C++20新特性简要概述
C++20新特性
- 1,模块(Modules)
- 2,Ranges
- 3,协程(Coroutines)
- 4,Concepts
- 5,Lambda
-
- [=, this] as Lambda Capture
- Templated Lambda Expressions(模板Lambda表达式)
- Pack Expansion in Lambda Captures(Lambda捕获列表扩展)
- 6,constexpr
-
- constexpr virtual functions
- union, try/catch, dynamic_cast, typeid
- allocations(内存分配)
- constexpr string & vector
- 7,Concurrency(并发编程)
-
- Atomic Smart Pointers(原子智能指针)
- Joining & Cancellable Threads(可删除线程)
- The C++20 Synchronization Library(同步库)
-
- Semaphores(信号量)
- latches
- barriers
- Waiting & notifying on std::atomic
- std::atomic_ref
- 8,其他小功能
-
- Designated Initializers(指定Initializers)
- Spaceship Operator<=>
- Range-based for Loop Initializer(循环语句中初始化对象)
- Non-Type Template Parameters(无类型模板参数)
- [[likely]] and [[unlikely]]
- Calendars & timezones(日历 & 时区)
- std::span
- Feature Test Macros(功能测试宏)
- \
- Immediate Functions - consteval(即时函数)
- constinit
- Class Enums and using Directive
- Text Formatting(std::format)
- Math Constants
- std::source_location
- [[nodiscard(reason)]]
- Bit Operations(位操作)
- Small Standard Library Additions(标准库添加)
- New keywords
1,模块(Modules)
优势
-
模块长远来看是要替换头文件
-
使用模块必须明确的说明要从模块中导入的内容, 例如要导出哪个类,函数,常亮,枚举
-
有模块接口文件和模块实现文件, 因此可将代码分成接口文件和实现文件, 类似头文件和cpp文件,对模块来说已经不再是必需的,对于模块接口文件,只有函数签名是导出内容, 因此即使在模块接口文件中编写了任何函数体,它们也不会被导出,不在导出的接口中, 因此如果这个函数被修改,不会触发引入你模块的用户重新编译
-
如果想为模块添加更多结构,可以做两件事, 可以使用子模块, 或者使用分区
-
不需要防卫式
-
不同的模块可以有相同的函数名字,当然两个模块导入同一个源文件那么会有链接错误
-
模块在处理时只会被构建一次, 预处理器宏不会对模块里的diamante产生任何影响,在模块里定义的所有预处理器宏都不会泄露出去, 因此模块的导入顺序并不重要
Create a module:
//cppcon.cppm -- Module Interface File
export module cppcon;//模块声明
namespace CppCon{
auto GetWelcomeHepler(){return "Welcom to CppCon 20";}//没被导出
export auto GetWelcome(){return GetWelcomeHelper();}//被导出
}
如何使用这个模块:
Consume a module:
//main.cpp
import cppcon;
int main(){
std::cout << CppCon::GetWelcome();
}
- C++20支持模块的使用, 但是没有指定是否和怎样模块化标准库,但标准库中的所有C++头文件都是可导入的
2,Ranges
- Ranges是一个引用元素系列/范围的对象, 所以基本上它类似于一个begin/end迭代器,但是不替换它们
- 为什么引入Ranges
场景:对vector容器内的元素进行排序
//before
vector data{11, 22, 33};
sort(begin(data), end(data));
//now
ranges::sort(data);
消除不匹配的begin/end迭代器的错误
ranges的适配器能延迟转换/过滤数据,再传给算法
Ranges的主要组成部分
-
Range: 所有支持begin/end的标准库容器都是Ranges
-
Range-based algorithms:几乎所有以前接受迭代器对的标准库算法都能加在Ranges上
-
Projection:在交给算法之前,转换容器中的元素
-
Views:延期执行transform/filter元素, 视图不拥有任何东西,也无法修改底层数据
-
Range factories:建立range工厂按需生成值,如Range工厂可以产生整数无穷序列
-
Pipelining:可以将几个转换或过滤串联起来成为一个流水线管道

Note:延迟执行: 在构造result对象时没有事情被真正执行, 只有在便利结果对象中元素时, 整个流水线才被执行
因为有这种延迟执行, 我们可以使用所谓的无限序列
使用无穷序列:
auto result{ view::ints(10)//创建一个从10开始的无穷序列
| views::filter([](const auto& value){return value % 2 == 0;})
/*....执行一系列操作....*/
| views::take(10)//取前10个限制结果数量
};
3,协程(Coroutines)
- A function
- 包含三个关键字之一的函数:
-
- co_await : 挂起当前协程, 等待其他异步计算完成
-
- co_yield : 从当前协程返回一个值给调用者, 并挂起当前协程, 随后调用者再次调用这个协程时, 它会在co_yield之后的语句处恢复执行
-
- co_return : 协程结束不能只调用return, 必须使用co_return
协程来做什么?
