Kafka Consumer
目录
-
- 消费者分区分配策略
-
- range(默认)
- roundrobin
- StickyAssignor分配策略 0.11以后新加
- 什么时候触发分区分配策略:
- offset提交
-
- 手动提交
-
- 消费者导致的数据漏消费(数据丢失)
- 消费者导致的数据重复消费问题
- 自动提交offset
- 消费者三中语义
-
- At-most-once
- at-least-once
- Exactly-once
- 使用subscribe实现Exactly-once
- 使用assign实现Exactly-once
一个分区的数据最多只能被一个消费者消费,增加或者减少会触发kafka集群的负载均衡**
消费者分区分配策略
consumer采用pull(拉)模式从broker中读取数据
Kafka有两种分配策略,一是roundrobin,一是range
range(默认)
对于每一个topic,RangeAssignor策略会将消费组内所有订阅这个topic的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区
- 分区刚好分配均匀时候

- 可能出现

roundrobin
RoundRobinAssignor策略的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询消费者方式逐个将分区分配给每个消费者。
RoundRobinAssignor策略对应的partition.assignment.strategy参数值为:org.apache.kafka.clients.consumer.RoundRobinAssignor
- 同一个消费组内所有的消费者的订阅信息都是相同的,那么RoundRobinAssignor策略的分区分配会是均匀的。

- 如果同一个消费组内的消费者所订阅的Topic 是不相同的,那么在执行分区分配的时候就不是完全的轮询分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个topic,那么在分配分区的时候此消费者将分配不到这个topic的任何分区
C0订阅的是主题T0,消费者C1订阅的是主题T0和T1,消费者C2订阅的是主题T0、T1和T2)
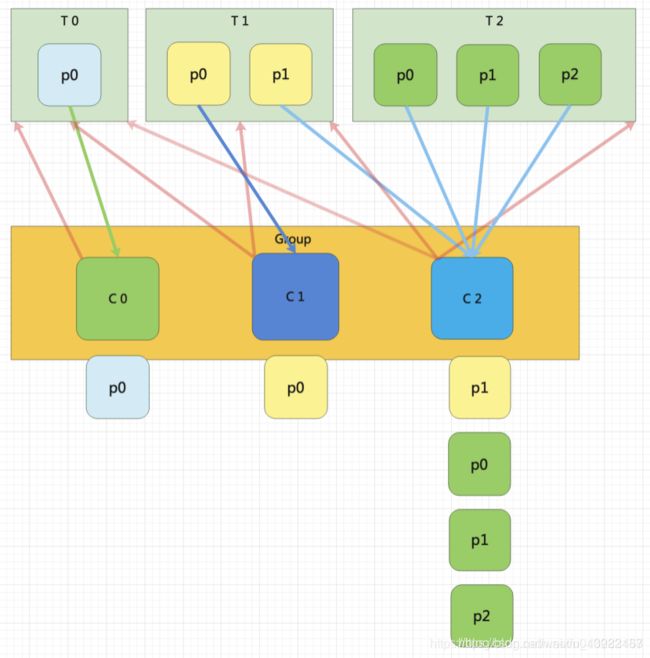
StickyAssignor分配策略 0.11以后新加
分区的分配要尽可能的均匀;
分区的分配尽可能的与上次分配的保持相同。
- 今天偶然看到的,大致简单看了一下,有时间再去了解一下
什么时候触发分区分配策略:
1.同一个Consumer Group内新增或减少Consumer
2.Topic分区发生变化
offset提交
Consumer消费数据时的可靠性是很容易保证的,因为数据在Kafka中是持久化的,故不用担心数据丢失问题。
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
所以offset的维护是Consumer消费数据是必须考虑的问题
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
手动提交
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync会失败重试,一直到提交成功(如果由于不可恢复原因导致,也会提交失败);而commitAsync则没有失败重试机制,故有可能提交失败
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.199.100:9092");
props.put("group.id", "test");//消费者组,只要group.id相同,就属于同一个消费者组
props.put("enable.auto.commit", "false");//自动提交offset
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("mytopic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
consumer.commitSync();
消费者导致的数据漏消费(数据丢失)
我们把上面的代码改一下,我们拿到records 先不做处理,先commit offset,那么commit之后发生异常,你这个数据其实还没处理,但是kafka认为你已经消费了
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
consumer.commitSync();
//比如在这加一个异常
throw new Exception()
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
消费者导致的数据重复消费问题
如果consumer消费到了5,挂了,offset只提交到了3,
下次启动记录的3开始消费,但是其实4和5已经消费过了
这就导致重复消费

自动提交offset
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能
在构建consumer时候加上自动提交offset的配置
props.put("enable.auto.commit", "true");:是否开启自动提交offset功能
props.put("auto.commit.interval.ms", "1000");:自动提交offset的时间间隔
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.199.100:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("mytopic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
消费者三中语义
- At least once 最少一次
- At most once 最多一次
- Exactly once 恰好一次
At-most-once
做多一次消费语义是kafka消费者的默认实现。配置这种消费者最简单的方式是
- enable.auto.commit设置为true。
- auto.commit.interval.ms设置为一个较低的时间范围。
- consumer.commitSync()不要调用该方法。
由于上面的配置,就可以使得kafka有线程负责按照指定间隔提交offset。
但是其实这种方式会使得kafka消费者有两种消费语义:
-
最多一次语义->at-most-once
消费者的offset已经提交,但是消息还在处理,这个时候挂了,再重启的时候会从上次提交的offset处消费,导致上次在处理的消息部分丢失。 -
最少一次消费语义->at-least-once
消费者已经处理完了,但是offset还没提交,那么这个时候消费者挂了,就会导致消费者重复消费消息处理。但是由于auto.commit.interval.ms设置为一个较低的时间范围,会降低这种情况出现的概率。
at-least-once
实现最少一次消费语义的消费者也很简单。
- 设置enable.auto.commit为false
- 消息处理完之后手动调用consumer.commitSync()
这种方式就是要手动在处理完该次poll得到消息之后,调用offset异步提交函数consumer.commitSync()。建议是消费者内部实现密等,来避免消费者重复处理消息进而得到重复结果。最多一次发生的场景是消费者的消息处理完已经输出到结果库,但是offset还没提交,这个时候消费者挂掉了,再重启的时候会重新消费并处理消息。
Exactly-once
使用subscribe实现Exactly-once
使用subscribe实现Exactly-once 很简单,具体思路如下:
- 将enable.auto.commit设置为false。
- 不调用consumer.commitSync()。
- 使用subcribe定于topic。
- 实现一个ConsumerRebalanceListener,在该listener内部执行
consumer.seek(topicPartition,offset),从指定的topic/partition的offset处启动。 - 在处理消息的时候,要同时控制保存住每个消息的offset。以原子事务的方式保存offset和处理的消息结果。传统数据库实现原子事务比较简单。但对于非传统数据库,比如hdfs或者nosql,为了实现这个目标,只能将offset与消息保存在同一行。
- 实现密等,作为保护层。
使用assign实现Exactly-once
使用assign实现Exactly-once 也很简单,具体思路如下:
- 将enable.auto.commit设置为false。
- 不调用consumer.commitSync()。
- 调用assign注册kafka消费者到kafka
- 初次启动的时候,调用consumer.seek(topicPartition,offset)来指定offset。
- 在处理消息的时候,要同时控制保存住每个消息的offset。以原子事务的方式保存offset和处理的消息结果。传统数据库实现原子事务比较简单。但对于非传统数据库,比如hdfs或者nosql,为了实现这个目标,只能将offset与消息保存在同一行。
- 实现密等,作为保护层。