ElasticSearch(六)【分词器】
六、分词器
6.1 分词器介绍
Analysis 和 Analyzer
Analysis:文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词(Analyzer)。Analysis是通过Analyzer来实现的。分词就是将文档通过Analyzer分成一个一个的Term,每一个Term都指向包含这个Term的文档
Analyzer 组成
【注意】:在ES中默认使用标准分词器:StandardAnalyzer特点:中文单字分词/单词分词
我是中国人this is a good man---->analyzer—>我 是 中 国 人 this is a good man
- 分析器(analyzer)都由三种构件组成的:
character filters,tokenizers,token filters- Character Filter 字符过滤器
- 在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello–> hello),&–> and,(I&you–>I and you)
- Tokenizers 分词器
- 英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词
- Token Filters Token过滤器
- 将切分的单词进行加工。大小写转换(例将"Quick"转为小写),去掉停用词(例如停用词像"a"、“and”、“the"等等),加入同义词(例如同义词像"jump"和"leap”)
- Character Filter 字符过滤器
【注意】
- 三者顺序:Character Filter—>Tokenizers—>Token Filter
- 三者个数:Character Filter(0个或多个)+ Tokenizers + Token Filters(0个或多个)
内置分词器
- Standard Analyzer:默认分词器,英文按单词切分,并小写处理
- Simple Analyzer:按照单词切分(符号被过滤),小写处理
- Stop Analyzer:小写处理,停用词过滤(the、a、is…)
- Whitespace Analyzer:按照空格切分,不转小写
- Keyword Analyzer:不分词,直接将输入当作输出
6.2 内置分词器测试
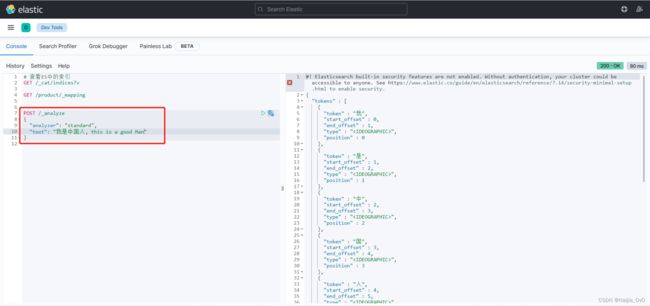
- Standard Analyzer 标准分词器
- 特点:按照单词分词,英文统一转为小写,过滤标点符号,中文单子分词
POST /_analyze
{
"analyzer": "standard",
"text": "我是中国人, this is a good Man"
}
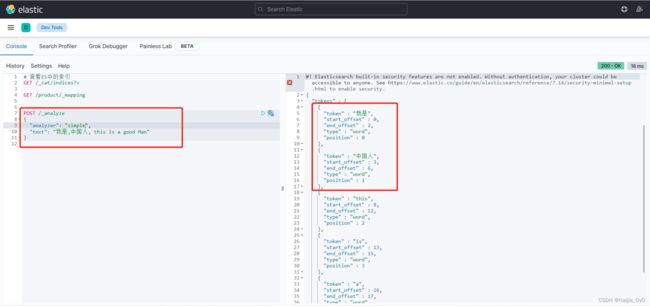
- Simple Analyzer 简单分词器
- 特点:按照单词分词,英文统一转为小写,过滤标点符号,中文不分词(按照"空格"或标点符号分词)
POST /_analyze
{
"analyzer": "simple",
"text": "我是,中国人, this is a good Man"
}
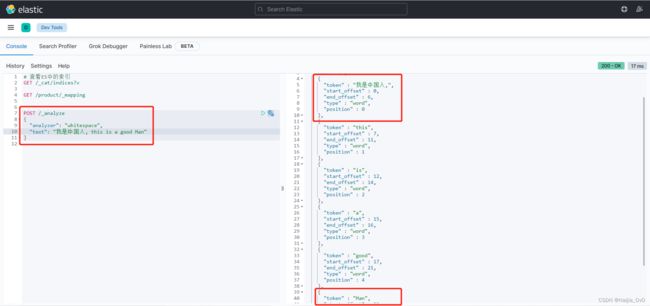
- WhitespaceAnalyzer 空格分词器
- 特点:中文、英文按照空格分词,英文不会转为小写,不去掉标点符号
POST /_analyze
{
"analyzer": "whitespace",
"text": "我是中国人, this is a good Man"
}
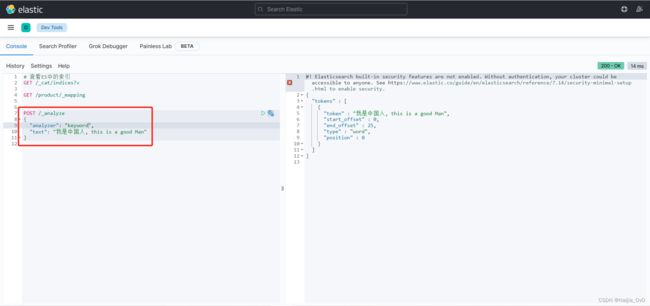
- Keyword Analyzer 关键词分词器
- 特点:将输入的内容当作一个关键词
POST /_analyze
{
"analyzer": "keyword",
"text": "我是中国人, this is a good Man"
}
6.3 创建索引设置分词
# 创建时,默认使用标准分词器 "analyzer": "standard"
PUT /analyzer
{
