k8s 基于 cgroup 的资源限额(capacity enforcement)
k8s 基于 cgroup 的资源限额(capacity enforcement)
- 一、 K8S资源模型
-
- 1.1 Node资源抽象
-
- 1.1.1 Capacity
- 1.1.1 Allocatable
- 1.1.3 Allocated
- 1.2 Node资源预留
-
- 1.2.1 SystemReserved
- 1.2.2 KubeReserved
- 1.2.3 EvictionThreshold
- 1.2.4 Allocatable
- 1.3 kubelet 相关配置参数
- 二、k8s cgroup 层次设计
-
- 3.1 cgroup 基础
- 3.2 kubelet cgroup runtime driver
- 3.3 kubelet cgroup 层级
-
- 3.3.1 Container 级别 cgroup
- 3.3.2 Pod 级别 cgroup
- 3.3.3 QoS 级别 cgroup
- 3.3.4 Node 级别 cgroup
- 3.4 cgroup (v1) 配置目录
-
- 3.4.1 kubelet cgroup root
- 3.4.2 /kubepods(node 级别配置)
- 3.4.3 QoS 级别配置
- 3.4.4 Pod 级别配置
- 3.4.5 Container 级别配置
一、 K8S资源模型
- 资源抽象
- 抽象了 cpu/memory/device/hugepage 等资源类型;
- 抽象了 node 概念;
- 资源调度
- 抽象了 request 和 limit 两个概念,分别表示一个容器所需要的最小(request)和最大(limit)资源量;
- 调度算法根据各 node 当前可供分配的资源量(Allocatable),为容器选择合适的 node; 注意,k8s 的调度只看 requests,不看 limits。
- 资源enforcement
- 使用 cgroup 在多个层面确保 workload 使用的最大资源量不超过指定的 limits。
1.1 Node资源抽象
$ kubectl describe node
…
Capacity:
cpu: 48
mem-hard-eviction-threshold: 500Mi
mem-soft-eviction-threshold: 1536Mi
memory: 263192560Ki
pods: 256
Allocatable:
cpu: 46
memory: 258486256Ki
pods: 256
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 800m (1%) 7200m (15%)
memory 1000Mi (0%) 7324Mi (2%)
hugepages-1Gi 0 (0%) 0 (0%)
…
1.1.1 Capacity
这台 node 的总资源量(可以简单理解为物理配置), 例如上面的输出显示,这台 node 有 48CPU、256GB 内存等等。
1.1.1 Allocatable
可供 k8s 分配的总资源量, 显然,Allocatable 不会超过 Capacity,例如上面看到 CPU 就少了 2 个,只剩下 46 个(有时候Allocatable和Capacity回变现相同数值)。
1.1.3 Allocated
这台 node 目前已经分配出去的资源量,注意其中的 message 也说了,node 可能会超分,所以加起来可能会超过 Allocatable,但不会超过 Capacity。
Allocatable 不超过 Capacity,这个概念上也是很好理解的; 但具体是哪些资源被划出去,导致 Allocatable < Capacity 呢?
1.2 Node资源预留
由于每台 node 上会运行 kubelet/docker/containerd 等 k8s 相关基础服务, 以及 systemd/journald 等操作系统本身的进程,因此并不是一台 node 的所有资源都能给 k8s 创建 pod 用。 所以,k8s 在资源管理和调度时,需要把这些基础服务的资源使用量和 enforcement 单独拎出来。
为此,k8s 提出了 Node Allocatable Resources 提案,上面的 Capacity、Allocatable 等术语正是从这里来的。为此做出几点说明:
- 如果 Allocatable 可用,调度器会用 Allocatable,否则会用 Capacity;
- 用 Allocatable 是不超分,用 Capacity 是超分(overcommit);
计算公式:[Allocatable] = [NodeCapacity] - [KubeReserved] - [SystemReserved] - [HardEvictionThreshold]
分别介绍这几种类型。
1.2.1 SystemReserved
操作系统的基础服务,例如 systemd、journald 等,在 k8s 管理之外。 k8s 不能管理这些资源的分配,但是能管理这些资源的限额(enforcement),后面会看到。
1.2.2 KubeReserved
k8s 基础设施服务,包括 kubelet/docker/containerd 等等。 跟上面系统服务类似,k8s 不能管理这些资源的分配,但是能管理这些资源的限额(enforcement),后面会看到。
1.2.3 EvictionThreshold
当 node memory/disk 等资源即将耗尽时,kubelet 就开始按照 QoS 优先级(besteffort/burstable/guaranteed)驱逐 pod, eviction 资源就是为这个目的预留的。
1.2.4 Allocatable
可供 k8s 创建 pod 使用的资源。
1.3 kubelet 相关配置参数
资源预留相关的 kubelet 命令参数:
- –system-reserved=“”
- –kube-reserved=“”
- –qos-reserved=“”
- –reserved-cpus=“”
可以通过 kubelet 配置文件,例如,
$ cat /etc/kubernetes/kubelet/config
...
