Kafka基于Zookeeper搭建高可用集群实战
1、前言
1.1 高可用的由来
为何需要Replication?
在Kafka在0.8以前的版本中,是没有Replication的,一旦某一个Broker宕机,则其上所有的Partition数据都不可被消费,这与Kafka数据持久性及Delivery Guarantee的设计目标相悖。同时Producer都不能再将数据存于这些Partition中。
如果Producer使用同步模式则Producer会在尝试重新发送message.send.max.retries(默认值为3)次后抛出Exception,用户可以选择停止发送后续数据也可选择继续发送。而前者会造成本应发往该Broker的数据的丢失,后者会造成数据的阻塞。
如果Producer使用异步模式,则Producer会尝试重新发送message.send.max.retries(默认值为3)次后记录该异常并继续发送后续数据,这会造成数据丢失并且用户只能通过日志发现该问题。
由此可见,在没有Replication的情况下,一旦某机器宕机或者某个Broker停止工作则会造成整个系统的可用性降低。随着集群规模的增加,整个集群中出现该类异常的几率大大增加,因此对于生产系统而言Replication机制的引入非常重要。
什么是Leader Election
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
因为需要保证同一个Partition的多个Replica之间的数据一致性(其中一个宕机后其它Replica必须要能继续服务并且不能造成数据重复也不能造成数据丢失)。如果没有一个Leader,所有Replica都可同时读/写数据,那就需要保证多个Replica之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证,大大增加了Replication实现的复杂性,同时也增加了出现异常的几率。而引入Leader后,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路),系统更加简单且高效。
1.2 相关术语
正文开始之前,我们先了解一下Kafka中涉及的相关术语:
Broker : 安装Kafka服务的那台集群就是一个broker(broker的id要全局唯一)
Producer:消息的生产者,负责将数据写入到broker中(push)
Consumer:消息的消费者,负责从kafka中读取数据(pull),老版本的消费者需要依赖zk,新版本的不需要
Topic:主题,相当于是数据的一个分类,不同topic存放不同的数据
partition:分区,是一个物理分区,一个分区就是一个文件,一个topic可以有一到多个分区,每一个分区都有自己的副本。
replication:副本,数据保存多少份(保证数据不丢)
Consumer Group:消费者组,一个topic可以有多个消费者同时消费,多个消费者如果在一个消费者组中,那么他们不能重复消费数据
Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
zookeeper是用来管理broker和consumer的,为分布式应用提供一致性服务的功能。
2、架构图
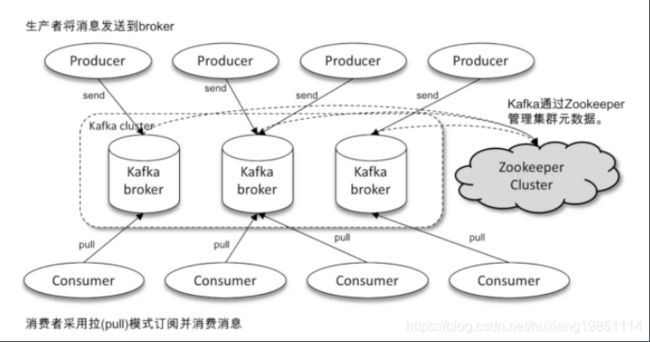
Producer: 生产者,也就是发送消息的一方。生产者负责创建消息,通过zookeeper找到broker,然后将其投递到 Kafka 中。
Consumer: 消费者,也就是接收消息的一方。通过zookeeper找对应的broker 进行消费,进而进行相应的业务逻辑处理。
Broker: 服务代理节点。对于 Kafka 而言,Broker 可以简单地看作一个独立的 Kafka 服务节点或 Kafka 服务实例。大多数情况下也可以将 Broker 看作一台 Kafka 服务器,前提是这台服务器上只部署了一个 Kafka 实例。一个或多个 Broker 组成了一个 Kafka 集群。一般而言,我们更习惯使用首字母小写的 broker 来表示服务代理节点
3、发送消息流程
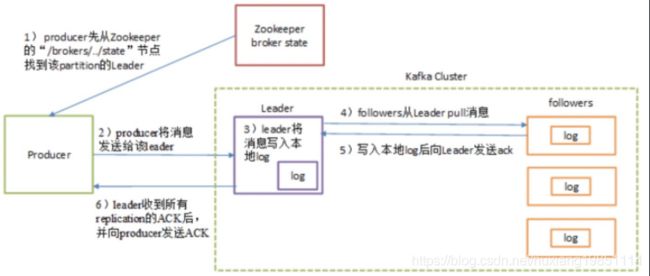
上图中关于多副本(Replication)副本机制如下图:
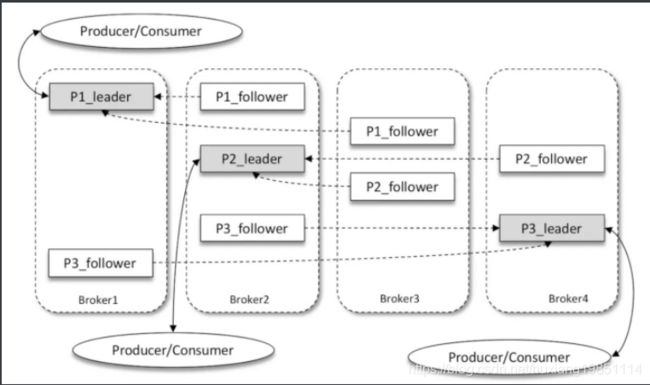
解释:
如上图所示,Kafka 集群中有4个 broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个 leader 副本和2个 follower 副本。生产者和消费者只与 leader 副本进行交互,而 follower 副本只负责消息的同步,很多时候 follower 副本中的消息相对 leader 副本而言会有一定的滞后。
4、部署kafka&zookeeper集群
4.1 准备工作
准备三台虚拟机,分别安装 kafka和zookeeper:
192.168.223.128
192.168.223.129
192.168.223.130
#三台机器之间需要使用域名相互通信,需要配置DNS域名解析:
vim /etc/hosts
#增加如下配置
192.168.223.128 ydt1
192.168.223.129 ydt2
192.168.223.130 ydt3
4.2 启动zookeeper集群
分别修改128,129,130节点zookeeper配置文件zoo.cfg,参考《从0开始搭建3个节点的Zookeeper集群及配置》
cd /usr/local/zookeeper-3.4.6/
#修改zoo.cfg文件配置
vim conf/zoo.cfg
---------------------------------#配置如下#----------------------------------
tickTime=2000 #作为 Zookeeper #服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime #时间就会发送一个心跳。
initLimit=10 #集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)
syncLimit=5 #集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tick#Time的数量)。
dataDir=/usr/local/zookeeper-3.4.6/data #数据持久化目录
