Linux 进程控制
进程地址空间的收尾
task_struct有一个结构体成员叫mm_struct,也就是进程地址空间。
为什么要有进程地址空间:进程内存地址管理,保护物理内存,进行权限审查,从无序变有序,让我们从统一的视角看待进程代码和数据。
mm_struct里面有这些东西。
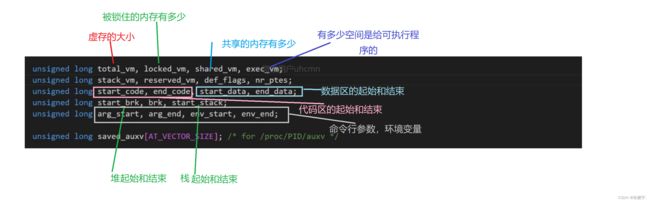
这些起始和结束划分了很多区域。也就是我们用户区的那3个G的空间:
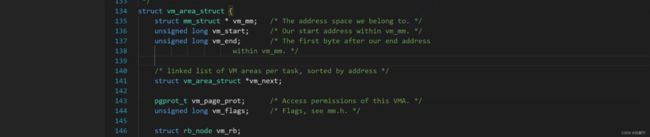
vm_area_struct里面有自己的成员
其中vm_mm是一个指向自己的指针。
start和end指定了一段范围。
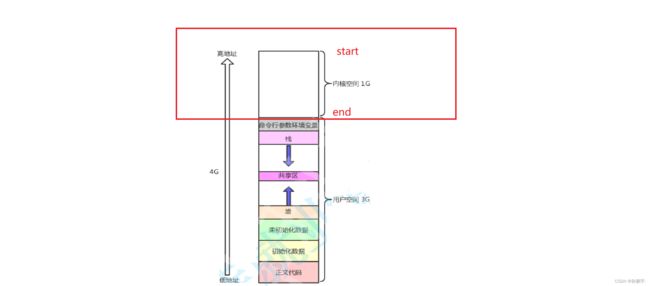
 也就是内核区那1个G的空间:
也就是内核区那1个G的空间:
进程控制
fork()创建进程

fork有返回值,返回值的本质就是写入。
所以父进程要创建一个变量 pid id=fork()。
返回时就是向该变量进行写入。
子进程和父进程同享这一个变量,为了子进程修改该变量时不影响父进程,因此就有了写实拷贝。
因此父子进程的该变量值不同,但是逻辑地址相同。
这在上文已经讲过,过了。
创建子进程之后会做什么事情
写实拷贝
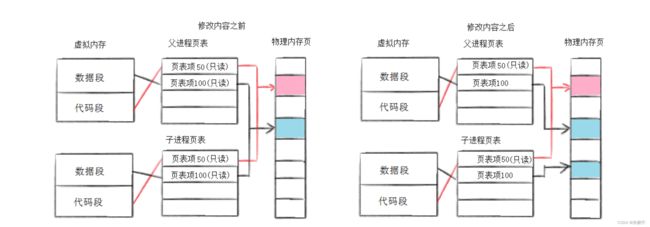
数据区本身是可读写的,但是在fork()创建完子进程之后变为只读了。

原因
子进程要写入就要产生写实拷贝,写实拷贝就要重新开辟一块空间,然后进行拷贝,修改页表。
这些工作都要操作系统来做。但是操作系统要怎么介入进来呢?
此时父进程正在fork(),操作系统会把父进程的数据区变为只读权限,这时候创建完子进程之后复制父进程的代码区,子进程也为只读权限。
这个工作是操作系统完成的,用户是看不见的,也就是用户是不知道的,那么用户就有修改子进程的可能。
因为页表此刻是只读权限,用户写入就会因为页表转换而报错。
操作系统此时就会过来,因为有人对只读数据区写入,操作系统此刻会介入,因为父子进程共享一块空间,所以子进程的修改就会影响父进程,为了不影响父进程,操作系统会给子进程重新开一块空间。
这是操作系统为了介入 写实拷贝进行的一个策略,同样的,当子进程没改,父进程要写入时也会发生写实拷贝。
页表转换出错的两种可能
第一种就是写入数据,正好地址落在了code starth ~code end之间,也就是代码区,这些区本身就只能读,这时候非要写就会报错。
第二种情况就是地址落在了数据区,这些区平时本身就有读写权限,此刻却只有读权限,这时候用户写入不是错误,而是操作系统为了介入的一种策略机制。
进程退出
main函数的return 0是什么意思?
为什么不return 1 ,2 ,3,4,5,6,7,8
用c写一段代码,创建一个子进程,让子进程做一个work()的工作,work()是一个函数。
我们让子进程做完这个工作就结束了,就退出。
return 0是main函数的返回值,main函数也是函数,被调用时也就是一个进程,它的父进程时bash。
bash想要知道它的子进程main函数任务进行的怎么样,是成功了还是失败了,就看main函数的返回值。
如果main函数返回0就代表成功,如果main函数返回非0就代表失败。
返回0的情况就不用管了,返回非0就有很多情况,比如1 2 3 4 5 6 7 8
每一个数字都代表一个错误的情况,如果只是看数字,谁也不知道到底是什么错误,所以每个数组都有一个映射的字符串。
strerror
就可以返回码对应的错误信息打印出来:
![]()
如下代码为打印100个错误信息:
 只截10个:
只截10个:

