k8s - Pod资源解读
yaml 编写
可以通过 kubectl explain 查看资源清单包含了那些字段
kubectl explain Pod
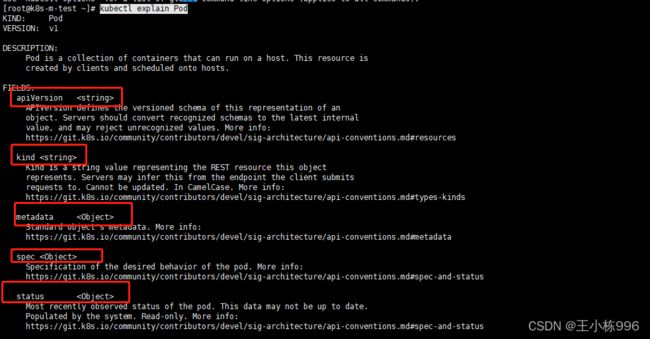
可以通过提供的More info 网页查看具体的配置样例
apiVersion 定义了对象版本
Kind 定义了资源类型
matadata 定义了元属性信息 <资源名称>
spec 定义了Pod的规格,具体容器信息
status 定义了状态,不可修改,不需要定义。
查看matadata对象该如何定义
kubectl explain Pod.metadata
查看对象该如何定义直接在后面.+对象名即可。
字段类型为
apiVersion: v1字段类型为
metadata:字段类型为
key: value字段类型为 <[]Object> 对象列表
- name: tomcat-pod-java带有required 为必填

常见属性:
metadate:
- labels 创建资源具有的标签
- namespace 资源所属命名空间(默认default)
spec:
- activeDeadlineSeconds pod可运行的最长时间
- affinity pod亲和性
- containers 定义容器必填字段,至少要有一个容器
- dnsConfig
- dnsPolicy
pod.spec.containers
- args
- command
- env
- envFrom
- image 用来指定容器需要的镜像
- imagePullPolicy 镜像拉取策略,Always 一直重新拉取、Never 从不拉取镜像、IfNotPresent优先使用本地镜像,没有在拉取镜像。
- name 必须字段指定pod中容器的名字
- ports 端口
pod.spec.containers.ports
- containerPort 必须字段,端口号
- hostIP 将容器中的服务暴露到宿主机的端口上时,可以指定绑定的宿主机 IP
-
hostPort 容器中的服务在宿主机上映射的端口
-
name 端口名称
样例:
apiVersion: v1
kind: Pod
metadata:
name: demo-pod1
labels:
app: myapp
spec:
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat命名空间
k8s中物理集群中的虚拟集群。可以给不同用户、租户、环境或项目创建对应的命名空间。
命名空间的名称仅能是字母、数字、下划线、连接线等字符组成。
命名空间通过资源配额可以限制资源。
删除命名空间,级联下的资源对象也会被删除。
# 创建命名空间
kubectl create namespace test
# 切换当前命名空间。切换命名空间后,kubectl get pods 如果不指定-n,查看的就是test命名空间的资源了。
kubectl config set-context --current --namespace=test
# 查看哪些资源属于命名空间级别的
kubectl api-resources --namespaced=true资源限额
命名空间可以通过ResourceQuota限制空间资源
kubectl explain resourcequotas
apiVersion: v1
kind: ResourceQuota
metadata:
name: test-rq
# 指定名称空间
namespace: test
spec:
hard:
# 所有容器的内存请求总额不得超过
requests.cpu: "1"
# 所有容器的CPU请求总额不得超过
requests.memory: 1Gi
# 所有容器的内存限额总额不得超过
limits.cpu: "2"
# 所有容器的CPU限额总额不得超过
limits.memory: 2Gi
名称空间下的每个容器必须设置内存请求(memory request),内存限额(memory limit),cpu请求(cpu request)和cpu限额(cpu limit)。查看限额
kubectl get quota -n test
标签
标签是一对 key/value, 被关联到对象。标签可以用来划分特定的对象,一个对象可以有多个标签。但是key值必须是唯一的。通过标签可以方便的对资源进行分组管理。k8s中大部分资源都可以打标签。
# 查看pods 标签,其他资源也可以用--show-labels查看标签
kubectl get pods --show-labels
# 对已经存在的pod打标签
kubectl label pod pod名称 key=value
# 列出默认命名空间下所有标签 key=app,不显示标签
kubectl get pods -l app
# 列出默认命名空间下所有标签 key是app,value是myapp 不显示标签
kubectl get pods -l app=myapp
# 列出默认名称空间下标签key是app的所有pod,并打印对应的标签值
kubectl get pods -L app
# 查看所有名称空间下的所有pod的标签
kubectl get pods --all-namespace --show-labels