dataLogDir=/usr/local/zookeeper-3.4.6/logs #日志目录
clientPort=2181 #客户端连接 Zookeeper 服务器的端口 用默认就行
server.1=192.168.223.128:4000:5000
server.2=192.168.223.129:4000:5000
server.3=192.168.223.130:4000:5000
#创建多个节点集群时,在dataDir目录下必须创建myid文件,myid文件用于zookeeper验证server序号#等,myid文件只有一行,并且为当前server的序号,例如server.1的myid就是1,server.2的myid就是#2等。
#server.A=B:C:D;其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C #表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 #Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 #Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 #B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号
------------------------------------------------------------------------------
#增加服务器号myid文件到data目录
vim data/myid
#192.168.223.128 ---1
#192.168.223.129 ---2
#192.168.223.130 ---3
依次启动三台zookeeper服务!
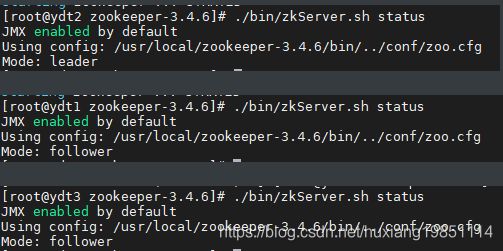
4.3 启动kafka集群
分别修改128,129,130三个节点的kafka配置文件server.properties
cd /usr/local/kafka
vim config/server.properties
#128配置
#集群中每个节点的唯一标
broker.id=1
#集群中每个节点的唯一标
listeners=PLAINTEXT://ydt1:9092
#集群中每个节点的唯一标
advertised.listeners=PLAINTEXT://ydt1:9092
# Zookeeper连接地址
zookeeper.connect=ydt1:2181,ydt2:2181,ydt3:2181
#129配置
broker.id=2
listeners=PLAINTEXT://ydt2:9092
advertised.listeners=PLAINTEXT://ydt2:9092
zookeeper.connect=ydt1:2181,ydt2:2181,ydt3:2181
#130配置
broker.id=3
listeners=PLAINTEXT://ydt3:9092
advertised.listeners=PLAINTEXT://ydt3:9092
zookeeper.connect=ydt1:2181,ydt2:2181,ydt3:2181
分别依次启动kafka服务():
cd /usr/local/kafka/
./bin/kafka-server-start.sh config/server.properties #控制台进程启动
./bin/kafka-server-start.sh -daemon config/server.properties #后台守护进程启动

4.4 测试
1)、在其中一台虚拟机(192.168.228.128)创建topic
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --create --bootstrap-server ydt1:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Created topic my-replicated-topic
在任意节点上查看该主题
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt2:9092 --topic my-replicated-topic
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
可以看到分区 2 的有2,3,1 三个副本,且三个副本都是可用副本,都在 ISR(in-sync Replica 同步副本) 列表中,其中 2 为首领副本,此时代表集群已经搭建成功。
2)、创建一个分区数为1,副本数为3的topic:
bin/kafka-topics.sh --zookeeper ydt1:2181 --create --replication-factor 3 --partitions 1 --topic first
执行发送数据到topic:
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-producer.sh --broker-list ydt1:9092 --topic first
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
>hello
>kafka
进入到log目录看看,在128,129,130节点都能看到该分区文件夹:
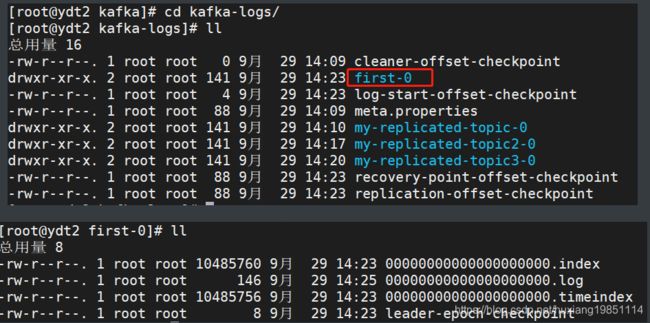
打开看到的都是一堆乱码:

我们可以通过kafka提供的脚本查看:
[root@ydt1 kafka]# ./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files kafka-logs/first-0/00000000000000000000.index
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Dumping kafka-logs/first-0/00000000000000000000.index
offset: 0 position: 0
[root@ydt1 kafka]# ./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files kafka-logs/first-0/00000000000000000000.log
