mysql基础 --函数
文章目录
- 内置函数
- 流程控制函数
- 加密函数
- 自定义函数
内置函数
- 单行函数,单行输入,单行输出;
# 数值函数
abs(-1), 绝对值 1
sign(-32), 负数取-1,正数取1
pi() 圆周率;
ceil(x) 向上取整
floor(x) 向下取整
least(1,2,3)
greatest(1,2,3) 最大值
mod(x,y) 求模
rand() 0-1的随机数; rand(seed) 给一个种子,同一个种子生成的随机数相同;
round(x) 四舍五入,取整
round(x,y) 保留几位小数
round(123.34, 1); 123.3
round(123.34, -1); 120
truncat(123.39, 1) 截断保留一位 123.3
truncat(123.39, -1) 截断保留一位 120
truncat(123.39, 0) 截断保留一位 123
sqrt(x) 开根号
# 三角函数
radians(x) 角度转为弧度;
degrees(x) 弧度转为角度;
sin(x)
cos(x)
asin(x)
acos(x)
tan(x)
atan(x)
cot(x)
# 指数函数
pow(a, b) a^b
exp(a) e^a
# 对数函数
ln(e^2); 2
log(10^3); 3
log10(xx)
log2(xx)
# 进制转换
bin(10) 十转二
hex(10) 十进制转十六
oct(10) 十进制转八进制
conv(num, base, tobase)
# 字符串函数
ascii('abc') 首字母的ascii码
char_length('我们') 字符长度 2
length('我们') 字节长度 6bytes (utf8)
concat('a', 'bc', '') 'abc'
insert('abcdefg', 3, 5, '000') 替换,(从1开始)3的位置向后长度为5的子串,替换为'000'
replace('laufing', 'lauf', 'tom') 替换,匹配到lauf,替换为tom
upper(s)/lower(s) 全大/小写
left(s, 3) 从左边取三个字符
right(s, 4) 从右边取四个字符
# 右对齐
lpad(s, 10, ' ') 保持长度为10,不够左补空格
rpad(s, 10, ' ')
# 去除空格
trim(s)/ltrim(s)/rtrim(s)
# 去除特定的字符
trim(xxx from s)
trim(leading xx from s)
trim(trailing xx from s)
repeat(s, n) 重复
space(n) 空格
strcmp(s1, s2) 逐字符比较
substr(s, idx, len) 截取
locate(s1, s) 查找s1在s中的首次出现位置
reverse(s)
# 日期时间类型
select curdate(), curtime(), now(); # 当前日期、时间
select utc_date(), utc_time() # utc 时间
select unix_timestamp(), unix_timestamp('2022-10-11'); # 获取当前时间戳,将日期转为时间戳;
select from_unixtime(1665417600); # 将时间戳转为日期
# 解析日期
select year(curdate()), month(curdate()), day(curdate());
select extract(day from now()); # 抽取day
# 日期加减
select date_add(now(), interval 1 year);
select date_add(now(), interval -1 year);
select date_add('2022-10-11', interval '1_1' year_month); # 加1年1月
解析日期:


interval 间隔类型



- (分组)聚合函数(多行函数),多行输入,单行输出;
count, sum, avg, min, max
# 查询学生的平均年龄
select avg(age) from stu;
# 查询学生数
select count(*) from stu;
# count(*) count(1) count(字段)
# myisam存储引擎 三者效率相同
# innodb count(*)=count(1) > count(字段)
# 查询每个老师id有几个学生
select teacher_id, count(*) from stu GROUP BY teacher_id;
# select 中的非聚合的字段一定是在group by中的
# group by中的不一定出现在select 中
# group by可多个字段分组, 跟 with rollup 统计结果记录数,与order by 互斥
# 执行顺序 from > where > group by> select > order by > limit
# having
# 普通的过滤条件,放在where中,且效率要高;
# 如果where 条件中使用了聚合函数过滤,则必须使用having代替(分组聚合后的过滤条件),且在group by后
# 查询各个部门中最高工资>10000的部门
select depart_id, max(salary) from employees group by depart_id having max(salary) > 10000;
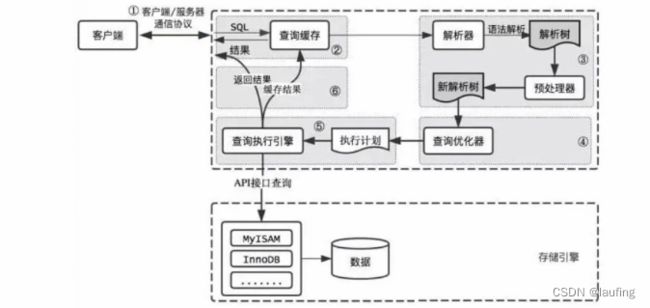
- sql的执行流程
- from 确定源数据;
- join…on 源数据连接;
- where 普通条件过滤;
- group by xxx having
- select > distinct 查询结果
- order by 对结果排序;
- limit xxx offset xxx 限制返回的 结果;
流程控制函数
#if
if(exp, v1, v2) # exp为true返回v1, 否则返回v2
#ifnull
ifnull(v1, v2) # v1 is null then reutrn v2
# case
case when exp1 then v1
when exp2 then v2
when exp3 then v3 # true 则返回
else v4 end
case 字段 when 10 then v1
when 20 then v2
else v3 end
加密函数
- password(str);
- md5(str);
- sha(str);
- encode(str, key); 加密
- decode(str, key); 解密
其他


自定义函数
- create function fname(p1 type1, p2 type2…) returns type
- 函数体 begin…return xx…end
# 创建函数
create FUNCTION lauf(age1 int) returns int(4)
BEGIN
# define variable;
declare a1 int default 0;
# assign;
set a1 = (select age from stu where age = age1);
return a1;
END
在另一个会话中,调用函数
select lauf(30);