编写所谓的生成器(Generators), 异步I/O, 延迟计算, 事件驱动应用
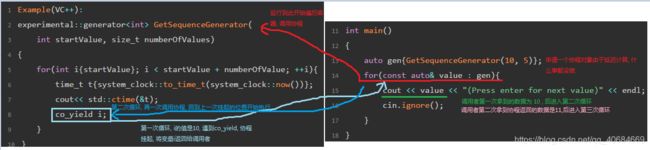
Example(VC++):
experimental::generator<int> GetSequenceGenerator(
int startValue, size_t numberOfValues)
{
for(int i{startValue}; i < startValue + numberOfValue; ++i){
time_t t{system_clock::to_time_t(system_clock::now())};
cout<< std::ctime(&t);
co_yield i;
}
}
int main()
{
auto gen{GetSequenceGenerator(10, 5)};
for(const auto& value : gen){
cout << value << "(Press enter for next value)" << endl;
cin.ignore();
}
}
4,Concepts
- 给模板参数添加一个要求
- 约束类模板或者函数模板的模板参数
创建一个concept:
template<typename T>
concept Incrementable = requires(T x){x++; ++x;};
//要求类型T同时支持前置++和后置++运算符
//对于类型T, x++和++x都应该能被编译
//这不是运行时要执行的代码, 而是在编译器评估
如何使用这个concept
方法一: 代替typename T
template<Incrementable T>
void Foo(T t);
方法二: 使用requires字句
template<typename T> requires Incrementable<T>
void Foo<T t>;
requires字句也可以在函数签名之前或者之后
template<typename T>
void Foo<T t> requires Incrementable<T>;
方法三:与简明函数模板语法结合
void Foo(Incrementable auto t);
我们写一个更复杂的concept
要求有一个不抛出异常的swap方法, 有一个返回size_t的size方法
template <typename T>
concept C = requires (T& x, T& y){
{x.swap(y)} noexcept;
{x.size()} -> std::convertible_to<std::size_t>;
}
模板要求, x可以使用swap()且不抛出异常,
x能使用size()且返回值能转换成std::size_t
当然现有的concept是可以任意组合
template<typename T> requires Incrementable<T> && Decrementable<T>
void Foo(T t);
也可以创建一个新的concept
template<typename T>
concept C = Incrementable<T> && Decrementable<T>;
void Foo(C auto t);//简明模板语法
5,Lambda
[=, this] as Lambda Capture
- C++20的lambda指定缺省按值捕获所有内容自动捕获this, 需要手动指定[=, this]
Templated Lambda Expressions(模板Lambda表达式)
[]<typename T> (T x){/*........*/}
[]<typename T> (T* p){/*........*/}
[]<typename T, int N> (T (&a)[N]){/*........*/}
- 假设有一个通用lambda可以接受vector, 并且想提取出T的类型
before C++20
[](const auto &vec){
using V = std::decay_t<decltype(vec)>;
using T = typename V::value_type;
T x{};
T::static_function();
//...
};
now C++20:
[]<typename T> (const vector<T>& vec){
T x{};
T::static_function();
//...
};
- 如果有个lambda表达式具有可变数量的参数, 你想转发这些参数, 如果想转发到另一个函数foo
before C++20
[](auto&& ...args){
return foo(std::forward<decltype(args)>(args)...);
}
now C++20
[]<typename ...T>(T&& ...args){
return foo(std::forward<T>(args)...);
}
Pack Expansion in Lambda Captures(Lambda捕获列表扩展)
- 捕获列表为一包参数
在之前有这样的问题:

如果这样捕获则会报错:C++20之后则不会报错


6,constexpr
constexpr virtual functions
- 现在虚函数可以被标记为constexpr
union, try/catch, dynamic_cast, typeid
- constexpr functions 也可以调用dynamic_cast, typeid,union
- 可以包含try/catch代码块 但是不允许抛出异常,必须捕获所有可能引发的异常
allocations(内存分配)
- constexpr function中可以使用new/delete, 确保是使用的全局的new/delete
constexpr string & vector
- 现在可以再constexpr函数中使用string和vector
- 这是将来支持constexpr反射的第一步
7,Concurrency(并发编程)
Atomic Smart Pointers(原子智能指针)
- shared_ptr是线程安全的吗?
