python—spark本地安装及环境变量配置
Spark介绍
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。Spark和Hadoop的关系是,Hadoop的MapReduce是大家广为熟知的计算框架,而Spark则是一种新的计算框架。
Windows上python的spark环境搭建
一:python环境的安装(如果已经安装可以跳过,但是注意环境变量的配置)
python的jdk安装:
1、安装前选择add to path, 自动添加到环境变量。
2、win+r,进入cmd窗口,输入python,出现python界面并出现版本
3、以上两种情况,说明python的jdk安装成功
或Anoconda的安装:3.8.3
1、下载安装 一路到底
下载镜像地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
安装:一路到底。
注意:在安装时候注意安装路径要记录下来,方便配置环境变量使用
C:\Users\HP\miniconda3
2添加环境变量:
在系统环境变量中,添加如下配置
C:\Users\HP\miniconda3\Library\bin
C:\Users\HP\miniconda3\Scripts
C:\Users\HP\miniconda3
3、进入win+R,输入cmd
进入cmd命令窗口,输入 conda -V 查看 conda版本
进入cmd命令窗口,输入 python 进入python程序界面,并显示python版本。---输入 eixt() 退出。
以上两个出现,则说明安装成功
二:Java与hadoop环境的安装
1.安装好JDK
下载并安装好jdk-12.0.1_windows-x64_bin.exe,配置环境变量:
- 新建系统变量JAVA_HOME,值为Java安装路径
- 新建系统变量CLASSPATH,值为 .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注意最前面的圆点)
- 配置系统变量PATH,添加 %JAVA_HOME%bin;%JAVA_HOME%jre/bin
在CMD中输入:java或者java -version,不显示不是内部命令等,说明安装成功。
2.安装Hadoop,并配置环境变量(hadoop也可以自己下载。但是路径要记住方便配置环境变量)
- 解压hadoop-2.7.7.tar.gz特定路径,如:D:\adasoftware\hadoop
- 添加系统变量HADOOP_HOME:D:\adasoftware\hadoop
- 在系统变量PATH中添加:D:\adasoftware\hadoop\bin或%HADOOP_HOME%\bin, D:\adasoftware\hadoop\sbin或%HADOOP_HOME%\sbin
- 安装组件winutils:将winutils中对应的hadoop版本中的bin替换自己hadoop安装目录下的bin
三:Spark环境的安装
1.Spark环境变量配置
spark是基于hadoop之上的,运行过程中会调用相关hadoop库,如果没配置相关hadoop运行环境,会提示相关出错信息,虽然也不影响运行。
- 下载对应hadoop版本的spark:http://spark.apache.org/downloads.html
- 解压文件到:D:\adasoftware\spark-2.4.4-bin-hadoop2.7
- 添加PATH值:D:\adasoftware\spark-2.4.4-bin-hadoop2.7\bin;
- 新建系统变量SPARK_HOME:D:\adasoftware\spark-2.4.4-bin-hadoop2.7;
- 添加PATH值:D:\adasoftware\spark-2.4.3-bin-hadoop2.7\bin;或%SPARK_HOME%\bin,
2.在CMD中运行pyspark,出现类似下图说明安装配置正常:

四:pycharm部分配置
1.引入spark-core的包,复制spark-2.4.3-bin-hadoop2.7/python/pyspark文件夹到python的安装路径下(或anaconda路径下)的 Lib\site-packages中,如图所示。

2.在pycharm中配置spark
配置spark开发依赖包
步骤1:选择菜单栏“File”—>“Project Structure ”命令,快捷键为“ctrl+alt+shift+s”打开图5-4所示界面。
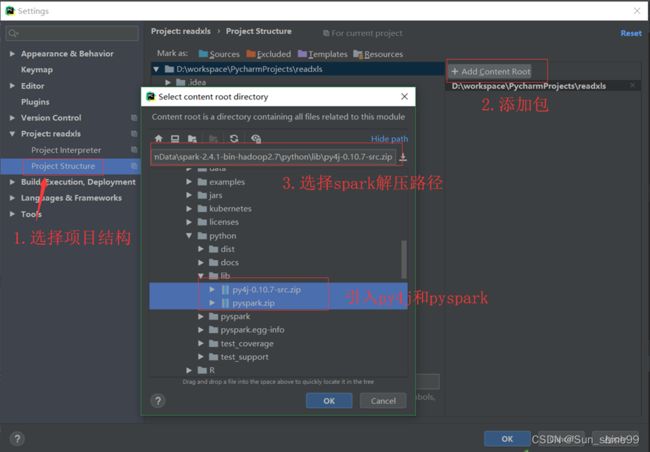 图5-4 配置项目
图5-4 配置项目
步骤2:引入spark-core的包,如图5-5所示。