node节点选择器
我们创建pod资源的时候,pod会根据schduler进行调度,那么默认会调度到随机的一个工作节点,如果我们想要pod调度到指定节点或调度到一些具有相同特点的node节点可以使用pod中的nodeName或nodeSelector字段指定调度到的节点
nodeName
kubectl explain pod.spec
通过nodeName 可以直接指定调度到那个节点

样例:
apiVersion: v1
kind: Pod
metadata:
name: demo-pod1
labels:
app: myapp
spec:
nodeName: k8snode02
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat
nodeSelector
通过node节点标签选择器,进行调度

样例:
# 节点打标签
kubectl label node k8snode01 dome=test
# dome yaml文件
apiVersion: v1
kind: Pod
metadata:
name: demo-pod1
labels:
app: myapp
spec:
nodeSelector:
dome: test
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat
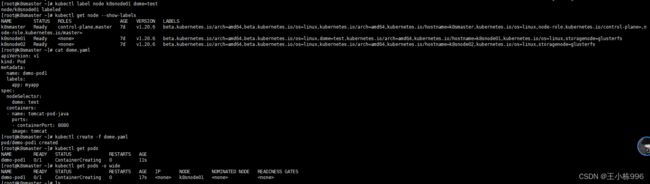
污点和容忍度
亲和性(affinity)
kubectl explain pod.spec.affinity
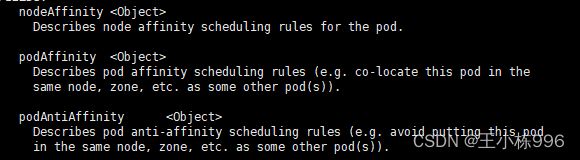
node节点亲和性(nodeAffinity)
Node节点亲和性针对的是pod和node的关系,Pod调度到node节点的时候匹配的条件
preferredDuringSchedulingIgnoredDuringExecution (软亲和性)
requiredDuringSchedulingIgnoredDuringExecution (硬亲和性,必须满足)
查看文档可以获得填写规则
kubectl explain pod.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchExpressions
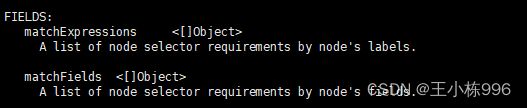
填写筛选条件 values 可以设置多个 满足其中一个即可。
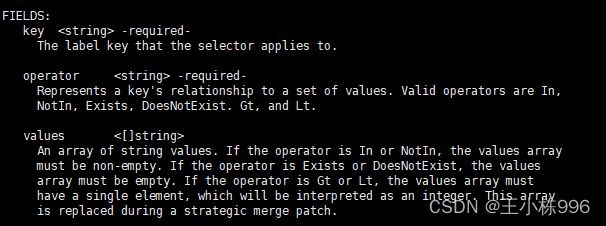
样例:根据节点标签dome=test完成调度
apiVersion: v1
kind: Pod
metadata:
name: demo-pod1
labels:
app: myapp
spec:
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dome
operator: In
values:
- test
- dev
Pod节点亲和性
kubectl explain pod.spec.affinity
pod 自身亲和性调度有两种表现形式
podAffinity (pod亲和性)
podAntiAffinity (pod反亲和性)