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Dumping kafka-logs/first-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1601360714075 size: 73 magic: 2 compresscodec: NONE crc: 1546871644 isvalid: true
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 73 CreateTime: 1601360716608 size: 73 magic: 2 compresscodec: NONE crc: 200963068 isvalid: true
3)、生产者在一个topic上发布消息,然后通过客户端消费
#查看有哪些topic
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --list --bootstrap-server=ydt1:9092
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
__consumer_offsets
kafka1
kafka2
kafka3
kafka4
#生产者往kafka1主题发送消息
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-producer.sh --bootstrap-server=ydt1:9092 --topic kafka1
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
>he1
>he2
>he3
>he4
>he5
>he6
------------------------------消费者订阅(不分组)--------------------------------
#消费者订阅kafka1主题消息(消费者1)
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-consumer.sh --bootstrap-server=ydt2:9092 --topic kafka1
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
he1
he2
he3
he4
he5
he6
#消费者订阅kafka1主题消息(消费者2)
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-consumer.sh --bootstrap-server=ydt3:9092 --topic kafka1
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
he1
he2
he3
he4
he5
he6
-----------------------------消费者订阅(分组)------------------------
#现在我们看到的两个消费者都能看到相同的消息,那是因为没有设置为同一个消费者组,我们给这两个消费者设置一下消费者组:kafkaconsumer
#消费者1
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-consumer.sh --bootstrap-server=ydt1:9092 --topic kafka1 --group kafkaconsumer
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
he5
#消费者2
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-consumer.sh --bootstrap-server=ydt1:9092 --topic kafka1 --group kafkaconsumer
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
he1
he2
he3
he4
he6
#现在我们可以看到,消息只能被其中一个消费者消费!
5、 kafka集群管理控制台安装
5.1 安装配置
#下载安装包
wget https://github.com/yahoo/kafka-manager/archive/2.0.0.2.zip
#解压
unzip 2.0.0.2.zip
#重命名(纯粹就是为了容易识别)
mv CMAK-2.0.0.2/ kafka-manager-2.0.0.2
#sbt编译(需要下载一些jar包,很慢,勿慌!出去抽半包烟!当然你也可以配置阿里云镜像,自行百度)
cd /usr/local/kafka-manager-2.0.0.2
./sbt clean dist
#配置
#在解压后的conf目录中打开 application.conf文件,修改其中的zookeeper配置信息,vim conf/application.conf:
kafka-manager.zkhosts="192.168.223.128:2181"
#启动
#在上面sbt编译后,会给你生成一个kafka-manager-2.0.0.2.zip包,解压之:
cd /usr/local/kafka-manager-2.0.0.2/target/universal
unzip kafka-manager-2.0.0.2.zip
cd /usr/local/kafka-manager-2.0.0.2/target/universal/kafka-manager-2.0.0.2/
#找到bin目录下的kafka-manager启动脚本文件执行
./bin/kafka-manager
#开启端口
firewall-cmd --zone=public --add-port=9000/tcp --permanent ----其他端口照做
#重启防火墙
firewall-cmd --reload
#访问:
http://192.168.223.128:9000
SBT编译
Kafka-manager启动:
5.2 控制台访问
新增集群管理:
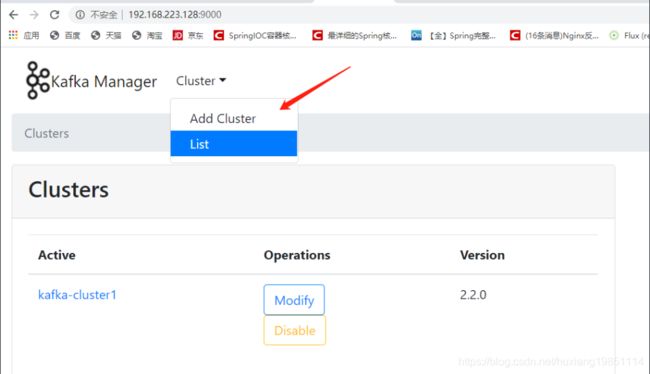
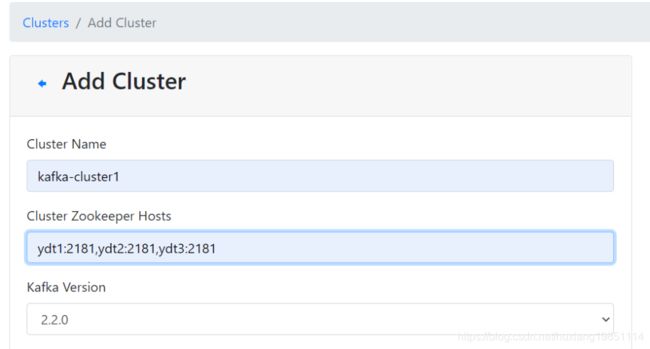
点击保存时会提示一些集群管理线程池大小设置,都设置为大于2的数字就行!
