第二次调用的时候,因为原来已经有这个对象了,所以并不会进入到这个If语句中,返回的还是上一次s1调用的实例,所以两个变量指向的是同一块地址,所以返回结果为true;
3)咱们一直说类加载,类加载,那么类加载到底是什么?就是把,class文件,加载到内存里面变成我们的类对象,通过类名.class,我们的类对象就有包含.class文件的一切信息,包括类名是什么,类里面有什么属性,每一个属性叫什么名字,每一个属性是什么类型,每一个属性是public还是private,基于这些信息,我们才可以使用反射;比如说我们想要获取到类中某一个名字是value的属性,先通过类对象找到这个value属性在我们对象中的偏移量,然后再去对应的内存空间里面一找,就找到了这个值;
4)类本质上就是一个实例的模板,基于这个模板我们可以创建出很多的对象来;
饿汉模式与懒汉模式
1)饿汉模式:类加载的时候没有被实例化,当第一次调用getinstance的时候才真的被实例化了,要是一整场都没有调用getInstance,实例化的过程也就省略了
2)一般认为懒汉模式比饿汉模式效率更高,因为懒汉模式很大的时候实例用不到,此时有了节省实例化的开销;
1)饿汉模式:一个典型的场景:像我们的notepad这样的程序,在我们大开大文件的时候是很慢的,你要想打开这一个G的文件,我们就需要尝试把这1G的大文件都进行加载到内存里面
2)懒汉模式:像我们的一些其他的程序,在我们尝试打开大文件的时候就会进行优化,比如说我们想要打开1G的文件,但是只能先进行加载这一个屏幕中我们能够显示的部分,便翻页便进行加载,翻多少,我们就进行加载多少,用多少加载多少
对于懒汉模式,线程不安全
1)在的饿汉模式里面,读取地址里面的值本身就是一条原子性的指令,但是懒汉模式里面,既包含了读,又包含了修改况且这里面的读和修改,还是分成两个步骤的,不是原子的指令,因此就存在线程安全问题
1)读取instance的内容
2)判断是否为空
3)如果instance为null,就创建一个对象
4)返回instance的值


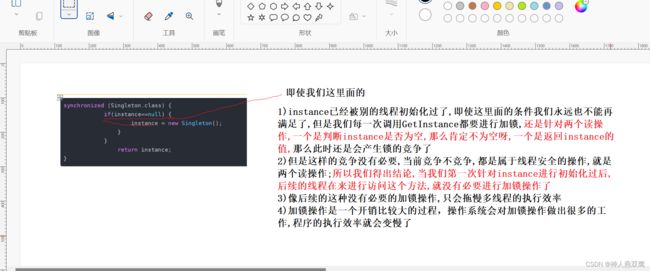
1)下面的这种写法是一种非常非常错误的写法,因为只是给赋值操作进行加了锁,进行对我们类的实例instance判断是否为空没有进行加锁
2)假设现在有两个线程同时调用了getInstance()方法,同时进行判断当前的instance实例是否为空?是的呢,然后线程1进入到锁内部,然后创建实例,此时线程2在线程1进行创建实例之后,就不会再进行判断instance是否为空了,因为之前已经判断过了,此时线程2就会获取到锁,然后创建实例
synchronized (Singleton.class) { if(instance==null) { instance = new Singleton(); } } return instance; }