使用pod亲和性必须添加位置拓扑键 topologyKey,完成调度的参照。
样例:
节点亲和性
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
labels:
dome: aff
spec:
containers:
- name: tomcat-pod
ports:
- containerPort: 8080
image: tomcat
affinity:
# 节点亲和性
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# 列表字段有同级属性时,子属性多缩进两个空格
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp
# 位置拓扑键参照主机名调度
topologyKey: kubernetes.io/hostname
节点反亲和性:
apiVersion: v1
kind: Pod
metadata:
name: demo-pod2
labels:
dome2: noaff
spec:
containers:
- name: tomcat-pod2
ports:
- containerPort: 8080
image: tomcat
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp
topologyKey: kubernetes.io/hostname

污点
给节点选择的主动权,我们给节点打个污点,不能容忍的pod就运行不上来。
污点是定义在节点上的键值属性数据。taints是键值对数据。
污点等级
- NoSchedule (仅影响pod调度,后来的pod不容忍这个污点无法调度到该节点,已存在的pod不受影响)
- NoExecute(既影响现有pod也影响pod调度,节点中现有pod会被剔除)
-
PreferNoSchedule (最好不也可以是NoSchedule的柔性版本)
# 查看污点
kubectl describe nodes |grep Taints
# 给节点打污点
kubectl taint nodes 节点名 key=value:NoSchedule
# 删除污点
kubectl taint nodes 节点名 key-污点容忍
kubectl explain pod.spec.tolerations

如果 operator 的值是 Exists,则 value 属性可省略
如果 operator 的值是 Equal,则表示其 key 与 value 之间的关系是 equal(等于)
如果不指定 operator 属性,则默认值为 Equal
另外,还有两个特殊值:
空的 key 如果再配合 Exists 就能匹配所有的 key 与 value,也是是能容忍所有 node 的所有 Taints
空的 effect 匹配所有的 effect
样例:
apiVersion: v1
kind: Pod
metadata:
name: demo-pod1
labels:
app: myapp
spec:
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dome
operator: In
values:
- test
tolerations:
- key: "taint"
operator: "Equal"
value: "node02"
effect: "NoSchedule"
pod常见状态

