Pytorch常用的函数(四)深度学习中常见的上采样方法总结
Pytorch常用的函数(四)深度学习中常见的上采样方法总结
我们知道在深度学习中下采样的方式比较常用的有两种:
-
池化
-
步长为2的卷积
而在上采样过程中常用的方式有三种:
-
插值
-
反池化
-
反卷积
不论是语义分割、目标检测还是三维重建等模型,都需要将提取到的高层特征进行放大,此时就需要对feature map进行上采样。
1、插值算法
插值算法中常用的方法有最近邻插值(nearest interpolation)、单线性插值(linear interpolation)、双线性插值(bilinear interpolation)等,这里只讲解最常用的最邻近插值法和双线性插值法。
1.1 pytorch中相关api
1.1.1 torch.nn.Upsample
在pytorch中,插值算法的相关api如下:
torch.nn.Upsample(
size=None,
scale_factor=None,
mode='nearest',
align_corners=None,
recompute_scale_factor=None
)
参数说明:
①size:可以用来指定输出空间的大小,默认是None;
②scale_factor:比例因子,比如scale_factor=2,意味着将输入图像上采样2倍,默认是None;
③mode:用来指定上采样算法,有’nearest’、 ‘linear’、‘bilinear’、‘bicubic’、‘trilinear’,默认是’nearest’。
④align_corners:如果True,输入和输出张量的角像素对齐,从而保留这些像素的值,默认是False。
⑤recompute_scale_factor:
-
如果recompute_scale_factor是True,则必须传入scale_factor并且scale_factor用于计算输出大小。计算出的输出大小将用于推断插值的新比例。请注意,当scale_factor为浮点数时,由于舍入和精度问题,它可能与重新计算的scale_factor不同。
-
如果recompute_scale_factor是False,那么size或scale_factor将直接用于插值。
1.1.2 torch.nn.functional.interpolate
或者用如下api:
torch.nn.functional.interpolate(
input,
size=None,
scale_factor=None,
mode='nearest',
align_corners=None,
recompute_scale_factor=None,
antialias=False
)
参数说明:
①input:输入张量;
②size:可以用来指定输出空间的大小,默认是None;
③scale_factor:比例因子,比如scale_factor=2意味着将输入图像上采样2倍,默认是None;
④mode:用来指定上采样算法,有’nearest’、 ‘linear’、‘bilinear’、‘bicubic’、‘trilinear’,默认是’nearest’。
④align_corners:如果True,输入和输出张量的角像素对齐,从而保留这些像素的值,默认是False。
⑤recompute_scale_factor:
-
如果recompute_scale_factor是True,则必须传入scale_factor并且scale_factor用于计算输出大小。计算出的输出大小将用于推断插值的新比例。请注意,当scale_factor为浮点数时,由于舍入和精度问题,它可能与重新计算的scale_factor不同。
-
如果recompute_scale_factor是False,那么size或scale_factor将直接用于插值。
1.2 最邻近插值法
对于未知位置,直接采用与它最邻近的像素点的值为其赋值。
最近邻插值法的计算速度很快,但是新图像局部破坏了原图的渐变关系。
import torch
input = torch.tensor([[10, 20] ,[30, 40]], dtype=torch.float32).view(1, 1, 2, 2)
print('原始输入:\n', input)
# 1、最近邻插值
# 对于未知位置,直接采用与它最邻近的像素点的值为其赋值
# 最近邻插值法的计算速度很快,但是新图像局部破坏了原图的渐变关系。
nearest = torch.nn.Upsample(scale_factor=2, mode='nearest')
print('最近邻插值:\n', nearest(input))
原始输入:
tensor([[[[10., 20.],
[30., 40.]]]])
最近邻插值:
tensor([[[[10., 10., 20., 20.],
[10., 10., 20., 20.],
[30., 30., 40., 40.],
[30., 30., 40., 40.]]]])