图5-5 配置Spark库
如果遇到下面问题:
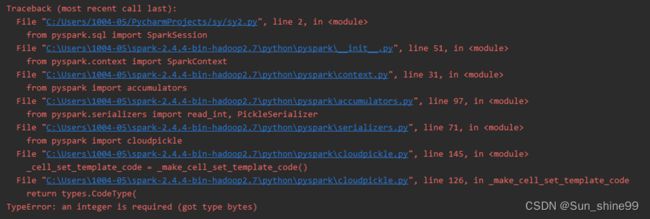
请更换python版本到3.7版本或者更低版本
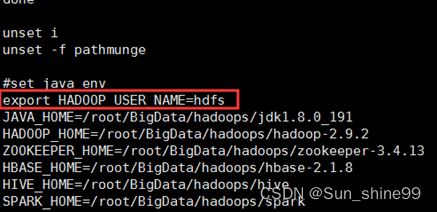
注意:在开发项目时出现权限无法访问问题解决方案
/etc/profile中添加
export HADOOP_USER_NAME=hdfs
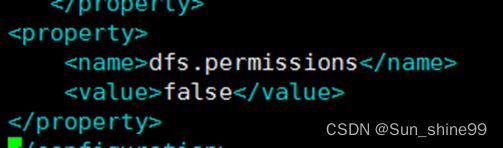
Hdfs-site.xml中添加
开发Spark程序
开发Spark程序的基本流程,就是使用Spark提供的API来创建RDD、转换RDD、触发计算、转存计算结果。
1.创建RDD方式
spark主要就是用来创建RDD和操作RDD,创建RDD两种方式:
1.1 parallelize()方法
parallelize()方法:并行化,就是讲集合或者列表转换为RDD,一般在测试或者学习的情况使用。
案例
| parallelize 调用SparkContext 的 parallelize(),将一个存在的集合,变成一个RDD,这种方式试用于学习spark和做一些spark的测试 spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext #案例1:
ls = [1, 2, 3, 4, 5, 6, 7, 8, 9]
rdd = sc.parallelize(ls)
print(type(rdd))
print(rdd)
print(rdd.collect())
rdd1 =rdd.map(lambda x:x*2)
print(rdd1.collect()) #案例2:为方便操作集合或者列表,将列表转为RDD list = ["Hadoop","Spark","Hive","Spark"] rdd = sc.parallelize(list) pairRDD = rdd.map(lambda word : (word,1)) pairRDD.foreach(print) |
1.2 读取一个外部的数据集
读取一个外部的数据集,Spark将不同地方的数据源转为统一的rdd格式
例如:从本地加载数据集或者从hdfs文件系统上、hbase,、Amazoo S3 等加载外部数据集。。Spark可以支持文本文件、SequenceFile文件(Hadoop提供的 SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件)和其他符合Hadoop InputFormat格式的文件。
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext """
从本加载文件数据集,存储到本地
"""
rdd = sc.textFile("C:/WorkSpace/sparkProject/localfile/test.txt")
print(type(rdd))
print(rdd.collect())
rdd.saveAsTextFile("C:/WorkSpace/sparkProject/localToLocal")
"""
从本加载文件数据集,存储到hdfs
"""
rdd = sc.textFile("C:/WorkSpace/sparkProject/localfile/test.txt")
print(type(rdd))
print(rdd.collect())
rdd.saveAsTextFile("hdfs://hadoop001:9000/localToHdfs")
"""
从hdfs载文件数据集,存储到本地
"""
rdd = sc.textFile("hdfs://hadoop001:9000/test.txt")
print(type(rdd))
print(rdd.collect())
rdd.saveAsTextFile("C:/WorkSpace/sparkProject/hdfsToLocal") """
从hdfs载文件数据集,存储到HDFS
"""
rdd = sc.textFile("hdfs://hadoop001:9000/test.txt")
print(type(rdd))
print(rdd.collect())
rdd.saveAsTextFile("hdfs://hadoop001:9000/HdfsToHdfs") |
注意事项:
1.如果使用了本地文件系统的路径,那么,必须要保证在所有的worker节点上,也都能够采用相同的路径访问到该文件,比如,可以把该文件拷贝到每个worker节点上,或者也可以使用网络挂载共享文件系统。
2.textFile()方法的输入参数,可以是文件名,也可以是目录,也可以是压缩文件等。比如,textFile("/usr/local"), textFile("/usr/local/.txt"), textFile("/usr/local/.gz")
3.textFile()方法也可以接受第2个输入参数(可选),用来指定分区的数目。默认情况下,Spark会为HDFS的每个block创建一个分区(HDFS中每个block默认是128MB)。你也可以提供一个比block数量更大的值作为分区数目,但是,不能提供一个小于block数量的值作为分区数目,那么有些块就不能创建成分区,对应数据就无法计算。
2.读取json文件

JSON数据:
{"product":"suit"}
{"product":"pants", "age":30}
{"product":"Shoes", "age":19}
| from pyspark import SparkContext import json spark = SparkSession.builder.appName("实例1").master("local[*]").getOrCreate() sc = spark.sparkContext inputFile = "file:///hwadee/spark/testdata/04.json" jsonStrs = sc.textFile(inputFile) result = jsonStrs.map(lambda s: json.loads(s)) result.foreach(print) |
构建Pair RDD
什么是Pair RDD
(1)包含键值对类型的RDD被称作Pair RDD。
(2)Pair RDD通常用来进行聚合计算。
(3)Pair RDD通常由普通RDD做ETL转换而来。
一个完整示例
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
创建Pair RDD 什么是Pair RDD?
包含key-vaule键值对类型的RDD就称为Pair RDD
Pair RDD通常用来对数据进行聚合计算
Pair RDD通过普通RDD转换来的,例如:
通过map构建一个Pair RDD
"""
案例1:
# context = sc.textFile("C:/WorkSpace/sparkProject/localfile/test.txt")
# #将每一行的数字作为key值,每行的数据作为value,构建pairRDD
# pairRDD = context.map(lambda line:(line.split(" ")[0],line))
# print(pairRDD.collect())
案例2:
context = sc.textFile("C:/WorkSpace/sparkProject/localfile/word.txt")
#将每一行的数字作为key值,每行的数据作为value,构建pairRDD
pairRDD = context.map(lambda word:(word,1))
tmp_list = pairRDD.collect()
print(type(tmp_list))
def fun(x):
print(x)
[ fun(i) for i in tmp_list] |
我的理解:首先将待处理的数据或者文件读入创建一个RDD,然后根据业务逻辑写函数。也就是生成不同的RDD最终得到我们想要的数据的过程。 |