pod的status简述了其生命周期的阶段。
挂起(pending): pod创建时调度条件不满足,多会处于此状态。
运行中(running): pod正常运行。
成功(succeeded): pod成功运行结束,并且不在重启
失败(failed): pod中容器异常终止,或者说容器以非0状态推出
未知(unknown):未知状态,pod所在节点kubelet故障未上报pod信息,
Evicted: 这种状态多见系统内存不足
CrashLoopBackOff: 容器启动又异常退出,重启次数过多也会出现此状态
Error 状态:Pod 启动过程中发生了错误
ready 代表pod的容器状态
问题排查命令
查看pod详情
kubectl describe pod pod名称 (如果不是默认空间需要指定空间名)
查看pod容器日志
kubectl logs test-host -c test-host
pod 重启策略
pod重启策略(RestartPolicy)应用于pod内的所有容器,pod所在的node上的kubelet会进行判断和重启操作。某个容器异常推出或健康检测失败会。kubelet会根据重启策略进行操作
pod的重启策略包括: Always、OnFailure、Never 默认是Always
Always:当容器失败时,由kubelet自动重启该容器。
OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
Never:不论容器运行状态如何,kubelet都不会重启该容器。
示例:
apiVersion: v1
kind: Pod
metadata:
name: test2
spec:
restartPolicy: Never
containers:
- name: test2
image: nginx
生命周期
init容器
pod中可以定义多个容器,部署应用的容器称为主容器。pod创建时可以有一个或多个先于主容器启动的init容器,init容器中的程序执行完了才会运行主容器,由于pod中共享存储,多用于主容器启动前的一些初始化工作
init容器与主容器区别:
1 init容器运行完,主容器才会启动。
2 每个init容器必须运行成功,才可以执行下一个init容器
3 如果init容器运行失败,pod会不断重启,知道运行成功,如果重启策略设置为Never,他不会重启
示例:
apiVersion: v1
kind: Pod
metadata:
name: init-test
spec:
initContainers:
- name: init-con
image: centos
command: ["sh", "-c", "echo '123' > /temdir/123"]
volumeMounts:
- mountPath: "/temdir"
name: vol
containers:
- name: zhu-con
image: centos
command: ["sh", "-c", "cat /temdir/123 && sleep 3600"]
volumeMounts:
- mountPath: "/temdir"
name: vol
volumes:
- name: vol
emptyDir: {}
容器探测
容器钩子
初始化容器启动之后,开始启动主容器,在主容器启动之前有一个post start hook(容器启动后钩子)和pre stop hook(容器结束前钩子),无论启动后还是结束前所做的事我们可以把它放两个钩子,这个钩子就表示用户可以用它来钩住一些命令,来执行它,做开场前的预设,结束前的清理,如awk有begin,end,和这个效果类似;
postStart:该钩子在容器被创建后立刻触发,通知容器它已经被创建。如果该钩子对应的hook handler执行失败,则该容器会被杀死,并根据该容器的重启策略决定是否要重启该容器,这个钩子不需要传递任何参数。
preStop:该钩子在容器被删除前触发,其所对应的hook handler必须在删除该容器的请求发送给Docker daemon之前完成。在该钩子对应的hook handler完成后不论执行的结果如何,Docker daemon会发送一个SGTERN信号量给Docker daemon来删除该容器,这个钩子不需要传递任何参数。
在k8s中支持两类对pod的检测,第一类叫做livenessprobe(pod存活性探测):
存活探针主要作用是,用指定的方式检测pod中的容器应用是否正常运行,如果检测失败,则认为容器不健康,那么Kubelet将根据Pod中设置的 restartPolicy来判断Pod 是否要进行重启操作,如果容器配置中没有配置 livenessProbe,Kubelet 将认为存活探针探测一直为成功状态。
第二类是状态检readinessprobe(pod就绪性探测):用于判断容器中应用是否启动完成,当探测成功后才使Pod对外提供网络访问,设置容器Ready状态为true,如果探测失败,则设置容器的Ready状态为false。
postStart:容器创建成功后,运行前的任务,用于资源部署、环境准备等。
preStop:在容器被终止前的任务,用于优雅关闭应用程序、通知其他系统等。
lifecycle


