第"三"行代码-kotlin部分学习笔记
1 Kotlin快速入门
01 运行kotlin项目
可以百度kotlin代码在线运行网站。
可以在Android studio 新建kotlin文件直接运行(前提是在Android studio建立的kotlin版本项目下)
2 编程之本:变量和函数
01 变量
只允许在变量前声明两种关键字:val和var。
- val(value的简写)用来声明一个不可变的变量,这种变量在初始赋值之后就再也不能重新赋值,对应Java中的final变量。
- var(variable的简写)用来声明一个可变的变量,这种变量在初始赋值之后仍然可以再被重新赋值,对应Java中的非final变量。
Kotlin完全抛弃了Java中的基本数据类型,全部使用了对象数据类型。
显示声明变量类型
val a:Int = 10
| Java基本数据类型 | Kotlin对象数据类型 | 数据类型说明 |
|---|---|---|
| int | Int | 整型 |
| long | Long | 长整型 |
| short | Short | 短整型 |
| float | Float | 单精度浮点型 |
| double | Double | 双精度浮点型 |
| boolean | Boolean | 布尔型 |
| char | Char | 字符型 |
| byte | Byte | 字节型 |
02函数
fun methodName(param1: Int, param2: Int): Int {
return 0
}
参数的声明格式是“参数名: 参数类型”,其中参数名也是可以随便定义的,这一点和函数名类似。如果不想接收任何参数,那么写一对空括号就可以了。
参数括号后面的那部分是可选的,用于声明该函数会返回什么类型的数据,上述示例就表示该函数会返回一个Int类型的数据。如果你的函数不需要返回任何数据,这部分可以直接不写。
例子:
fun largerNumber(num1 : Int,num2 : Int){
return max(num1,num2)
}
fun main() {
val a = 37
val b = 21
val value = largerNumber(a,b)
println(value)
}

3 程序逻辑控制
01 if语句
fun largerNumber(num1 : Int,num2 : Int){
var value = 0
if (num1 > num2) {
value = num1
} else {
value = num2
}
return value
}
简化:
fun largerNumber(num1: Int, num2: Int): Int {
return if (num1 > num2) {
num1
} else {
num2
}
}
语法糖简化(当一个函数只有一行代码时,可以省略函数体部分,直接将这一行代码使用等号串连在函数定义的尾部。)
fun largerNumber(num1: Int, num2: Int)
=
if (num1 > num2) {
num1
} else {
num2
}
语法糖再简化
fun largerNumber(num1: Int, num2: Int) = if (num1 > num2) num1 else num2
02 when语句
有点类似java中的switch
fun getScore(name: String) = when (name) {
"Tom" -> 86
"Jim" -> 77
"Jack" -> 95
"Lily" -> 100
else -> 0
}
格式: 匹配值 -> { 执行逻辑 } (当执行逻辑只有一句话时,可以省略{})
除了精确匹配之外,when语句还允许进行类型匹配
fun checkNumber(num: Number) {
when (num) {
is Int -> println("number is Int")
is Double -> println("number is Double")
else -> println("number not support")
}
}
03 循环语句
val range = 0..10
//val range = 0 until 10
//val range = 10 downTo 0
for (i in range){
println(i)
}
其中
0…10相当于[0,10]
0 until 10 相当于[0,10)
10 downTo 0 相当于 [10,0]
4 面向对象编程
01 类与对象
定义一个类:
class Person {
var name = ""
var age = 0
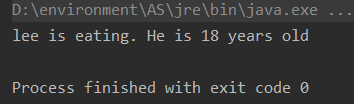
fun eat(){
println(name + " is eating. He is " + age + " years old")
}
}
new 对象
fun main(){
var p = Person()
p.name = "lee"
p.age = 18
p.eat()
}
02 继承和构造函数
令Person类可以被继承
//添加open
open class Person {
...
}
Student继承Person
1.
//每个类默认都会有一个不带参数的主构造函数,
//当然你也可以显式地给它指明参数。
//主构造函数的特点是没有函数体,直接定义在类名的后面即可。
class Student : Person() {
var sno = ""
var grade = 0
//重写tostring方法
override fun toString(): String {
return "Student(sno='$sno', grade=$grade)"
}
}
//实例化
var stu = Student()
stu.age = 18
stu.name = "lee"
stu.grade = 4
stu.sno = "2017051313"
2.主构造函数的特点是没有函数体,直接定义在类名的后面即可
class Student(val sno: String, val grade: Int) : Person() {
}
//在这里,Person类后面的一对空括号表示Student类的主构造函数在初始化的时候会
//调用Person类的无参数构造函数,即使在无参数的情况下,这对括号也不能省略
//实例化
var stu = Student("2017051313",4)
当父类的主构造函数不为空时
//我们可以在Student类的主构造函数中加上name和age这两个参数,
//再将这两个参数传给Person类的构造函数
class Student(val sno: String, val grade: Int, name: String, age: Int) :
Person(name, age) {
...
}
次构造函数
当一个类既有主构造函数又有次构造函数时,所有的次构造函数都必须调用主构造函数(包括间接调用)。
class Student(val sno: String, val grade: Int, name: String, age: Int) :
Person(name, age) {
constructor(name: String, age: Int) : this("", 0, name, age) {
}
constructor() : this("", 0) {
}
}
//此时有3种方式实例化
val student1 = Student()
val student2 = Student("Jack", 19)
val student3 = Student("a123", 5, "Jack", 19)
03 接口
子类继承父类、实现接口
//父类
open class Person(val name:String, val age:Int) {
}
//接口
interface Study {
fun readBooks()
fun doHomework()
}
//子类继承父类、实现接口,都用":",实用","隔开
class Student(name:String,age: Int):Person(name,age),Study{
override fun readBooks(){
println(name + " is readBooks")
}
override fun doHomework() {
println(name + " is doHomework")
}
}
实例化
fun main() {
//1
var stu = Student("lee",18)
stu.doHomework()
stu.readBooks()
//2
doStudy(stu)
}
fun doStudy(study: Study) {
study.readBooks()
study.doHomework()
}
结果:

Kotlin还增加了一个额外的功能:允许对接口中定义的函数进行默认实现(在实现类中,可以不实现该函数了)。
函数的可见性修饰符
| 修饰符 | Java | Kotlin |
|---|---|---|
| public | 所有类可见 | 所有类可见(默认) |
| private | 当前类可见 | 当前类可见 |
| protected | 当前类、子类、同一包路径下的类可见 | 当前类、子类可见 |
| default | 同一包路径下的类可见(默认) | 无 |
| internal | 无 | 同一模块中的类可见 |
04 数据类与单例类
数据类通常需要重写equals()、hashCode()、toString()这几个方法。
其中,
- equals()方法用于判断两个数据类是否相等。
- hashCode()方法作为equals()的配套方法,也需要一起重写,否则会导致HashMap、HashSet等hash相关的系统类无法正常工作。
- toString()方法用于提供更清晰的输入日志,否则一个数据类默认打印出来的就是一行内存地址。
根据实际需求编写equal和hashcode函数的内容.
java中需要重写方法,kotlin中只需要"data"关键字
数据类Cellphone
data class Cellphone(val brand: String, val price: Double)
调用
fun main() {
var cellphone = Cellphone("OPPO",3000.0)
println(cellphone)
}