其中,我们可以看见 0是代表成功的。
errno
返回的是系统调用库函数报错时给的错误码。
写一段如下代码:
此时运行:
![]()
因为当前目录下并没有创建log.txt文件,所以就不能以只读形式打开该文件。
报错错误码为 2,错误信息为:“没有该文件"
错误码和退出码的区别
错误码是用户调用库函数或者系统调用用户的函数时的调用情况。
退出码是一个进程退出时的退出结果。
现在我们就可以不用return 0了
我们可以把错误信息打印出来,这样用户就知道了,把错误码return给bash,这样操作系统就知道了:

![]()
waitpid
进程等待。在二号手册明说明是系统调用: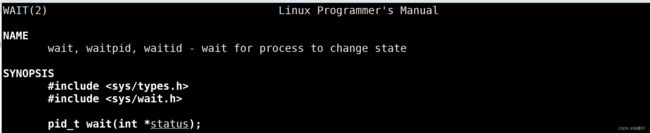
返回值错误时会设置errno: errno是c语言内置的,bash为什么也可以系统调用errno,因为linux内核是c写的。
errno是c语言内置的,bash为什么也可以系统调用errno,因为linux内核是c写的。
如果我们这样写代码:
int *b=NULL;
*b=100;就会出现如下报错:
![]()
这个报错字符串是:段错误。
原因是NULL地址是0x00000地址,这个地址在代码区上,是不被允许写入的。
如果强行访问就会出现指针越界报错。

信号
而我们的出错我们平常说是程序出错了,程序就是一个进程。进程的出错就需要操作系统去管理。
我们之前学过一个命令:kill 9 可以杀掉进程。
这个就是操作系统对进程的一个管理。
当然了,操作系统还有其他的管理,这种管理,我们称之为信号:
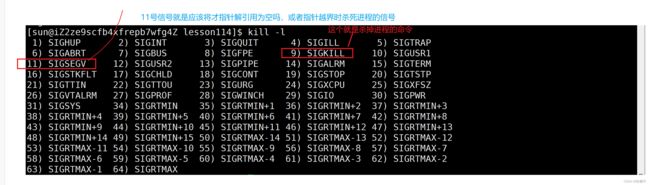
可以看见信号编码从1开始,也就是代表0是正常的,其余的非0都是各种报错。
当进程出现各种错误时,操作系统就会把对应错误的信号发送给进程,进程收到信号之后就会终止。
例如当进程出现指针越界访问时操作系统就会发送编码为9的信号,从而告诉进程:'你出现段错误了,停下."
因此一个进程是否正常就有看有没有收到信号。
验证
既然操作系统给进程发对应的信号编码就可以终止进程,那我们可以模拟实现一下,我们可以把信号发送给一个正常进程,从而让进程以各种报错而终止:
输入如下代码:
while(1)
{
printf("我是正常进程:pid:%d\n",getpid());
sleep(1);
}
此时编译运行让进程跑起来,会如下所示:
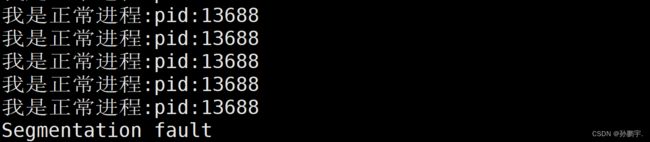
此刻输入命令:
kill -11 13688
进程就会报错,段错误:
让程序重新跑起来,输入 kill -9 +pid:
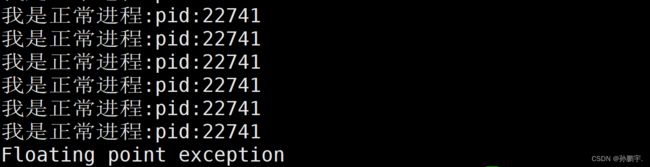
就会出现浮点型报错。
其他的报错不再模拟。
总结
两个数字
bash查看,子进程是否完成任务就看子进程的退出码来判断。
子进程是否出错就看操作系统给的信号编码。