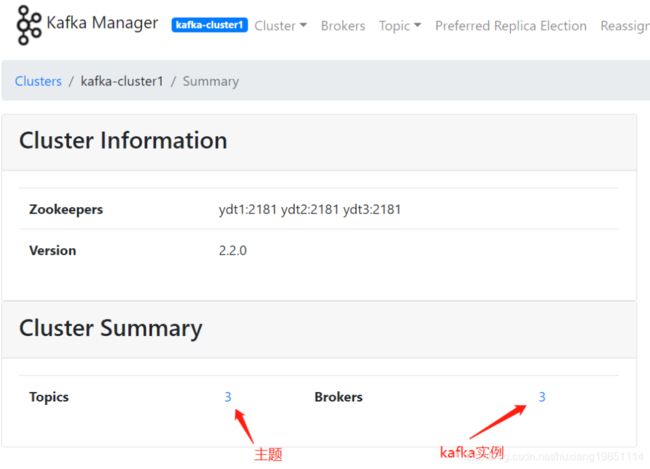
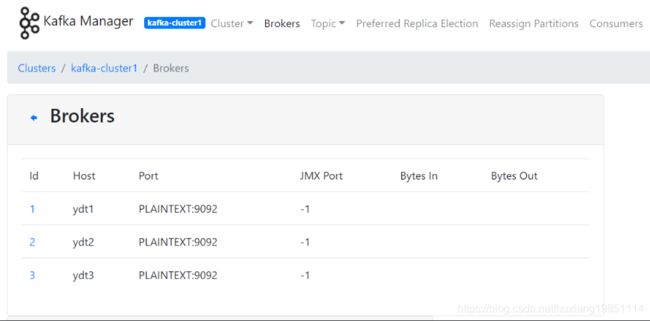
主题管理
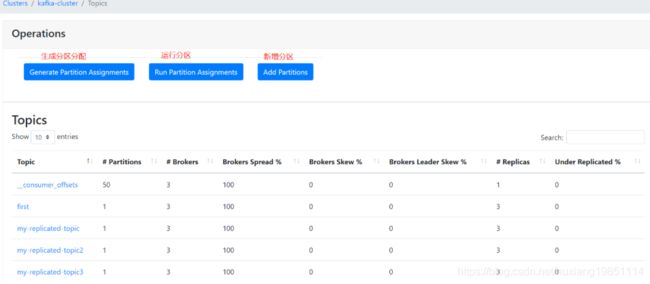
Kafka Manager 指标:
Brokers Spread:看作broker使用率,如kafka集群9个broker,某topic分片副本数为7(说明只会分配到7个broker),则broker spread: 7 / 9 = 77%
Brokers Skew:partition是否存在倾斜,如kafka集群9个broker,某topic有18个partition,正常每个broker应该2个partition。若其中有3个broker上的partition数>2,则broker skew: 3 / 9 = 33%,如果分片副本数小于集群broker数或者本身就不能均衡,则不存在倾斜一说!
Brokers Leader Skew:leader partition是否存在倾斜,如kafka集群9个broker,某topic有18个partition,则正常每个broker有2个leader partition。若其中一个broker有0个leader partition,一个有4个leader partition,则broker leader skew: 2 / 9 = 22%;由于kafka所有读写都在leader上进行, broker leader skew会导致不同broker的读写负载不均衡,配置参数 auto.leader.rebalance.enable=true 可以使kafka每5min自动做一次leader的rebalance,消除这个问题。
6、Java API操作
6.1 本地DNS映射配置
因为本地也使用域名配置,所以也需要域名映射配置:
#C:\Windows\System32\drivers\etc\hosts 增加如下配置
192.168.223.128 ydt1
192.168.223.129 ydt2
192.168.223.130 ydt3
6.2 pom依赖
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.12artifactId>
<version>2.5.0version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.5.0version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-streamsartifactId>
<version>2.5.0version>
dependency>
dependencies>
6.3 生产者类
package com.ydt.kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* 消息生产者
*
*/
public class ClusterProducer extends KafkaProducer {
public ClusterProducer(Properties properties) {
super(properties);
}
public static void main(String[] args) throws Exception {
Properties props = new Properties();
// kafka servers
props.put("bootstrap.servers", "ydt1:9092,ydt2:9092,ydt3:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
// topic 分组
props.put("client.id", "DemoProducer");
props.put("buffer.memory", 33554432);
// 序列化工具
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 序列化工具
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
}
}
6.4 消费者类
package com.ydt.kafka;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
/**
* 消费者
*/
public class ClusterConsumer extends KafkaConsumer {
public ClusterConsumer(Properties properties) {
super(properties);
}
public static void main(String[] args) {
Properties props = new Properties();
// kafka servers
props.put("bootstrap.servers", "ydt1:9092,ydt2:9092,ydt3:9092");
// group
props.put("group.id", "DemoConsumer");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅的topic
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
// 超时时间 ms