单例类
只需要将class改成object即可
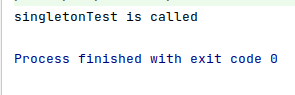
object Singleton {
fun singletonTest(){
println("singletonTest is called")
}
}
调用
Singleton.singletonTest()
5 Lambda编程
传统意义上的集合主要就是List和Set,再广泛一点的话,像Map这样的键值对数据结构也可以包含进来。
List、Set和Map在Java中都是接口.
- List的主要实现类是ArrayList和LinkedList
- Set的主要实现类是HashSet
- Map的主要实现类是HashMap
01 集合的创建与遍历
对于list,有两种生成方法,其中listOf生成的list集合,内容不可变
fun main() {
val list = listOf<String>("apple","banana","orange") //集合内容不可变
val mutableList = mutableListOf<String>("apple","banana","orange") //集合内容可以变
mutableList.add("grape")
for (fruit in mutableList){
println(fruit)
}
}
对于set,有两种生成方法,跟list类似,只是改成setOf和mutableSetOf.并且set不能放重复元素,放,也只会保存一个
Kotlin中并不建议使用put()和get()方法来对Map进行添加和读取数据操作,而是更加推荐使用一种类似于数组下标的语法结构
val map = HashMap<String, Int>()
map["Apple"] = 1
map["Banana"] = 2
map["Orange"] = 3
map["Pear"] = 4
map["Grape"] = 5
//更加简便的方法
val map = mapOf("Apple" to 1, "Banana" to 2, "Orange" to 3, "Pear" to 4, "Grape" to 5)
//遍历map
for ((fruit, number) in map) {
println("fruit is " + fruit + ", number is " + number)
}
02 集合的函数式API
总结:
在大括号内填写条件.
//获得字符串长度最长的那个词
val list = listOf<String>("Apple", "Banana", "Orange", "Pear", "Grape", "Watermelon")
val maxLengthFruit = list.maxByOrNull { it.length }
println("max length fruit is " + maxLengthFruit)
Lambda表达式的语法结构:
{参数名1: 参数类型, 参数名2: 参数类型 -> 函数体}
首先最外层是一对大括号,
如果有参数传入到Lambda表达式中的话,我们还需要声明参数列表,
参数列表的结尾使用一个->符号,表示参数列表的结束以及函数体的开始, 函数体中可以编写任意行代码(虽然不建议编写太长的代码),并且最后一行代码会自动作为Lambda表达式的返回值。
maxBy就是一个普通的函数而已,只不过它接收的是一个Lambda类型的参数,并且会在遍历集合时将每次遍历的值作为参数传递给Lambda表达式。
maxBy函数的工作原理是根据我们传入的条件来遍历集合,从而找到该条件下的最大值
val list = listOf("Apple", "Banana", "Orange", "Pear", "Grape", "Watermelon")
val lambda = { fruit: String -> fruit.length }
val maxLengthFruit = list.maxByOrNull(lambda)
简化
val maxLengthFruit = list.maxByOrNull({ fruit: String -> fruit.length })
1 .Kotlin规定,当Lambda参数是函数的最后一个参数时,可以将Lambda表达式移到函数括号的外面
val maxLengthFruit = list.maxByOrNull(){ fruit: String -> fruit.length }
2. 如果Lambda参数是函数的唯一一个参数的话,还可以将函数的括号省略:
val maxLengthFruit = list.maxByOrNull{ fruit: String -> fruit.length }
3. Lambda表达式中的参数列表其实在大多数情况下不必声明参数类型
val maxLengthFruit = list.maxByOrNull{ fruit -> fruit.length }
4. 当Lambda表达式的参数列表中只有一个参数时,也不必声明参数名,而是可以使用it关键字来代替
val maxLengthFruit = list.maxByOrNull { it.length }
集合中的map函数是最常用的一种函数式API,它用于将集合中的每个元素都映射成一个另外的值,映射的规则在Lambda表达式中指定,最终生成一个新的集合。
filter函数是用来过滤集合中的数据的,它可以单独使用,也可以配合刚才的map函数一起使用。
val list = listOf<String>("Apple", "Banana", "Orange", "Pear", "Grape", "Watermelon")
val newList = list.filter { it.length <= 5 }.map { it.toUpperCase() }
for (fruit in newList){
println(fruit)
}

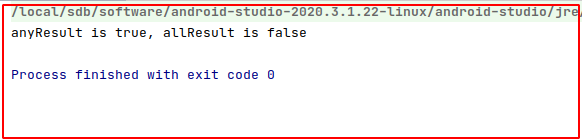
any函数用于判断集合中是否至少存在一个元素满足指定条件,all函数用于判断集合中是否所有元素都满足指定条件。
val list = listOf<String>("Apple", "Banana", "Orange", "Pear", "Grape", "Watermelon")
val anyResult = list.any { it.length <= 5 }
val allResult = list.all { it.length <= 5 }
println("anyResult is " + anyResult + ", allResult is " + allResult)
03 Java函数式API的使用
总结:
对作为参数的 单抽象方法接口(参数) 进行简化
Kotlin代码中调用了一个Java方法,并且该方法接收一个Java单抽象方法接口参数,就可以使用函数式API。
格式:
//其中new Thread是构造方法,是java方法; Runnable是单抽象方法接口,并作为构造方法的参数
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Thread is running");
}
}).start();
简化:
- kotlin写法
Thread(object :Runnable{
override fun run() {
println("run")
}
}).start()
- 因为Runnable类中只有一个待实现方法,即使这里没有显式地重写run()方法,Kotlin也能自动明白Runnable后面的Lambda表达式就是要在run()方法中实现的内容。
Thread(Runnable {
println("run")
}).start()
- 继续省略,kotlin知道参数是Runnable,省略Runnable.移动括号,省略括号.
Thread{
println("run")
}.start()
实例:
btn.setOnClickListener{
println("click")
}
6 空指针检查
Android系统上崩溃率最高的异常类型就是空指针异常(NullPointerException)。
fun doStudy(study: Study) {
study.readBooks()
study.doHomework()
}
在kotlin中,如果调用方法传入null值,会报错

01 可空类型系统
只需在类后面添加"?",并进行判空即可
fun doStudy(study: Study?) {
if (study != null) {
study.readBooks()
study.doHomework()
}
}
02 判空辅助工具
"?."操作符.
当对象不为空时正常调用相应的方法,
当对象为空时则什么都不做。
//优化
fun doStudy(study: Study?) {
study?.readBooks()
study?.doHomework()
}
"?:"操作符
操作符的左右两边都接收一个表达式
如果左边表达式的结果不为空就返回左边表达式的结果,否则就返回右边表达式的结果。
val c = if (a ! = null) {
a
} else {
b
}
简化:
val c = a ?: b
非空断言(确信不会为空,自己负责后果)

非空断言
fun printUpperCase() {
val upperCase = content!!.toUpperCase()
println(upperCase)
}
let函数
这个函数提供了函数式API的编程接口,并将原始调用对象作为参数传递到Lambda表达式中。
obj.let { obj2 ->
// 编写具体的业务逻辑
}
具体实例:
fun doStudy(study: Study?) {
study?.readBooks()
study?.doHomework()
}
//用了let
fun doStudy(study: Study?) {
study?.let { stu ->
stu.readBooks()
stu.doHomework()
}
}
let函数是可以处理全局变量的判空问题的,而if判断语句则无法做到这一点。