systemReserved:
cpu: "2" # 这就是为什么上面 describe node 输出中, Allocatable 比 Capacity 少 2 个 CPU 的原因,
memory: "4Gi" # 以及少 4GB 内存
是否需要对这些 reserved 资源用专门的 cgroup 来做资源限额,以确保彼此互不影响:
--kube-reserved-cgroup=""--system-reserved-cgroup=""
默认都是不启用。实际上也很难做到完全隔离。导致的后果就是系统进程和 pod 进程有可能相互影响, 例如,截至 v1.26,k8s 还不支持 IO 隔离,所以宿主机进程(例如 logrotate)IO 飙高, 或者某个 pod 进程执行 java dump 时,会影响这台 node 上所有 pod。
关于 k8s 资源模型就先介绍到这里,接下来进入本文重点,k8s 是如何用 cgroup 来限制 container、pod、基础服务等 workload 的资源使用量的(enforcement)。
二、k8s cgroup 层次设计
3.1 cgroup 基础
cgroup 是 Linux 内核基础设施,可以限制、记录和隔离进程组(process groups) 使用的资源量(CPU、内存、IO 等)。
cgroup 有两个版本,v1 和 v2,二者的区别可参考Control Group v2 (cgroupv2 权威指南)(KernelDoc, 2021) 。 目前 k8s 默认使用的是 cgroup v1,因此本文以 v1 为主。
cgroup v1 能管理很多种类的资源:
$ mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
k8s/kubelet 中只用到了 cpu/memory/pid/hugetlb 等几种类型。
3.2 kubelet cgroup runtime driver
k8s 通过配置 cgroup 来限制 container/pod 能使用的最大资源量。这个配置有两种实现方式, 在 k8s 中称为 cgroup runtime driver:
- cgroupfs:这种比较简单直接,kubelet 往 cgroup 文件系统中写 limit 就行了。 这也是目前 k8s 的默认方式。
- systemd:所有 cgroup-writing 操作都必须通过 systemd 的接口,不能手动修改 cgroup 文件。 适用于 k8s cgroup v2 模式。
3.3 kubelet cgroup 层级
如图所示:
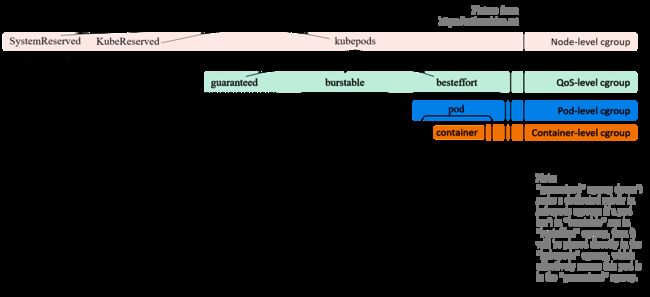
kubelet 会在 node 上创建了 4 个 cgroup 层级,从 node 的 root cgroup (一般都是 /sys/fs/cgroup)往下:
- Node 级别:针对 SystemReserved、KubeReserved 和 k8s pods 分别创建的三个 cgroup;
- QoS 级别:在 kubepods cgroup 里面,又针对三种 pod QoS 分别创建一个 sub-cgroup:
- Pod 级别:每个 pod 创建一个 cgroup,用来限制这个 pod 使用的总资源量;
- Container 级别:在 pod cgroup 内部,限制单个 container 的资源使用量。
为了使理解方便,接下来我们从最底层往最上层讲起。
3.3.1 Container 级别 cgroup
前面已经看到过,在创建 pod 时,可以直接在 container 级别设置 requests/limits:
apiVersion: v1
kind: Pod
spec:
containers:
- name: busybox
image: busybox
resources:
limits:
cpu: 500m
memory: "400Mi"
requests:
cpu: 250m
memory: "300Mi"
command: ["md5sum"]
args: ["/dev/urandom"]
kubelet 在这里做的事情很简单:创建 container 时,将 spec 中指定 requests/limits 传给 docker/containerd 等 container runtime。换句话说,底层能力都是 container runtime 提供的,k8s 只是通过接口把 requests/limits 传给了底层。
3.3.2 Pod 级别 cgroup
顾名思义,这种级别的 cgroup 是针对单个 pod 设置资源限额的。 这里有一个很明显但又很容易被忽视的问题:k8s requets/limits 模型的 requests/limits 是声明在 container 上,而不是 pod 上。 一个 pod 经常有多个容器,但 pod 的 requests/limits 并不是对它的 containers 简单累加。这是因为:
- 某些资源是这个 pod 的所有 container 共享的;
- 每个 pod 也有自己的一些开销,例如 sandbox container;
- Pod 级别还有一些内存等额外开销;
因此,为了防止一个 pod 的多个容器使用资源超标,k8s 引入了 引入了 pod-level cgroup,每个 pod 都有自己的 cgroup。 后面会介绍如何根据 containers requests/limits 计算一个 pod 的 requests/limits。
3.3.3 QoS 级别 cgroup
实际的业务场景需要我们能根据优先级高低区分几种 pod。例如,
- 高优先级 pod:无论何时,都应该首先保证这种 pod 的资源使用量;
- 低优先级 pod:资源充足时允许运行,资源紧张时优先把这种 pod 赶走,释放出的资源分给中高优先级 pod;
- 中优先级 pod:介于高低优先级之间,看实际的业务场景和需求。
k8s 针对这种需求提供了 cgroups-per-qos 选项:
// pkg/kubelet/apis/config/types.go
// Enable QoS based Cgroup hierarchy: top level cgroups for QoS Classes
// And all Burstable and BestEffort pods are brought up under their specific top level QoS cgroup.