-
- 一方面是. 控制块是线程安全的, 基本上引用计数增减是线程安全的, 这可以确保对象只会被释放一次
-
- 另一方面不是. 在使用指针时不是线程安全的,一个线程可能在读取指针, 另一个线程存储了一个新的指针
- 我们可以使用互斥锁来保护,
或者我们可以使用全局非成员原子操作如 std::atomic_load(), atomic_store()… - c++20中可以使用 atomic的shared_ptr–> atomic
实现线程安全 -
- 可以再内部使用互斥锁
-
- 不建议使用全局非成员原子操作
template<typename T> class concurrent_stack{
struct Node{ T t; shared_ptr<Node> next;};
atomic_shared_ptr<Node> head;
//C++11: 使用shared_ptr , 在每次使用head时
//都要调用全局非成员函数
public:
class reference{
shared_ptr<Node> p;
};
auto find(T t) const{
auto p = head.load();
//C++11:atomic_load(&head)
while(p && p->t != t)
p = p->next;
return reference(move(p));
}
auto front() const{
return reference(head);
//C++11:atomic_load(&head)
}
void push_front(T t){
auto p = make_shared<Node>();
p->t = t;
p->next = head;//C++11:atomic_load(&head)
while(!head.compare_exchange_weak(p->next, p)){}
//C++11:atomic_compare_exchange_weak(&head, &p->next, p)
}
void pop_front(){
auto p = head.load();
while(p && !head.compare_exchange_weak(p, p->next)){}
//C++11:atomic_compare_exchange_weak(&head, &p, p->next)
}
};
显然并没办法阻止用户直接使用shared_ptr, 一旦使用了会导致线程不安全
Joining & Cancellable Threads(可删除线程)
- std::jthread
- 它也在头文件里
- 两个新功能 1. 协作式取消 2.析构函数将自动取消线程并join
如何cancel一个线程:
- std::stop_token
-
- 检查是否有请求结束, 支持取消的线程将须定期检查是否被请求, 取消线程需要线程本身合作,故称作协作式取消
-
- stop_token与condition_variable_any兼容, 因此如果线程在休眠等待条件变量, 当stop_token请求停止线程时,它可以被condition_variable_any唤醒
- std::stop_source
-
- stop_source时线程取消的另一端, 被用来实际请求线程停止
- std::stop_callback
-
- 可以注册一个回调函数, 每当请求停止时, 你的回调就会被调用
-
- std::stop_callback myCallback{ myStopToken, []{/…/}}
e.g:
void DoWorkPreCpp20(){
std::thread job{[]{/*.......*/}}
//旧版本的thread对象并行 运作某些事情
try{
//.. Do something else ...
//在做其他事情的时候, 可能发生异常,
//发生异常时必须要保证线程被join
//因此必须把这块代码放在try/catch中
}catch(...){
job.join();
throw;//rethrow
}
job.join();
}
在C++20之后:
void DoWord(){
std::jthread job{[]{/*......*/}};
//... Do something else ...
}//jthread对象在析构函数中自动取消线程并调用join()
线程协作式取消:
std::jthread job{[](std::stop_token token){//线程传入参数std::stop_token
while(!token.stop_requested()){//定期检查以停止线程
/*......*/
}
}};
........
