C/C++ 编译链接过程详解
目录
一、预编译
二、编译
三、汇编
ELF文件
C语言中的强符号、弱符号
objdump
readelf
四、链接
五、运行
程序的编译链接过程要把我们编写的一个c/c++程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和用到的库文件进行组织,形成最终生成可执行代码的过程。
本文将以下面代码为例说明问题:main.c
#include
//以下为数据
int data1 = 10;
int data2 = 0;
int data3;
//以下为数据
static int data4 = 20;
static int data5 = 0;
static int data6;
int main()
{
//以下为指令(函数中普通的局部变量是属于指令)
int a = 30;
int b = 0;
int c;
//以下为数据
static int data7 = 40;
static int data8 = 0;
static int data9;
//以下为指令
return 0;
}
一、预编译
预编译主要处理规则:
1、删除#define,进行文本替换
2、处理条件预编译指令 例如:#if、 #endif 、#ifndef等
3、处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。(头文件展开是个递归展开的过程,被包含的文件可能还包含其他文件)
4、删除注释
5、添加行号和文件名标识
6、保留所有#pragma指令
在linux系统下执行gcc -E main.c -o main.i 生成.i文件

二、编译
过程:
1、词法分析
2、语法分析
3、语义分析 结合上下文
4、代码优化
5、生成汇编指令
在这个过程中,源代码会被放入到一个扫描器中,扫描器会利用一种叫有限状态机的算法将里面的代码划分成单个记号,这些记号一般就是关键字,标识符类等。然后会进行语法分析,语法分析的过程中,会将扫描器中的记号用树状结构连接起来。然后进行一些运算符的优先级判断,以及表达式的错误判断,然后进行语义分析,语义分析就是对树状结构的记号加上类型,从而让编译器去执行一些隐示类型转换,以及类型的错误判断。接下来编译器会将源代码优化成我们的汇编语言。
编译过程生成符号、生成汇编指令
执行gcc -S main.i -o main.s 生成.s文件
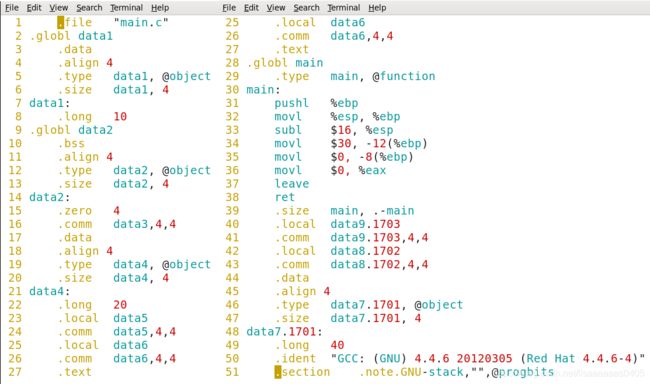
三、汇编
将汇编语言转换成我们的计算机可以执行的二进制可重定位文件 .o文件
执行gcc -c main.s -o main.o 生成.O文件
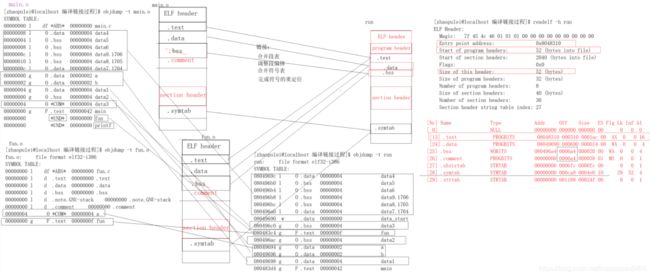
任何一个源文件在进行编译阶段的时候会去产生符号表,符号表中存放的就是程序所产生的符号(例如:函数名,变量名等),我们的编译阶段是不会去给符号分配正确的地址
因此当我们用 objdump -t main.o 命令查看.o文件时,

我们发现在这些符号都没有被分配地址,因此.o文件没有经过链接是无法执行的。
执行 file main.o
执行 ll main.o

根据上面两个显示的结果 我们可以知道main.o是32位系统下可重定位文件,文件大小为922字节
ELF文件
- 在计算机科学中,是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格式文件。
- ELF文件由4部分组成,分别是ELF头(ELF header)、程序头表(Program header table)、节(Section)和节头表(Section header table)。实际上,一个文件中不一定包含全部内容,而且他们的位置也未必固定,只有ELF头的位置是固定的,其余各部分的位置、大小等信息由ELF头中的各项值来决定。
下面我们来使用readelf和objdump来详细了解ELF文件的结构:
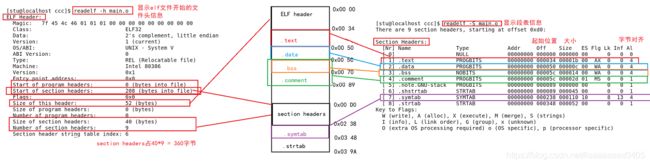
在执行ll main.o时,我们得知该文件占922个字节,即16进制 0x03 9A;上图.text段起始位置位0x00 34,大小为1b,所以.text终止位置为0x00 4F,但是由于按4字节对齐,故.text终止位置为0x00 50。
问题1:在上图中,bss段和comment段的起始位置相同,如果起始位置相同那么其中有一个应该不占内存,其实是.bss段不占内存,节省了文件的空间,那么bss段在文件中不占内存,其中数如何标识?
答:注意上图中的[7].symtab,这是数据生成的符号表,.bss 不占据实际的磁盘空间,只在段表中记录大小,从而节约了磁盘的空间。在符号表中记录符号。当文件加载运行时,才分配空间以及初始化。
所有的数据都会生成符号,符号存在于符号表,在符号表中看到该数据在bss段就不用找了,都为0。
- 在 elf 文件结构中,有一个字符串表.strtab,里面存放的是 elf 文件中各个段的名字以及变量名等字符串,字符串表中记录了这些字符串以及对应的下标,需要用到这些字符串时,直接用偏移下标去取就行了。段表中存放的段的名字这一项,就是存的.strtab 中对应字符串的偏移。
我们再来回顾下代码