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("测试 offset = %d, key = %s, value = %s%n", record.offset(), record.key(),
record.value());
}
}
}
7、分区/片备份
在 Kafka 集群中,我们可以对每个Topic设置一个或多个分区,并为该 Topic 下每个分区指定备份数。这部分元数据信息都是存放在 Zookeeper 上,我们可以使用ZooInspector工具来查看元数据信息。通过 log.dirs 属性控制消息存放路径,每个分区对应一个文件夹,文件夹命名方式为:TopicName-PartitionIndex,该文件夹下存放这该分区的所有消息和索引文件,如下图所示:

包括一个日志数据文件和两个索引文件;
分区机制是kafka实现高吞吐的秘密武器,但这个武器用得不好的话也容易出问题!我们这里主要介绍分区的机制以及相关的部分配置
从数据组织形式来说,kafka有三层形式,kafka有多个主题,每个主题有多个分区,每个分区又有多条消息。而每个分区可以分布到不同的机器上,这样一来,从服务端来说,分区可以实现高伸缩性,以及负载均衡,动态调节的能力。
当然多分区就意味着每条消息都难以按照顺序存储,那么是不是意味着这样的业务场景kafka就无能为力呢?不是的,最简单的做法可以使用单个分区,单个分区,所有消息自然都顺序写入到一个分区中,就跟顺序队列一样了。而复杂些的,还有其他办法,那就是使用按键保存策略,将需要顺序保存的消息存储到单独的分区,其他消息存储其他分区。
我们可以通过replication-factor指定创建topic时候所创建的分区副本数。
./bin/kafka-topics.sh --create --bootstrap-server ydt1:9092 --replication-factor 1 --partitions 1 --topic test
比如这里就是创建了一个叫做“test”的主题,他有1个分区,每个分区只有一个备份(其实就是分区本身)
以下是一些分区备份需要的注意事项:
1)、分区数可以大于节点数,但是副本数不能大于集群broker数量
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --create --bootstrap-server ydt1:9092 --replication-factor 4 --partitions 4 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Error while executing topic command : org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3.
[2020-08-17 18:36:28,528] ERROR java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3.
at org.apache.kafka.common.internals.KafkaFutureImpl.wrapAndThrow(KafkaFutureImpl.java:45)
at org.apache.kafka.common.internals.KafkaFutureImpl.access$000(KafkaFutureImpl.java:32)
at org.apache.kafka.common.internals.KafkaFutureImpl$SingleWaiter.await(KafkaFutureImpl.java:89)
at org.apache.kafka.common.internals.KafkaFutureImpl.get(KafkaFutureImpl.java:260)
at kafka.admin.TopicCommand$AdminClientTopicService.createTopic(TopicCommand.scala:244)
at kafka.admin.TopicCommand$TopicService.createTopic(TopicCommand.scala:196)
at kafka.admin.TopicCommand$TopicService.createTopic$(TopicCommand.scala:191)
at kafka.admin.TopicCommand$AdminClientTopicService.createTopic(TopicCommand.scala:219)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:62)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
Caused by: org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3.
(kafka.admin.TopicCommand$)
2)、创建主题时分区数量最好为集群broker的整数倍,以便数据均匀的分布且分区数不要过多。
分区越多,所需要消耗的资源就越多。甚至如果足够大的时候,还会触发到操作系统的一些参数限制。比如linux中的文件描述符限制,一般在创建线程,创建socket,打开文件的场景下,linux默认的文件描述符参数,只有1024,超过则会报错。
[root@ydt2 kafka]# ulimit -n
1024
很遗憾,暂时没有一个标准的分区数量!