1.3 双线性插值法
1.3.1 双线性插值法计算过程
双线性插值(bilinear interpolation)又称一阶插值,根据离待插值最近的2*2=4个已知值来计算待插值。
每个已知值的权重由与待插值的距离决定,距离越近权重越大。
双线性插值是分别在两个方向计算了共3次单线性插值。
计算过程如下:
- 按x轴方向进行两次单线性插值
按 x 轴方向进行两次单线性插值分别得到蓝点 R 1 和 R 2 的像素值 P 1 = f ( R 1 ) 和 P 2 = f ( R 2 ) ; 注意:此时 Q 需要加 f 函数 , 实质上下方图是: 3 维图像的映射在平面空间 P 1 = f ( R 1 ) = x 2 − x x 2 − x 1 f ( Q 11 ) + x − x 1 x 2 − x 1 f ( Q 21 ) P 2 = f ( R 2 ) = x 2 − x x 2 − x 1 f ( Q 12 ) + x − x 1 x 2 − x 1 f ( Q 22 ) 按x轴方向进行两次单线性插值分别得到蓝点R_{1}和R_{2}的像素值P_1=f(R_{1})和P_2=f(R_{2});\\ 注意:此时Q需要加f函数,实质上下方图是:3维图像的映射在平面空间\\ P_1=f(R_1)=\frac{x2-x}{x2-x1}f(Q_{11})+\frac{x-x1}{x2-x1}f(Q_{21}) \\ P_2=f(R_2)=\frac{x2-x}{x2-x1}f(Q_{12})+\frac{x-x1}{x2-x1}f(Q_{22}) 按x轴方向进行两次单线性插值分别得到蓝点R1和R2的像素值P1=f(R1)和P2=f(R2);注意:此时Q需要加f函数,实质上下方图是:3维图像的映射在平面空间P1=f(R1)=x2−x1x2−xf(Q11)+x2−x1x−x1f(Q21)P2=f(R2)=x2−x1x2−xf(Q12)+x2−x1x−x1f(Q22) - 按y轴方向进行一次单线性插值
按 y 轴方向进行一次单线性插值即可得到点 P 的像素值 f ( P ) f ( P ) = y 2 − y y 2 − y 1 f ( R 1 ) + y − y 1 y 2 − y 1 f ( R 2 ) 按y轴方向进行一次单线性插值即可得到点P的像素值f(P) \\ f(P)=\frac{y2-y}{y2-y1}f(R_{1})+\frac{y-y1}{y2-y1}f(R_{2}) 按y轴方向进行一次单线性插值即可得到点P的像素值f(P)f(P)=y2−y1y2−yf(R1)+y2−y1y−y1f(R2)
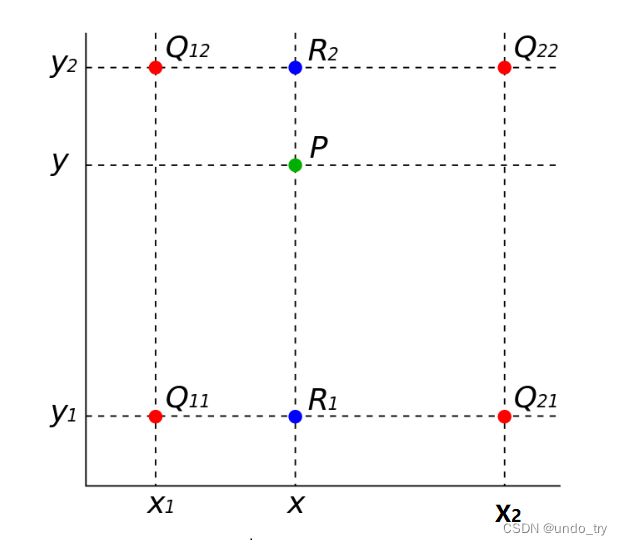
为了方便理解,我们再从三维进行理解:
-
按x轴方向进行两次单线性插值
按 x 轴方向进行两次单线性插值分别得到蓝点 R 1 和 R 2 的像素值 P 1 = f ( R 1 ) 和 P 2 = f ( R 2 ) ; f ( Q 11 ) = P 11 , f ( Q 21 ) = P 21 P 1 = f ( R 1 ) = x 2 − x x 2 − x 1 P 11 + x − x 1 x 2 − x 1 P 21 另外, f ( Q 12 ) = P 12 , f ( Q 23 ) = P 22 P 2 = f ( R 2 ) = x 2 − x x 2 − x 1 P 12 + x − x 1 x 2 − x 1 P 22 按x轴方向进行两次单线性插值分别得到蓝点R_{1}和R_{2}的像素值P_1=f(R_{1})和P_2=f(R_{2});\\ f(Q_{11})=P_{11},f(Q_{21})=P_{21}\\ P_1=f(R_1)=\frac{x2-x}{x2-x1}P_{11}+\frac{x-x1}{x2-x1}P_{21} \\ 另外,f(Q_{12})=P_{12},f(Q_{23})=P_{22}\\ P_2=f(R_2)=\frac{x2-x}{x2-x1}P_{12}+\frac{x-x1}{x2-x1}P_{22} 按x轴方向进行两次单线性插值分别得到蓝点R1和R2的像素值P1=f(R1)和P2=f(R2);f(Q11)=P11,f(Q21)=P21P1=f(R1)=x2−x1x2−xP11+x2−x1x−x1P21另外,f(Q12)=P12,f(Q23)=P22P2=f(R2)=x2−x1x2−xP12+x2−x1x−x1P22 -
按y轴方向进行一次单线性插值
按 y 轴方向进行一次单线性插值即可得到点 P 的像素值 f ( P ) f ( P ) = y 2 − y y 2 − y 1 P 1 + y − y 1 y 2 − y 1 P 2 按y轴方向进行一次单线性插值即可得到点P的像素值f(P) \\ f(P)=\frac{y2-y}{y2-y1}P_{1}+\frac{y-y1}{y2-y1}P_{2} 按y轴方向进行一次单线性插值即可得到点P的像素值f(P)f(P)=y2−y1y2−yP1+y2−y1y−y1P2

我们将P1和P2代入,可以得到下面公式:
f ( P ) = P 11 ( x 2 − x 1 ) ( y 2 − y 1 ) ( x 2 − x ) ( y 2 − y ) + P 21 ( x 2 − x 1 ) ( y 2 − y 1 ) ( x − x 1 ) ( y 2 − y ) + P 12 ( x 2 − x 1 ) ( y 2 − y 1 ) ( x 2 − x ) ( y − y 1 ) + P 22 ( x 2 − x 1 ) ( y 2 − y 1 ) ( x − x 1 ) ( y − y 1 ) f(P)=\frac{P_{11}}{(x2-x1)(y2-y1)}(x2-x)(y2-y) \\ +\frac{P_{21}}{(x2-x1)(y2-y1)}(x-x1)(y2-y) \\ +\frac{P_{12}}{(x2-x1)(y2-y1)}(x2-x)(y-y1) \\ +\frac{P_{22}}{(x2-x1)(y2-y1)}(x-x1)(y-y1) f(P)=(x2−x1)(y2−y1)P11(x2−x)(y2−y)+(x2−x1)(y2−y1)P21(x−x1)(y2−y)+(x2−x1)(y2−y1)P12(x2−x)(y−y1)+(x2−x1)(y2−y1)P22(x−x1)(y−y1)

由上图可知,分母可以化简为 1 ,因此 f ( P ) = P 11 ( x 2 − x ) ( y 2 − y ) + P 21 ( x − x 1 ) ( y 2 − y ) + P 12 ( x 2 − x ) ( y − y 1 ) + P 22 ( x − x 1 ) ( y − y 1 ) 由上图可知,分母可以化简为1,因此f(P)=P_{11}(x2-x)(y2-y) \\+P_{21}(x-x1)(y2-y) \\+P_{12}(x2-x)(y-y1) \\+P_{22}(x-x1)(y-y1) 由上图可知,分母可以化简为1,因此f(P)=P11(x2−x)(y2−y)+P21(x−x1)(y2−y)+P12(x2−x)(y−y1)+P22(x−x1)(y−y1)