.data段大小为00000C(即12字节),放入.data段的数据为三个占12字节,无误。
问题2:.bss段大小为000014(即20字节),但应该放入.bss段的数据有六个占24字节,少了一个数据,这是为什么呢???
要解决这个问题,我们先来了解一下强符号、弱符号。
C语言中的强符号、弱符号
符号:所有数据都会生成符号,指令只有函数名会生成符号。
强符号:初始化了的非静态数据
弱符号:没有初始化的非静态数据
针对强弱符号的处理:
- 两强报错
- 一弱一强 选强
- 两弱 看编译器处理
静态数据只在本文件中,不牵扯强弱符号。
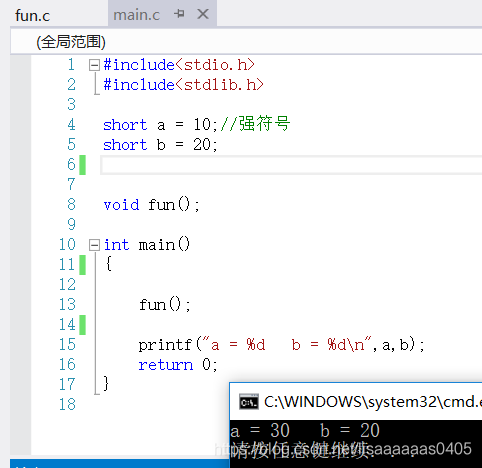
我们先来看一段代码 test.c
#include
short a = 10;//强符号
short b = 20;
void fun();
int main()
{
fun();
printf("a = %d b = %d\n",a,b);
return 0;
} fun.c
int a;//弱符号
void fun()
{
a = 30;
}在Linux系统下,运行结果如图:

为什么b的结果会是0呢?
因为在fun.c文件中,a属于弱符号,当将两个文件进行链接的时候,test.c中的short a(强符号)替换了fun.c中的a;因为fun函数中的a占四字节,test.c中的a占两字节,所以在赋值的时候,b的内存被覆盖了,故为0。
我们来通过查看fun.o的符号表来观察,发现a存放在*COM*,它是一个未初始化的变量,应该放到.bss段但是并没有,因为它是一个弱符号,这个 a 在编译过程中生成符号的时候并不占用.bss 空间,在链接过程中遇到强符号被test.c中的a所替换。

在vs2012下,运行结果如图:
vs2012带有内存保护机制,所以b的值依然为20。
现在我们回到之前的问题,为什么bss段少了一个数据?因为编译是针对单文件的,data3为弱符号,所以在*COM*,不在bss段,如果在链接过程中遇到强符号就会被替换。

-
objdump
objdump命令是Linux下的反汇编目标文件或者可执行文件的命令,它以一种可阅读的格式让你更多地了解二进制文件可能带有的附加信息。
参数:
-t 显示文件的符号表入口
-f 显示文件头信息
-
readelf
readelf命令用于查看ELF格式的文件信息,常见的文件如在Linux上的可执行文件,动态库(*.so)或者静态库(*.a) 等包含ELF格式的文件。
参数:
-h (elf header),显示elf文件开始的文件头信息。
-l (program headers),segments 显示程序头(段头)信息。
-S (section headers),sections 显示段表信息。
四、链接
过程:
1.合并段和符号表
2.符号解析 (在符号表发生,und符号引用的地方,需要符号解析来处理。没有找的的符号就会找到其定义的地方,如果还没有,就会发生链接错误。 )
3.分配地址和空间 (把程序和虚拟地址空间的映射建立好)
4.符号的重定位 给每个符号分配内存地址(虚拟空间上的地址)(编译过程中,数据的地址都是0,函数的入口地址都是一些不可访问的地址,也就是说编译过程中的地址都是无效的,这也就是为什么需要链接)
生成二进制可执行文件 (Windows下.exe文件,Linux下.out文件),在磁盘中存储。链接过程需要所有的.o文件和所有的库文件参与。
五、运行
./main
1.创建虚拟地址空间到物理内存的映射(创建内核地址映射结构体),创建页目录和页表
2.把磁盘中的代码段和数据段加载到内存中
3.将可执行文件的入口地址写到cpu的pc寄存器即可(入口地址写入下一行指令寄存器)

关于虚拟地址空间的知识可以参考这篇博客:虚拟地址空间
磁盘上文件映射到物理内存的过程:
DP磁盘数据通过(mmap函数) ——> VP 虚拟地址空间页面 (通过多级页表映射) ——> PP物理内存
为什么操作系统会经过虚拟地址空间来映射分配物理地址?
因为如果说我们链接之后不运行,长时间占用物理内存但是不使用,就会被分到swap交换分区磁盘里,也许一段时间后就会有其他进程占用了这块内存,但是,如果是经过虚拟内存来分配物理内存,直到运行时在分配,就会很方便,所以我们的操作系统可以实现多个进程协同运行。
六、总结

一个问题:
int a= 0;
int b =10;
int c = b/a;
只有在运行的时候才给他分配内存 ,运行的时候的错误
还可参考:程序的编译链接过程复习
编译链接过程