job.request_stop();//在外部停止线程
也可以通过std::stop_source 停止线程:
std::stop_source source{job.get_stop_source()};
source.request_stop();
最后通过std::stop_token可以知道是否已经请求停止
std::stop_token token{job.get_stop_token()};
bool b{tken.stop_requested()};
The C++20 Synchronization Library(同步库)
Semaphores(信号量)
- 轻量级的同步
- 可以实现其他任何同步概念: mutex, latches, barriers
- 有两种信号量
-
- counting_semaphore : 一个非负数的资源计数
-
- binary_semaphore: 只有一个槽位, 状态仅有 空闲/非空闲 (非常适合互斥对象)
latches
- latch是一个线程同步点
-
- 一个线程在遇到latch时会阻塞等待, 直到给定数量的线程全部达到这里, 一旦他们都到达这里,所有的线程都被恢复并继续
-
- 当指定数量为5, 每个线程到达这个位置计数器减1, 知道计数器为0, 线程才继续执行, 一旦计数器变为0, 它便保持为0, 因此std::latch基本上是一次性使用对象
barriers
- barriers有一系列的阶段, 类似一个能连续使用的latch
-
- 给定数量的线程阻塞直到它们都到达这里,
-
- 执行某种回调,
-
- 计数器被重置,
-
- 下一个阶段开始,
-
- 线程继续运行
Waiting & notifying on std::atomic
- 等待atomic对象改变值后通知函数
- 比轮询效率高
- Methods
-
- wait()
-
- notify_one()
-
- notify_all()
std::atomic_ref
- Atomic reference
- 基本上与std::atomic相同
-
- 但std::atomic永远拷贝值, std::atomic_ref可以用于引用, 在某些情况下atomic_ref可以更高效
8,其他小功能
Designated Initializers(指定Initializers)
结构体指定初始化
struct Data{
int anInt {0};
std::string aString;
};
Data d{.aString = "Hello"};
Spaceship Operator<=>
- 新增的运算符, 三相比较运算符<=>
-
- (a < = > b) < 0//true a
- (a < = > b) < 0//true a
-
- (a < = > b) > 0//true a>b
-
- (a < = > b) == 0// true a=b
- 为自己的类定义三相比较运算符
-
- auto X::operator<=>(const Y&) const = default; 这样可以要求编译器帮忙实现
-
- 编译器将生成所有的6个比较运算以比较X和Y, 它将按成员比较
- 不希望默认按成员比较, 这种情况下需要重写自己的三相比较符,这时会需要写一个operator== , 有三种返回值类型的选择: strong_ordering, partial_ordering, weak_ordering
int i{42};
strong_ordering result{i <=> 0};
if(result == strong_ordering::less){cout << "less";}
if(result == strong_ordering::greate){cout << "greater";}
if(result == strong_ordering::equal){cout << "equal";}
此外还有命名的比较函数:
if(is_lt(result)){cout << "less";}
if(is_gt(result)){cout << "greater";}
if(is_eq(result)){cout << "equal";}

- 标准库对< = > 都有支持 vector, string, map, set, sub_match
Range-based for Loop Initializer(循环语句中初始化对象)


Non-Type Template Parameters(无类型模板参数)
- C++20中无类型模板参数允许使用浮点数, 允许使用类, 但是类类型有很多限制
auto m {ctre::math<"[a-z]+([0-9]+)">(str)};
[[likely]] and [[unlikely]]
- 两个新增的属性
- 提示编译器优化某些分支
switch (value){
case 1:
break;
[[likely]] case 2:
break;
[[unlikely]] case 3:
break;
}
例子中,如果你知道2的可能性要比其他分支高, 可以在2处放置属性,
如果3的可能性比其他任何情况都小, 可以在3处放置属性
if语句分支也可以如此
Calendars & timezones(日历 & 时区)
支持日历和时区 - 当前仅支持公历, 但是可以添加自定义日历与内其他东西互操作
Creating a year:
auto y1{ year {2020} };//使用构造函数语法
auto y2 { 2020y };//使用标准自定义字面量
Creating a month://创建月可以用构造函数构造,或12个预定义实例
auto m1{ month {9} };
auto m2{ Septerber };
Creating a day:
auto d1{ day{15} };
auto d2{ 15d };
Creating a full date:
year_month_day fulldate1 { 2020y, September, 15d };
auto fulldate2{ 2020y / Septermber / 15d };