1.3.2 pytorch例子详解
m = torch.nn.Upsample(scale_factor=2, mode='bilinear')
output1 = m(input)
print('双线性插值:\n', output1)
# 可以看到,通过双线性插值的方式,将2x2的原矩阵插值成4x4的目标矩阵。
双线性插值:
tensor([[[[10.0000, 12.5000, 17.5000, 20.0000],
[15.0000, 17.5000, 22.5000, 25.0000],
[25.0000, 27.5000, 32.5000, 35.0000],
[30.0000, 32.5000, 37.5000, 40.0000]]]])
上面的例子对应的图片如下图所示。

我们来计算P2的值(即P2=12.5)。
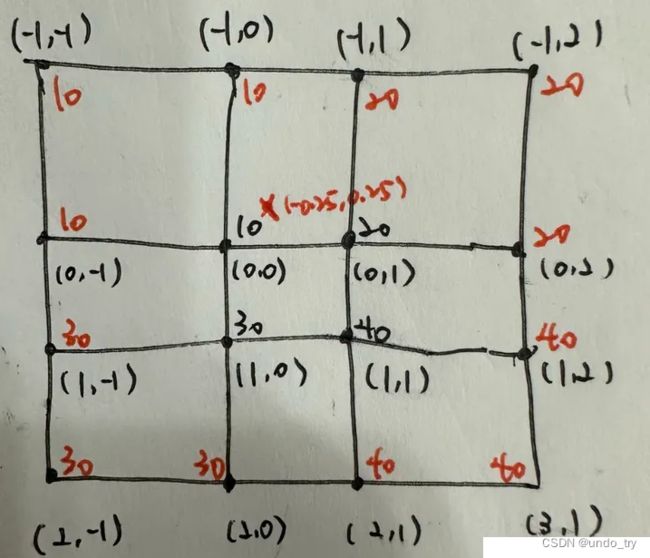
目标图像中P2为(0,1),可以根据下面公式计算出在原始图像中的坐标为(-0.25,0.25)。

(-0.25, 0.25)周围四个点分别为(-1, 0), (-1, 1), (0, 0), (0, 1)。对于是负数的坐标点,可以先对源矩阵进行拓展,拓展后的矩阵如下图所示。
这样我们将(-0.25, 0.25)代入化简后f公式,就得出f(结果P)=12.5
其中, P 11 = 10 , P 21 = 10 , P 12 = 20 , P 22 = 20 ( x 1 , y 1 ) = ( − 1 , 0 ) , ( x 1 , y 2 ) = ( − 1 , 1 ) ( x 2 , y 1 ) = ( 0 , 0 ) , ( x 2 , y 2 ) = ( 0 , 1 ) x = − 0.25 , y = 0.25 其中,P_{11}=10,P_{21}=10,P_{12}=20,P_{22}=20 \\ (x_1,y_1) = (-1,0),(x_1,y_2)= (-1,1) \\ (x_2,y_1)= (0,0),(x_2,y_2)= (0,1) \\ x=-0.25,y=0.25 其中,P11=10,P21=10,P12=20,P22=20(x1,y1)=(−1,0),(x1,y2)=(−1,1)(x2,y1)=(0,0),(x2,y2)=(0,1)x=−0.25,y=0.25
1.3.3 align_corners参数
align_corners参数设为True和False,其上采样结果是不同的
m = torch.nn.Upsample(scale_factor=2, mode='bilinear')
output1 = m(input)
print('双线性插值:\n', output1)
n = torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
output2 = n(input)
print('双线性插值align_corners=True:\n',output2)
双线性插值:
tensor([[[[10.0000, 12.5000, 17.5000, 20.0000],
[15.0000, 17.5000, 22.5000, 25.0000],
[25.0000, 27.5000, 32.5000, 35.0000],
[30.0000, 32.5000, 37.5000, 40.0000]]]])
双线性插值align_corners=True:
tensor([[[[10.0000, 13.3333, 16.6667, 20.0000],