全局变量,其他线程可能对study变量进行修改,导致空指针风险
7 Kotlin中的小魔术
01 字符串内嵌表达式
格式:
" hello, ${object.name}" //当大括号内表达式只有一个变量时,可以将大括号省略.
实例:
open class Person(val name:String, val age:Int) {
override fun toString(): String {
return "Person(name='$name', age=$age)"
}
}

02 默认值
//默认参数str = "hello".调用该方法,不传第二个参数时的默认值
fun printParams(num: Int, str: String = "hello") {
println("num is $num , str is $str")
}
fun main() {
printParams(123)
}
若默认值在前边,则使用键值对传值
fun printParams(num: Int = 100, str: String) {
println("num is $num , str is $str")
}
fun main() {
printParams(str = "world")
}
默认值代替次构造函数
class Student(val sno: String, val grade: Int, name: String, age: Int) :
Person(name, age) {
constructor(name: String, age: Int) : this("", 0, name, age) {
}
constructor() : this("", 0) {
}
}
//代替
class Student(val sno: String = "", val grade: Int = 0, name: String = "", age: Int = 0) :
Person(name, age) {
}
8 标准函数和静态方法
01 标准函数with、run和apply
Kotlin的标准函数指的是Standard.kt文件中定义的函数,任何Kotlin代码都可以自由地调用所有的标准函数。
with
with函数接收两个参数:第一个参数可以是一个任意类型的对象,第二个参数是一个Lambda表达式。
val result = with(obj) {
// 这里是obj的上下文
"value" // with函数的返回值
}
val list = listOf<String>("a","b")
val builder = StringBuilder()
for (l in list){
builder.append(l).append("\n")
}
val result = builder.toString()
println(result)
with函数进行简写
val list = listOf<String>("a","b")
val result = with(StringBuilder()){
for (l in list ){
append(l).append("\n")
}
toString()
}
println(result)
解读
首先我们给with函数的第一个参数传入了一个StringBuilder对象,那么接下来整个Lambda表达式的上下文就会是这个StringBuilder对象。Lambda表达式的最后一行代码会作为with函数的返回值返回.
run
使用run,相对于将stringbuilder作为with函数的参数,此处调用自身的run方法,其他没有区别.
val result = StringBuilder().run{
for (l in list ){
append(l).append("\n")
}
toString()
}
println(result)
apply
apply和run相似,不同的是,apply函数不能制定返回的参数.只能返回自身.下列函数返回的是StringBuilder对象.
val list = listOf<String>("a","b")
val result = StringBuilder().apply {
for (l in list ){
append(l).append("\n")
}
}
println(result.toString())
02 定义静态方法
静态方法在某些编程语言里面又叫作类方法,指的就是那种不需要创建实例就能调用的方法
单例类可以直接使用类方法.(仿静态方法)
object Util {
fun doAction() {
println("do action")
}
}
Util.doAction()
让类中的某个方法变成静态方法(仿静态)
class Util {
fun doAction1() {
println("do action1")
}
companion object {
fun doAction2() {
println("do action2")
}
}
}
原理(类似单例类)
companion object这个关键字实际上会在Util类的内部创建一个伴生类.Kotlin会保证Util类始终只会存在一个伴生类对象.因此调用Util.doAction2()方法实际上就是调用了Util类中伴生对象的doAction2()方法
真正的静态类
class Util {
fun doAction1() {
println("do action1")
}
companion object {
@JvmStatic
fun doAction2() {
println("do action2")
}
}
}
添加@JvmStatic,@JvmStatic注解只能加在单例类或companion object中的方法上
由于doAction2()方法已经成为了真正的静态方法,那么现在不管是在Kotlin中还是在Java中,都可以使用Util.doAction2()的写法来调用了。
但是不加注解的话,java代码中就不能识别
顶层方法
顶层方法,顶层方法指的是那些没有定义在任何类中的方法,比如我们在上一节中编写的main()方法。Kotlin编译器会将所有的顶层方法全部编译成静态方法,因此只要你定义了一个顶层方法,那么它就一定是静态方法。
定义顶层方法
- 创建一个kotlin文件(file 不是class)
fun doSomething(){
println("doSomething")
}
- 其他kotlin文件调用调用
doSomething()
- java文件中调用(需要带上类名)
HelperKt.doSomething();
9 延迟初始化和密封类
01 对变量延迟初始化
当程序中有全局变量时,往往需要对变量进行判空处理。但是我们可以知道这个全局变量在其他地方已经赋值过了。这时,我们可以使用lateinit关键字,表明我们晚些时候会对变量进行初始化。
private lateinit var adapter: Adapter
判断全局变量是否为空
if (!::adapter.isInitialized) {
adapter = Adapter(...)
}
02 使用密封类优化代码
创建一个kotlin文件,写入如下代码
interface Result
class Success(val msg: String) : Result
class Failure(val error: Exception) : Result
fun getResultMsg(result: Result) = when (result) {
is Success -> result.msg
is Failure -> result.error.message
else -> throw IllegalArgumentException()
}
在getResultMsg中,对Result进行类型判断,然后输出相应结果。但是我们很可能会遇到,类型少写了(因为新增了继承Result的类).
使用密封类(sealed class)
sealed class Result
class Success(val msg: String) : Result()
class Failure(val error: Exception) : Result()
fun getResultMsg(result: Result) = when (result) {
is Success -> result.msg
is Failure -> result.error.message
}
密封类可以很好避免这种情况出现。因为当在when语句中传入一个密封类变量作为条件时,Kotlin编译器会自动检查该密封类有哪些子类,并强制要求你将每一个子类所对应的条件全部处理。