year_month_day fulldate3{ Monday[3]/September/2020};
//创建2020年9月的第三个星期一
- 有几个新的duration类型别名, C++11已经有了 seconds, minutes, hours, 现在C++20还有days, weeks, months, years

weeks w {1};//一个星期
days d {w};// 将一个星期转换为天
- 新增四个clocks(基于 system_clock, steady_clock, high_resolution_clock):
-
- utc_clock:表示协调世界时(UTC),度量自1970年1月1日星期四00:00:00 UTC开始的时间,包括闰秒
-
- tai_clock:代表国际原子时(TAl),测量自1958年1月1日00:00:00开始的时间,在该日比UTC早10秒进行偏移,它不包括闰秒
-
- gps_clock:表示全球定位系统(GPS)时间,度量自UTC 1980年1月6日00:00:00开始的时间,它不包括闰秒
-
- file_clock:std::filesystem::file_time_type使用的时钟别名, 时代未指定
- 新增新的类型别名 sys_time: system_clock的- - time_point 与 duration
- 基于sys_time还有两个新的类型别名
-
- using sys_seconds = sys_time
- using sys_seconds = sys_time
-
- using sys_days = sys_time
- using sys_days = sys_time
这里有个日期, sys_days是别名, 实际上是将其转换成time_point
system_clock::time_point t{
sys_days{2020y / September / 15d}};//date转time_point
另一方面, 也可以将time_pont转换成date
auto yearmothday{
year_moth_day{ floor<days>(t) } };//time_point转date
Date+Time:
auto utc{ sys_days{2020y/September/15d} + 9h + 35min + 10s};
//2020-09-15 09:35:10 UTC
可以将utc转换为世界上任何时区
zoned_time denver {"America/Denver", utc};//转换时区
查询当前时区是什么, 然后创建一个时区
auto localt { zoned_time { current_zone(), system_clock::now()}};
std::span
- 提供了一个连续数据的"view"
- 不拥有任何内容(因此它永远不会分配和释放数据)
- 可以read/write
- 它只是指向连续数据中第一个元素的指针以及数据打大小, 因此它的copy非常轻便, 建议仅通过值传递,像使用string_view一样
- span可以是动态大小, 也可以是固定大小
int data[42];
span<int, 42> a {data}; // fixed-size: 42 ints
span<int> b {data}; // dynamic-size: 42 ints
span<int, 50> c {data};//指定错误大小compilation error
span<int> d {ptr, len};//dynamic-size: len ints
通过这些 span 可以对data数组进行读写
构建一个只读的span:
span<const int> b;
- span支持很多操作, 也有迭代器的全部支持
-
- Iterators(begin, cbegin, rbegin, …)
-
- front(), back(), operator[], data()
-
- size(), size_bytes(), empty()
-
- first(count): 返回第一个元素起count长度的子span
-
- last(count):返回末尾元素起count长度的子span
-
- subspan(offset, count):返回子span[offset, offset+count]
Feature Test Macros(功能测试宏)
- 允许检查编译器是否支持某些语言特性或库功能
- 语言功能测试宏
-
- __has_cpp_attribute(fallthrough)
-
- __cpp_binary_literals
-
- __cpp_char8_t
-
- __cpp_coroutines
…
- __cpp_coroutines
- 库功能测试宏
-
- __cpp_lib_concepts
-
- __cpp_lib_ranges
-
- __cpp_lib_scoped_lock
…
- __cpp_lib_scoped_lock
E.g:
#if __has_include()
#include)
#include - C++20引入的新的头文件
- 提供了关于你使用的C++编译器的系统信息
-
- Version number
-
- Release date
-
- Copyright notice
- 中包含一些库功能测试宏
-
- __cpp_lib_any, __cpp_lib_bool_constant, __cpp_lib_filesystem, …
Immediate Functions - consteval(即时函数)
- constexpr function (constexpr函数早已添加到C++标准中)
-
- 允许函数在编译时运行, 但不是一个硬性要求
C++20之前:
constexpr auto InchToMm(double inch){ return inch * 25.4;}
函数InchToMm被标记为constexpr
const double const_inch{6};
const auto mm1 {InchToMm(const_inch)};
如果调用这个函数, 使用const double, 此函数将在编译期执行