[16.6667, 20.0000, 23.3333, 26.6667],
[23.3333, 26.6667, 30.0000, 33.3333],
[30.0000, 33.3333, 36.6667, 40.0000]]]])
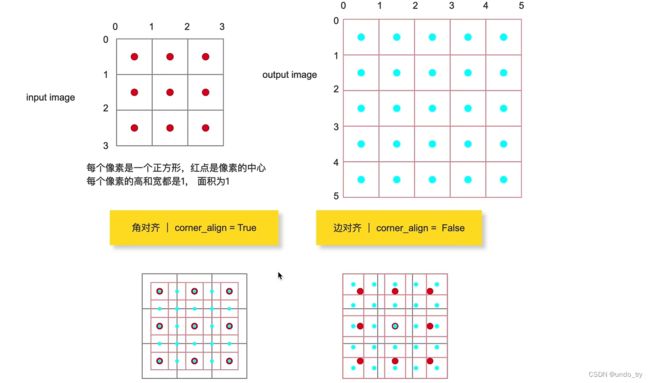
之所以造成上采样结果不同,其主要原因是看待像素的方式不同:
①Centers-aligned:将像素看作一个有面积的方格,方格中心点位置代表这个像素。
align_corners=False就是以这种方式看待像素的,像素的坐标并不是图像矩阵所对应的下标,
而是需要将下标i,j各加上0.5才是此时每个像素在坐标系里的坐标(以左上角为原点,x轴向右为正,y轴向下为正)。
②Corners-aligned:将像素看作一个理想的点,这个点的位置就代表这个像素。
align_corners=True是以这种方式看待像素的,每个像素的在矩阵里的下标i,j被直接视作坐标系里的一个个的坐标点进行计算。
具体原理可以参考视频:
https://www.bilibili.com/video/BV1wh411E7j9
2、反池化
反池化是池化的逆操作,是无法通过池化的结果还原出全部的原始数据,现如今很少使用这种方法去实现图像的上采样。因为池化的过程就只保留了主要信息,舍去部分信息。如果想从池化后的这些主要信息恢复出全部信息,则存在信息缺失,这时只能通过补位来实现最大程度的信息完整。
池化有两种:最大池化和平均池化,其反池化也需要与其对应。
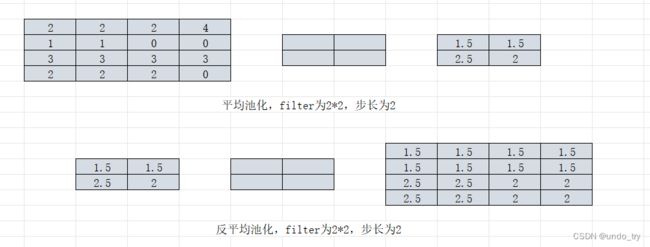
2.1 反平均池化
首先还原成原来的大小,然后将池化结果中的每个值都填入其对应原始数据区域中相应位置即可。
平均池化和反平均池化的过程如下:
2.2 反最大池化
在池化过程中记录最大激活值的坐标位置,然后在反池化时,只把池化过程中最大激活值所在位置坐标值激活,其他的值设置为0。
当然,这个过程只是一种近似。因为在池化过程中,除了最大值的位置,其他的值也是不为0的。
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1、最大池化与反最大池化
# 最大池化
input = torch.randint(0, 4, size=(1, 1, 4, 4), dtype=torch.float32)
print('原始输入:\n',input)
'''
反池化与前面的池化基本相同,参数一般仍然需要kernel_size,stride,padding等。
对于反最大池化,我们还需要提供参数indices。
indices表示下池化过程中池化窗口返回那个最大值的位置索引。
事实上,在前面的最大池化中,参数return_indices即表示是否返回索引,只不过该函数默认为False。
'''
maxpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
output, indices = maxpool(input)
print('池化后结果:\n', output) # 池化后结果
print('池化后indices:\n', indices) # 池化后indices
原始输入:
tensor([[[[1., 1., 0., 0.],
[1., 2., 2., 3.],
[3., 3., 2., 0.],
[1., 1., 2., 2.]]]])
池化后结果:
tensor([[[[2., 3.],
[3., 2.]]]])