10 扩展函数和运算符重载
01 扩展函数
扩展函数表示即使在不修改某个类的源码的情况下,仍然可以打开这个类,向该类添加新的函数。
模板
fun ClassName.methodName(param1: Int, param2: Int): Int {
return 0
}
例子:(向String类添加函数)(顶级方法)
fun String.letterCount():Int{
var count :Int = 0
for (c in this){
if (c.isLetter()){
count++
}
}
return count
}
调用
println("af23s".letterCount())
02 运算符重载(可多次重载)
Java中有许多语言内置的运算符关键字,如+ - * / % ++ --。而Kotlin允许我们将所有的运算符甚至其他的关键字进行重载,从而拓展这些运算符和关键字的用法。
运算符对应的函数
| 语法糖表达式 | 实际调用函数 |
|---|---|
| a + b | a.plus(b) |
| a - b | a.minus(b) |
| a * b | a.times(b) |
| a / b | a.div(b) |
| a % b | a.rem(b) |
| a++ | a.inc() |
| a– | a.dec() |
| +a | a.unaryPlus() |
| -a | a.unaryMinus() |
| !a | a.not() |
| a == b | a.equals(b) |
| a > b | |
| a < b | |
| a >= b | |
| a <= b | a.compareTo(b) |
| a…b | a.rangeTo(b) |
| a[b] | a.get(b) |
| a[b] = c | a.set(b, c) |
| a in b | b.contains(a) |
语法结构:
class Obj {
operator fun plus(obj: Obj): Obj {
// 处理相加的逻辑
}
}
val obj1 = Obj()
val obj2 = Obj()
val obj3 = obj1 + obj2
原理:
这种obj1 + obj2的语法看上去好像很神奇,但其实这就是Kotlin给我们提供的一种语法糖,它会在编译的时候被转换成obj1.plus(obj2)的调用方式。
例子:
class Money(val value:Int){
operator fun plus(money: Money):Money{
return Money(value + money.value)
}
}
fun main(){
val m1 = Money(1)
val m2 = Money(2)
val m3 = m1 + m2
print(m3.value)
}
11 高阶函数详解
01 定义高阶函数
如果一个函数接收另一个函数作为参数,或者返回值的类型是另一个函数,那么该函数就称为高阶函数。
函数类型的语法规则是有点特殊的,基本规则如下:
(String, Int) -> Unit
- ->左边的部分就是用来声明该函数接收什么参数的,多个参数之间使用逗号隔开,如果不接收任何参数,写一对空括号就可以了。
- ->右边的部分用于声明该函数的返回值是什么类型,如果没有返回值就使用Unit,它大致相当于Java中的void。
实例:
fun num1andnum2(num1:Int,num2:Int,operation:(Int,Int) -> Int):Int{
val result = operation(num1,num2)
return result
}
fun plus(num1: Int,num2: Int):Int{
return num1 + num2
}
fun minus(num1: Int,num2: Int):Int{
return num1 - num2
}
fun main(){
val num1 = 1
val num2 = 1
var result = num1andnum2(num1,num2, ::plus)
println(result)
}

Kotlin还支持其他多种方式来调用高阶函数,比如Lambda表达式、匿名函数、成员引用等。其中,Lambda表达式是最常见也是最普遍的高阶函数调用方式。
高阶函数不允许lambda表达式中使用return
lambda表达式调用高阶函数
val result = num1andnum2(num1, num2) { n1, n2 ->
n1 + n2
}
println(result)
原理:lambda表达式转换成Function接口的匿名类实现
public static int num1AndNum2(int num1, int num2, Function operation) {
int result = (int) operation.invoke(num1, num2);
return result;
}
public static void main() {
int num1 = 100;
int num2 = 80;
int result = num1AndNum2(num1, num2, new Function() {
@Override
public Integer invoke(Integer n1, Integer n2) {
return n1 + n2;
}
});
}
在这里num1AndNum2()函数的第三个参数变成了一个Function接口,这是一种Kotlin内置的接口,里面有一个待实现的invoke()函数。而num1AndNum2()函数其实就是调用了Function接口的invoke()函数,并把num1和num2参数传了进去。在调用num1AndNum2()函数的时候,之前的Lambda表达式在这里变成了Function接口的匿名类实现,然后在invoke()函数中实现了n1 + n2的逻辑,并将结果返回。
简单理解:参数给了lambda表达式,组成之后,在到高阶函数内继续运行。
手动实现String的apply
fun StringBuilder.build(block: StringBuilder.() -> Unit): StringBuilder {
block()
return this
}
02 内联函数
lambda表达式调用高阶函数会产生匿名类实例,增加开销。为了减少开销,可以使用内联函数。
定义高阶函数时加上inline关键字的声明即可
原理
- 首先,Kotlin编译器会将Lambda表达式中的代码替换到函数类型参数调用的地方

- 接下来,再将内联函数中的全部代码替换到函数调用的地方

- 最终:

noinline与crossinline
为什么Kotlin还要提供一个noinline关键字来排除内联功能呢?
-
这是因为内联的函数类型参数在编译的时候会被进行代码替换,因此它没有真正的参数属性。
-
非内联的函数类型参数可以自由地传递给其他任何函数,因为它就是一个真实的参数,
-
而内联的函数类型参数只允许传递给另外一个内联函数,这也是它最大的局限性。
内联函数和非内联函数还有一个重要的区别
那就是内联函数所引用的Lambda表达式中是可以使用return关键字来进行函数返回的,而非内联函数只能进行局部返回。
使用内联函数可能出现的错误

在runRunnable()函数中,我们创建了一个Runnable对象,并在Runnable的Lambda表达式中调用了传入的函数类型参数。而Lambda表达式在编译的时候会被转换成匿名类的实现方式,也就是说,上述代码实际上是在匿名类中调用了传入的函数类型参数。
内联函数所引用的Lambda表达式允许使用return关键字进行函数返回,但是由于我们是在匿名类中调用的函数类型参数,此时是不可能进行外层调用函数返回的,最多只能对匿名类中的函数调用进行返回,因此这里就提示了上述错误。
解决办法:
添加crossinline,保证block()中不会有return