"settings": {},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
}
}
}
}
6.4 中文分词器
在ES中支持中文分词器非常多,如smartCN、IK等,这里推荐使用IK分词器
安装IK
github网站:https://github.com/medcl/elasticsearch-analysis-ik
【注意】
- IK分词器的版本要与安装ES的版本一致
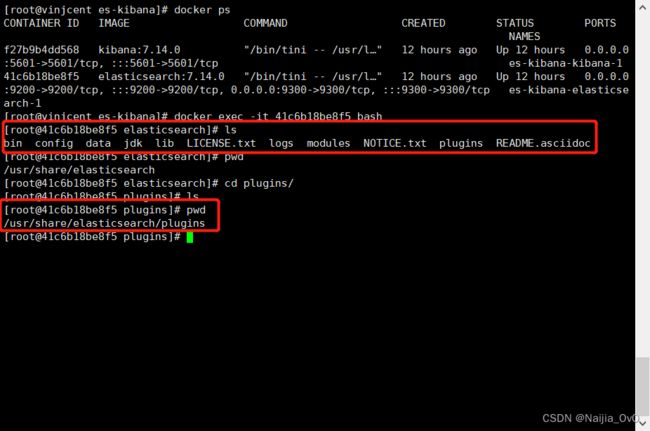
- Docker容器运行ES安装插件目录为
/usr/share/elasticsearch/plugins
# 1.下载对应版本到本地
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip
# 2.解压(建议本地下载之后,手动解压,再使用xftp将解压后的文件上传到linux)
unzip elasticsearch-analysis-ik-6.2.4.zip ik-7.14.0 (如果没有unzip命令,先使用"yum install -y unzip"进行安装)
# 3.移动到es安装目录的plugis目录中(不推荐使用,如果是手动解压,可以忽略此步骤往下看)
mv ik-7.14.0 elasticsearch-analysis-ik-6.2.4/plugins/

使用数据卷挂载的方式
# 1.先停止对应docker容器
docker-compose down
# 2.修改docker-compose.yml文件,如下图所示
# 将当前的路径下的ik-7.14.0文件映射到容器内部中的/usr/share/elasticsearch/plugins/ik-7.14.0文件,同时删除volumes下的plugin
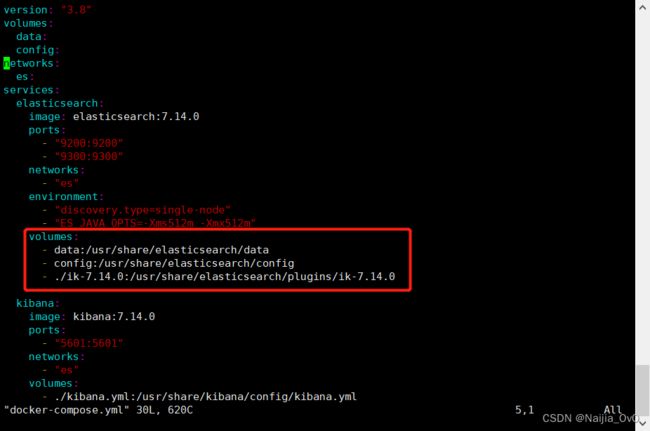
############################################### 内容如下 ###############################################
version: "3.8"
volumes:
data:
config:
networks:
es:
services:
elasticsearch:
image: elasticsearch:7.14.0
ports:
- "9200:9200"
- "9300:9300"
networks:
- "es"
environment:
- "discovery.type=single-node"
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data:/usr/share/elasticsearch/data
- config:/usr/share/elasticsearch/config
- ./ik-7.14.0:/usr/share/elasticsearch/plugins/ik-7.14.0
kibana:
image: kibana:7.14.0
ports:
- "5601:5601"
networks:
- "es"
volumes:
- ./kibana.yml:/usr/share/kibana/config/kibana.yml
############################################### ###############################################
6.5 IK使用
IK有两种颗粒度的拆分
- ik_smart:会做粗粒度的拆分
- ik_max_word:会将文本做最细粒度的拆分
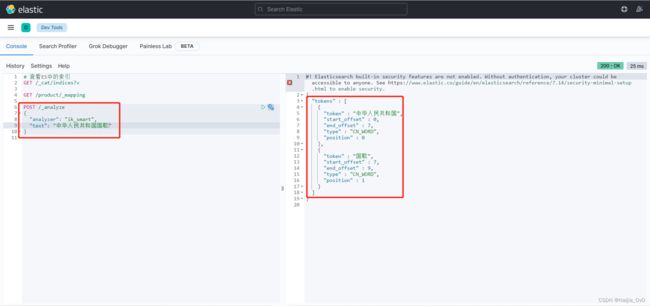
ik_smart测试
POST /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
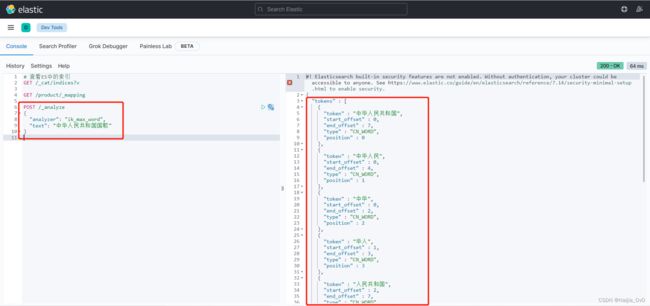
ik_max_word测试
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
下一篇文章《ElasticSearch - 扩展词、停用词配置》