池化后indices:
tensor([[[[ 5, 7],
[ 8, 10]]]])
# 反池化时,只把池化过程中最大激活值所在位置坐标值激活,其他的值设置为0。
反最大池化后结果:
tensor([[[[0., 0., 0., 0.],
[0., 2., 0., 3.],
[3., 0., 2., 0.],
[0., 0., 0., 0.]]]])
3、反卷积
3.1 常规卷积的计算过程
对于正常的卷积,我们需要实现大量的相乘相加操作,而这种乘加的方式恰好是矩阵乘法所擅长的。 所以在代码实现的时候,通常会借助矩阵乘法快速的实现卷积操作, 那么这是怎么做的呢?假设输入图像尺寸为4 × 4 , 卷积核为3 × 3 , padding=0, stride=1,通过计算可知,卷积之后输出图像的尺寸为2×2,如下图所示:
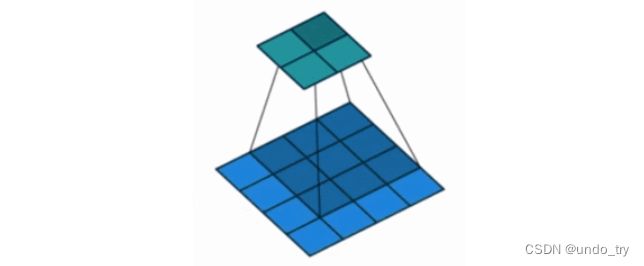
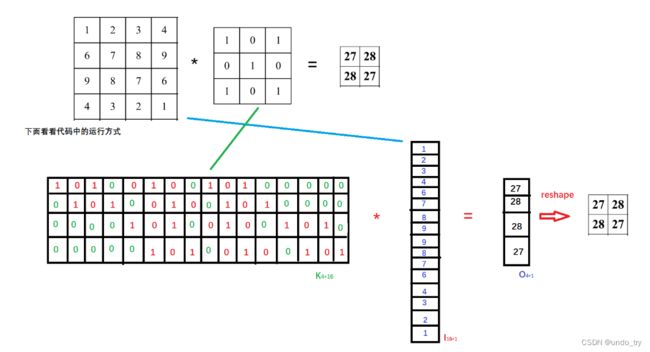
常规卷积在代码实现时的具体过程就是:
-
首先将代表输入图像的4 × 4 矩阵转换成16 × 1 的列向量,
-
由于计算可知输出图像是2×2的矩阵,同样将其转换成4×1的列向量
-
那么由矩阵乘法可知,参数矩阵必定是4×16的,那么这个4×16的参数矩阵是怎么来的呢?从上图很明显可知4就是卷积核窗口滑动了4次就遍历完整个输入图像了,这个16就是先把3×3的9个权值拉成一行,然后根据窗口在输入图像上滑动的位置补7个0凑成16个参数,这16个参数就是输入图像16个像素各自对应的权重参数。
3.2 转置卷积(反卷积)的计算过程
反卷积又被称为转置卷积,其实这个函数最准确的叫法应该是转置卷积。
转置卷积是一种上采样方法,输入的图像尺寸是比较小的,经过转置卷积之后,会输出一个更大的图像。假设输入图像尺寸为2 × 2 , 卷积核为3 × 3 ,padding=0, stride=1,通过转置卷积会得到4×4的输出图像,如下图所示:
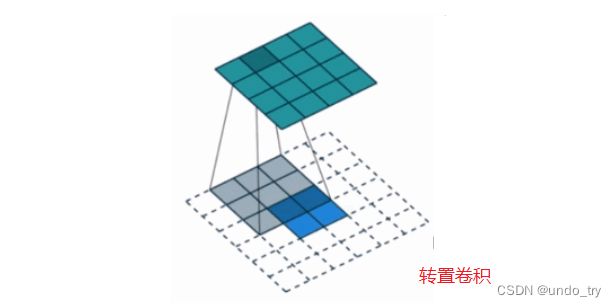
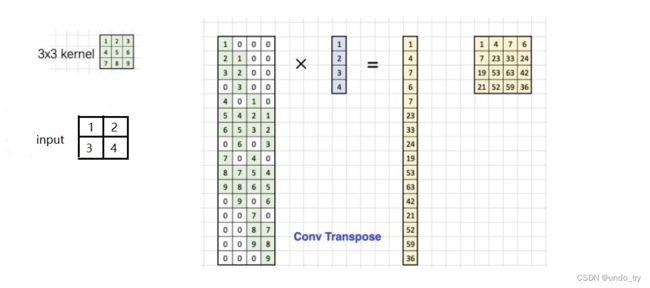
转置卷积在代码实现时的具体过程就是:
首先将代表输入图像的2 × 2 矩阵转换成4 × 1 的列向量
由于转置卷积后输出图像是4×4的矩阵,同样将其转换成16×1的列向量
那么由矩阵乘法可知,参数矩阵必定是16×4的,那么这个16×4的参数矩阵是怎么来的呢?从上图很明显可知16就是卷积核窗口滑动了16次就遍历完整个输入图像了,虽然这里的卷积核有9个权值,可是能与图像相乘的最多只有四个(也就是卷积核在中间的时候), 这便是参数矩阵中4的含义。
3.3 pytorch例子
反卷积又被称为转置卷积
torch.nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1,
padding_mode='zeros',
device=None,
dtype=None
)
参数说明:
in_channels: 输入的通道数
out_channels:输出的通道数
kernel_size:卷积核的大小
stride:卷积核滑动的步长,默认是1
padding:怎么填充输入图像,此参数的类型可以是int , tuple或str , optional 。默认padding=0,即不填充。
dilation:设置膨胀率,即核内元素间距,默认是1。
如果kernel_size=3,dilation=1,那么卷积核大小就是3×3;
如果kernel_size=3,dilation=2,那么卷积核大小为5×5
groups:通过设置这个参数来决定分几组进行卷积,默认是1,即默认是普通卷积, 此时卷积核通道数=输入通道数
bias:是否添加偏差,默认true