double dynamic_inch{8};
const auto mm2{InchToMm(dynamic_inch)};
如果用double调用, 而不是const double, 那依然在运行时运行,
依然编译通过, 或许并不是想要的
- consteval function(C++20的即时函数)
在编译运行时函数需要一个const常量, 否则编译会报错
C++20:
consteval auto InchToMm(double inch) {return inch * 25.4;}
const double const_inch{6};
const auto mm1 {InchToMm(const_inch)};//Fine
double dynamic_inch{8};
const auto mm2{InchToMm(dynamic_inch)};//error
constinit
- 使用constinit关键字可以强制常量初始化
constinit const char *a{...};
这里用了constinit, 如果这里有某种动态活动, 编译器会报错,
这样在运行时不会产生奇怪的结果
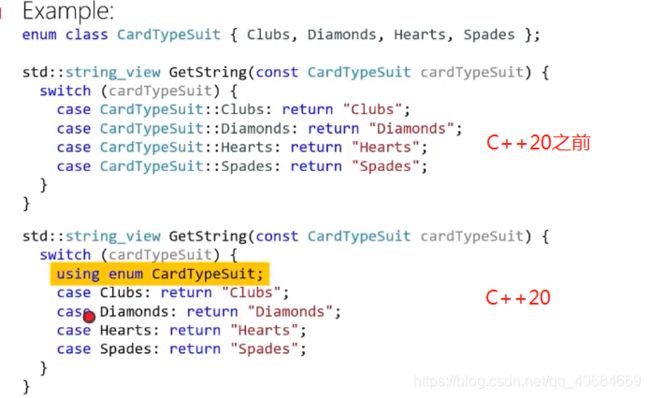
Class Enums and using Directive
Text Formatting(std::format)
文字格式化C++20之前有两种方式
- I/O streams
安全的和可扩展, 很难阅读,很难本地化, 没有分隔格式字符串和参数 - pintf()
不安全,不可扩展, 更容易阅读,没有一系列的<<插入操作符分隔格式字符串和参数容易本地化 - C++20的文字格式化
std::format()
结合了I/O流和printf的优势, 安全且可扩展, 易于阅读,没有一系列的<<插入操作符, 分隔格式字符串和参数, 有位置参数, 易于本地化。比sprintf()、ostringstream和to_string()性能更好
cout << format("{:=^19}, "CppCon 2020"); //====CppCon 2020====
cout << format("Read {0} bytes from {1}", n, "file1.txt");
cout << format("从{1}中读取{0}个字节", n, "file1.txt");
//这样也不会导致输出文本混乱
Math Constants
, 新的头文件, 定义了一些数学常量
e, log2e, log10e
pi, inv_pi, inv_sqrtpi
ln2, ln10
sqrt2, sqrt3, inv_sqrt3
egamma
phi- In std::numbers
std::source_location
头文件定义了一些源码信息 - 调用 source_location::current() 可以提供 line, column,file_name, function_name
E.g:
void LogInfo(string_view info,
const source_location& location = source_location::current()){
cout << location.file_name() << ":" << location.line() << ":" << info <<endl;
}
int main(){
LogInfo("Welcome to CppCon 2020!");
}//打印信息可以实时输出代码信息, 不必使用宏来达成这个目的
[[nodiscard(reason)]]
- [[nodiscard]]现在可以包含一个文字形式的原因
[[nodiscard("Ignoring the return value will result in memory leaks.")]]
void* GetData(){
/*......*/
}
Bit Operations(位操作)
- 标准库现在支持位操作
-
- 左移 rotl() 右移 rotr()
-
- countl_zero():从最高有效位开始的连续0位数
-
- countl_one():从最高有效位开始的连续1位的数目
-
- countr_zero():从最低有效位开始的连续0位数
-
- countr_one():从最小有效位开始连续1位的个数
-
- popcount(): 1的位数
创建一个bitset对象,01100101向左移动2位:
std::bitset<8> b { std::rotl(0b01100101, 2)};
计算01100101中1位的个数:
int count {std::popcount(0b01100101)};
Small Standard Library Additions(标准库添加)
- string 和 string_view现在支持starts_with, ends_with
std::string str{"Hello world!"};
bool b{str.starts_with("Hello")};
- 关联容器也有contains()
std::map myMap{std::pair {1, "ons"s}, {2, "two"s}, {3, "three"s}};
bool result{myMap.contains(2)};
头文件有两个新算法, shift_left()和shift_right() - 所有容器可以使用erase()和erase_if()来移除特定的元素
- midpoint()可以计算两个数字的中点
- lerp()用于线性插值
- unsequenced_policy(execution::unseq): 算法允许向量化, 你可以使用或传递一个并发算法,这样算法被允许向量化执行, 但不允许并行执行
New keywords
conscept 用于concept
requires 用于concept
constinit 用于const初始化
consteval 用于const运算
co_await 协程相关
co_return 协程相关
co_yield 协程相关
char8_t