12 高阶函数的应用
01 简化SharedPreferences的用法
向SharedPreferences中存储数据的过程大致可以分为以下3步:
(1) 调用SharedPreferences的edit()方法获取SharedPreferences.Editor对象;
(2) 向SharedPreferences.Editor对象中添加数据;
(3) 调用apply()方法将添加的数据提交,完成数据存储操作。
val editor = getSharedPreferences("data", Context.MODE_PRIVATE).edit()
editor.putString("name", "Tom")
editor.putInt("age", 28)
editor.putBoolean("married", false)
editor.apply()
简化
fun SharedPreferences.open(block: SharedPreferences.Editor.() -> Unit) {
val editor = edit()
editor.block()
editor.apply()
}
首先,我们通过扩展函数的方式向SharedPreferences类中添加了一个open函数,并且它还
接收一个函数类型的参数,因此open函数自然就是一个高阶函数了。
简化后使用
getSharedPreferences("data", Context.MODE_PRIVATE).open {
putString("name", "Tom")
putInt("age", 28)
putBoolean("married", false)
}
Lambda表达式拥有的是SharedPreferences.Editor的上下文环境,因此这里可以直接调用相应的put方法来添加数据。最后我们也不再需要调用apply()方法来提交数据了,因为open函数会自动完成提交操作。
02 简化ContentValues的用法
13 泛型和委托
01 泛型的基本用法
在一般的编程模式下,我们需要给任何一个变量指定一个具体的类型,而泛型允许我们在不指定具体类型的情况下进行编程,这样编写出来的代码将会拥有更好的扩展性。
定义泛型类
class MyClass<T> {
fun method(param: T): T {
return param
}
}
val myclass = MyClass<Int>()
var num:Int = myclass.method(123)
定义泛型方法
class MyClass {
fun <T> method(param: T): T {
return param
}
}
val myclass = MyClass()
var num:Int = myclass.method<Int>(123)
使用泛型实现apply函数
fun<T> T.build(block:T.() -> Unit ):T{
block()
return this
}
02 类委托和委托属性
类委托
委托是一种设计模式,它的基本理念是:操作对象自己不会去处理某段逻辑,而是会把工作委托给另外一个辅助对象去处理。委托功能分为了两种:类委托和委托属性
类委托,它的核心思想在于将一个类的具体实现委托给另一个类去完成。
委托模式例子
class MySet<T>(val helperSet: HashSet<T>) : Set<T> {
override val size: Int
get() = helperSet.size
override fun contains(element: T) = helperSet.contains(element)
override fun containsAll(elements: Collection<T>) = helperSet.containsAll(elements)
override fun isEmpty() = helperSet.isEmpty()
override fun iterator() = helperSet.iterator()
}
MySet的构造函数中接收了一个HashSet参数,这就相当于一个辅助对象。然后在Set接口所有的方法实现中,我们都没有进行自己的实现,而是调用了辅助对象中相应的方法实现,这其实就是一种委托模式。
写法的好处
我们只是让大部分的方法实现调用辅助对象中的方法,少部分的方法实现由自己来重写,甚至加入一些自己独有的方法,那么MySet就会成为一个全新的数据结构类,这就是委托模式的意义所在。
类委托例子
接口中的待实现方法在kotlin中可以通过类委托实现。使用by字段,之后我们只需写入自己想重写的方法即可
class MySet<T>(val helperSet: HashSet<T>) : Set<T> by helperSet {
fun helloWorld() = println("Hello World")
override fun isEmpty() = false
}
委托属性
类委托的核心思想是将一个类的具体实现委托给另一个类去完成,而委托属性的核心思想是将一个属性(字段)的具体实现委托给另一个类去完成。
class Delegate {
var propValue: Any? = null
operator fun getValue(myClass: MyClass, prop: KProperty<*>): Any? {
return propValue
}
operator fun setValue(myClass: MyClass, prop: KProperty<*>, value: Any?) {
propValue = value
}
}
class MyClass{
var p by Delegate()
}
这里使用by关键字连接了左边的p属性和右边的Delegate实例。这种写法就代表着将p属性的具体实现委托给了Delegate类去完成。当调用p属性的时候会自动调用Delegate类的getValue()方法,当给p属性赋值的时候会自动调用Delegate类的setValue()方法。
getValue()方法要接收两个参数:
-
第一个参数用于声明该Delegate类的委托功能可以在什么类中使用,这里写成MyClass表示仅可在MyClass类中使用;
-
第二个参数KProperty< * >是Kotlin中的一个属性操作类,可用于获取各种属性相关的值,在当前场景下用不着,但是必须在方法参数上进行声明。
-
另外,<*>这种泛型的写法表示你不知道或者不关心泛型的具体类型,只是为了通过语法编译而已,有点类似于Java中的写法。至于返回值可以声明成任何类型,根据具体的实现逻辑去写就行了,上述代码只是一种示例写法。
03 实现一个自己的lazy函数
懒加载:使用时才为变量赋值
lazy函数原理:
lazy函数本身是一个高阶函数,它先将lambda表达式的内容交给了Delagate的setValue,最后返回一个Delegate对象。而Delagate对象,只有在使用变量时才会使用setValue为变量赋值.
下面是自定义的懒加载函数
使用
val uriMatcher by later {
val matcher = UriMatcher(UriMatcher.NO_MATCH)
matcher.addURI(authority, "book", bookDir)
matcher.addURI(authority, "book/#", bookItem)
matcher.addURI(authority, "category", categoryDir)
matcher.addURI(authority, "category/#", categoryItem)
matcher
}
将()->T类型的lambda表达式传入高阶函数later中。
Delagate类
class Lazy<T> (val block:()->T){
var value: Any? = null
operator fun getValue(any: Any?, prop: KProperty<*>): T {
if (value == null) {
value = block()
}
return value as T
}
}
运行lambda表达式,将运行结果交由getValue。
高阶函数
fun <T>later( block: () -> T) = Lazy(block)
将lambda表达式交给委托类。
14 使用infix函数构建更可读的语法
01 定义
val map = mapOf("Apple" to 1, "Banana" to 2, "Orange" to 3, "Pear" to 4, "Grape" to 5)
to并不是Kotlin语言中的一个关键字,之所以我们能够使用A to B这样的语法结构,是因为Kotlin提供了一种高级语法糖特性:infix函数。
infix函数也并不是什么难理解的事物,它只是把编程语言函数调用的语法规则调整了一下而已
比如A to B这样的写法,实际上等价于A.to(B)的写法
通过一个具体的例子来学习一下infix函数的用法。(在函数前添加infix关键字)
实例:
infix fun String.isEqual(prefix:String):Boolean{
if(this.equals(prefix)){
return true
}
return false
}
fun main(){
val s = "test"
println(s isEqual "test")
}

infix函数允许我们将函数调用时的小数点、括号等计算机相关的语法去掉,从而使用一种更接近英语的语法来编写程序,让代码看起来更加具有可读性。
02 严格的限制
- infix函数是不能定义成顶层函数的,它必须是某个类的成员函数,可以使用扩展函数的方式将它定义到某个类当中;
- 其次,infix函数必须接收且只能接收一个参数,至于参数类型是没有限制的。只有同时满足这两点,infix函数的语法糖才具备使用的条件,你可以思考一下是不是这个道理。
03 模仿To生成键值对
infix fun<A,B> A.with(that:B) :Pair<A,B> = Pair(this,that)
15 泛型的高级特性
01 对泛型进行实化
类型擦除机制
Java的泛型功能是通过类型擦除机制来实现的。
就是说泛型对于类型的约束只在编译时期存在,运行的时候仍然会按照JDK 1.5之前的机制来运行,JVM是识别不出来我们在代码中指定的泛型类型的。
假设我们创建了一个List集合,虽然在编译时期只能向集合中添加字符串类型的元素,但是在运行时期JVM并不能知道它本来只打算包含哪种类型的元素,只能识别出来它是个List。
内联函数
内联函数中的代码会在编译的时候自动被替换到调用它的地方,这样的话也就不存在什么泛型擦除的问题了,因为代码在编译之后会直接使用实际的类型来替代内联函数中的泛型声明,其工作原理如下图所示。
完成替换

Kotlin中是可以将内联函数中的泛型进行实化的。
泛型实化
首先,该函数必须是内联函数才行,也就是要用inline关键字来修饰该函数。其次,在声明泛型的地方必须加上reified关键字来表示该泛型要进行实化。
示例代码
inline fun <reified T> getGenericType() {
}
inline fun <reified T> getGenericType() = T::class.java
fun main(){
val result1 = getGenericType<String>()
val result2 = getGenericType<Int>()
println("$result1\n$result2")
}
02 泛型实化的应用(对startActivity进行简化)
class MainActivity5 : AppCompatActivity() {
inline fun<reified T> startActivity(context: Context, block : Intent.()->Unit){
val intent = Intent(context,T::class.java)
intent.block()
context.startActivity(intent)
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main5)
startActivity<Activity>(this){
putExtra("test","test")
}
}
}
//相当于
// val intent = Intent(this, MainActivity5::class.java)
// intent.putExtra("test","test")
// this.startActivity(intent)
03 泛型协变(只能out)
约定
先了解一个约定。一个泛型类或者泛型接口中的方法,它的参数列表是接收数据的地方,因此可以称它为in位置,而它的返回值是输出数据的地方,因此可以称它为out位置,如下图所示。