padding_mode:填充时,此参数决定用什么值来填充,默认是'zeros',即用0填充
可选参数有'zeros', 'reflect', 'replicate'或'circular'
import torch
import torch.nn as nn
if __name__ == '__main__':
input = torch.tensor([
[1, 2, 3, 4],
[6, 7, 8, 9],
[9, 8, 7, 6],
[4, 3, 2, 1]
], dtype=torch.float32).view(1, 1, 4, 4)
print('原始输入:\n', input)
# 1、常规卷积
conv2 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, bias=False)
kernel = torch.tensor(
[
[1, 0, 1],
[0, 1, 0],
[1, 0, 1]
], dtype=torch.float32
).view(1, 1, 3, 3)
for param in conv2.parameters():
param.data = kernel
print('自定义kernel结果:\n', param)
output = conv2(input)
print('卷积结果:\n', output)
print('-'*80)
# 2、反卷积
convtrans = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, bias=False)
input = torch.tensor([
[1, 2],
[3, 4]
], dtype=torch.float32).view(1, 1, 2, 2)
kernel = torch.tensor(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
], dtype=torch.float32
).view(1, 1, 3, 3)
for param in convtrans.parameters():
param.data = kernel
print('自定义kernel结果:\n', param)
print('反卷积结果:\n', convtrans(input))
原始输入:
tensor([[[[1., 2., 3., 4.],
[6., 7., 8., 9.],
[9., 8., 7., 6.],
[4., 3., 2., 1.]]]])
自定义kernel结果:
Parameter containing:
tensor([[[[1., 0., 1.],
[0., 1., 0.],
[1., 0., 1.]]]], requires_grad=True)
卷积结果:
tensor([[[[27., 28.],
[28., 27.]]]], grad_fn=<ConvolutionBackward0>)
--------------------------------------------------------------------------------
自定义kernel结果:
Parameter containing:
tensor([[[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]]]], requires_grad=True)
反卷积结果:
tensor([[[[ 1., 4., 7., 6.],
[ 7., 23., 33., 24.],
[19., 53., 63., 42.],
[21., 52., 59., 36.]]]], grad_fn=<ConvolutionBackward0>)