......
containers:
- image: sample:v2
name: war
lifecycle:
postStart:
exec:
command:
- “cp”
- “/sample.war”
- “/app”
prestop:
httpGet:
host: monitor.com
path: /waring
port: 8080
scheme: HTTP
......而在容器终止之前,发送HTTP警告请求到监控系统。
优雅的删除资源对象
当用户请求删除含有pod的资源对象时(如RC、deployment等),K8S为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S提供两种信息通知:
1)、默认:K8S通知node执行docker stop命令,docker会先向容器中PID为1的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送SIGKILL的系统信号强行kill掉进程。
2)、使用pod生命周期(利用PreStop回调函数),它执行在发送终止信号之前。默认情况下,所有的删除操作的优雅退出时间都在30秒以内。kubectl delete命令支持--grace-period=的选项,以运行用户来修改默认值。0表示删除立即执行,并且立即从API中删除pod。在节点上,被设置了立即结束的的pod,仍然会给一个很短的优雅退出时间段,才会开始被强制杀死。
spec:
containers:
- name: nginx-demo
image: centos:nginx
lifecycle:
preStop:
exec:
# nginx -s quit gracefully terminate while SIGTERM triggers a quick exit
command: ["/usr/local/nginx/sbin/nginx","-s","quit"]
ports:
- name: http
containerPort: 80pod阶段
当用户创建pod时,这个请求给apiserver,apiserver把创建请求的状态保存在etcd中;接下来apiserver会请求scheduler来完成调度,如果调度成功,会把调度的结果(如调度到哪个节点上了,运行在哪个节点上了,把它更新到etcd的pod资源状态中)保存在etcd中,一旦存到etcd中并且完成更新以后,节点上的kubelet通过apiserver当中的状态变化知道有一些任务被执行了,所以此时此kubelet会拿到用户创建时所提交的清单,这个清单会在当前节点上运行或者启动这个pod,如果创建成功或者失败会有一个当前状态,当前这个状态会发给apiserver,apiserver在存到etcd中;在这个过程中,etcd和apiserver一直在打交道,不停的交互,scheduler也参与其中,负责调度pod到合适的node节点上,这个就是pod的创建过程。
pod探测
三种探测方法:
1、ExecAction:在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
2、TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
3、HTTPGetAction:通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康
存活性探测livenessProbe
K8S提供livenessProbe来检测容器是否正常运行,许多应用程序经过长时间运行,最终过渡到无法运行的状态。这时候检测到容器异常,kubelet会根据重启策略重启容器。
示例:
Exec:
apiVersion: v1
kind: Pod
metadata:
name: liveness
spec:
containers:
- image: centos
name: test-liv
command: ["sh", "-c", "touch /123 && sleep 120 && rm -rf /123 && sleep 600"]
livenessProbe:
initialDelaySeconds: 10
periodSeconds: 5
exec:
command: ["sh", "-c", "cat /123"]
# #netstat -an|grep 80
# #echo $? 查看上面命令执行后的状态码
# 相关属性:
# initialDelaySeconds: Pod启动后首次进行检查的等待时间,单位“秒”。
# periodSeconds: 检查的间隔时间,默认为10s,单位“秒”。
# timeoutSeconds: 探针执行检测请求后,等待响应的超时时间,默认为1s,单位“秒”。
# successThreshold:连续探测几次成功,才认为探测成功,默认为 1,在 Liveness 探针中必须为1,最小值为1。
# failureThreshold: 探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod会被标记为未就绪,默认为 3,最小值为 tcp
apiVersion: v1
kind: Pod
metadata:
name: test-tcp
spec:
containers:
- name: test-tcp
image: nginx
# 存活性探测
livenessProbe:
# 容器启动多长时间后开始探测,默认是秒
initialDelaySeconds: 10
# 探测间隔时间,默认是秒
periodSeconds: 5
# 探测超时时间
timeoutSeconds: 10
# 探测端口
tcpSocket:
port: 80
# host 默认是本机
#TCP 检查方式和 HTTP 检查方式非常相似,在容器启动 initialDelaySeconds 参数设定的时间后,kubelet将发送第一个 livenessProbe 探针,尝试连接容器的 80 端口,如果连接失败则将杀死 Pod 重启容器。
![]()
http
apiVersion: v1
kind: Pod
metadata:
name: test-http
spec:
containers:
- name: test-http
image: nginx
livenessProbe:
initialDelaySeconds: 10
periodSeconds: 5
httpGet:
port: 80
# httpGet探测方式有如下可选的控制字段:
# scheme: 用于连接host的协议,默认为HTTP。
# host:要连接的主机名,默认为Pod IP,可以在http request head中设置host头部。
# port:容器上要访问端口号或名称。
# path:http服务器上的访问URI。
# httpHeaders:自定义HTTP请求headers,HTTP允许重复headers。![]()
就绪性探测readinessProbe
没有配置就绪性探测,pod中容器运行后默认成功。
就绪性探测和存活性探测配置方法类似。
区别在于:
存活性探测失败后会由kubelet根据重启策略操作pod.
就绪性探测失败后会从EndPoint中移除。
存活性探测和就绪性探测配合使用案例:
apiVersion: v1
kind: Pod
metadata:
name: test-live-read
spec:
containers:
- name: test-live-read
image: nginx
livenessProbe:
initialDelaySeconds: 10
periodSeconds: 5
httpGet:
port: 80
readinessProbe:
initialDelaySeconds: 10
periodSeconds: 5
httpGet:
port: 80
![]()