因为每个业务场景都不同,只能结合具体业务来看。假如每秒钟需要从主题写入和读取1GB数据,而一个消费者1秒钟最多处理50MB的数据,那么这个时候就可以设置20-25个分区,当然还要结合具体的物理资源情况。
如果无法估算出大概的处理速度和时间,那么就用基准测试来测试:创建不同分区的topic,逐步压测测出最终的结果。如果实在是懒得测,那比较无脑的确定分区数的方式就是broker机器数量的2~3倍。
3)、分区数可以增加,不能减少,并且新增分区不会有数据
#创建topic test,3个分区,3个备份
./bin/kafka-topics.sh --create --bootstrap-server ydt1:9092 --replication-factor 3 --partitions 3 --topic test
#查看topic详情,可以看到如下信息,第一个broker上存放0分片leader,备份节点在第二和第三个broker上
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt1:9092 --topic test OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: test PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: test Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
#增加一个分区,可以看到新增的分区3,和分区0,都使用了同一个leader:0,无形中该leader所在broker承载的压力加大
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --alter --bootstrap-server ydt1:9092 --partitions 4 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: test PartitionCount: 4 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: test Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test Partition: 3 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
4)、消息是追加到分区的,所以多个分区顺序写磁盘(轮询策略)的总效率甚至比其他消息中间件随机写内存还要高,这也是Kafka高吞吐率的原因
磁盘和内存写入速度:

写入测试:
#使用轮询策略将h1,h2,h3分别写入三个分区,然后从h4开始又进行轮询
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-producer.sh --bootstrap-server ydt1:9092 --topic test1
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
>h1
>h2
>h3
>h4
#kafka默认是实现了两个策略,没指定key的时候就是轮询策略,有的话那就使用按键保存策略了,这个请参考生产者往主题写入数据
5)、一个分区可以有多个副本,这些副本保存在不同的broker上,每个分区的副本中都会有一个作为leader,当一个broker挂掉时,leader在这台broker上的分区都会变得不可用,kafka会自动移除leader,再在其他可用副本列表中(Replicas)选一个作为新leader
#停掉集群中一台broker之前,查看topic信息
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: tes2 PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: tes2 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: tes2 Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: tes2 Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
#停掉集群中某一台broker,继续查看topic信息
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: tes2 PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: tes2 Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0,2
Topic: tes2 Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2
Topic: tes2 Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,0
#再次将该broker启动后,该节点原先leader分片不能够再次恢复leader角色
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: tes2 PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: tes2 Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0,2,1
Topic: tes2 Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: tes2 Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,0,1
6)、增加分区备份可以提供集群的吞吐量和可用性,但是也要注意集群的总分区数过多,会增加不可用及延迟的风险(人数越多,选举越慢;分组越多,leader挂掉的次数越多)
7)、Kafka分区选举机制不是常见的多数选举,而是会在zookeeper上针对每一个Topic维护一个称为ISR(已同步可用副本)集合,只有这个ISR列表里面的副本才有资格称为leader(直接使用Replicas里面第一个,以次类推)
8)、新增加的broker没有参与Topic分区,需要通过分区重新分配来分配数据
#删除topic test
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --delete --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
#创建topic test
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --create --bootstrap-server ydt1:9092 --replication-factor 3 --partitions 3 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Created topic test.
#往分区插入四条数据
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-console-producer.sh --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