这次加了双重if来优化代码:避免频繁的触发不必要的加锁操作:
1)当前这个代码,首次调用getinstance此会发生线程安全问题,后续再进行操作,就不会涉及到修改操作了也就是new操作了;按照刚才这个写法,不仅仅使首次调用会加锁,后续进行调用的时候也会涉及到加锁操作;
2)对于刚才的这个懒汉模式的代码来说,线程不安全,是发生在instance被初始化之前的,未进行初始化的时候,多线程调用getInstance,就可能涉及到读与修改,但是一旦Instance被初始化之后,if判断语句一定不是null了,if条件一定不成立了,GetInstance也就只剩下两个读操作,也就是线程安全的了,这两个读操作分别是判断if语句中的条件是否成立,还有直接进行return操作,但是我们的程序中还是对这两个操作进行了加锁,好像没有什么必要了;
3)按照上面的加锁方式,无论是代码初始化之后,还是初始化之前,每一次调用GetInstance方法之后都会进行加锁,也就是针对两个只读操作进行加锁,也就意味着即使是初始化完成之后,也要进行大量的锁竞争,程序的速度就慢了;
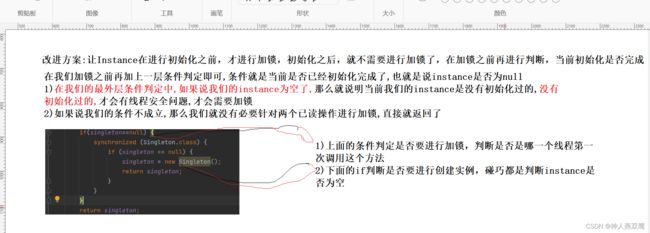
1)改进思路:首次调用的时候,进行加锁,后续进行调用的时候,就不会进行加锁;
2)在上面的代码中,看起来两个一样的if条件是相邻的,但是实际上这两个条件的执行实际差别是很大的,加锁是由可能会使代码出现阻塞,外层条件是10:16分进行执行的,但是里层条件可能是10:30分执行的,在这个执行差中间,instance也是有可能被其他线程给修改的
3)从上述的代码中分析不是说出现了多线程就需要进行加锁,从上述情况下可知只有在第一次进行初始化的时候才需要进行加锁,后续线程调用到这个方法的时候,就不需要进行加锁了,但是我们JAVA标准库中的集合类,vector,HashTable就是这两个集合类在无脑加锁
4)如果去掉里面if操作就变成了刚才那一个典型的错误代码,加锁没有进行把读操作修改操作给打包到一起
5)如果说是针对方法来进行加锁,那么此时就是无脑加锁,显然就不会提高程序执行的效率
class Singleton { private Singleton() {} private static Singleton instance = null; public static Singleton getInstance() { if (instance == null) { synchronized (Singleton.class) { if (instance == null) { instance = new Singleton(); } } } return instance; }

使用volatile来保证内存可见性和指令重排序:
正常情况下加上了双重校验锁之后,应该就是下面这种情况:

1)但是加了双重if后,会出现内存可见性的问题,在最开始的时候,如果我们现在有很多线程,都去调用这里面的GetInstance,就会造成大量的读instance内存的操作,涉及到要读内存,编译器可能让这个读内存操作编程优化操作,直接读CPU寄存器或者缓存,一个线程可能都已经对instance进行了修改,咱们的另一个线程的最外边的if语句还是再读CPU寄存器里面的值呢,那么最外边的条件加不加没啥意思,因为我们的内存可见性问题只会引起第一个if语句判定失效,但是对于第二个if语句影响其实不大,因为我们的synchronized也是可以保证内存可见性的,因此这样子的内存可见性问题,只会影响到第一个条件的误判,也就是说导致不应该加锁的地方进行了加锁,但是不会影响到第二层if的误判,不至于说创建多个实例
2)一旦这里面触发了优化,那么比如说后续的第一个线程完成了针对instance的修改操作,那么紧接着后面的线程都感知不到后面的修改操作,仍然把instance当成空值,内存可见性问题,可能会引起第一个if判定失效,但是当进入synchronized(保证内存可见性)之后,再去判断if语句,就不会影响,就是最终造成的结果是引起第一层的误判,不该加锁的加锁了,不至于说创建多个实例,不会导致单例模式失效,就会导致锁的竞争变得更激烈了;
3)首批线程进入到第一层if,进入到锁阶段,并创建好对象之后,这个时候,就相当于把instance的实例设成非空的值了;但是在后续线程调用方法读取instance的值时,可能就会出现内存可见性的问题;
总结:为了保证懒汉模式的线程安全:
1)加锁 保证线程安全,在这里面使用我们的类作为锁对象,类对象在程序中只有一份,就能保证getInstance都是针对同一个对象进行加锁
2)双重if保证效率,避免进行不必要的重复加锁操作
3)加上volatile保证避免出现内存可见性的问题
下面来看一下完整的正确代码
class Singleton { private Singleton() { } private static volatile Singleton instance = null; public static Singleton getInstance() { if (instance == null) { synchronized (Singleton.class) { if (instance == null) { instance = new Singleton(); } } } return instance; }