定义
定义了一个MyClass< T >的泛型类,其中A是B的子类型,同时MyClass< A >又是MyClass< B >的子类型,那么我就可以称MyClass在T这个泛型上是协变的。
协变声明:一个泛型类在其泛型类型的数据上是只读的话,那么它是没有类型转换安全隐患的。而要实现这一点,则需要让MyClass< T >类中的所有方法都不能接收T类型的参数。换句话说,T只能出现在out位置上,而不能出现在in位置上。
override fun contains(element: @UnsafeVariance T): Boolean
在泛型E的前面又加上了一个@UnsafeVariance注解,这样编译器就会允许泛型E出现在in位置上了。但是如果你滥用这个功能,导致运行时出现了类型转换异常,Kotlin对此是不负责的。
例子
open class Person(val name: String, val age: Int)
class Student(name: String, age: Int) : Person(name, age)
class Teacher(name: String, age: Int) : Person(name, age)
//可协变声明
class SimpleData<out T>(val data: T?) {
fun get(): T? {
return data
}
}
fun main() {
val student = Student("Tom", 19)
val simpleStudent = SimpleData<Student>(student)
handleMyData(simpleStudent) //SimpleData是SimpleData的子类
val studentData = simpleStudent.get()
}
fun handleMyData(simplePerson: SimpleData<Person>) {
val personData = simplePerson.get()
//simplePerson.get返回person类
}
没协变声明会造成的类型转换异常
open class Person(val name: String, val age: Int)
class Student(name: String, age: Int) : Person(name, age)
class Teacher(name: String, age: Int) : Person(name, age)
class SimpleData<T> {
private var data: T? = null
fun set(t: T?) {
data = t
}
fun get(): T? {
return data
}
}
fun main() {
val student = Student("Tom", 19)
val simpleStudent = SimpleData<Student>()
simpleStudent.set(student)
handleSimpleData(simpleStudent) // 实际上这行代码会报错,这里假设它能编译通过
val studentData = simpleStudent.get()
//通过之后,使用get方法,simpleStudent的get获得student对象
//但在handleSimpleData中数据被替换成teacher,
//student类和teacher类存在类型转换异常。
}
fun handleSimpleData(simplePerson: SimpleData<Person>) {//将teacher放入simplePerson中
val teacher = Teacher("Jack", 35)
simplePerson.set(teacher)
}
list类就使用了协变
04 泛型逆变(只能in)
定义
定义了一个MyClass< T >的泛型类,其中A是B的子类型,同时MyClass< B >又是MyClass< A >的子类型,那么我们就可以称MyClass在T这个泛型上是逆变的。协变和逆变的区别如下图所示。

interface Transformer<in T> {
fun transform(t: T): String
}
在泛型T的声明前面加上了一个in关键字。这就意味着现在T只能出现在in位置上,而不能出现在out位置上,同时也意味着Transformer在泛型T上是逆变的。
未声明逆变出现的问题
open class Person(val name: String, val age: Int)
class Student(name: String, age: Int) : Person(name, age)
class Teacher(name: String, age: Int) : Person(name, age)
//将T装换成String 类型
interface Transformer<T> {
fun transform(t: T): String
}
fun main() {
//将Person类转成String
val personTrans = object : Transformer<Person> {
override fun transform(t: Person): String {
return "${t.name} ${t.age}"
}
}
handleTransformer(personTrans)
// 这行代码会报错
// 但personTrans的transform方法的参数是Person类,student与person没有转换异常
}
fun handleTransformer(trans: Transformer<Student>) {
val student = Student("Tom", 19)
val result = trans.transform(student)
}
泛型T出现在out位置上出现的问题
open class Person(val name: String, val age: Int)
class Student(name: String, age: Int) : Person(name, age)
class Teacher(name: String, age: Int) : Person(name, age)
//将name + age 转成 T 输出
interface Transformer<in T> {
fun transform(name: String, age: Int): @UnsafeVariance T
}
fun main() {
val teacherTrans = object : Transformer<Person> {
override fun transform(name: String, age: Int): Person {
return Teacher(name, age)
}
}
handleTransformer(teacherTrans)
//会出现异常,因为handleTransformer中studentTrans的transform方法out返回的是student类型。
// 但是传入的teacherTrans却返回teacher类型,因此出现异常
}
fun handleTransformer(studentTrans: Transformer<Student>) {
val result = studentTrans.transform("Tom", 19)
}
16 使用协程编程
其实和线程是有点类似的,可以简单地将它理解成一种轻量级的线程。
fun foo() {
a()
b()
c()
}
fun bar() {
x()
y()
z()
}
正常的线程中会按顺序调用foo()和bar(),但是假如foo()放到协程A中,bar()放到协程B中,虽然他们在同一线程中,但是执行foo()时随时都有可能被挂起来而去执行bar(),执行bar()时同理。这就有点像线程了。
01 协程的基本用法
需要先导入依赖
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.1.1"
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-android:1.1.1"
第二个依赖库是在Android项目中才会用到的,纯Kotlin程序,用不到第二个依赖库。
如何开启一个协程
最简单的方法是使用Global.launch函数
fun main(){
GlobalScope.launch {
println("codes run in coroutine scope")
}
}
GlobalScope.launch函数可以创建一个协程的作用域,这样传递给launch函数的代码块(Lambda表达式)就是在协程中运行的了,这里我们只是在代码块中打印了一行日志。
没有输出,Global.launch函数每次创建的都是一个顶层协程,这种协程当应用程序运行结束时也会跟着一起结束。刚才的日志之所以无法打印出来,就是因为代码块中的代码还没来得及运行,应用程序就结束了。
添加Thread.sleep(1000)即可

但是代码块中的代码在1秒钟之内不能运行结束,那么就会被强制中断
fun main(){
GlobalScope.launch {
println("codes run in coroutine scope")
delay(1500)
println("codes run in coroutine scope finished")
}
Thread.sleep(1000)
}
delay和sleep的区别
-
delay()函数是一个非阻塞式的挂起函数,它只会挂起当前协程,并不会影响其他协程的运行。
-
Thread.sleep()方法会阻塞当前的线程,这样运行在该线程下的所有协程都会被阻塞。
-
注意,delay()函数只能在协程的作用域或其他挂起函数中调用。
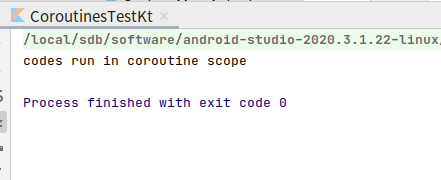
可以看到第二行代码没打印出来
runBlocking
fun main(){
runBlocking {
println("codes run in coroutine scope")
delay(1500)
println("codes run in coroutine scope finished")
}
}
runBlocking函数同样会创建一个协程的作用域,但是它可以保证在协程作用域内的所有代码和子协程没有全部执行完之前一直阻塞当前线程。需要注意的是,runBlocking函数通常只应该在测试环境下使用,在正式环境中使用容易产生一些性能上的问题。

可以看到runBlocking中协程阻塞线程,等到协程中代码运行完毕,线程才结束。
创建多个协程
fun main(){
runBlocking {
launch {
println("codes run in coroutine scope")
delay(1500)
println("codes run in coroutine scope finished")
}
launch {
println("codes2 run in coroutine scope")
delay(1500)
println("codes2 run in coroutine scope finished")
}
}
}
这里的launch函数和我们刚才所使用的GlobalScope.launch函数不同。它必须在协程的作用域中才能调用,其次它会在当前协程的作用域下创建子协程。子协程的特点是如果外层作用域的协程结束了,该作用域下的所有子协程也会一同结束。
GlobalScope.launch函数创建的永远是顶层协程,这一点和线程比较像,因为线程也没有层级这一说,永远都是顶层的。