>h1
>h2
>h3
>h4
#给该topic增加一个分区,新增分区3和分区0的leader都是borker节点0上,导致压力过大
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --alter --bootstrap-server ydt1:9092 --partitions 4 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: test PartitionCount: 4 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: test Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: test Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: test Partition: 3 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
#现在我们新增一台虚拟机,加入kafka集群,使得上一步新增节点均匀分布到每一个broker
1)、将之前集群的/etc/hosts增加一个域名映射 192.168.223.131 ydt4,然后重新启动网卡:service network restart;如果你新增主机使用ip配置,那么该步骤忽略!
2)、新增机器也配置本地DNS域名映射:
192.168.223.128 ydt1
192.168.223.129 ydt2
192.168.223.130 ydt3
192.168.223.131 ydt4
#我们发现集群新增broker并没有改变现在的分片分布状态:
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-topics.sh --describe --bootstrap-server ydt1:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Topic: test PartitionCount: 4 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: test Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: test Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: test Partition: 3 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
#我们需要对分片重新进行分配
#1)、声明那些topic需要重新分区
vim reset.json
----------------输入如下内容--------------------------
{
"topics":[{"topic":"test"}],
"version":1
}
-------------------------------------
#执行kafka-reassign-partitions.sh脚本生成分配规则候选项:
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-reassign-partitions.sh --zookeeper ydt1:2181 --topics-to-move-json-file reset.json --broker-list "0,1,2,3" --generate
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Current partition replica assignment
{"version":1,"partitions":[
{"topic":"test","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"test","partition":1,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"test","partition":0,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"test","partition":3,"replicas":[0,2,1],"log_dirs":["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[
{"topic":"test","partition":1,"replicas":[2,1,3],"log_dirs":["any","any","any"]},{"topic":"test","partition":3,"replicas":[0,3,1],"log_dirs":["any","any","any"]},{"topic":"test","partition":0,"replicas":[1,0,2],"log_dirs":["any","any","any"]},{"topic":"test","partition":2,"replicas":[3,2,0],"log_dirs":["any","any","any"]}]}
#2)、定义一个分片规则
#根据上一步候选分片规则选择进行重新分片
vim result.json
------------------------输入分片规则json数据--------------------------
{"version":1,"partitions":[
{"topic":"test","partition":1,"replicas":[2,1,3],"log_dirs":["any","any","any"]}, {"topic":"test","partition":3,"replicas":[0,3,1],"log_dirs":["any","any","any"]}, {"topic":"test","partition":0,"replicas":[1,0,2],"log_dirs":["any","any","any"]}, {"topic":"test","partition":2,"replicas":[3,2,0],"log_dirs":["any","any","any"]}]}
----------------------------------------------------------------------------------------
#重新分片:
[root@ydt1 kafka_2.12-2.5.0]# ./bin/kafka-reassign-partitions.sh --zookeeper ydt1:2181 --reassignment-json-file result.json --execute
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Current partition replica assignment
{"version":1,"partitions":[
{"topic":"test","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"test","partition":1,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"test","partition":0,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"test","partition":3,"replicas":[0,2,1],"log_dirs":["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