CgroupsPerQOS bool
如果设置了 kubelet --cgroups-per-qos=true 参数(默认为 true), 就会将所有 pod 分成三种 QoS,优先级从高到低:Guaranteed > Burstable > BestEffort。 三种 QoS 是根据 requests/limits 的大小关系来定义的:
- Guaranteed: requests == limits, requests != 0, 即 正常需求 == 最大需求,换言之 spec 要求的资源量必须得到保证,少一点都不行;
- Burstable: requests < limits, requests != 0, 即 正常需求 < 最大需求,资源使用量可以有一定弹性空间;
- BestEffort: request == limits == 0, 创建 pod 时不指定 requests/limits 就等同于设置为 0,kubelet 对这种 pod 将尽力而为;有好处也有坏处:
- 好处:node 的资源充足时,这种 pod 能使用的资源量没有限制;
- 坏处:这种 pod 的 QoS 优先级最低,当 node 资源不足时,最先被驱逐。
每个 QoS 对应一个子 cgroup,设置该 QoS 类型的所有 pods 的总资源限额, 三个 cgroup 共同构成了 kubepods cgroup。 每个 QoS cgroup 可以认为是一个资源池,每个池子内的 pod 共享资源。
3.3.4 Node 级别 cgroup
所有的 k8s pod 都会落入 kubepods cgroup; 因此所有 k8s pods 占用的资源都已经能够通过 cgroup 来控制,剩下的就是那些 k8s 组件自身和操作系统基础服务所占用的资源了,即 KubeReserved 和 SystemReserved。 k8s 无法管理这两种服务的资源分配,但能管理它们的限额:有足够权限给它们创建并设置 cgroup 就行了。 但是否会这样做需要看 kubelet 配置:
--kube-reserved-cgroup=""--system-reserved-cgroup=""
默认为空,表示不创建,也就是系统组件和 pod 之间并没有严格隔离。 但概念上二者始终是存在的,因此前面几节介绍的内容构成了 k8s cgroup 的四个层级:
3.4 cgroup (v1) 配置目录
3.4.1 kubelet cgroup root
k8s 的 cgroup 路径都是相对于它的 cgroup root 而言的。 cgroup root 是个 kubelet 配置项,默认为空,表示使用底层 container runtime 的 cgroup root,一般是 /sys/fs/cgroup/。
3.4.2 /kubepods(node 级别配置)
cgroup v1 是按 resource controller 类型来组织目录的, 因此,/kubepods 会按 resource controller 对应到 /sys/fs/cgroup/{resource controller}/kubepods/,例如:
/sys/fs/cgroup/cpu/kubepods//sys/fs/cgroup/memory/kubepods/
前面已经介绍了每台 k8s node 的资源切分, 其中 Allocatable 资源量就是写到 kubepods 对应 cgroup 文件中, 例如 allocatable cpu 写到 /sys/fs/cgroup/kubepods/cpu.share。 这一工作是在 kubelet containerManager Start() 中完成的。
3.4.3 QoS 级别配置
QoS cgroup 是 /kubepods 的 sub-cgroup,因此路径是 /kubepods/{qos}/ ,具体来说,
- Burstable: 默认 /sys/fs/cgroup/{controller}/kubepods/burstable/;
- BestEffort: 默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/;
- Guaranteed:这个比较特殊,直接就是 /sys/fs/cgroup/{controller}/kubepods/, 没有单独的子目录。这是因为这种类型的 pod 都设置了 limits, 就无需再引入一层 wrapper 来防止这种类型的 pods 的资源使用总量超出限额。
3.4.4 Pod 级别配置
Pod 配置在 QoS cgroup 配置的下一级,
- Guaranteed Pod:默认 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/;
- Burstable Pod:默认 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/;
- BestEffort Pod:默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/。
3.4.5 Container 级别配置
Container 级别配置文件在 pod 的下一级:
- Guaranteed container:默认 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/{container_id}/;
- Burstable container:默认 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/{container_id}/;
- BestEffort container:默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/{container_id}/。