可以看到日志交替打印。
多协程并发的运行效率很高
fun main(){
val start = System.currentTimeMillis()
runBlocking {
repeat(100000){
launch {
println(".")
}
}
}
val end = System.currentTimeMillis()
println("coastTime:")
println(end - start)
}
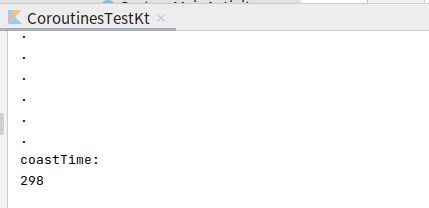
协程作用域
很多时候我们会将代码提取到一个单独的函数中,这时,在launch函数中编写的代码是拥有协程作用域的,但是提取到一个单独的函数中就没有协程作用域了,到时如何调用delay()这样的挂起函数
声明挂起函数,挂起函数之间可以互相调用,于是就可以调用delay()了
suspend fun printDot() {
println(".")
delay(1000)
}
suspend关键字只能将一个函数声明成挂起函数,是无法给它提供协程作用域的。比如lauch函数必须在协程作用域中使用
coroutineScope函数
coroutineScope函数也是一个挂起函数,因此可以在任何其他挂起函数中调用。它的特点是会继承外部的协程的作用域并创建一个子协程,借助这个特性,我们就可以给任意挂起函数提供协程作用域了。
suspend fun printDot() = coroutineScope {
launch {
println(".")
delay(1000)
}
}
coroutineScope函数和runBlocking函数还有点类似,它可以保证其作用域内的所有代码和子协程在全部执行完之前,外部的协程会一直被挂起。有点像runBlocking阻塞线程。coroutineScope是阻塞协程
fun main(){
val start = System.currentTimeMillis()
runBlocking {
coroutineScope {
launch {
for (i in 1..3) {
println(i)
delay(1000)
}
}
}
println("coroutineScope finished")
}
println("runBlocking finished")
}
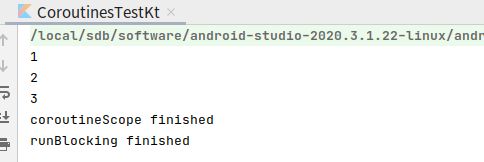
可以看到coroutineScope阻塞了runBlocking。等coroutineScope运行完之后,才运行runBlocking的其他代码。
runBlocking阻塞了线程。等runBlocking运行完之后,才运行线程中的其他内容。
但是coroutineScope函数只会阻塞当前协程,既不影响其他协程,也不影响任何线程,因此是不会造成任何性能上的问题的。而runBlocking函数由于会挂起外部线程,如果你恰好又在主线程中当中调用它的话,那么就有可能会导致界面卡死的情况,所以不太推荐在实际项目中使用。
02 更多的作用域构建器
GlobalScope.launch和runBlocking函数是可以在任意地方调用的,coroutineScope函数可以在协程作用域或挂起函数中调用,而launch函数只能在协程作用域中调用。runBlocking由于会阻塞线程,因此只建议在测试环境下使用。GlobalScope.launch由于每次创建的都是顶层协程,一般也不太建议使用,除非你非常明确就是要创建顶层协程。
取消顶层协程
顶层协程会在线程结束时结束。我们需要取消它。
val job = GlobalScope.launch {
// 处理具体的逻辑
}
job.cancel()
不管是GlobalScope.launch函数还是launch函数,它们都会返回一个Job对象,只需要调用Job对象的cancel()方法就可以取消协程。
大量取消,很麻烦。所以GlobalScope.launch不常用。
常用做法:
val job = Job()
val scope = CoroutineScope(job)
scope.launch {
//具体处理逻辑
}
job.cancel()
我们先创建了一个Job对象,然后把它传入CoroutineScope()函数当中,注意这里的CoroutineScope()是个函数,虽然它的命名更像是一个类。CoroutineScope()函数会返回一个CoroutineScope对象,这种语法结构的设计更像是我们创建了一个CoroutineScope的实例,可能也是Kotlin有意为之的。有了CoroutineScope对象之后,就可以随时调用它的launch函数来创建一个协程了。
现在所有调用CoroutineScope的launch函数所创建的协程,都会被关联在Job对象的作用域下面。这样只需要调用一次cancel()方法,就可以将同一作用域内的所有协程全部取消,从而大大降低了协程管理的成本。
async函数(获取执行结果)
async函数必须在协程作用域当中才能调用,它会创建一个新的子协程并返回一个Deferred对象,如果我们想要获取async函数代码块的执行结果,只需要调用Deferred对象的await()方法即可
fun main(){
runBlocking {
val start = System.currentTimeMillis()
val result1 = async {
delay(1000)
5 + 5
}.await()
val result2 = async {
delay(1000)
4 + 6
}.await()
println("result is ${result1 + result2}")
val end = System.currentTimeMillis()
println("cost ${end - start} ms.")
}
}
当调用await()方法时,如果代码块中的代码还没执行完,那么await()方法会将当前协程阻塞住,直到可以获得async函数的执行结果。coroutineScope函数也阻塞协程。

让async并行,晚点使用await()
fun main(){
runBlocking {
val start = System.currentTimeMillis()
val result1 = async {
delay(1000)
5 + 5
}
val result2 = async {
delay(1000)
4 + 6
}
println("result is ${result1.await() + result2.await()}")
val end = System.currentTimeMillis()
println("cost ${end - start} ms.")
}
}
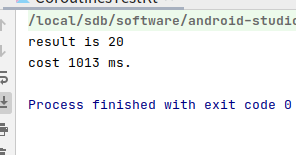
可以看到时间为1013少了很多。
withContext()函数(挂起函数)
比较特殊的作用域构建器,可以将它理解成async函数的一种简化版写法。
fun main() {
runBlocking {
val result = withContext(Dispatchers.Default) {
5 + 5
}
println(result)
}
}