9)、消费者分区分配策略和自定义分配策略
/**
* partition.assignment.strategy
*/
public static final String PARTITION_ASSIGNMENT_STRATEGY_CONFIG = "partition.assignment.strategy";
private static final String PARTITION_ASSIGNMENT_STRATEGY_DOC = "A list of class names or class types, ordered by preference, of supported assignors responsible for the partition assignment strategy that the client will use to distribute partition ownership amongst consumer instances when group management is used. Implementing the org.apache.kafka.clients.consumer.ConsumerPartitionAssignor interface allows you to plug in a custom assignment strategy.";
Range 范围分区(默认的)
假如有10个分区,3个消费者,把分区按照序号排列0,1,2,3,4,5,6,7,8,9;消费者为C1,C2,C3,那么用分区数除以消费者数来决定每个Consumer消费几个Partition,除不尽的前面几个消费者将会多消费一个 最后分配结果如下
C1:0,1,2,3 C2:4,5,6 C3:7,8,9
如果有11个分区将会是:
C1:0,1,2,3 C2:4,5,6,7 C3:8,9,10
假如我们有两个主题T1,T2,分别有10个分区,最后的分配结果将会是这样:
C1:T1(0,1,2,3) T2(0,1,2,3) C2:T1(4,5,6) T2(4,5,6) C3:T1(7,8,9) T2(7,8,9)
在这种情况下,C1多消费了两个分区
RoundRobin 轮询分区
把所有的partition和consumer列出来,然后轮询consumer和partition,尽可能的让把partition均匀的分配给consumer
假如有3个Topic T0(三个分区P0-0,P0-1,P0-2),T1(两个分区P1-0,P1-1),T2(四个分区P2-0,P2-1,P2-2,P2-3)
有三个消费者:C0(订阅了T0,T1),C1(订阅了T1,T2),C2(订阅了T0,T2)
那么分区过程如下图所示 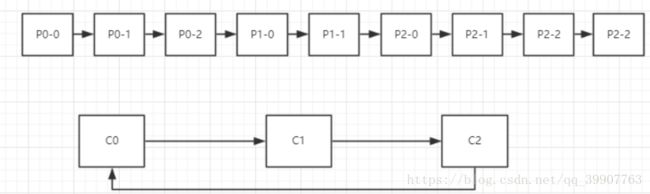
分区将会按照一定的顺序排列起来,消费者将会组成一个环状的结构,然后开始轮询。 P0-0分配给C0 P0-1分配给C1但是C1并没订阅T0,于是跳过C1把P0-1分配给C2, P0-2分配给C0 P1-0分配给C1, P1-1分配给C0, P2-0分配给C1, P2-1分配给C2, P2-2分配给C1, p2-3分配给C2
C0: P0-0,P0-2,P1-1 C1:P1-0,P2-0,P2-2 C2:P0-1,P2-1,P2-3
什么时候重新触发分区分配策略: 1.同一个Consumer Group内新增或减少Consumer 2.Topic分区发生变化
8、集群监控
使用kafka做消息队列中间件时,为了实时监控其性能时,免不了要使用jmx调取kafka broker的内部数据,不管是自己重新做一个kafka集群的监控系统,还是使用一些开源的产品,比如yahoo的kafka manager, 其都需要使用jmx来监控一些敏感的数据
8.1 开启JMX端口
#vim /bin/kafka-server-start.sh
--------------------------------------------
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999" #增加此行,开启JMX端口
fi
8.2 Kafka Manager加载JMX监控信息
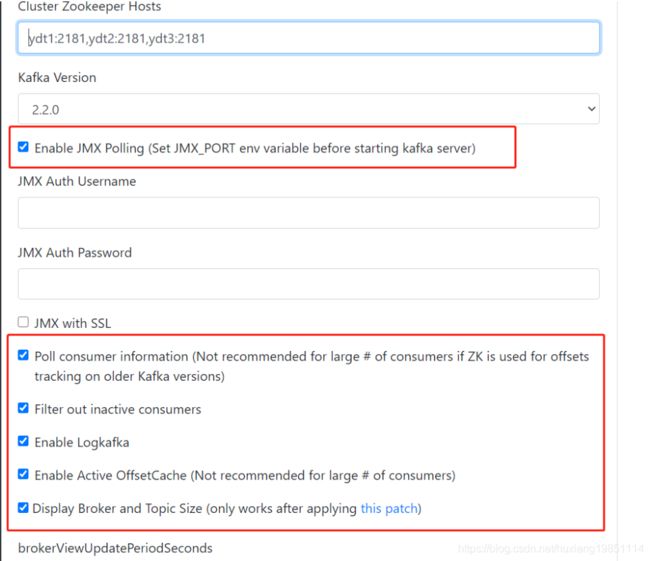
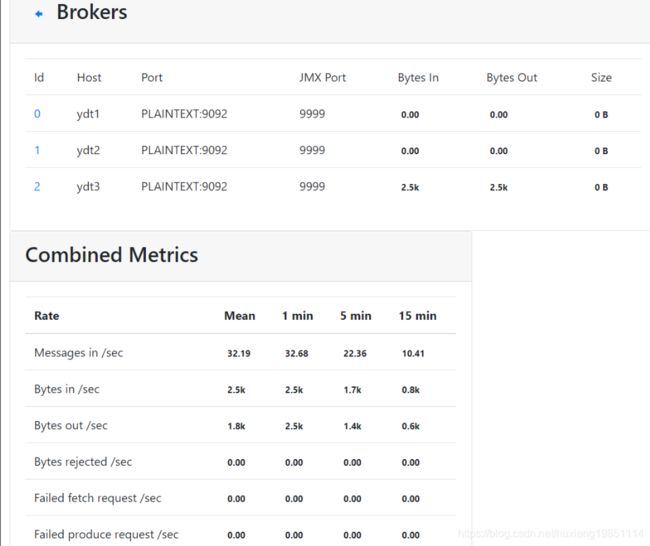
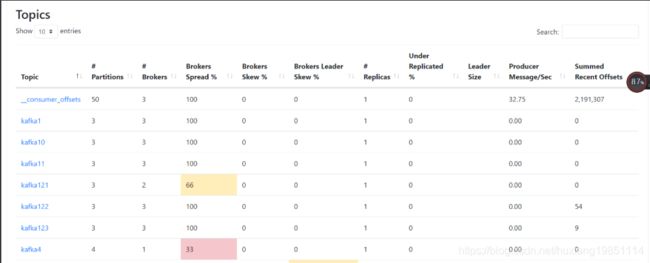
8.3 JDK自带JMX API
如果你们公司逼格很高,需要自己来实现一些定制化的监控数据,那么可以使用JMX API
使用JDK自带的JConsole程序,连接kafka的JMX远程监控:
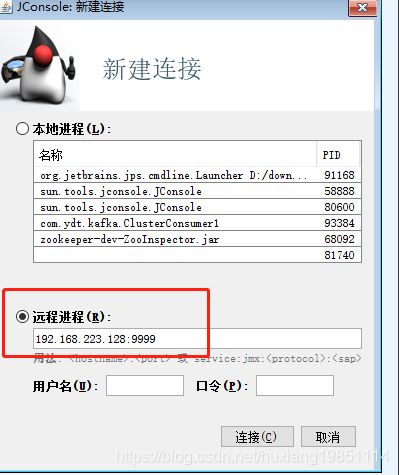
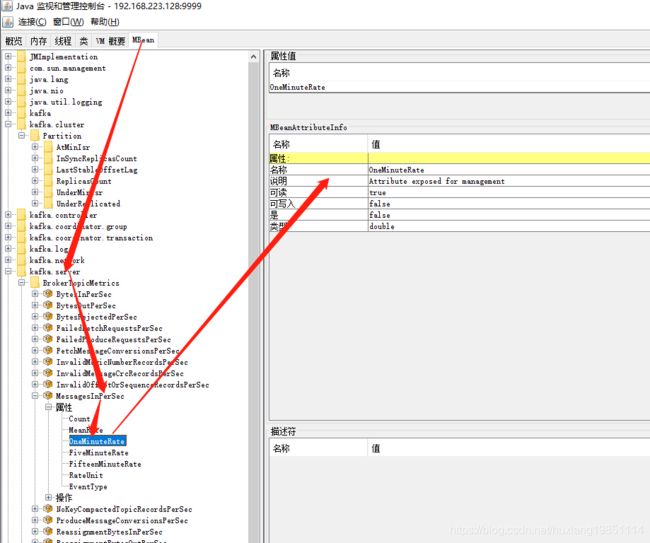
比如我们想获取如下监控信息:
package com.ydt.kafka;
import javax.management.MBeanServerConnection;
import javax.management.ObjectName;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
public class JMXTest {
public static void main(String[] args) {
String jmxURL = "service:jmx:rmi:///jndi/rmi://192.168.223.128:9999/jmxrmi";
try {
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
JMXConnector connector = JMXConnectorFactory.connect(serviceURL,null);
MBeanServerConnection conn = connector.getMBeanServerConnection();
if(conn == null){
System.out.println("please check kafka is opened the jmx port");
return;
}
System.out.println("connection is success !");
ObjectName objectName = new ObjectName("kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec");
System.out.println(conn.getAttribute(objectName, "OneMinuteRate"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
9、消费规则
先看下图:
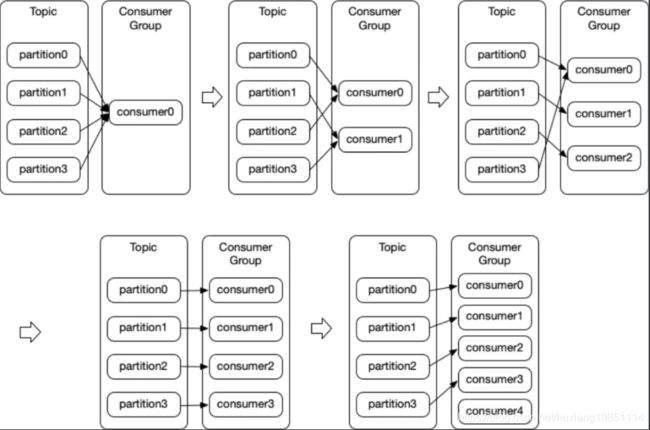
1)、当消费者组只有一个消费者时,所有的分片数据都被她消费
2)、当消费者组中有多个消费者,但是消费者数据小于分区数量时,一个消费者可能会消费多个分区数据
3)、当消费者组中消费者数量跟分片数量相等时,每一个消费者消费一个分片数据
4)、当消费者组中消费者数量大于主题分片数量时,有闲置的消费者