调用withContext()函数之后,会立即执行代码块中的代码,同时将外部协程挂起。当代码块中的代码全部执行完之后,会将最后一行的执行结果作为withContext()函数的返回值返回,因此基本上相当于val result = async{ 5 + 5}.await()的写法。
withContext()函数强制要求我们指定一个线程参数。
我们还是需要使用子线程的。Android中要求网络请求必须在子线程中进行,即使你开启了协程去执行网络请求,假如它是主线程当中的协程,那么程序仍然会出错。这个时候我们就应该通过线程参数给协程指定一个具体的运行线程。
线程参数主要有以下3种值可选:Dispatchers.Default、Dispatchers.IO和Dispatchers.Main。
-
Dispatchers.Default表示会使用一种默认低并发的线程策略,当你要执行的代码属于计算密集型任务时,开启过高的并发反而可能会影响任务的运行效率,此时就可以使用Dispatchers.Default。
-
Dispatchers.IO表示会使用一种较高并发的线程策略,当你要执行的代码大多数时间是在阻塞和等待中,比如说执行网络请求时,为了能够支持更高的并发数量,此时就可以使用Dispatchers.IO。
-
Dispatchers.Main则表示不会开启子线程,而是在Android主线程中执行代码,但是这个值只能在Android项目中使用,纯Kotlin程序使用这种类型的线程参数会出现错误。
除了coroutineScope函数之外,其他所有的函数都是可以指定这样一个线程参数的,只不过withContext()函数是强制要求指定的,而其他函数则是可选的。
03 使用协程简化回调的写法
回调机制基本上是依靠匿名类来实现的,但是匿名类的写法通常比较烦琐,比如如下代码:
HttpUtil.sendHttpRequest(address, object : HttpCallbackListener {
override fun onFinish(response: String) {
// 得到服务器返回的具体内容
}
override fun onError(e: Exception) {
// 在这里对异常情况进行处理
}
})
只需要借助suspendCoroutine函数就能将传统回调机制的写法大幅简化。
suspendCoroutine
suspendCoroutine函数必须在协程作用域或挂起函数中才能调用,它接收一个Lambda表达式参数,主要作用是将当前协程立即挂起,然后在一个普通的线程中执行Lambda表达式中的代码。
Lambda表达式的参数列表上会传入一个Continuation参数,调用它的resume()方法或resumeWithException()可以让协程恢复执行。
优化
suspend fun request(address: String): String {
return suspendCoroutine { continuation ->
HttpUtil.sendHttpRequest(address, object : HttpCallbackListener {
override fun onFinish(response: String) {
continuation.resume(response)
}
override fun onError(e: Exception) {
continuation.resumeWithException(e)
}
})
}
}
request()函数是一个挂起函数,并且接收一个address参数。
request()函数的内部,我们调用了刚刚介绍的suspendCoroutine函数,这样当前协程就会被立刻挂起,而Lambda表达式中的代码则会在普通线程中执行。
接着我们在Lambda表达式中调用HttpUtil.sendHttpRequest()方法发起网络请求,并通过传统回调的方式监听请求结果。
如果请求成功就调用Continuation的resume()方法恢复被挂起的协程,并传入服务器响应的数据,该值会成为suspendCoroutine函数的返回值。
如果请求失败,就调用Continuation的resumeWithException()恢复被挂起的协程,并传入具体的异常原因
这里虽然仍然使用了传统回调的写法,但是之后不管我们要发起多少次网络请求,都不需要再重复进行回调实现,所以简化了回调。
比如请求百度:
suspend fun getBaiduResponse() {
try {
val response = request("https://www.baidu.com/")
// 对服务器响应的数据进行处理
} catch (e: Exception) {
// 对异常情况进行处理
}
}
17 编写好用的工具方法
01 求N个数的最大、最小值
fun max(vararg nums:Int):Int{
var maxNum = Int.MIN_VALUE
for (num in nums){
maxNum = kotlin.math.max(num,maxNum)
}
return maxNum
}
fun min(vararg nums:Int):Int{
var minNum = Int.MAX_VALUE
for (num in nums){
minNum = kotlin.math.min(minNum,num )
}
return minNum
}
fun main() {
val maxN = max(1,2,3,4,5)
var minN = min(1,2,3,4,5)
println(maxN)
print(minN)
}

泛型化
fun<T:Comparable<T>> max(vararg nums:T):T{
if (nums.size == 0) throw RuntimeException("Params can not be empty.")
var maxN = nums[0]
for(num in nums){
if (num > maxN){
maxN = num
}
}
return maxN
}
fun main() {
var maxN = max(1,2,3,4,5)
println(maxN)
}
02 简化Toast的用法
我们常用Toast弹出String或者Int。为了方便,可以为String和Int添加扩展函数。
fun main() {
"String".toast(this)
"String".toast(this,Toast.LENGTH_LONG)
}
fun String.toast(context: Context,duration:Int = Toast.LENGTH_SHORT){
Toast.makeText(context,this,duration).show()
}
fun Int.toast(context: Context,duration:Int = Toast.LENGTH_SHORT){
Toast.makeText(context,this,duration).show()
}
03 简化Snackbar
18 使用DSL构建专有的语法结构
DSL的全称是领域特定语言(Domain Specific Language)。通过它我们可以编写出一些看似脱离其原始语法结构的代码,从而构建出一种专有的语法结构。kotlin也是支持DSL的。
01 高阶函数模拟dependency实现
class Dependency{
val libraries = ArrayList<String>()
fun implementation(lib:String){
libraries.add(lib)
}
}
fun dependencies(block: Dependency.()->Unit):List<String>{
val dependency = Dependency()
dependency.block()
return dependency.libraries
}
//使用
dependencies {
implementation("com....")
implementation("com....")
}
02 Table对应的HTML代码
class Td{
var content = ""
fun html()= "\n\t\t{$content} "
}
class Tr{
private val children = ArrayList<Td>()
//block是定义在Td类中的一个方法。block 一般为return “String”
fun td(block: Td.()->String){
println("-- Tr td方法别调用")
val td = Td()
td.content = td.block()
children.add(td)
}
fun html():String{
val builder = StringBuilder()
builder.append("\n\t")
for (childTag in children){
builder.append(childTag.html())
}
builder.append("\n\t ")
return builder.toString()
}
}
class Table{
private val children = ArrayList<Tr>()
//block是定义在Tr中的一个方法。参数为td{ "String"}, 为Tr类的td方法。
fun tr(block: Tr.() -> Unit){
println("Table tr方法被调用")
val tr = Tr()
tr.block()
children.add(tr)
}
fun html():String{
val builder = StringBuilder()
builder.append("")
for (childTag in children){
builder.append(childTag.html())
}
builder.append("\n
")
return builder.toString()
}
}
fun table(block:Table.()->Unit):String{
//block定义在Table类中。参数是Table的tr方法。
val table = Table()
table.block()
return table.html()
}
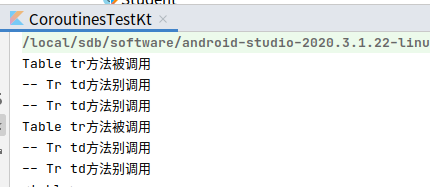
fun main(){
val html = table {
tr {
td { "didi" }
td { "didi" }
}
tr {
td { "waibiwaibi" }
td { "waibiwaibi" }
}
}
println(html)
}
lambda表达式其实是调用了对应的方法。
19 kotlin和java代码之间的转换
01 最简单的方法
在Android Stuido中新建kotlin文件,将java代码复制进去,会提醒是否转成kotlin代码。
但是自动转换只会按照固定的语法变化规律进行转换,不会使用kotlin的优秀特性。在细节方面需要自己进行手动优化。
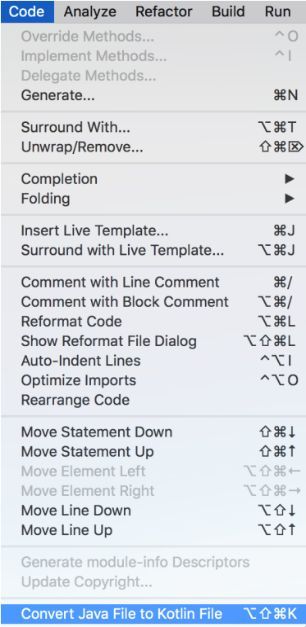
02 使用工具栏->code->Convert Java File to Kotlin File 直接转换
03 将kotlin代码转换成Kotlin字节码,在反编译成java代码
点击Android Studio导航栏中的Tools→Kotlin→Show Kotlin Bytecode。点击decompile即可反编译成java代码。
